Usare Spark & Hive Tools per Visual Studio Code
Informazioni su come usare Spark & Hive Tools per Visual Studio Code. Usare gli strumenti per creare e inviare processi batch Apache Hive, query Hive interattive e script PySpark per Apache Spark. Verrà prima di tutto descritto come installare Spark & Hive Tools in Visual Studio Code. Quindi verrà illustrato come inviare processi a tali strumenti.
È possibile installare Spark & Hive Tools nelle piattaforme supportate da Visual Studio Code. Si notino i prerequisiti seguenti per le diverse piattaforme.
Prerequisiti
Per completare i passaggi in questo articolo, è necessario quanto segue:
- Un cluster HDInsight di Azure. Per creare un cluster, vedere Introduzione a HDInsight. In alternativa, usare un cluster Spark e Hive che supporta un endpoint Apache Livy.
- Visual Studio Code.
- Mono. Mono è necessario solo per Linux e macOS.
- Un ambiente interattivo PySpark per Visual Studio Code.
- Una directory locale. Questo articolo usa
C:\HD\HDexample.
Installare Spark & Hive Tools
Dopo aver soddisfatto i prerequisiti, è possibile installare Spark & Hive Tools per Visual Studio Code seguendo questa procedura:
Aprire Visual Studio Code.
Dalla barra dei menu passare a Visualizza>Estensioni.
Nella casella di ricerca immettere Spark & Hive.
Selezionare Spark & Hive Tools nei risultati della ricerca e quindi selezionare Installa:
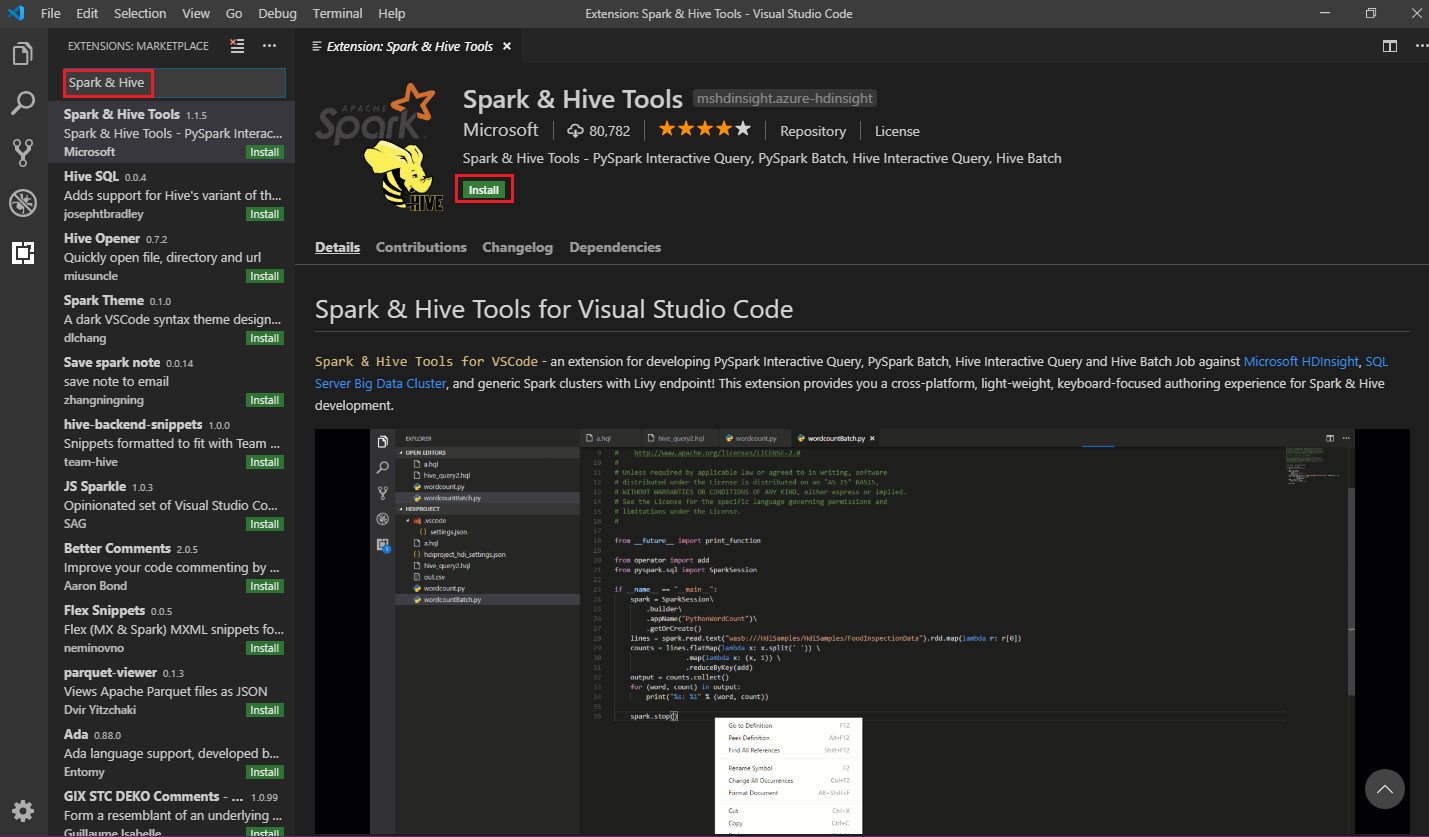
Selezionare Ricarica quando è necessario.
