Specificare i processi della pipeline
Azure DevOps Services | Azure DevOps Server 2022 - Azure DevOps Server 2019
È possibile organizzare la pipeline in processi. Ogni pipeline ha almeno un processo. Un processo è una serie di passaggi eseguiti in sequenza come unità. In altre parole, un processo è l'unità di lavoro più piccola che può essere pianificata per l'esecuzione.
Per informazioni sui concetti chiave e sui componenti che costituiscono una pipeline, vedere Concetti chiave per i nuovi utenti di Azure Pipelines.
Azure Pipelines non supporta la priorità dei processi per le pipeline YAML. Per controllare quando vengono eseguiti i processi, è possibile specificare condizioni e dipendenze.
Definire un singolo processo
Nel caso più semplice, una pipeline ha un singolo processo. In tal caso, non è necessario usare in modo esplicito la job parola chiave a meno che non si usi un modello. È possibile specificare direttamente i passaggi nel file YAML.
Questo file YAML include un processo eseguito in un agente ospitato da Microsoft e restituisce Hello world.
pool:
vmImage: 'ubuntu-latest'
steps:
- bash: echo "Hello world"
Potrebbe essere necessario specificare più proprietà in tale processo. In tal caso, è possibile usare la job parola chiave .
jobs:
- job: myJob
timeoutInMinutes: 10
pool:
vmImage: 'ubuntu-latest'
steps:
- bash: echo "Hello world"
La pipeline potrebbe avere più processi. In tal caso, usare la jobs parola chiave .
jobs:
- job: A
steps:
- bash: echo "A"
- job: B
steps:
- bash: echo "B"
La pipeline può avere più fasi, ognuna con più processi. In tal caso, usare la stages parola chiave .
stages:
- stage: A
jobs:
- job: A1
- job: A2
- stage: B
jobs:
- job: B1
- job: B2
La sintassi completa per specificare un processo è:
- job: string # name of the job, A-Z, a-z, 0-9, and underscore
displayName: string # friendly name to display in the UI
dependsOn: string | [ string ]
condition: string
strategy:
parallel: # parallel strategy
matrix: # matrix strategy
maxParallel: number # maximum number simultaneous matrix legs to run
# note: `parallel` and `matrix` are mutually exclusive
# you may specify one or the other; including both is an error
# `maxParallel` is only valid with `matrix`
continueOnError: boolean # 'true' if future jobs should run even if this job fails; defaults to 'false'
pool: pool # agent pool
workspace:
clean: outputs | resources | all # what to clean up before the job runs
container: containerReference # container to run this job inside
timeoutInMinutes: number # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: number # how much time to give 'run always even if cancelled tasks' before killing them
variables: { string: string } | [ variable | variableReference ]
steps: [ script | bash | pwsh | powershell | checkout | task | templateReference ]
services: { string: string | container } # container resources to run as a service container
La sintassi completa per specificare un processo è:
- job: string # name of the job, A-Z, a-z, 0-9, and underscore
displayName: string # friendly name to display in the UI
dependsOn: string | [ string ]
condition: string
strategy:
parallel: # parallel strategy
matrix: # matrix strategy
maxParallel: number # maximum number simultaneous matrix legs to run
# note: `parallel` and `matrix` are mutually exclusive
# you may specify one or the other; including both is an error
# `maxParallel` is only valid with `matrix`
continueOnError: boolean # 'true' if future jobs should run even if this job fails; defaults to 'false'
pool: pool # agent pool
workspace:
clean: outputs | resources | all # what to clean up before the job runs
container: containerReference # container to run this job inside
timeoutInMinutes: number # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: number # how much time to give 'run always even if cancelled tasks' before killing them
variables: { string: string } | [ variable | variableReference ]
steps: [ script | bash | pwsh | powershell | checkout | task | templateReference ]
services: { string: string | container } # container resources to run as a service container
uses: # Any resources (repos or pools) required by this job that are not already referenced
repositories: [ string ] # Repository references to Azure Git repositories
pools: [ string ] # Pool names, typically when using a matrix strategy for the job
Se lo scopo principale del processo è distribuire l'app (anziché compilare o testare l'app), è possibile usare un tipo speciale di processo denominato processo di distribuzione.
La sintassi per un processo di distribuzione è:
- deployment: string # instead of job keyword, use deployment keyword
pool:
name: string
demands: string | [ string ]
environment: string
strategy:
runOnce:
deploy:
steps:
- script: echo Hi!
