Ottenere consigli di Azure per eseguire la migrazione del database di SQL Server
L'estensione Azure SQL Migration per Azure Data Studio consente di valutare i requisiti del database per comprendere l'idoneità per la migrazione, ottenere i consigli per lo SKU di dimensioni appropriate per le risorse di Azure ed eseguire la migrazione del database di SQL Server ad Azure.
Informazioni su come usare questa esperienza unificata, raccogliendo i dati sulle prestazioni dall'istanza di SQL Server di origine per ottenere consigli di Azure di dimensioni appropriate per le destinazioni Azure SQL.
Panoramica
Prima di eseguire la migrazione ad Azure SQL, è possibile usare l'estensione Migrazione Azure SQL Data Studio per generare consigli di dimensioni appropriate per database SQL di Azure, Istanza gestita di SQL di Azure e SQL Server nelle destinazioni Macchine virtuali di Azure. Lo strumento consente di raccogliere dati sulle prestazioni dall'istanza SQL di origine (in esecuzione in locale o altro cloud) e di consigliare una configurazione di calcolo e archiviazione per soddisfare le esigenze del carico di lavoro.
Il diagramma presenta il workflow per i consigli di Azure nell'estensione Migrazione Azure SQL per Azure Data Studio:

Nota
Valutazione e funzionalità consiglio di Azure nell'estensione Migrazione Azure SQL per Azure Data Studio supporta le istanze di SQL Server di origine in esecuzione in Windows o Linux.
Prerequisiti
Per iniziare a usare i consigli di Azure per la migrazione del database di SQL Server, è necessario soddisfare i prerequisiti seguenti:
Installare l'estensione di Migrazione Azure SQL dal Marketplace Azure Data Studio.
Assicurarsi che l’accesso usato per connettere l'istanza di SQL Server di origine disponga delle autorizzazioni minime.
Origini e destinazioni supportate
È possibile generare consigli di Azure per le versioni di SQL Server seguenti:
- È supportato SQL Server 2008 e versioni successive su Windows o Linux.
- SQL Server in esecuzione in altri cloud potrebbe essere supportato, ma l'accuratezza dei risultati potrebbe variare
È possibile generare consigli di Azure per le destinazioni Azure SQL seguenti:
- Database SQL di Azure
- Serie hardware: serie Standard (Gen5)
- Livelli di servizio: utilizzo generico, business critical o Hyperscale
- Istanza gestita di SQL di Azure
- Serie hardware: serie Standard (Gen5), serie Premium e Premium ottimizzata per la memoria
- Livelli di servizio: utilizzo generico, Business critical
- SQL Server nella Macchina virtuale di Azure
- Serie VM: utilizzo generico, ottimizzata per la memoria
- Serie di archiviazione: SSD Premium
Raccolta dati sulle prestazioni
Prima di poter generare consigli, è necessario raccogliere i dati sulle prestazioni dall'istanza di SQL Server di origine. Durante questo passaggio di raccolta dati, vengono eseguite query su più viste di sistema dinamiche (DMV) dell'istanza di SQL Server per acquisire le caratteristiche delle prestazioni del carico di lavoro. Lo strumento acquisisce le metriche, tra cui CPU, memoria, archiviazione e utilizzo di I/O ogni 30 secondi e salva i contatori delle prestazioni in locale nel computer come set di file CSV.
Livello di istanza
Questi dati sulle prestazioni vengono raccolti una volta per ogni istanza di SQL Server:
| Dimensione delle prestazioni | Descrizione | Viste a gestione dinamica (DMV) |
|---|---|---|
SqlInstanceCpuPercent |
Quantità di CPU usata dal processo di SQL Server, come percentuale | sys.dm_os_ring_buffers |
PhysicalMemoryInUse |
Footprint complessivo della memoria del processo di SQL Server | sys.dm_os_process_memory |
MemoryUtilizationPercentage |
Utilizzo della memoria di SQL Server | sys.dm_os_process_memory |
A livello di database
| Dimensione delle prestazioni | Descrizione | Viste a gestione dinamica (DMV) |
|---|---|---|
DatabaseCpuPercent |
Percentuale totale di CPU usata da un database | sys.dm_exec_query_stats |
CachedSizeInMb |
Dimensioni totali in megabyte di cache usate da un database | sys.dm_os_buffer_descriptors |
Livello file
| Dimensione delle prestazioni | Descrizione | Viste a gestione dinamica (DMV) |
|---|---|---|
ReadIOInMb |
Numero totale di megabyte letti da questo file | sys.dm_io_virtual_file_stats |
WriteIOInMb |
Numero totale di megabyte scritti nel file | sys.dm_io_virtual_file_stats |
NumOfReads |
Numero totale di letture eseguite in questo file | sys.dm_io_virtual_file_stats |
NumOfWrites |
Numero totale di scritture eseguite in questo file | sys.dm_io_virtual_file_stats |
ReadLatency |
Latenza di lettura di I/O in questo file | sys.dm_io_virtual_file_stats |
WriteLatency |
Latenza di scrittura di I/O in questo file | sys.dm_io_virtual_file_stats |
Prima di generare un consiglio, sono necessari almeno 10 minuti di raccolta dei dati, ma per valutare con precisione il carico di lavoro, è consigliabile eseguire la raccolta dati per una durata sufficientemente lunga per acquisire sia l'utilizzo on-peak che off-peak.