Aprire una cartella di lavoro
Per aprire una cartella di lavoro e creare un file in Visual Studio Code, seguire questa procedura:
Dalla barra dei menu passare a File>Apri cartella e>
C:\HD\HDexamplequindi selezionare il pulsante Seleziona cartella. La cartella verrà visualizzata nella visualizzazione Explorer a sinistra.Nella visualizzazione Esplora risorse selezionare la
HDexamplecartella e quindi selezionare l'icona Nuovo file accanto alla cartella di lavoro: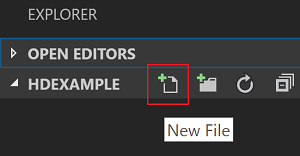
Denominare il nuovo file usando l'estensione
.hql(query Hive) o (.pyscript Spark). Questo esempio usa HelloWorld.hql.
Configurare l'ambiente di Azure
Per un utente cloud nazionale, seguire questa procedura per impostare prima l'ambiente di Azure e quindi usare il comando Azure: Sign In (Azure: Sign In ) per accedere ad Azure:
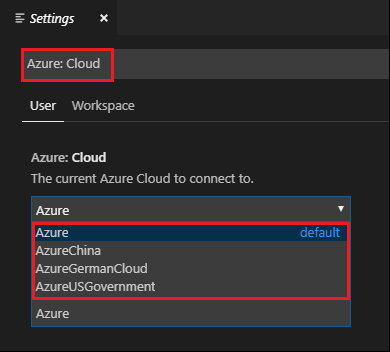
Passare a Impostazioni preferenze>file.>
Cercare nella stringa seguente: Azure: Cloud.
Selezionare il cloud nazionale dall'elenco:
Connettersi a un account Azure
Prima di poter inviare script ai cluster da Visual Studio Code, l'utente può accedere alla sottoscrizione di Azure o collegare un cluster HDInsight. Usare il nome utente/password di Ambari o le credenziali aggiunte a un dominio per il cluster ESP per connettersi al cluster HDInsight. Seguire questa procedura per connettersi ad Azure:
Nella barra dei menu scegliere Visualizza>Riquadro comandi... e immettere Azure: accedere:
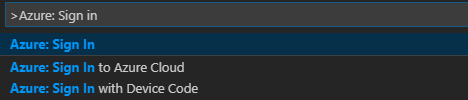
Seguire le istruzioni per accedere ad Azure. Dopo essersi connessi, il nome dell'account Azure viene visualizzato sulla barra di stato nell'angolo in basso a sinistra della finestra di Visual Studio Code.
Collegare un cluster
Collegamento: Azure HDInsight
È possibile collegare un cluster normale usando un nome utente gestito da Apache Ambari oppure collegare un cluster Hadoop sicuro di Enterprise Security Pack usando un nome utente di dominio , ad esempio . user1@contoso.com
Dalla barra dei menu passare a Visualizza>riquadro comandi... e immettere Spark/Hive: Collega un cluster.

Selezionare il tipo di cluster collegato Azure HDInsight.
Immettere l'URL del cluster HDInsight.
Immettere il nome utente di Ambari; il valore predefinito è admin.
Immettere la password di Ambari.
Selezionare il tipo di cluster.
Impostare il nome visualizzato del cluster (facoltativo).
Esaminare la visualizzazione OUTPUT per verificare.
Nota
Il nome utente e la password collegati vengono usati se il cluster ha eseguito l'accesso alla sottoscrizione di Azure e collegato a un cluster.
Collegamento: endpoint Livy generico
Dalla barra dei menu passare a Visualizza>riquadro comandi... e immettere Spark/Hive: Collega un cluster.
Selezionare il tipo di cluster collegatoGeneric Livy Endpoint (Endpoint Livy generico).
Immettere l'endpoint Livy generico. Ad esempio: http://10.172.41.42:18080.
Selezionare il tipo di autorizzazione Basic (Di base) o None (Nessuna). Se si seleziona Basic:
Immettere il nome utente di Ambari; il valore predefinito è admin.
Immettere la password di Ambari.
Esaminare la visualizzazione OUTPUT per verificare.
Elencare i cluster
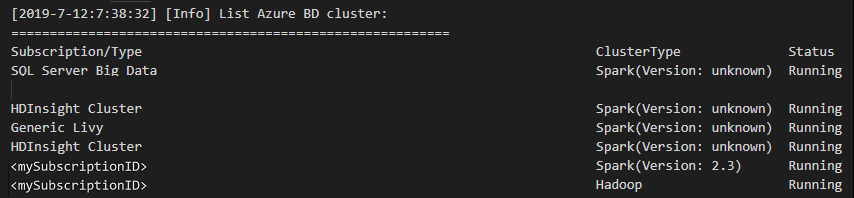
Dalla barra dei menu passare a Visualizza>riquadro comandi... e immettere Spark/Hive: Elenca cluster.
Selezionare la sottoscrizione desiderata.
Esaminare la visualizzazione OUTPUT. Questa visualizzazione mostra il cluster collegato (o i cluster) e tutti i cluster nella sottoscrizione di Azure:
Impostare il cluster predefinito
Riaprire la
HDexamplecartella descritta in precedenza, se chiusa.Selezionare il file HelloWorld.hql creato in precedenza. Viene aperto nell'editor di script.