Sebbene sia possibile aggiungere passaggi per le attività di distribuzione in un job, è consigliabile usare invece un processo di distribuzione. Un processo di distribuzione offre alcuni vantaggi. Ad esempio, è possibile eseguire la distribuzione in un ambiente, che include vantaggi come la possibilità di visualizzare la cronologia degli elementi distribuiti.

Tipi di processi
I processi possono essere di tipi diversi, a seconda della posizione in cui vengono eseguiti.
- I processi del pool di agenti vengono eseguiti in un agente in un pool di agenti.
- I processi del server vengono eseguiti in Azure DevOps Server.
- I processi contenitore vengono eseguiti in un contenitore su un agente in un pool di agenti. Per altre informazioni sulla scelta dei contenitori, vedere Definire i processi del contenitore.
Processi del pool di agenti
Si tratta del tipo di processi più comune e vengono eseguiti in un agente in un pool di agenti.
- Quando si usano agenti ospitati da Microsoft, ogni processo in una pipeline ottiene un nuovo agente.
- Usare le richieste con agenti self-hosted per specificare quali funzionalità deve essere necessario che un agente esegua il processo. È possibile ottenere lo stesso agente per i processi consecutivi, a seconda che nel pool di agenti siano presenti più agenti che corrispondano alle esigenze della pipeline. Se nel pool è presente un solo agente che corrisponde alle richieste della pipeline, la pipeline attende fino a quando l'agente non è disponibile.
Nota
Le richieste e le funzionalità sono progettate per l'uso con agenti self-hosted in modo che i processi possano essere confrontati con un agente che soddisfi i requisiti del processo. Quando si usano agenti ospitati da Microsoft, si seleziona un'immagine per l'agente che soddisfa i requisiti del processo, quindi anche se è possibile aggiungere funzionalità a un agente ospitato da Microsoft, non è necessario usare le funzionalità con gli agenti ospitati da Microsoft.
pool:
name: myPrivateAgents # your job runs on an agent in this pool
demands: agent.os -equals Windows_NT # the agent must have this capability to run the job
steps:
- script: echo hello world
O più richieste:
pool:
name: myPrivateAgents
demands:
- agent.os -equals Darwin
- anotherCapability -equals somethingElse
steps:
- script: echo hello world
Altre informazioni sulle funzionalità dell'agente.
Processi server
Le attività in un processo del server vengono orchestrate e eseguite nel server (Azure Pipelines o TFS). Un processo del server non richiede un agente o un computer di destinazione. In un processo del server sono supportate solo alcune attività. Il tempo massimo per un processo server è di 30 giorni.
Attività supportate dai processi senza agente
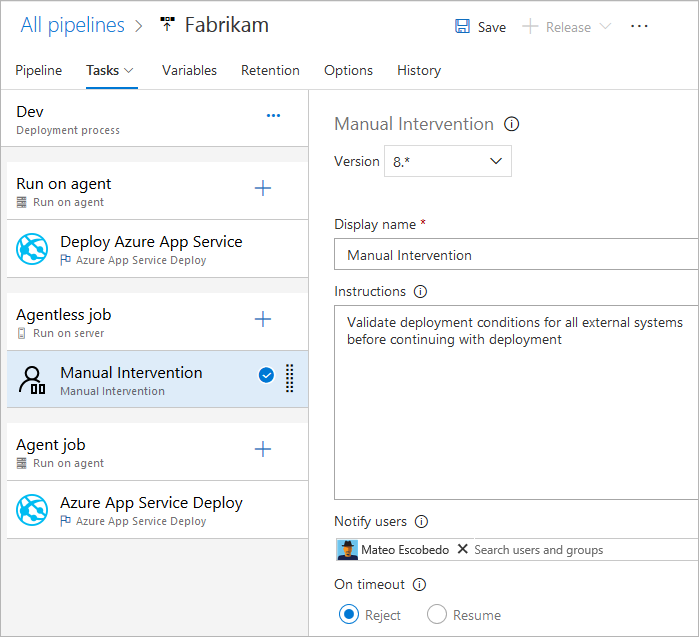
Attualmente sono supportate solo le attività seguenti per i processi senza agente:
- Attività Ritardo
- Richiamare l'attività Funzione di Azure
- Richiamare l'attività API REST
- Attività Di convalida manuale
- Attività Pubblica in bus di servizio di Azure
- Eseguire query sugli avvisi di Monitoraggio di Azure
- Attività Query Work Items
Poiché le attività sono estendibili, è possibile aggiungere altre attività senza agente usando le estensioni. Il timeout predefinito per i processi senza agente è 60 minuti.