Per avviare il processo di raccolta dati, iniziare connettendosi all'istanza SQL di origine in Azure Data Studio, quindi avviare la procedura guidata di migrazione SQL. Al passaggio 2, selezionare "Ottieni consiglio di Azure". Selezionare "Raccogli dati sulle prestazioni ora" e selezionare una cartella nel computer in cui verranno salvati i dati raccolti.
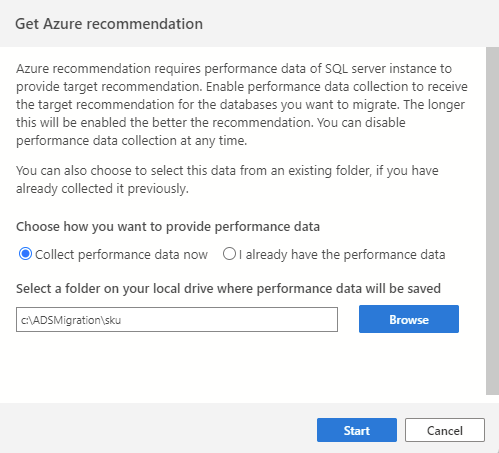
Il processo di raccolta dati viene eseguito per 10 minuti per generare il primo consiglio. È importante avviare il processo di raccolta dati quando il carico di lavoro del database attivo riflette l'utilizzo simile agli scenari di produzione.
Dopo aver generato il primo consiglio, è possibile continuare a eseguire la raccolta dati per continuare il processo di raccolta dati e affinare il consiglio SKU. Questa opzione è particolarmente utile se i criteri di utilizzo variano nel tempo.
Il processo di raccolta dati inizia dopo aver selezionato Avvia. Ogni 10 minuti, i punti dati raccolti vengono aggregati e il numero massimo, medio e varianza di ogni contatore verrà scritto su disco in un set di tre file CSV.
In genere viene visualizzato un set di file CSV con i suffissi seguenti nella cartella selezionata:
SQLServerInstance_CommonDbLevel_Counters.csv: contiene dati di configurazione statici relativi al layout e ai metadati del file di database.SQLServerInstance_CommonInstanceLevel_Counters.csv: contiene dati statici sulla configurazione hardware dell'istanza del server.SQLServerInstance_PerformanceAggregated_Counters.csv: contiene dati aggregati sulle prestazioni aggiornati di frequente.
Durante questo periodo, lasciare aperto Azure Data Studio, anche se è possibile continuare con altre operazioni. In qualsiasi momento, è possibile arrestare il processo di raccolta dati restituendo a questa pagina e selezionando Arresta raccolta dati.
Generare consigli di dimensioni appropriate
Se sono già stati raccolti dati sulle prestazioni da una sessione precedente o usando uno strumento diverso, ad esempio Database Migration Assistant, è possibile importare eventuali dati sulle prestazioni esistenti selezionando l'opzione Ho già i dati sulle prestazioni. Passare alla cartella in cui vengono salvati i dati sulle prestazioni (tre file .csv) e selezionare Avvia per avviare il processo di consiglio.