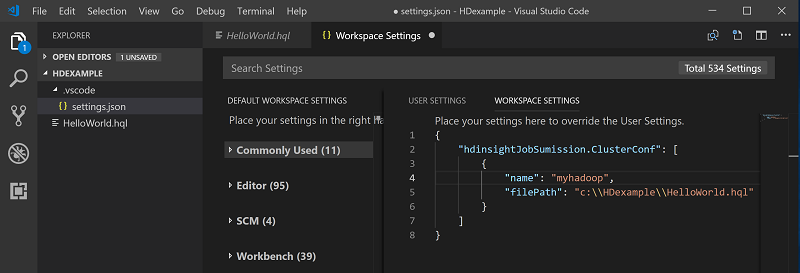
Fare clic con il pulsante destro del mouse sull'editor di script e quindi scegliere Spark/Hive: Imposta cluster predefinito.
Connettersi all'account Azure o collegare un cluster se non è ancora stato fatto.
Selezionare un cluster come predefinito per il file di script corrente. Gli strumenti aggiornano automaticamente il file di configurazione .VSCode\settings.json:
Inviare query Hive interattive e script batch Hive
Con Spark & Hive Tools per Visual Studio Code, è possibile inviare query Hive interattive e script batch Hive ai cluster.
Riaprire la
HDexamplecartella descritta in precedenza, se chiusa.Selezionare il file HelloWorld.hql creato in precedenza. Viene aperto nell'editor di script.
Copiare e incollare il codice seguente nel file Hive e quindi salvarlo:
SELECT * FROM hivesampletable;Connettersi all'account Azure o collegare un cluster se non è ancora stato fatto.
Fare clic con il pulsante destro del mouse sull'editor di script e scegliere Hive: Interactive per inviare la query oppure usare i tasti di scelta rapida CTRL+ALT+I. Selezionare Hive: Batch per inviare lo script oppure usare i tasti di scelta rapida CTRL+ALT+H.
Se non è stato specificato un cluster predefinito, selezionare un cluster. Gli strumenti consentono anche di inviare un blocco di codice anziché l'intero file di script usando il menu di scelta rapida. Dopo alcuni istanti, i risultati della query vengono visualizzati in una nuova scheda:
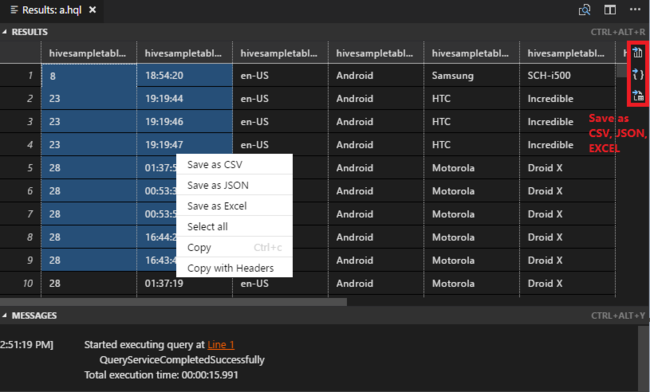
Pannello RISULTATI : è possibile salvare l'intero risultato come file CSV, JSON o Excel in un percorso locale o semplicemente selezionare più righe.
Pannello MESSAGGI: quando si seleziona un numero di riga, si passa alla prima riga dello script in esecuzione.
Inviare query PySpark interattive
Prerequisito per Pyspark interattivo
Si noti che jupyter Extension version (ms-jupyter): v2022.1.1001614873 e Python Extension version (ms-python): v2021.12.1559732655, Python 3.6.x e 3.7.x sono necessari per le query PySpark interattive di HDInsight.
Gli utenti possono eseguire PySpark interattivo nei modi seguenti.
Uso del comando interattivo PySpark nel file PY
Per usare il comando interattivo di PySpark per inviare le query, seguire questa procedura:
Riaprire la
HDexamplecartella descritta in precedenza, se chiusa.Creare un nuovo file HelloWorld.py seguendo la procedura illustrata in precedenza.
Copiare e incollare il codice seguente nel file di script:
from operator import add from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName('hdisample') \ .getOrCreate() lines = spark.read.text("/HdiSamples/HdiSamples/FoodInspectionData/README").rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) coll = counters.collect() sortedCollection = sorted(coll, key = lambda r: r[1], reverse = True) for i in range(0, 5): print(sortedCollection[i])Nell'angolo in basso a destra della finestra viene visualizzata la richiesta di installare i kernel PySpark/SynapsePyspark. È possibile fare clic sul pulsante Installa per procedere alle installazioni di PySpark/SynapsePyspark oppure sul pulsante Ignora per ignorare questo passaggio.
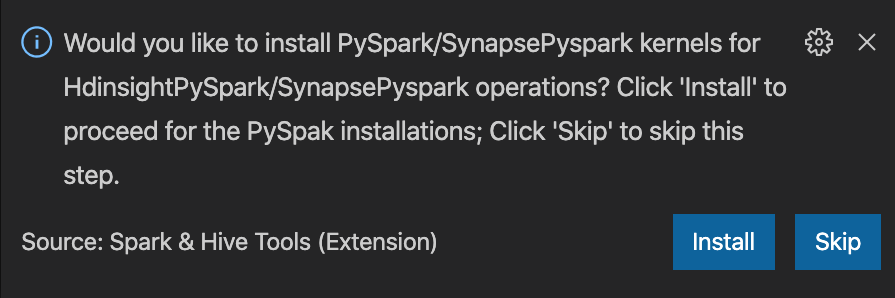
Se è necessario installarlo in un secondo momento, è possibile passare a Impostazioni preferenza>file>, quindi deselezionare HDInsight: Abilita Ignora installazione pyspark nelle impostazioni.