La sintassi completa per specificare un processo del server è:
jobs:
- job: string
timeoutInMinutes: number
cancelTimeoutInMinutes: number
strategy:
maxParallel: number
matrix: { string: { string: string } }
pool: server # note: the value 'server' is a reserved keyword which indicates this is an agentless job
È anche possibile usare la sintassi semplificata:
jobs:
- job: string
pool: server # note: the value 'server' is a reserved keyword which indicates this is an agentless job
Dipendenze
Quando si definiscono più processi in una singola fase, è possibile specificare le dipendenze tra di esse. Le pipeline devono contenere almeno un processo senza dipendenze. Per impostazione predefinita, i processi della pipeline YAML di Azure DevOps vengono eseguiti in parallelo, a meno che il dependsOn valore non sia impostato.
Nota
Ogni agente può eseguire un solo processo alla volta. Per eseguire più processi in parallelo, è necessario configurare più agenti. Sono necessari anche processi paralleli sufficienti.
La sintassi per la definizione di più processi e le relative dipendenze è:
jobs:
- job: string
dependsOn: string
condition: string
Processi di esempio che compilano in sequenza:
jobs:
- job: Debug
steps:
- script: echo hello from the Debug build
- job: Release
dependsOn: Debug
steps:
- script: echo hello from the Release build
Processi di esempio compilati in parallelo (nessuna dipendenza):
jobs:
- job: Windows
pool:
vmImage: 'windows-latest'
steps:
- script: echo hello from Windows
- job: macOS
pool:
vmImage: 'macOS-latest'
steps:
- script: echo hello from macOS
- job: Linux
pool:
vmImage: 'ubuntu-latest'
steps:
- script: echo hello from Linux
Esempio di fan out:
jobs:
- job: InitialJob
steps:
- script: echo hello from initial job
- job: SubsequentA
dependsOn: InitialJob
steps:
- script: echo hello from subsequent A
- job: SubsequentB
dependsOn: InitialJob
steps:
- script: echo hello from subsequent B
Esempio di fan-in:
jobs:
- job: InitialA
steps:
- script: echo hello from initial A
- job: InitialB
steps:
- script: echo hello from initial B
- job: Subsequent
dependsOn:
- InitialA
- InitialB
steps:
- script: echo hello from subsequent
Condizioni
È possibile specificare le condizioni in base alle quali eseguire ogni processo. Per impostazione predefinita, un processo viene eseguito se non dipende da altri processi o se tutti i processi da cui dipende sono stati completati e completati. È possibile personalizzare questo comportamento forzando l'esecuzione di un processo anche se un processo precedente ha esito negativo o specificando una condizione personalizzata.
Esempio per eseguire un processo in base allo stato di esecuzione di un processo precedente:
jobs:
- job: A
steps:
- script: exit 1
- job: B
dependsOn: A
condition: failed()
steps:
- script: echo this will run when A fails
- job: C
dependsOn:
- A
- B
condition: succeeded('B')
steps:
- script: echo this will run when B runs and succeeds
Esempio di utilizzo di una condizione personalizzata:
jobs:
- job: A
steps:
- script: echo hello
- job: B
dependsOn: A
condition: and(succeeded(), eq(variables['build.sourceBranch'], 'refs/heads/main'))
steps:
- script: echo this only runs for master
È possibile specificare che un processo viene eseguito in base al valore di una variabile di output impostata in un processo precedente. In questo caso, è possibile usare solo le variabili impostate in processi dipendenti direttamente:
jobs:
- job: A
steps:
- script: "echo '##vso[task.setvariable variable=skipsubsequent;isOutput=true]false'"
name: printvar
- job: B
condition: and(succeeded(), ne(dependencies.A.outputs['printvar.skipsubsequent'], 'true'))
dependsOn: A
steps:
- script: echo hello from B
Timeout
Per evitare di occupare risorse quando il processo non risponde o è in attesa troppo a lungo, è consigliabile impostare un limite per quanto tempo è consentito l'esecuzione del processo. Usare l'impostazione di timeout del processo per specificare il limite in minuti per l'esecuzione del processo. L'impostazione del valore su zero indica che il processo può essere eseguito:
- Per sempre sugli agenti self-hosted
- Per 360 minuti (6 ore) sugli agenti ospitati da Microsoft con un progetto pubblico e un repository pubblico
- Per 60 minuti sugli agenti ospitati da Microsoft con un progetto privato o un repository privato (a meno che non venga pagata capacità aggiuntiva)
Il periodo di timeout inizia all'avvio dell'esecuzione del processo. Non include il momento in cui il processo è in coda o è in attesa di un agente.