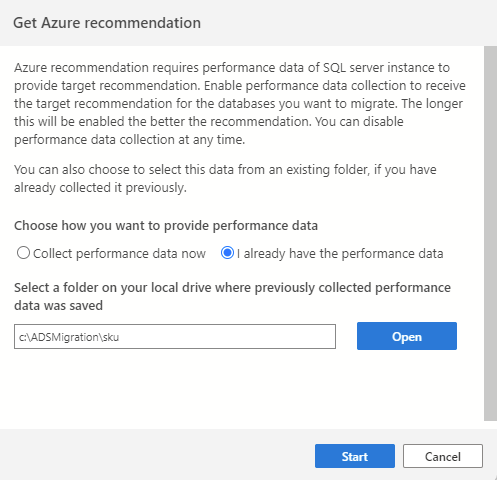
Il passaggio uno procedura guidata per la migrazione SQL richiede di selezionare un set di database da valutare e questi sono gli unici database che verranno presi in considerazione durante il processo di consiglio.
Tuttavia, il processo di raccolta dei dati sulle prestazioni raccoglie i contatori delle prestazioni per tutti i database dall'istanza di SQL Server di origine, non solo quelli selezionati.
Ciò significa che i dati sulle prestazioni raccolti in precedenza possono essere usati per rigenerare ripetutamente i consigli per un sottoinsieme diverso di database specificando un elenco diverso al passaggio 1.
Parametri dei consigli
Esistono più impostazioni configurabili che potrebbero influire sui consigli.

Selezionare l'opzione Modifica parametri per regolare questi parametri in base alle proprie esigenze.
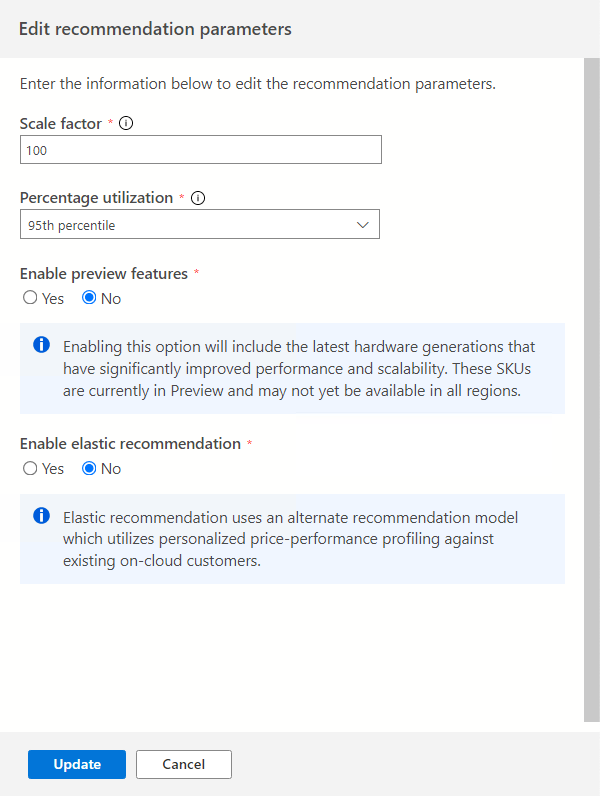
Fattore di scala:
Questa opzione consente di fornire un buffer da applicare a ogni dimensione di prestazioni. Questa opzione tiene conto di aspetti quali l'utilizzo stagionale, una cronologia ridotta delle prestazioni e il probabile aumento dell'utilizzo futuro. Ad esempio, se si determina che un requisito di CPU a quattro vCore ha un fattore di scala del 150%, il vero requisito di CPU è di sei vCore.
Il volume del fattore di scala predefinito è 100%.
Percentuale di utilizzo:
Percentile dei punti dati da usare come dati di prestazione durante l'aggregazione dei dati.
Il valore predefinito è il 95° percentile.
Abilita funzionalità di anteprima:
Questa opzione consente di consigliare le configurazioni che potrebbero non essere ancora disponibili a livello generale per tutti gli utenti in tutte le aree.
Per impostazione predefinita, questa opzione è disabilitata.
Abilitare il consiglio elastico:
Questa opzione usa un modello di consiglio alternativo che usa la profilatura personalizzata delle prestazioni dei prezzi rispetto ai clienti esistenti nel cloud.
Per impostazione predefinita, questa opzione è disabilitata.
Il processo di raccolta dati termina se si chiude Azure Data Studio. I dati raccolti fino a quel punto vengono salvati nella cartella.
Se si chiude Azure Data Studio mentre è in corso la raccolta dati, usare una delle opzioni seguenti per riavviarla:
Riaprire Azure Data Studio e importare i file di dati salvati nella cartella locale. Generare quindi un consiglio basato sui dati raccolti.
Riaprire Azure Data Studio e avviare di nuovo la raccolta dati usando la procedura guidata di migrazione.