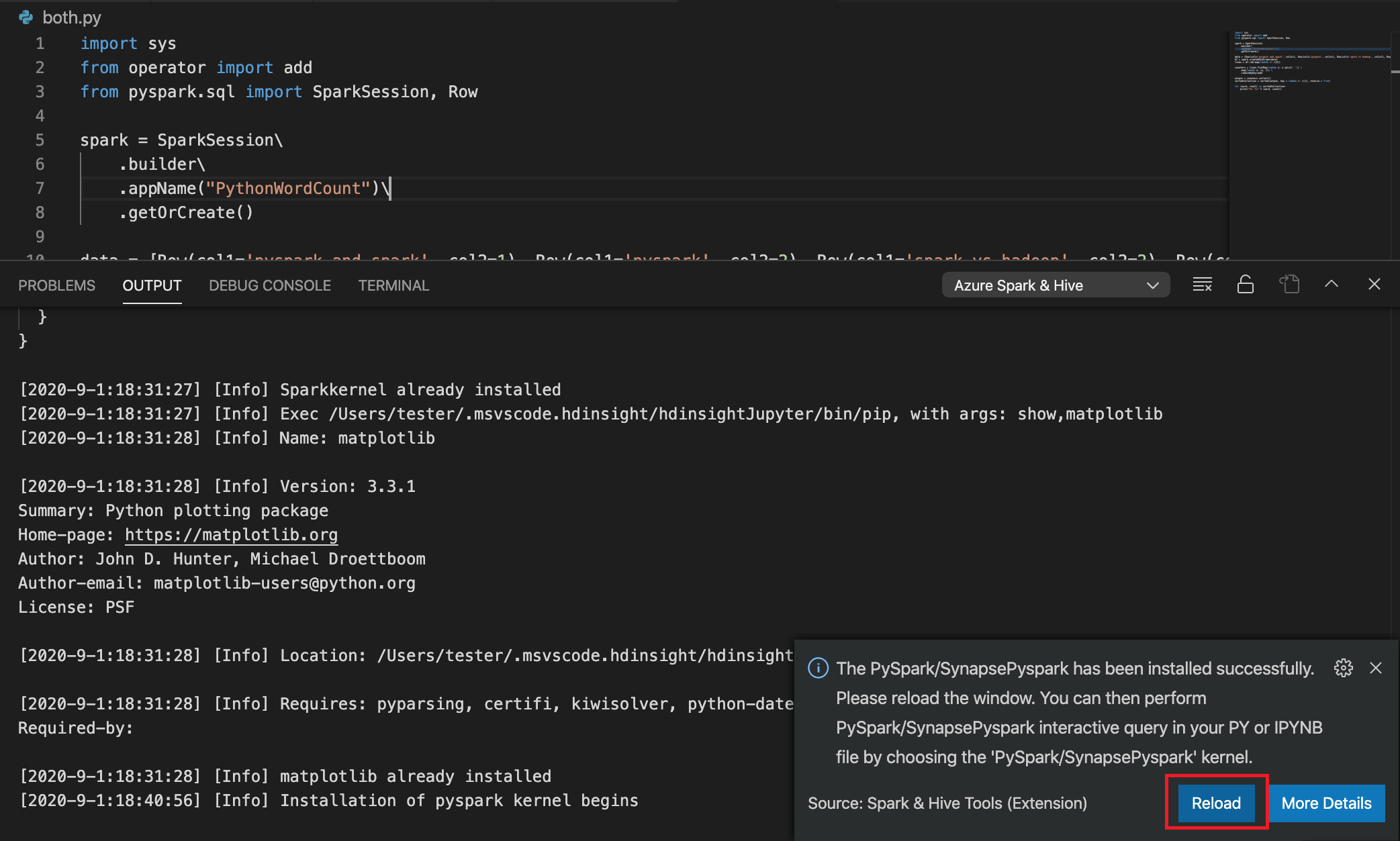
Se l'installazione ha esito positivo nel passaggio 4, la finestra di messaggio "PySpark installato correttamente" viene visualizzata nell'angolo inferiore destro della finestra. Fare clic sul pulsante Ricarica per ricaricare la finestra.
Nella barra dei menu andare a Visualizza>Riquadro comandi... oppure premere i tasti di scelta rapida Maiusc+Ctrl+P e immettere Python: selezionare Interprete per avviare il server Jupyter.

Selezionare l'opzione Python seguente.

Nella barra dei menu, andare a Visualizza>Riquadro comandi... oppure premere i tasti di scelta rapida Maiusc+Ctrl+P e immettere Developer: ricarica finestra.

Connettersi all'account Azure o collegare un cluster se non è ancora stato fatto.
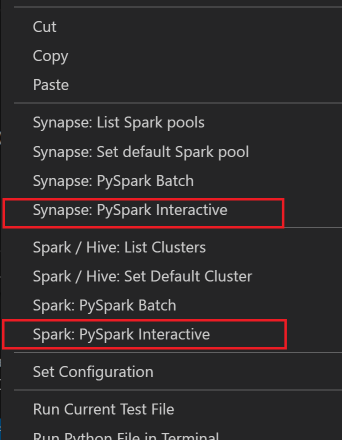
Selezionare tutto il codice, fare clic con il pulsante destro del mouse sull'editor di script e selezionare Spark: PySpark Interactive/Synapse: Pyspark Interactive per inviare la query.
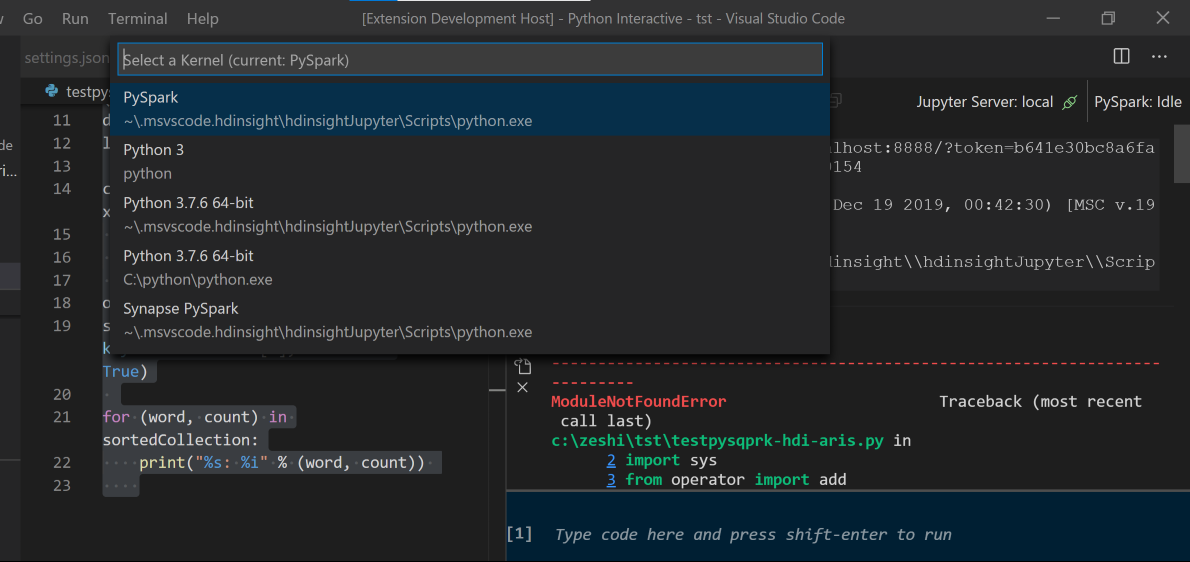
Selezionare il cluster, se non è stato specificato un cluster predefinito. Dopo alcuni istanti, i risultati interattivi di Python vengono visualizzati in una nuova scheda. Fare clic su PySpark per passare il kernel a PySpark/Synapse Pyspark e il codice verrà eseguito correttamente. Se si vuole passare al kernel Pyspark di Synapse, è consigliabile disabilitare le impostazioni automatica in portale di Azure. In caso contrario, potrebbe essere necessario molto tempo per riattivare il cluster e impostare il kernel Synapse per il primo utilizzo. Se gli strumenti consentono anche di inviare un blocco di codice anziché l'intero file di script usando il menu di scelta rapida:
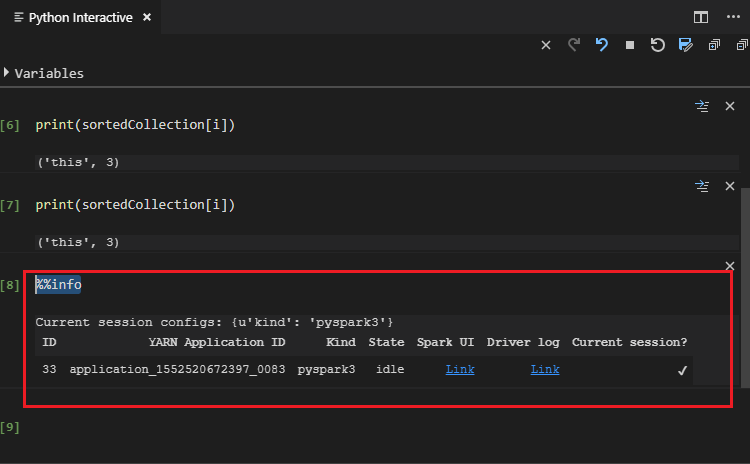
Immettere %%info, quindi premere MAIUSC+INVIO per visualizzare le informazioni sul processo (facoltativo):
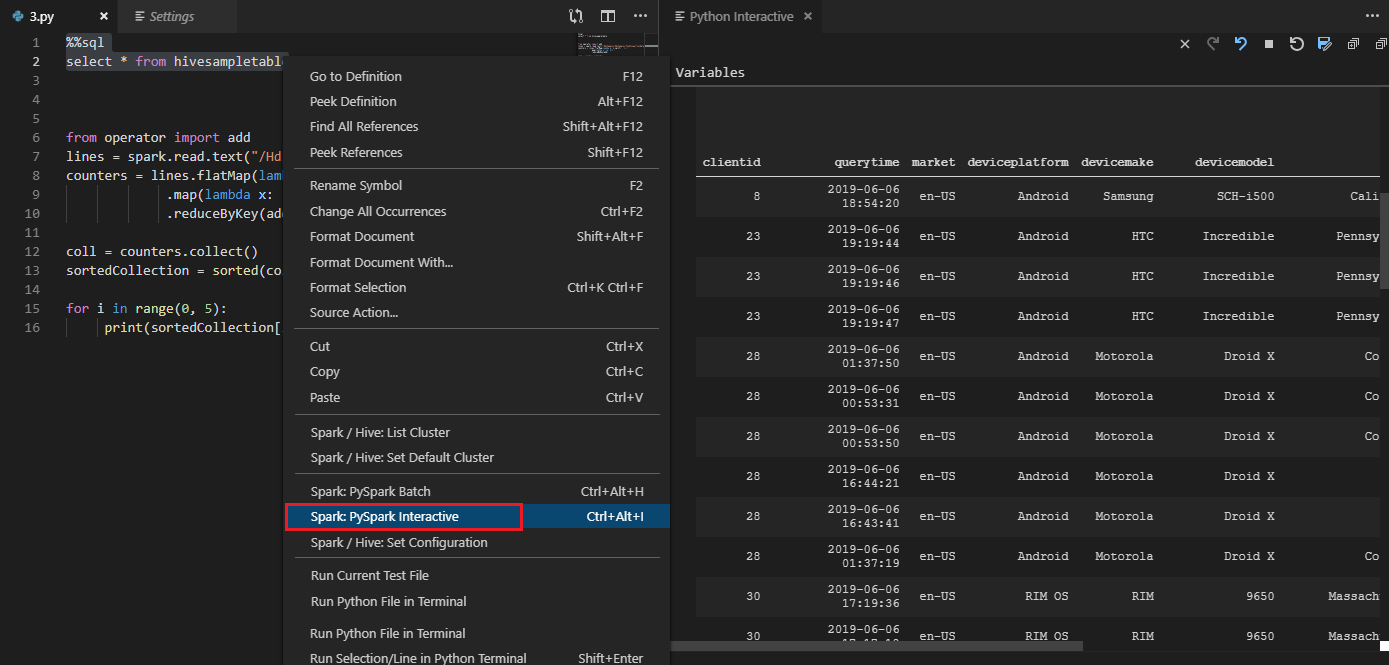
Lo strumento supporta anche la query Spark SQL :
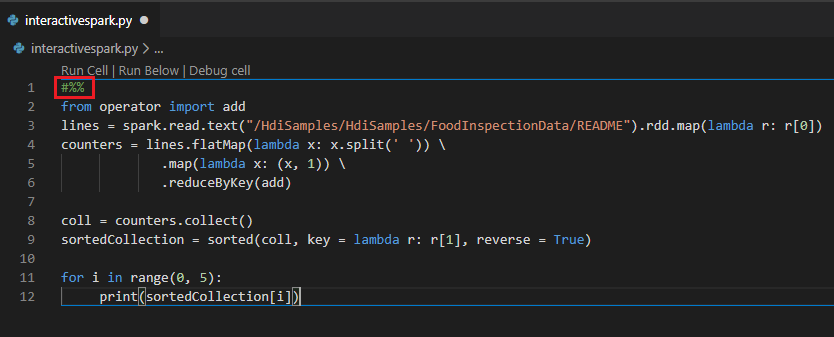
Eseguire query interattive in un file PY usando un commento #%%
Aggiungere #%% prima del codice Py per ottenere l'esperienza del notebook.
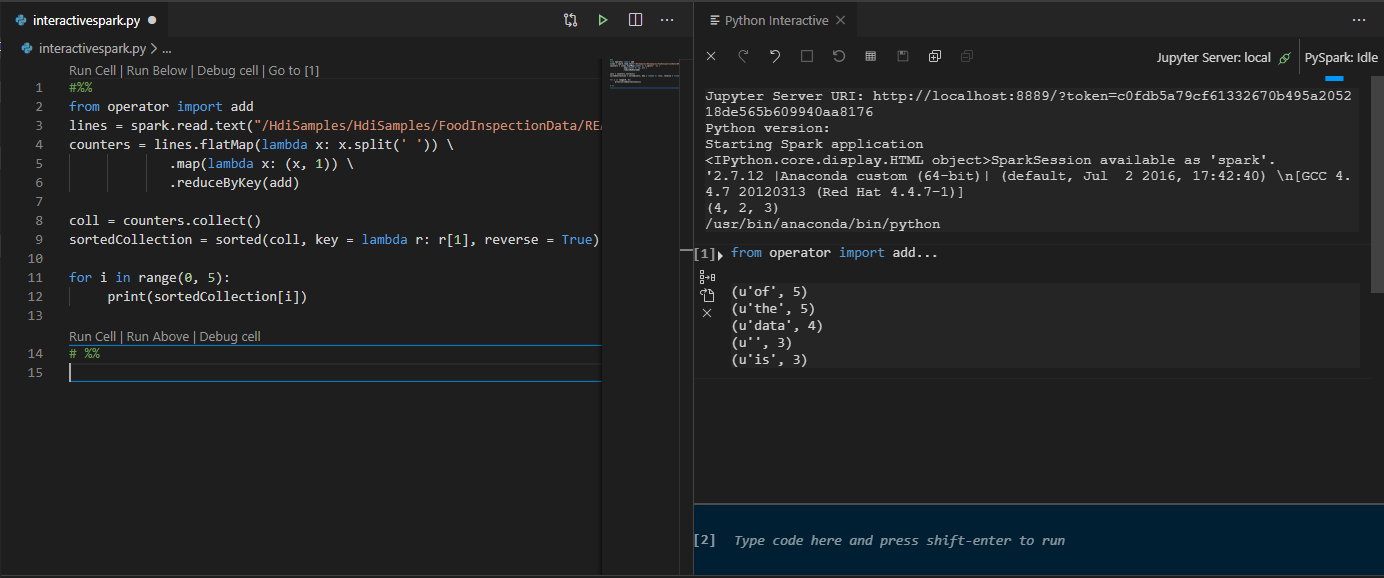
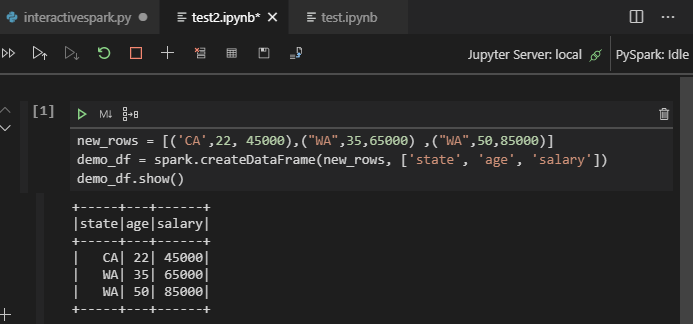
Fare clic su Esegui cella. Dopo alcuni istanti, i risultati interattivi di Python vengono visualizzati in una nuova scheda. Fare clic su PySpark per passare il kernel a PySpark/Synapse PySpark, quindi fare di nuovo clic su Esegui cella e il codice verrà eseguito correttamente.
Sfruttare il supporto per IPYNB dell'estensione Python
È possibile creare un notebook di Jupyter tramite il comando dal riquadro comandi o creando un nuovo
.ipynbfile nell'area di lavoro. Per altre informazioni, vedere Uso di notebook di Jupyter in Visual Studio CodeFare clic sul pulsante Esegui cella , seguire le istruzioni per impostare il pool di spark predefinito (è consigliabile impostare il cluster/pool predefinito ogni volta prima di aprire un notebook) e quindi, finestra Ricarica .
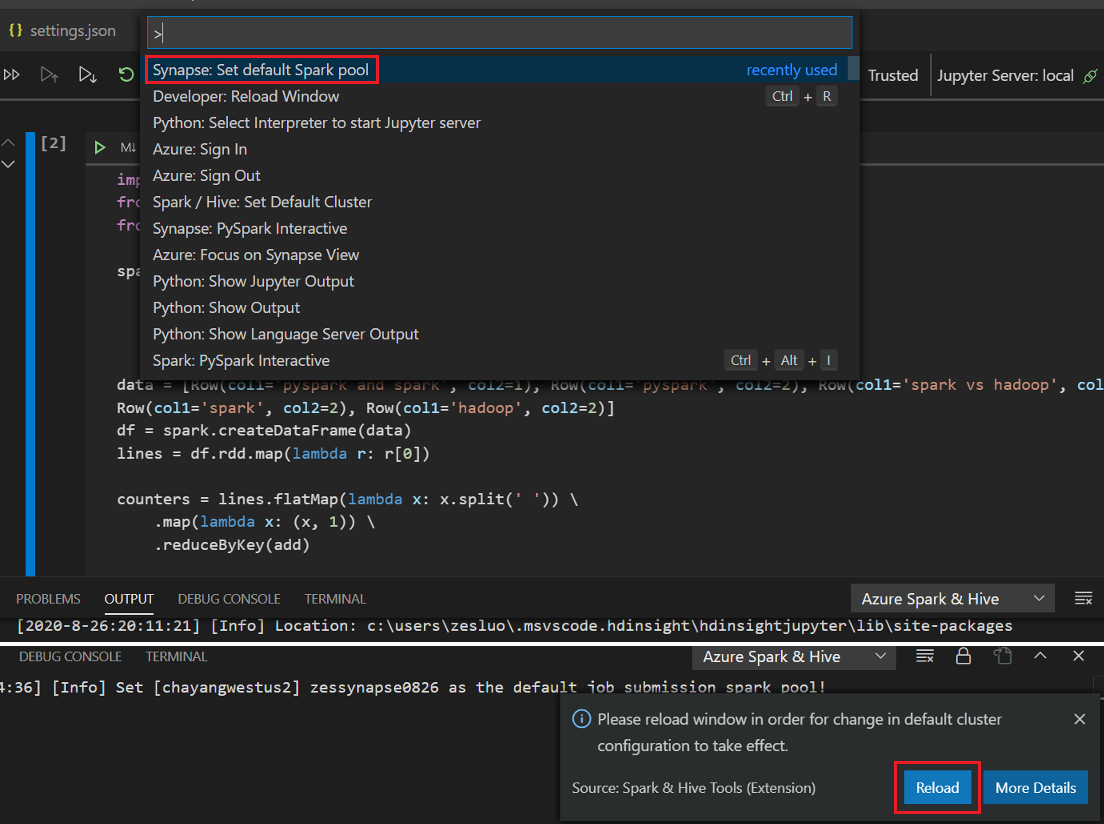
Fare clic su PySpark per passare dal kernel a PySpark/Synapse Pyspark e quindi fare clic su Esegui cella, dopo un po' di tempo, verrà visualizzato il risultato.
Nota
Per l'errore di installazione di Synapse PySpark, poiché la relativa dipendenza non verrà più gestita da altri team, non verrà più gestita. Se si prova a usare Synapse Pyspark interattivo, passare all'uso di Azure Synapse Analytics . Ed è un cambiamento a lungo termine.
Inviare il processo batch PySpark
Riaprire la
HDexamplecartella descritta in precedenza, se chiusa.Creare un nuovo file BatchFile.py seguendo la procedura descritta in precedenza.
Copiare e incollare il codice seguente nel file di script:
from __future__ import print_function import sys from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv').rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' '))\ .map(lambda x: (x, 1))\ .reduceByKey(add) output = counts.collect() for (word, count) in output: print("%s: %i" % (word, count)) spark.stop()Connettersi all'account Azure o collegare un cluster se non è ancora stato fatto.
Fare clic con il pulsante destro del mouse sull'editor di script e quindi scegliere Spark: PySpark Batch o Synapse: PySpark Batch*.