timeoutInMinutes consente di impostare un limite per il tempo di esecuzione del processo. Se non specificato, il valore predefinito è 60 minuti. Quando 0 viene specificato, viene usato il limite massimo (descritto in precedenza).
cancelTimeoutInMinutes consente di impostare un limite per l'ora di annullamento del processo quando l'attività di distribuzione è impostata per continuare l'esecuzione se un'attività precedente non è riuscita. Se non specificato, il valore predefinito è 5 minuti. Il valore deve essere compreso tra 1 e 35790 minuti.
jobs:
- job: Test
timeoutInMinutes: 10 # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: 2 # how much time to give 'run always even if cancelled tasks' before stopping them
I timeout hanno il livello di precedenza seguente.
- Negli agenti ospitati da Microsoft, i processi sono limitati per quanto tempo possono essere eseguiti in base al tipo di progetto e se vengono eseguiti usando un processo parallelo a pagamento. Quando è trascorso l'intervallo di timeout del processo ospitato da Microsoft, il processo viene terminato. Negli agenti ospitati da Microsoft i processi non possono essere eseguiti più a lungo di questo intervallo, indipendentemente dai timeout a livello di processo specificati nel processo.
- Il timeout configurato a livello di processo specifica la durata massima per l'esecuzione del processo. Quando viene trascorso l'intervallo di timeout a livello di processo, il processo viene terminato. Se il processo viene eseguito in un agente ospitato da Microsoft, l'impostazione del timeout a livello di processo su un intervallo maggiore del timeout predefinito del processo ospitato da Microsoft non ha alcun effetto e viene usato il timeout del processo ospitato da Microsoft.
- È anche possibile impostare il timeout per ogni attività singolarmente. Vedere le opzioni di controllo delle attività. Se l'intervallo di timeout a livello di processo è trascorso prima del completamento dell'attività, il processo in esecuzione viene terminato, anche se l'attività è configurata con un intervallo di timeout più lungo.
Configurazione multi-processo
Da un singolo processo creato, è possibile eseguire più processi su più agenti in parallelo. Alcuni esempi includono:
Compilazioni con più configurazioni: è possibile compilare più configurazioni in parallelo. Ad esempio, è possibile compilare un'app Visual C++ per entrambe
debugle configurazioni ereleasein entrambex86le piattaforme ex64. Per altre informazioni, vedere Compilazione di Visual Studio - più configurazioni per più piattaforme.Distribuzioni con più configurazioni: è possibile eseguire più distribuzioni in parallelo, ad esempio in aree geografiche diverse.
Test con più configurazioni: è possibile eseguire test di più configurazioni in parallelo.
La configurazione multipla genererà sempre almeno un processo, anche se una variabile multiconfigurazione è vuota.
La matrix strategia consente di inviare più volte un processo, con set di variabili diversi. Il maxParallel tag limita la quantità di parallelismo. Il processo seguente viene inviato tre volte con i valori di Location e Browser impostati come specificato. Tuttavia, solo due processi vengono eseguiti contemporaneamente.
jobs:
- job: Test
strategy:
maxParallel: 2
matrix:
US_IE:
Location: US
Browser: IE
US_Chrome:
Location: US
Browser: Chrome
Europe_Chrome:
Location: Europe
Browser: Chrome
Nota
I nomi di configurazione della matrice (come US_IE sopra) devono contenere solo lettere alfabetici latine di base (A-Z, a-z), numeri e caratteri di sottolineatura (_).
Devono iniziare con una lettera.
Inoltre, devono essere di almeno 100 caratteri.
È anche possibile usare le variabili di output per generare una matrice. Questo può essere utile se è necessario generare la matrice usando uno script.
matrix accetta un'espressione di runtime contenente un oggetto JSON stringato.
L'oggetto JSON, se espanso, deve corrispondere alla sintassi di matrice.