Autorizzazioni minime
Per eseguire query sulle viste di sistema necessarie per la raccolta dei dati sulle prestazioni, sono necessarie autorizzazioni specifiche per l’accesso di SQL Server usato per questa attività. È possibile creare un utente con privilegi minimi per la raccolta dei dati di valutazione e prestazioni usando lo script seguente:
-- Create a login to run the assessment
USE master;
GO
CREATE LOGIN [assessment]
WITH PASSWORD = '<STRONG PASSWORD>';
-- Create user in every database other than TempDB and model and provide minimal read-only permissions
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''TempDB'',''model''))
BEGIN TRY
CREATE USER [assessment] FOR LOGIN [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''tempdb'',''model''))
BEGIN TRY
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''tempdb'',''model''))
BEGIN TRY
GRANT VIEW DATABASE STATE TO [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
-- Provide server level read-only permissions
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment];
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment];
GRANT EXECUTE ON OBJECT::sys.xp_regenumkeys TO [assessment];
GRANT VIEW DATABASE STATE TO assessment;
GRANT VIEW SERVER STATE TO assessment;
GRANT VIEW ANY DEFINITION TO assessment;
-- Provide msdb specific permissions
USE msdb;
GO
GRANT EXECUTE ON [msdb].[dbo].[agent_datetime] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobsteps] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syssubsystems] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobhistory] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syscategories] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobs] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmaintplan_plans] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syscollector_collection_sets] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_profile] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_profileaccount] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_account] TO [assessment];
-- USE master;
-- GO
-- EXECUTE sp_MSforeachdb 'USE [?]; BEGIN TRY DROP USER [assessment] END TRY BEGIN CATCH SELECT ERROR_MESSAGE() END CATCH';
-- DROP LOGIN [assessment];
Scenari non supportati e limitazioni
I consigli di Azure non includono stime dei prezzi, in quanto questa situazione può variare a seconda dell'area, della valuta e degli sconti, ad esempio il Vantaggio Azure Hybrid. Per ottenere stime dei prezzi, usare il Calcolatore prezzi di Azure o creare una valutazione SQL in Azure Migrate.
I consigli per database SQL di Azure con il modello di acquisto basato su DTU non sono supportati.
Attualmente, i consigli di Azure per database SQL di Azure livello di calcolo serverless e i pool elastici non sono supportati.
Risoluzione dei problemi
- Nessun consiglio generato
- Se non sono stati generati consigli, questa situazione potrebbe indicare che non sono state identificate configurazioni che possono soddisfare completamente i requisiti di prestazioni dell'istanza di origine. Per verificare i motivi per cui una determinata dimensione, un livello di servizio o una serie hardware è stata esclusa:
- Accedere ai log da Azure Data Studio passando alla Guida > Visualizzare tutti i comandi > Aprire la cartella dei log dell'estensione
- Passare a Microsoft.mssql > SqlAssessmentLogs > aprire SkuRecommendationEvent.log
- Il log contiene una traccia di ogni potenziale configurazione valutata e il motivo per cui è stata o non è stata considerata una configurazione idonea:
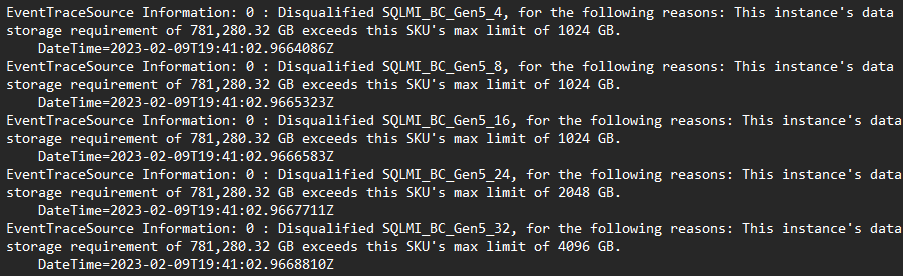
- Provare a rigenerare il consiglio con il consiglio elastico abilitato. Questa opzione usa un modello di consiglio alternativo, che usa la profilatura personalizzata delle prestazioni dei prezzi rispetto ai clienti esistenti nel cloud.
- Se non sono stati generati consigli, questa situazione potrebbe indicare che non sono state identificate configurazioni che possono soddisfare completamente i requisiti di prestazioni dell'istanza di origine. Per verificare i motivi per cui una determinata dimensione, un livello di servizio o una serie hardware è stata esclusa:
