Definire le variabili
Azure DevOps Services | Azure DevOps Server 2022 - Azure DevOps Server 2019
Le variabili offrono un modo pratico per ottenere i bit di dati chiave in varie parti della pipeline. L'uso più comune delle variabili consiste nel definire un valore che è quindi possibile usare nella pipeline. Tutte le variabili sono stringhe e sono modificabili. Il valore di una variabile può passare da esecuzione a esecuzione o da processo a processo della pipeline.
Quando si definisce la stessa variabile in più posizioni con lo stesso nome, la variabile con ambito locale ha la precedenza. Una variabile definita a livello di processo può quindi eseguire l'override di una variabile impostata a livello di fase. Una variabile definita a livello di fase esegue l'override di una variabile impostata a livello radice della pipeline. Una variabile impostata nel livello radice della pipeline esegue l'override di una variabile impostata nell'interfaccia utente delle impostazioni della pipeline. Per altre informazioni su come usare le variabili definite nel processo, nella fase e nel livello radice, vedere Ambito delle variabili.
È possibile usare le variabili con espressioni per assegnare valori in modo condizionale e personalizzare ulteriormente le pipeline.
Le variabili sono diverse dai parametri di runtime. I parametri di runtime sono tipizzati e disponibili durante l'analisi del modello.
Variabili definite dall'utente
Quando si definisce una variabile, è possibile usare sintassi diverse (macro, espressione modello o runtime) e la sintassi usata determina dove viene eseguito il rendering della variabile nella pipeline.
Nelle pipeline YAML è possibile impostare le variabili a livello di radice, fase e processo. È anche possibile specificare variabili all'esterno di una pipeline YAML nell'interfaccia utente. Quando si imposta una variabile nell'interfaccia utente, tale variabile può essere crittografata e impostata come segreto.
Le variabili definite dall'utente possono essere impostate come di sola lettura. Esistono restrizioni di denominazione per le variabili( ad esempio: non è possibile usare secret all'inizio di un nome di variabile).
È possibile usare un gruppo di variabili per rendere disponibili le variabili tra più pipeline.
Usare i modelli per definire le variabili in un file usato in più pipeline.
Variabili multilinea definite dall'utente
Azure DevOps supporta variabili multilinea, ma esistono alcune limitazioni.
I componenti downstream, ad esempio le attività della pipeline, potrebbero non gestire correttamente i valori delle variabili.
Azure DevOps non modifica i valori delle variabili definite dall'utente. I valori delle variabili devono essere formattati correttamente prima di essere passati come variabili a più righe. Quando si formatta la variabile, evitare caratteri speciali, non usare nomi limitati e assicurarsi di usare un formato di fine riga che funzioni per il sistema operativo dell'agente.
Le variabili a più righe si comportano in modo diverso a seconda del sistema operativo. Per evitare questo problema, assicurarsi di formattare correttamente le variabili multilinea per il sistema operativo di destinazione.
Azure DevOps non modifica mai i valori delle variabili, anche se si fornisce una formattazione non supportata.
Variabili di sistema
Oltre alle variabili definite dall'utente, Azure Pipelines include variabili di sistema con valori predefiniti. Ad esempio, la variabile predefinita Build.BuildId fornisce l'ID di ogni compilazione e può essere usata per identificare esecuzioni di pipeline diverse. È possibile usare la Build.BuildId variabile negli script o nelle attività quando è necessario un valore univoco.
Se si usano pipeline di compilazione YAML o classiche, vedere variabili predefinite per un elenco completo delle variabili di sistema.
Se si usano pipeline di versione classica, vedere Variabili di versione.
Le variabili di sistema vengono impostate con il relativo valore corrente quando si esegue la pipeline. Alcune variabili vengono impostate automaticamente. L'autore o l'utente finale della pipeline modifica il valore di una variabile di sistema prima dell'esecuzione della pipeline.
Le variabili di sistema sono di sola lettura.
Variabili di ambiente
Le variabili di ambiente sono specifiche del sistema operativo in uso. Vengono inseriti in una pipeline in modi specifici della piattaforma. Il formato corrisponde alla formattazione delle variabili di ambiente per la piattaforma di scripting specifica.
Nei sistemi UNIX (macOS e Linux), le variabili di ambiente hanno il formato $NAME. In Windows il formato è %NAME% per batch e $env:NAME in PowerShell.
Anche le variabili definite dal sistema e dall'utente vengono inserite come variabili di ambiente per la piattaforma. Quando le variabili vengono convertite in variabili di ambiente, i nomi delle variabili diventano maiuscoli e i punti diventano caratteri di sottolineatura. Ad esempio, il nome any.variable della variabile diventa il nome $ANY_VARIABLEdella variabile .
Esistono restrizioni di denominazione delle variabili per le variabili di ambiente( ad esempio: non è possibile usare secret all'inizio di un nome di variabile).
Restrizioni di denominazione per le risorse
Le variabili di ambiente e definite dall'utente possono essere costituite da lettere, numeri, .e _ caratteri. Non usare prefissi di variabile riservati dal sistema. Si tratta di: endpoint, secretinput, , pathe securefile. Qualsiasi variabile che inizia con una di queste stringhe (indipendentemente dalla maiuscola) non sarà disponibile per le attività e gli script.