Nell'esempio seguente è stata hardcoded la stringa JSON, ma potrebbe essere generata da un linguaggio di scripting o da un programma da riga di comando.
jobs:
- job: generator
steps:
- bash: echo "##vso[task.setVariable variable=legs;isOutput=true]{'a':{'myvar':'A'}, 'b':{'myvar':'B'}}"
name: mtrx
# This expands to the matrix
# a:
# myvar: A
# b:
# myvar: B
- job: runner
dependsOn: generator
strategy:
matrix: $[ dependencies.generator.outputs['mtrx.legs'] ]
steps:
- script: echo $(myvar) # echos A or B depending on which leg is running
Sezionamento
È possibile usare un processo dell'agente per eseguire un gruppo di test in parallelo. Ad esempio, è possibile eseguire un gruppo di grandi dimensioni di 1000 test su un singolo agente. In alternativa, è possibile usare due agenti ed eseguire 500 test su ognuno in parallelo.
Per applicare il sezionamento, le attività nel processo devono essere sufficientemente intelligenti da comprendere la sezione a cui appartengono.
L'attività Test di Visual Studio è un'attività di questo tipo che supporta il sezionamento dei test. Se sono stati installati più agenti, è possibile specificare il modo in cui l'attività test di Visual Studio viene eseguita in parallelo su questi agenti.
La parallel strategia consente di duplicare un processo più volte.
Le variabili System.JobPositionInPhase e System.TotalJobsInPhase vengono aggiunte a ogni processo. Le variabili possono quindi essere usate all'interno degli script per dividere il lavoro tra i processi.
Vedere Parallel and multiple execution using agent jobs (Parallel and multiple execution using agent jobs).
Il processo seguente viene inviato cinque volte con i valori di System.JobPositionInPhase e System.TotalJobsInPhase impostato in modo appropriato.
jobs:
- job: Test
strategy:
parallel: 5
Variabili di processo
Se si usa YAML, è possibile specificare variabili nel processo. Le variabili possono essere passate agli input dell'attività usando la sintassi della macro $(variableName) o accessibili all'interno di uno script usando la variabile di fase.
Di seguito è riportato un esempio di definizione delle variabili in un processo e dell'uso all'interno delle attività.
variables:
mySimpleVar: simple var value
"my.dotted.var": dotted var value
"my var with spaces": var with spaces value
steps:
- script: echo Input macro = $(mySimpleVar). Env var = %MYSIMPLEVAR%
condition: eq(variables['agent.os'], 'Windows_NT')
- script: echo Input macro = $(mySimpleVar). Env var = $MYSIMPLEVAR
condition: in(variables['agent.os'], 'Darwin', 'Linux')
- bash: echo Input macro = $(my.dotted.var). Env var = $MY_DOTTED_VAR
- powershell: Write-Host "Input macro = $(my var with spaces). Env var = $env:MY_VAR_WITH_SPACES"
Per informazioni sull'uso di una condizione, vedere Specificare le condizioni.
Area di lavoro
Quando si esegue un processo del pool di agenti, viene creata un'area di lavoro nell'agente. L'area di lavoro è una directory in cui scarica l'origine, esegue i passaggi e produce output. È possibile fare riferimento alla directory dell'area di lavoro nel processo usando Pipeline.Workspace la variabile . In questo caso vengono create varie sottodirectory:
Build.SourcesDirectoryè dove le attività scaricano il codice sorgente dell'applicazione.Build.ArtifactStagingDirectoryè la posizione in cui le attività scaricano gli artefatti necessari per la pipeline o caricano gli artefatti prima della pubblicazione.Build.BinariesDirectoryè dove le attività scrivono i relativi output.Common.TestResultsDirectoryè dove le attività caricano i risultati dei test.
e $(Build.ArtifactStagingDirectory) $(Common.TestResultsDirectory) vengono sempre eliminati e ricreati prima di ogni compilazione.
Quando si esegue una pipeline in un agente self-hosted, per impostazione predefinita, nessuna delle sottodirectory diverse da $(Build.ArtifactStagingDirectory) e $(Common.TestResultsDirectory) viene pulita tra due esecuzioni consecutive. Di conseguenza, è possibile eseguire compilazioni e distribuzioni incrementali, purché le attività vengano implementate per usarle. È possibile eseguire l'override di questo comportamento usando l'impostazione workspace nel processo.
Importante
Le opzioni di pulizia dell'area di lavoro sono applicabili solo per gli agenti self-hosted. I processi vengono sempre eseguiti in un nuovo agente con agenti ospitati da Microsoft.
- job: myJob
workspace:
clean: outputs | resources | all # what to clean up before the job runs
Quando si specifica una delle clean opzioni, queste vengono interpretate come segue:
outputs: eliminaBuild.BinariesDirectoryprima di eseguire un nuovo processo.resources: eliminaBuild.SourcesDirectoryprima di eseguire un nuovo processo.all: eliminare l'interaPipeline.Workspacedirectory prima di eseguire un nuovo processo.
jobs:
- deployment: MyDeploy
pool:
vmImage: 'ubuntu-latest'
workspace:
clean: all
environment: staging
Nota
A seconda delle funzionalità dell'agente e delle richieste di pipeline, ogni processo può essere indirizzato a un agente diverso nel pool self-hosted. Di conseguenza, è possibile ottenere un nuovo agente per le esecuzioni successive della pipeline (o fasi o processi nella stessa pipeline), pertanto non è garantito che le esecuzioni, i processi o le fasi successive saranno in grado di accedere agli output di esecuzioni, processi o fasi precedenti. È possibile configurare le funzionalità dell'agente e le richieste di pipeline per specificare quali agenti vengono usati per eseguire un processo della pipeline, ma a meno che nel pool non sia presente un solo agente che soddisfi le richieste, non esiste alcuna garanzia che i processi successivi useranno lo stesso agente dei processi precedenti. Per altre informazioni, vedere Specificare le richieste.
Oltre alla pulizia dell'area di lavoro, è anche possibile configurare la pulizia configurando l'impostazione Pulisci nell'interfaccia utente delle impostazioni della pipeline. Quando l'impostazione Pulisci è true, che è anche il valore predefinito, equivale a specificare clean: true per ogni passaggio di estrazione nella pipeline. Quando si specifica clean: true, si eseguirà git clean -ffdx seguito da git reset --hard HEAD prima del recupero git. Per configurare l'impostazione Pulisci :
Modificare la pipeline, scegliere ...e selezionare Trigger.
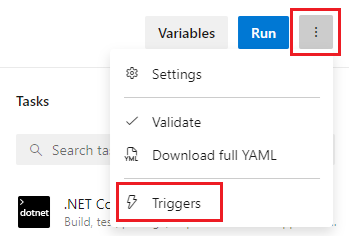
Selezionare YAML, Recupera origini e configurare l'impostazione Pulisci desiderata. Il valore predefinito è true.
Download artefatto
Questo file YAML di esempio pubblica l'artefatto WebSite e quindi scarica l'artefatto in $(Pipeline.Workspace). Il processo Distribuisci viene eseguito solo se il processo di compilazione ha esito positivo.
# test and upload my code as an artifact named WebSite
jobs:
- job: Build
pool:
vmImage: 'ubuntu-latest'
steps:
- script: npm test
- task: PublishBuildArtifacts@1
inputs:
pathtoPublish: '$(System.DefaultWorkingDirectory)'
artifactName: WebSite
# download the artifact and deploy it only if the build job succeeded
- job: Deploy
pool:
vmImage: 'ubuntu-latest'
steps:
- checkout: none #skip checking out the default repository resource
- task: DownloadBuildArtifacts@0
displayName: 'Download Build Artifacts'
inputs:
artifactName: WebSite
downloadPath: $(Pipeline.Workspace)
dependsOn: Build
condition: succeeded()
Per informazioni sull'uso di dependsOn e condizione, vedere Specificare le condizioni.
Accesso al token OAuth
È possibile consentire agli script in esecuzione in un processo di accedere al token di sicurezza OAuth o Azure Pipelines corrente. Il token può essere usato per eseguire l'autenticazione all'API REST di Azure Pipelines.
Il token OAuth è sempre disponibile per le pipeline YAML.
Deve essere mappato in modo esplicito all'attività o al passaggio usando env.
Ecco un esempio:
steps:
- powershell: |
$url = "$($env:SYSTEM_TEAMFOUNDATIONCOLLECTIONURI)$env:SYSTEM_TEAMPROJECTID/_apis/build/definitions/$($env:SYSTEM_DEFINITIONID)?api-version=4.1-preview"
Write-Host "URL: $url"
$pipeline = Invoke-RestMethod -Uri $url -Headers @{
Authorization = "Bearer $env:SYSTEM_ACCESSTOKEN"
}
Write-Host "Pipeline = $($pipeline | ConvertTo-Json -Depth 100)"
env:
SYSTEM_ACCESSTOKEN: $(system.accesstoken)