Informazioni sulla sintassi delle variabili
Azure Pipelines supporta tre modi diversi per fare riferimento a variabili: macro, espressione modello ed espressione di runtime. È possibile usare ogni sintassi per uno scopo diverso e ognuna presenta alcune limitazioni.
In una pipeline, le variabili di espressione modello (${{ variables.var }}) vengono elaborate in fase di compilazione prima dell'avvio del runtime. Le variabili di sintassi macro ($(var)) vengono elaborate durante il runtime prima dell'esecuzione di un'attività. Le espressioni di runtime ($[variables.var]) vengono elaborate anche durante il runtime, ma devono essere usate con condizioni ed espressioni. Quando si usa un'espressione di runtime, questa deve assumere l'intero lato destro di una definizione.
In questo esempio è possibile notare che l'espressione modello ha ancora il valore iniziale della variabile dopo l'aggiornamento della variabile. Il valore della variabile di sintassi della macro viene aggiornato. Il valore dell'espressione modello non cambia perché tutte le variabili di espressione modello vengono elaborate in fase di compilazione prima dell'esecuzione delle attività. Al contrario, le variabili di sintassi delle macro valutano prima dell'esecuzione di ogni attività.
variables:
- name: one
value: initialValue
steps:
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one)
displayName: First variable pass
- bash: echo "##vso[task.setvariable variable=one]secondValue"
displayName: Set new variable value
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one) # outputs secondValue
displayName: Second variable pass
Variabili di sintassi macro
La maggior parte degli esempi di documentazione usa la sintassi macro ($(var)). La sintassi delle macro è progettata per interpolare i valori delle variabili negli input delle attività e in altre variabili.
Le variabili con sintassi macro vengono elaborate prima dell'esecuzione di un'attività durante il runtime. Il runtime viene eseguito dopo l'espansione del modello. Quando il sistema rileva un'espressione macro, sostituisce l'espressione con il contenuto della variabile. Se non esiste alcuna variabile con tale nome, l'espressione macro non cambia. Ad esempio, se $(var) non può essere sostituito, $(var) non verrà sostituito da nulla.
Le variabili di sintassi macro rimangono invariate senza alcun valore perché un valore vuoto, ad $() esempio, potrebbe significare qualcosa per l'attività in esecuzione e l'agente non deve presupporre che si voglia sostituire tale valore. Ad esempio, se si usa $(foo) per fare riferimento a una variabile foo in un'attività Bash, la sostituzione di tutte le $() espressioni nell'input nell'attività potrebbe interrompere gli script Bash.
Le variabili di macro vengono espanse solo quando vengono usate per un valore, non come parola chiave. I valori vengono visualizzati sul lato destro di una definizione di pipeline. Di seguito è riportato un valore valido: key: $(value). Il codice seguente non è valido: $(key): value. Le variabili di macro non vengono espanse quando vengono usate per visualizzare un nome di processo inline. È invece necessario utilizzare la displayName proprietà .
Nota
Le variabili di sintassi delle macro vengono espanse solo per stages, jobse steps.
Non è possibile, ad esempio, utilizzare la sintassi macro all'interno di un resource oggetto o trigger.
In questo esempio viene usata la sintassi delle macro con Bash, PowerShell e un'attività script. La sintassi per chiamare una variabile con sintassi macro è la stessa per tutte e tre.
variables:
- name: projectName
value: contoso
steps:
- bash: echo $(projectName)
- powershell: echo $(projectName)
- script: echo $(projectName)
Sintassi dell'espressione modello
È possibile usare la sintassi dell'espressione modello per espandere sia i parametri del modello che le variabili (${{ variables.var }}). Il processo delle variabili modello in fase di compilazione viene sostituito prima dell'avvio del runtime. Le espressioni modello sono progettate per riutilizzare parti di YAML come modelli.
Le variabili di modello si unisseguono automaticamente a stringhe vuote quando non viene trovato un valore di sostituzione. Le espressioni modello, a differenza delle espressioni macro e di runtime, possono essere visualizzate come chiavi (lato sinistro) o valori (lato destro). Di seguito è riportato un valore valido: ${{ variables.key }} : ${{ variables.value }}.
Sintassi delle espressioni di runtime
È possibile usare la sintassi delle espressioni di runtime per le variabili espanse in fase di esecuzione ($[variables.var]). Le variabili di espressione di runtime si unisseguono automaticamente a stringhe vuote quando non viene trovato un valore di sostituzione. Usare espressioni di runtime in condizioni di processo, per supportare l'esecuzione condizionale di processi o intere fasi.
Le variabili di espressione di runtime vengono espanse solo quando vengono usate per un valore, non come parola chiave. I valori vengono visualizzati sul lato destro di una definizione di pipeline. Di seguito è riportato un valore valido: key: $[variables.value]. Il codice seguente non è valido: $[variables.key]: value. L'espressione di runtime deve occupare l'intero lato destro di una coppia chiave-valore. Ad esempio, key: $[variables.value] è valido ma key: $[variables.value] foo non lo è.
| Sintassi | Esempio | Quando viene elaborato? | Dove si espande in una definizione della pipeline? | Come viene eseguito il rendering quando non viene trovato? |
|---|---|---|---|---|
| macro | $(var) |
runtime prima dell'esecuzione di un'attività | value (lato destro) | Stampe $(var) |
| espressione modello | ${{ variables.var }} |
tempo di compilazione | chiave o valore (lato sinistro o destro) | stringa vuota |
| espressione di runtime | $[variables.var] |
runtime | value (lato destro) | stringa vuota |
Quale sintassi è consigliabile usare?
Usare la sintassi della macro se si specifica una stringa sicura o un input di variabile predefinito per un'attività.
Scegliere un'espressione di runtime se si utilizzano condizioni ed espressioni. Tuttavia, non usare un'espressione di runtime se non si vuole che la variabile vuota venga stampata (ad esempio: $[variables.var]). Ad esempio, se si dispone di logica condizionale che si basa su una variabile con un valore specifico o nessun valore. In tal caso, è consigliabile usare un'espressione macro.
In genere, una variabile di modello è lo standard da usare. Sfruttando le variabili del modello, la pipeline inserirà completamente il valore della variabile nella pipeline durante la compilazione della pipeline. Ciò è utile quando si tenta di eseguire il debug delle pipeline. È possibile scaricare i file di log e valutare il valore completamente espanso in cui viene sostituito. Poiché la variabile viene sostituita in, non è consigliabile usare la sintassi del modello per i valori sensibili.
Impostare le variabili nella pipeline
Nel caso più comune, è possibile impostare le variabili e usarle all'interno del file YAML. In questo modo è possibile tenere traccia delle modifiche apportate alla variabile nel sistema di controllo della versione. È anche possibile definire le variabili nell'interfaccia utente delle impostazioni della pipeline (vedere la scheda Classica) e farvi riferimento in YAML.
Di seguito è riportato un esempio che illustra come impostare due variabili configuration e platforme usarle più avanti nei passaggi. Per usare una variabile in un'istruzione YAML, eseguire il wrapping in $(). Le variabili non possono essere usate per definire un oggetto repository in un'istruzione YAML.
# Set variables once
variables:
configuration: debug
platform: x64
steps:
# Use them once
- task: MSBuild@1
inputs:
solution: solution1.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
# Use them again
- task: MSBuild@1
inputs:
solution: solution2.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
Ambiti delle variabili
Nel file YAML è possibile impostare una variabile in vari ambiti:
- A livello radice, per renderlo disponibile per tutti i processi nella pipeline.
- A livello di fase, per renderlo disponibile solo per una fase specifica.
- A livello di processo, per renderlo disponibile solo per un processo specifico.
Quando si definisce una variabile all'inizio di un YAML, la variabile è disponibile per tutti i processi e le fasi della pipeline ed è una variabile globale. Le variabili globali definite in un YAML non sono visibili nell'interfaccia utente delle impostazioni della pipeline.
Le variabili a livello di processo eseguono l'override delle variabili a livello radice e di fase. Le variabili a livello di fase eseguono l'override delle variabili a livello radice.
variables:
global_variable: value # this is available to all jobs
jobs:
- job: job1
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable1: value1 # this is only available in job1
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable1)
- bash: echo $JOB_VARIABLE1 # variables are available in the script environment too
- job: job2
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable2: value2 # this is only available in job2
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable2)
- bash: echo $GLOBAL_VARIABLE
L'output di entrambi i processi è simile al seguente:
# job1
value
value1
value1
# job2
value
value2
value
Specificare le variabili
Negli esempi precedenti la variables parola chiave è seguita da un elenco di coppie chiave-valore.
Le chiavi sono i nomi delle variabili e i valori sono i valori delle variabili.
È disponibile un'altra sintassi, utile quando si vogliono usare modelli per variabili o gruppi di variabili.
Con i modelli, le variabili possono essere definite in un file YAML e incluse in un altro file YAML.
I gruppi di variabili sono un set di variabili che è possibile usare tra più pipeline. Consentono di gestire e organizzare variabili comuni a varie fasi in un'unica posizione.
Usare questa sintassi per i modelli di variabili e i gruppi di variabili a livello radice di una pipeline.
In questa sintassi alternativa, la variables parola chiave accetta un elenco di identificatori di variabile.
Gli identificatori di variabile sono name per una variabile regolare, group per un gruppo di variabili e template per includere un modello di variabile.
Nell'esempio seguente vengono illustrati tutti e tre.
variables:
# a regular variable
- name: myvariable
value: myvalue
# a variable group
- group: myvariablegroup
# a reference to a variable template
- template: myvariabletemplate.yml
Altre informazioni sul riutilizzo delle variabili con i modelli.
Accedere alle variabili tramite l'ambiente
Si noti che le variabili vengono rese disponibili anche agli script tramite variabili di ambiente. La sintassi per l'uso di queste variabili di ambiente dipende dal linguaggio di scripting.
Il nome è maiuscolo e viene . sostituito con ._ Questa operazione viene inserita automaticamente nell'ambiente di processo. Di seguito sono riportati alcuni esempi.
- Script batch:
%VARIABLE_NAME% - Script di PowerShell:
$env:VARIABLE_NAME - Script Bash:
$VARIABLE_NAME
Importante
Le variabili predefinite che contengono percorsi di file vengono convertite nello stile appropriato (stile Windows C:\foo\ rispetto allo stile Unix /foo/) in base al tipo di host e al tipo di shell dell'agente. Se si eseguono attività di script bash in Windows, è consigliabile usare il metodo della variabile di ambiente per accedere a queste variabili anziché al metodo della variabile della pipeline per assicurarsi di avere lo stile corretto del percorso del file.
Impostare le variabili segrete
Suggerimento
Le variabili segrete non vengono esportate automaticamente come variabili di ambiente. Per usare le variabili segrete negli script, eseguirne il mapping esplicito alle variabili di ambiente. Per altre informazioni, vedere Impostare le variabili segrete.
Non impostare le variabili segrete nel file YAML. I sistemi operativi spesso registrano i comandi per i processi eseguiti e non si vuole che il log includa un segreto passato come input. Usare l'ambiente dello script o eseguire il mapping della variabile all'interno del variables blocco per passare segreti alla pipeline.
Nota
Azure Pipelines si impegna a mascherare i segreti durante l'emissione di dati nei log della pipeline, pertanto è possibile visualizzare variabili aggiuntive e dati mascherati nell'output e nei log che non sono impostati come segreti.
È necessario impostare le variabili segrete nell'interfaccia utente delle impostazioni della pipeline per la pipeline. Queste variabili hanno come ambito la pipeline in cui sono impostate. È anche possibile impostare le variabili segrete nei gruppi di variabili.
Per impostare i segreti nell'interfaccia Web, seguire questa procedura:
- Passare alla pagina Pipeline, selezionare la pipeline appropriata e quindi selezionare Modifica.
- Individuare le Variabili per la pipeline.
- Aggiungere o aggiornare la variabile.
- Selezionare l'opzione Mantieni questo valore segreto per archiviare la variabile in modo crittografato.
- Salvare la pipeline.
Le variabili segrete vengono crittografate quando sono inattive con una chiave RSA a 2048 bit. I segreti sono disponibili nell'agente per le attività e gli script da usare. Prestare attenzione a chi ha accesso per modificare la pipeline.
Importante
Si fa un tentativo di mascherare i segreti dalla visualizzazione nell'output di Azure Pipelines, ma è comunque necessario adottare precauzioni. Non richiamare mai i segreti come output. Alcuni sistemi operativi registrano gli argomenti della riga di comando. Non passare mai i segreti sulla riga di comando. È invece consigliabile eseguire il mapping dei segreti alle variabili di ambiente.
Non mascheramo mai le sottostringhe dei segreti. Se, ad esempio, "abc123" viene impostato come segreto, "abc" non viene mascherato dai log. Lo scopo è evitare di mascherare i segreti a un livello troppo granulare, rendendo illeggibili i log. Per questo motivo, i segreti non dovrebbero contenere dati strutturati. Se, ad esempio, "{ "foo": "bar" }" è impostato come segreto, "bar" non viene mascherato nei log.
A differenza di una variabile normale, non vengono decrittografati automaticamente nelle variabili di ambiente per gli script. È necessario eseguire il mapping esplicito delle variabili segrete.
L'esempio seguente illustra come eseguire il mapping e usare una variabile segreta denominata mySecret negli script di PowerShell e Bash. Vengono definite due variabili globali. GLOBAL_MYSECRET viene assegnato il valore di una variabile mySecretsegreta e GLOBAL_MY_MAPPED_ENV_VAR viene assegnato il valore di una variabile nonSecretVariablenon segreta . A differenza di una variabile di pipeline normale, non esiste alcuna variabile di ambiente denominata MYSECRET.
L'attività di PowerShell esegue uno script per stampare le variabili.
$(mySecret): si tratta di un riferimento diretto alla variabile segreta e funziona.$env:MYSECRET: tenta di accedere alla variabile segreta come variabile di ambiente, che non funziona perché le variabili segrete non vengono mappate automaticamente alle variabili di ambiente.$env:GLOBAL_MYSECRET: tenta di accedere alla variabile segreta tramite una variabile globale, che non funziona perché non è possibile eseguire il mapping delle variabili segrete in questo modo.$env:GLOBAL_MY_MAPPED_ENV_VAR: accede alla variabile non segreta tramite una variabile globale, che funziona.$env:MY_MAPPED_ENV_VAR: accede alla variabile segreta tramite una variabile di ambiente specifica dell'attività, che è il modo consigliato per eseguire il mapping delle variabili segrete alle variabili di ambiente.
variables:
GLOBAL_MYSECRET: $(mySecret) # this will not work because the secret variable needs to be mapped as env
GLOBAL_MY_MAPPED_ENV_VAR: $(nonSecretVariable) # this works because it's not a secret.
steps:
- powershell: |
Write-Host "Using an input-macro works: $(mySecret)"
Write-Host "Using the env var directly does not work: $env:MYSECRET"
Write-Host "Using a global secret var mapped in the pipeline does not work either: $env:GLOBAL_MYSECRET"
Write-Host "Using a global non-secret var mapped in the pipeline works: $env:GLOBAL_MY_MAPPED_ENV_VAR"
Write-Host "Using the mapped env var for this task works and is recommended: $env:MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
- bash: |
echo "Using an input-macro works: $(mySecret)"
echo "Using the env var directly does not work: $MYSECRET"
echo "Using a global secret var mapped in the pipeline does not work either: $GLOBAL_MYSECRET"
echo "Using a global non-secret var mapped in the pipeline works: $GLOBAL_MY_MAPPED_ENV_VAR"
echo "Using the mapped env var for this task works and is recommended: $MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
L'output di entrambe le attività nello script precedente sarà simile al seguente:
Using an input-macro works: ***
Using the env var directly does not work:
Using a global secret var mapped in the pipeline does not work either:
Using a global non-secret var mapped in the pipeline works: foo
Using the mapped env var for this task works and is recommended: ***
È anche possibile usare variabili segrete al di fuori degli script. Ad esempio, è possibile eseguire il mapping delle variabili segrete alle attività usando la variables definizione . Questo esempio illustra come usare le variabili $(vmsUser) segrete e $(vmsAdminPass) in un'attività di copia file di Azure.
variables:
VMS_USER: $(vmsUser)
VMS_PASS: $(vmsAdminPass)
pool:
vmImage: 'ubuntu-latest'
steps:
- task: AzureFileCopy@4
inputs:
SourcePath: 'my/path'
azureSubscription: 'my-subscription'
Destination: 'AzureVMs'
storage: 'my-storage'
resourceGroup: 'my-rg'
vmsAdminUserName: $(VMS_USER)
vmsAdminPassword: $(VMS_PASS)
Fare riferimento alle variabili segrete nei gruppi di variabili
Questo esempio illustra come fare riferimento a un gruppo di variabili nel file YAML e come aggiungere variabili all'interno di YAML. Esistono due variabili usate dal gruppo di variabili: user e token. La token variabile è segreta ed è mappata alla variabile $env:MY_MAPPED_TOKEN di ambiente in modo che possa essere fatto riferimento in YAML.
Questo YAML esegue una chiamata REST per recuperare un elenco di versioni e restituisce il risultato.
variables:
- group: 'my-var-group' # variable group
- name: 'devopsAccount' # new variable defined in YAML
value: 'contoso'
- name: 'projectName' # new variable defined in YAML
value: 'contosoads'
steps:
- task: PowerShell@2
inputs:
targetType: 'inline'
script: |
# Encode the Personal Access Token (PAT)
# $env:USER is a normal variable in the variable group
# $env:MY_MAPPED_TOKEN is a mapped secret variable
$base64AuthInfo = [Convert]::ToBase64String([Text.Encoding]::ASCII.GetBytes(("{0}:{1}" -f $env:USER,$env:MY_MAPPED_TOKEN)))
# Get a list of releases
$uri = "https://vsrm.dev.azure.com/$(devopsAccount)/$(projectName)/_apis/release/releases?api-version=5.1"
# Invoke the REST call
$result = Invoke-RestMethod -Uri $uri -Method Get -ContentType "application/json" -Headers @{Authorization=("Basic {0}" -f $base64AuthInfo)}
# Output releases in JSON
Write-Host $result.value
env:
MY_MAPPED_TOKEN: $(token) # Maps the secret variable $(token) from my-var-group
Importante
Per impostazione predefinita con i repository GitHub, le variabili segrete associate alla pipeline non vengono rese disponibili per le compilazioni di richieste pull dei fork. Per altre informazioni, vedere Contributi dai fork.
Condividere variabili tra pipeline
Per condividere variabili tra più pipeline nel progetto, usare l'interfaccia Web. In Libreria usare gruppi di variabili.
Usare le variabili di output dalle attività
Alcune attività definiscono le variabili di output, che è possibile utilizzare nei passaggi downstream, nei processi e nelle fasi. In YAML è possibile accedere alle variabili tra processi e fasi usando le dipendenze.
Quando si fa riferimento a processi matrice nelle attività downstream, è necessario usare una sintassi diversa. Vedere Impostare una variabile di output multi-processo. È anche necessario usare una sintassi diversa per le variabili nei processi di distribuzione. Vedere Supporto per le variabili di output nei processi di distribuzione.
Alcune attività definiscono le variabili di output, che è possibile utilizzare nei passaggi downstream e nei processi all'interno della stessa fase. In YAML è possibile accedere alle variabili tra i processi usando le dipendenze.
- Per fare riferimento a una variabile da un'attività diversa all'interno dello stesso processo, usare
TASK.VARIABLE. - Per fare riferimento a una variabile da un'attività da un processo diverso, usare
dependencies.JOB.outputs['TASK.VARIABLE'].
Nota
Per impostazione predefinita, ogni fase di una pipeline dipende da quella appena precedente nel file YAML. Se è necessario fare riferimento a una fase che non è immediatamente precedente a quella corrente, è possibile eseguire l'override di questa impostazione predefinita automatica aggiungendo una dependsOn sezione alla fase.
Nota
Negli esempi seguenti viene usata la sintassi della pipeline standard. Se si usano pipeline di distribuzione, la sintassi delle variabili variabili e condizionali sarà diversa. Per informazioni sulla sintassi specifica da usare, vedere Processi di distribuzione.
Per questi esempi, si supponga di avere un'attività denominata MyTask, che imposta una variabile di output denominata MyVar.
Altre informazioni sulla sintassi in Espressioni - Dipendenze.
Usare gli output nello stesso processo
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- script: echo $(ProduceVar.MyVar) # this step uses the output variable
Usare gli output in un processo diverso
jobs:
- job: A
steps:
# assume that MyTask generates an output variable called "MyVar"
# (you would learn that from the task's documentation)
- task: MyTask@1
name: ProduceVar # because we're going to depend on it, we need to name the step
- job: B
dependsOn: A
variables:
# map the output variable from A into this job
varFromA: $[ dependencies.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
Usare gli output in un passaggio diverso
Per usare l'output da una fase diversa, il formato per fare riferimento alle variabili è stageDependencies.STAGE.JOB.outputs['TASK.VARIABLE']. A livello di fase, ma non a livello di processo, è possibile usare queste variabili in condizioni.
Le variabili di output sono disponibili solo nella fase downstream successiva. Se più fasi utilizzano la stessa variabile di output, usare la dependsOn condizione .
stages:
- stage: One
jobs:
- job: A
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- stage: Two
dependsOn:
- One
jobs:
- job: B
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
- stage: Three
dependsOn:
- One
- Two
jobs:
- job: C
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
È anche possibile passare variabili tra le fasi con un input di file. A tale scopo, è necessario definire le variabili nella seconda fase a livello di processo e quindi passare le variabili come env: input.
## script-a.sh
echo "##vso[task.setvariable variable=sauce;isOutput=true]crushed tomatoes"
## script-b.sh
echo 'Hello file version'
echo $skipMe
echo $StageSauce
## azure-pipelines.yml
stages:
- stage: one
jobs:
- job: A
steps:
- task: Bash@3
inputs:
filePath: 'script-a.sh'
name: setvar
- bash: |
echo "##vso[task.setvariable variable=skipsubsequent;isOutput=true]true"
name: skipstep
- stage: two
jobs:
- job: B
variables:
- name: StageSauce
value: $[ stageDependencies.one.A.outputs['setvar.sauce'] ]
- name: skipMe
value: $[ stageDependencies.one.A.outputs['skipstep.skipsubsequent'] ]
steps:
- task: Bash@3
inputs:
filePath: 'script-b.sh'
name: fileversion
env:
StageSauce: $(StageSauce) # predefined in variables section
skipMe: $(skipMe) # predefined in variables section
- task: Bash@3
inputs:
targetType: 'inline'
script: |
echo 'Hello inline version'
echo $(skipMe)
echo $(StageSauce)
L'output delle fasi della pipeline precedente è simile al seguente:
Hello inline version
true
crushed tomatoes
Elencare le variabili
È possibile elencare tutte le variabili nella pipeline con il comando az pipelines variable list . Per iniziare, vedere Introduzione all'interfaccia della riga di comando di Azure DevOps.
az pipelines variable list [--org]
[--pipeline-id]
[--pipeline-name]
[--project]
Parametri
- org: URL dell'organizzazione di Azure DevOps. È possibile configurare l'organizzazione predefinita usando
az devops configure -d organization=ORG_URL. Obbligatorio se non è configurato come predefinito o prelevato tramitegit config. Esempio:--org https://dev.azure.com/MyOrganizationName/. - pipeline-id: obbligatorio se pipeline-name non viene specificato. ID della pipeline.
- pipeline-name: obbligatorio se pipeline-id non viene fornito, ma ignorato se viene specificato pipeline-id . Nome della pipeline.
- project: nome o ID del progetto. È possibile configurare il progetto predefinito usando
az devops configure -d project=NAME_OR_ID. Obbligatorio se non è configurato come predefinito o prelevato tramitegit config.
Esempio
Il comando seguente elenca tutte le variabili nella pipeline con ID 12 e mostra il risultato in formato tabella.
az pipelines variable list --pipeline-id 12 --output table
Name Allow Override Is Secret Value
------------- ---------------- ----------- ------------
MyVariable False False platform
NextVariable False True platform
Configuration False False config.debug
Impostare variabili negli script
Gli script possono definire le variabili usate in un secondo momento nei passaggi successivi della pipeline. Tutte le variabili impostate da questo metodo vengono considerate come stringhe. Per impostare una variabile da uno script, usare una sintassi dei comandi e stamparla in stdout.
Impostare una variabile con ambito processo da uno script
Per impostare una variabile da uno script, usare il task.setvariable comando di registrazione. In questo modo vengono aggiornate le variabili di ambiente per i processi successivi. I processi successivi hanno accesso alla nuova variabile con la sintassi macro e nelle attività come variabili di ambiente.
Se issecret è true, il valore della variabile verrà salvato come segreto e mascherato dal log. Per altre informazioni sulle variabili segrete, vedere Comandi di registrazione.
steps:
# Create a variable
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes" # remember to use double quotes
# Use the variable
# "$(sauce)" is replaced by the contents of the `sauce` variable by Azure Pipelines
# before handing the body of the script to the shell.
- bash: |
echo my pipeline variable is $(sauce)
I passaggi successivi avranno anche la variabile della pipeline aggiunta al proprio ambiente. Non è possibile usare la variabile nel passaggio definito.
steps:
# Create a variable
# Note that this does not update the environment of the current script.
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes"
# An environment variable called `SAUCE` has been added to all downstream steps
- bash: |
echo "my environment variable is $SAUCE"
- pwsh: |
Write-Host "my environment variable is $env:SAUCE"
Output della pipeline precedente.
my environment variable is crushed tomatoes
my environment variable is crushed tomatoes
Impostare una variabile di output multi-processo
Se si vuole rendere disponibile una variabile per i processi futuri, è necessario contrassegnarla come variabile di output usando isOutput=true. È quindi possibile eseguirne il mapping in processi futuri usando la $[] sintassi e includendo il nome del passaggio che imposta la variabile. Le variabili di output multi-processo funzionano solo per i processi nella stessa fase.
Per passare variabili ai processi in fasi diverse, usare la sintassi delle dipendenze della fase.
Nota
Per impostazione predefinita, ogni fase di una pipeline dipende da quella appena precedente nel file YAML. Di conseguenza, ogni fase può usare le variabili di output della fase precedente. Per accedere ad altre fasi, sarà necessario modificare il grafico delle dipendenze, ad esempio, se la fase 3 richiede una variabile dalla fase 1, sarà necessario dichiarare una dipendenza esplicita nella fase 1.
Quando si crea una variabile di output multi-processo, è necessario assegnare l'espressione a una variabile. In questo YAML, $[ dependencies.A.outputs['setvarStep.myOutputVar'] ] viene assegnato alla variabile $(myVarFromJobA).
jobs:
# Set an output variable from job A
- job: A
pool:
vmImage: 'windows-latest'
steps:
- powershell: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable into job B
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobA: $[ dependencies.A.outputs['setvarStep.myOutputVar'] ] # map in the variable
# remember, expressions require single quotes
steps:
- script: echo $(myVarFromJobA)
name: echovar
Output della pipeline precedente.
this is the value
this is the value
Se si imposta una variabile da una fase a un'altra, usare stageDependencies.
stages:
- stage: A
jobs:
- job: A1
steps:
- bash: echo "##vso[task.setvariable variable=myStageOutputVar;isOutput=true]this is a stage output var"
name: printvar
- stage: B
dependsOn: A
variables:
myVarfromStageA: $[ stageDependencies.A.A1.outputs['printvar.myStageOutputVar'] ]
jobs:
- job: B1
steps:
- script: echo $(myVarfromStageA)
Se si imposta una variabile da una matrice o una sezione, per fare riferimento alla variabile quando si accede da un processo downstream, è necessario includere:
- Il nome del processo.
- Il passaggio.
jobs:
# Set an output variable from a job with a matrix
- job: A
pool:
vmImage: 'ubuntu-latest'
strategy:
maxParallel: 2
matrix:
debugJob:
configuration: debug
platform: x64
releaseJob:
configuration: release
platform: x64
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the $(configuration) value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the debug job
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobADebug: $[ dependencies.A.outputs['debugJob.setvarStep.myOutputVar'] ]
steps:
- script: echo $(myVarFromJobADebug)
name: echovar
jobs:
# Set an output variable from a job with slicing
- job: A
pool:
vmImage: 'ubuntu-latest'
parallel: 2 # Two slices
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the slice $(system.jobPositionInPhase) value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobsA1: $[ dependencies.A.outputs['job1.setvarStep.myOutputVar'] ]
steps:
- script: "echo $(myVarFromJobsA1)"
name: echovar
Assicurarsi di anteporre il nome del processo alle variabili di output di un processo di distribuzione . In questo caso, il nome del processo è A:
jobs:
# Set an output variable from a deployment
- deployment: A
pool:
vmImage: 'ubuntu-latest'
environment: staging
strategy:
runOnce:
deploy:
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the deployment variable value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromDeploymentJob: $[ dependencies.A.outputs['A.setvarStep.myOutputVar'] ]
steps:
- bash: "echo $(myVarFromDeploymentJob)"
name: echovar
 Impostare le
Impostare le  Impostare le
Impostare le  Impostare le
Impostare le Impostare le variabili usando espressioni
È possibile impostare una variabile usando un'espressione. È già stato rilevato un caso di questo tipo per impostare una variabile sull'output di un altro processo precedente.
- job: B
dependsOn: A
variables:
myVarFromJobsA1: $[ dependencies.A.outputs['job1.setvarStep.myOutputVar'] ] # remember to use single quotes
È possibile usare una qualsiasi delle espressioni supportate per impostare una variabile. Di seguito è riportato un esempio di impostazione di una variabile da usare come contatore che inizia da 100, viene incrementato di 1 per ogni esecuzione e viene reimpostato su 100 ogni giorno.
jobs:
- job:
variables:
a: $[counter(format('{0:yyyyMMdd}', pipeline.startTime), 100)]
steps:
- bash: echo $(a)
Per altre informazioni su contatori, dipendenze e altre espressioni, vedere espressioni.
Configurare le variabili impostabili per i passaggi
È possibile definire settableVariables all'interno di un passaggio o specificare che non è possibile impostare variabili.
In questo esempio lo script non può impostare una variabile.
steps:
- script: echo This is a step
target:
settableVariables: none
In questo esempio lo script consente la variabile sauce ma non la variabile secretSauce. Nella pagina di esecuzione della pipeline verrà visualizzato un avviso.

steps:
- bash: |
echo "##vso[task.setvariable variable=Sauce;]crushed tomatoes"
echo "##vso[task.setvariable variable=secretSauce;]crushed tomatoes with garlic"
target:
settableVariables:
- sauce
name: SetVars
- bash:
echo "Sauce is $(sauce)"
echo "secretSauce is $(secretSauce)"
name: OutputVars
Elementi consentiti nel tempo di attesa
Se nel blocco di un file YAML viene visualizzata variables una variabile, il relativo valore è fisso e non può essere sottoposto a override in fase di coda. La procedura consigliata consiste nel definire le variabili in un file YAML, ma in alcuni casi questo non ha senso. Ad esempio, è possibile definire una variabile privata e non avere la variabile esposta nel file YAML. In alternativa, potrebbe essere necessario impostare manualmente un valore di variabile durante l'esecuzione della pipeline.
Sono disponibili due opzioni per la definizione dei valori della coda. È possibile definire una variabile nell'interfaccia utente e selezionare l'opzione Consenti agli utenti di eseguire l'override di questo valore durante l'esecuzione di questa pipeline oppure usare i parametri di runtime. Se la variabile non è un segreto, è consigliabile usare i parametri di runtime.
Per impostare una variabile in fase di coda, aggiungere una nuova variabile all'interno della pipeline e selezionare l'opzione di override.
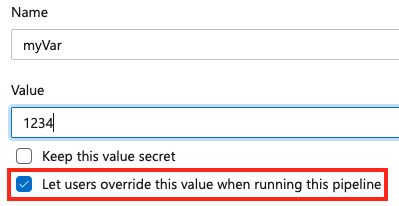
Per consentire l'impostazione di una variabile in fase di coda, assicurarsi che la variabile non venga visualizzata anche nel variables blocco di una pipeline o di un processo. Se si definisce una variabile sia nel blocco di variabili di un YAML che nell'interfaccia utente, il valore in YAML ha priorità.

Espansione delle variabili
Quando si imposta una variabile con lo stesso nome in più ambiti, si applica la precedenza seguente (prima di tutto la precedenza più alta).
- Variabile a livello di processo impostata nel file YAML
- Variabile a livello di fase impostata nel file YAML
- Variabile a livello di pipeline impostata nel file YAML
- Variabile impostata nel tempo di attesa
- Variabile della pipeline impostata nell'interfaccia utente delle impostazioni della pipeline
Nell'esempio seguente la stessa variabile viene impostata a a livello di pipeline e di processo nel file YAML. Viene anche impostato in un gruppo Gdi variabili e come variabile nell'interfaccia utente delle impostazioni della pipeline.
variables:
a: 'pipeline yaml'
stages:
- stage: one
displayName: one
variables:
- name: a
value: 'stage yaml'
jobs:
- job: A
variables:
- name: a
value: 'job yaml'
steps:
- bash: echo $(a) # This will be 'job yaml'
Quando si imposta una variabile con lo stesso nome nello stesso ambito, l'ultimo valore impostato ha la precedenza.
stages:
- stage: one
displayName: Stage One
variables:
- name: a
value: alpha
- name: a
value: beta
jobs:
- job: I
displayName: Job I
variables:
- name: b
value: uno
- name: b
value: dos
steps:
- script: echo $(a) #outputs beta
- script: echo $(b) #outputs dos
Nota
Quando si imposta una variabile nel file YAML, non definirla nell'editor Web come impostabile in fase di coda. Attualmente non è possibile modificare le variabili impostate nel file YAML in fase di coda. Se è necessario impostare una variabile in fase di coda, non impostarla nel file YAML.
Le variabili vengono espanse una volta all'avvio dell'esecuzione e di nuovo all'inizio di ogni passaggio. Ad esempio:
jobs:
- job: A
variables:
a: 10
steps:
- bash: |
echo $(a) # This will be 10
echo '##vso[task.setvariable variable=a]20'
echo $(a) # This will also be 10, since the expansion of $(a) happens before the step
- bash: echo $(a) # This will be 20, since the variables are expanded just before the step
Nell'esempio precedente sono presenti due passaggi. L'espansione di $(a) si verifica una volta all'inizio del processo e una volta all'inizio di ognuno dei due passaggi.
Poiché le variabili vengono espanse all'inizio di un processo, non è possibile usarle in una strategia. Nell'esempio seguente non è possibile usare la variabile a per espandere la matrice del processo, perché la variabile è disponibile solo all'inizio di ogni processo espanso.
jobs:
- job: A
variables:
a: 10
strategy:
matrix:
x:
some_variable: $(a) # This does not work
Se la variabile è una variabile a di output di un processo precedente, è possibile usarla in un processo futuro.
- job: A
steps:
- powershell: echo "##vso[task.setvariable variable=a;isOutput=true]10"
name: a_step
# Map the variable into job B
- job: B
dependsOn: A
variables:
some_variable: $[ dependencies.A.outputs['a_step.a'] ]
Espansione ricorsiva
Nell'agente le variabili a cui si fa riferimento usando $( ) la sintassi vengono espanse in modo ricorsivo.
Ad esempio:
variables:
myInner: someValue
myOuter: $(myInner)
steps:
- script: echo $(myOuter) # prints "someValue"
displayName: Variable is $(myOuter) # display name is "Variable is someValue"