Selezionare un pool di cluster/spark per inviare il processo PySpark a:
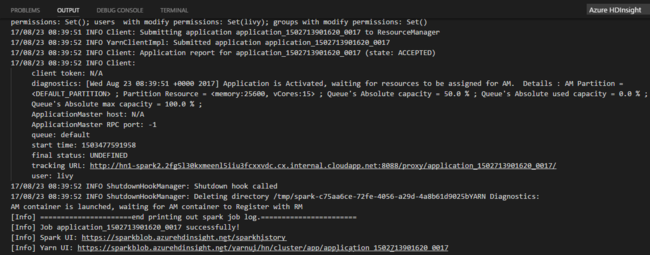
Dopo aver inviato un processo Python, i log di invio vengono visualizzati nella finestra OUTPUT in Visual Studio Code. Vengono visualizzati anche l'URL dell'interfaccia utente spark e l'URL dell'interfaccia utente yarn. Se si invia il processo batch a un pool di Apache Spark, vengono visualizzati anche l'URL dell'interfaccia utente della cronologia Spark e l'URL dell'interfaccia utente dell'applicazione processo Spark. È possibile aprire l'URL in un Web browser per tenere traccia dello stato del processo.
Eseguire l'integrazione con broker di identità di HDInsight
Connettersi al cluster HDInsight ESP con ID Broker (HIB)
È possibile seguire la procedura normale per accedere alla sottoscrizione di Azure per connettersi al cluster ESP HDInsight con ID Broker (HIB). Dopo l'accesso, verrà visualizzato l'elenco dei cluster in Azure Explorer. Per altre istruzioni, vedere Connettersi al cluster HDInsight.
Eseguire un processo Hive/PySpark in un cluster ESP HDInsight con ID Broker (HIB)
Per eseguire un processo Hive, è possibile seguire la procedura normale per inviare il processo al cluster ESP HDInsight con ID Broker (HIB). Per altre istruzioni, vedere Inviare query Hive interattive e script batch Hive.
Per eseguire un processo PySpark interattivo, è possibile seguire la procedura normale per inviare il processo al cluster ESP HDInsight con ID Broker (HIB). Vedere Inviare query PySpark interattive.
Per eseguire un processo batch PySpark, è possibile seguire la procedura normale per inviare il processo al cluster HDInsight ESP con ID Broker (HIB). Per altre istruzioni, vedere Inviare il processo batch PySpark.
Configurazione di Apache Livy
La configurazione di Apache Livy è supportata. È possibile configurarlo in . File VSCode\settings.json nella cartella dell'area di lavoro. Attualmente, la configurazione di Livy supporta solo script Python. Per altre informazioni, vedere Livy README.
Come attivare la configurazione di Livy
Metodo 1
- Dalla barra dei menu passare a File>Preferenze>Impostazioni.
- Nella casella Impostazioni di ricerca immettere Invio processo HDInsight: Livy Conf.
- Selezionare Edit in settings.json (Modifica in settings.json) per il risultato della ricerca pertinente.
Metodo 2
Inviare un file e notare che la .vscode cartella viene aggiunta automaticamente alla cartella di lavoro. È possibile visualizzare la configurazione di Livy selezionando .vscode\settings.json.
Impostazioni del progetto:
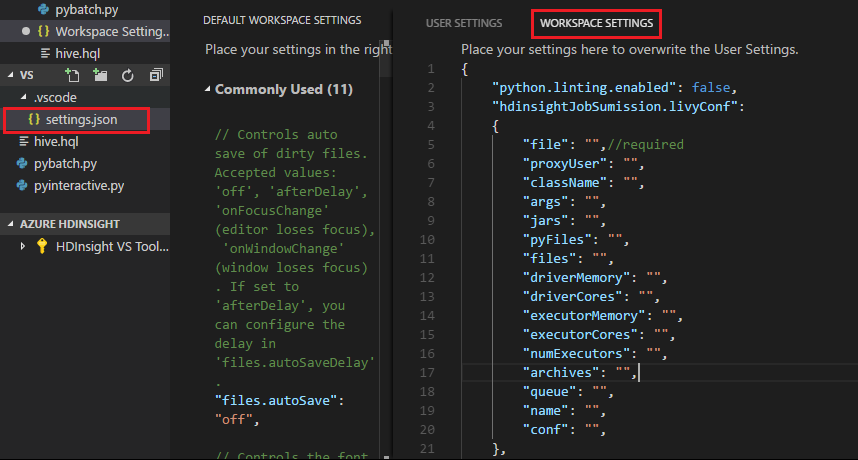
Nota
Per le impostazioni driverMemory ed executorMemory , impostare il valore e l'unità. Ad esempio: 1g o 1024m.
Configurazioni livy supportate:
POST /batches
Testo della richiesta
name description type file File contenente l'applicazione da eseguire Percorso (obbligatorio) proxyUser Utente da rappresentare quando si esegue il processo String className Classe principale Java/Spark dell'applicazione String args Argomenti della riga di comando per l'applicazione Elenco di stringhe jars Jar da usare in questa sessione Elenco di stringhe pyFiles File Python da usare in questa sessione Elenco di stringhe files File da usare in questa sessione Elenco di stringhe driverMemory Quantità di memoria da usare per il processo del driver String driverCores Numero di core da usare per il processo del driver Int executorMemory Quantità di memoria da usare per un processo executor String executorCores Numero di core da usare per ogni executor Int numExecutors Numero di executor da avviare per questa sessione Int archives Archivi da usare in questa sessione Elenco di stringhe queue Nome della coda YARN a cui inviare String name Nome della sessione String conf Proprietà di configurazione Spark Mappa di chiave=valore Corpo della risposta L'oggetto Batch creato.
name description type ID ID sessione Int IDapp ID applicazione di questa sessione String appInfo Informazioni dettagliate sull'applicazione Mappa di chiave=valore log Righe di log Elenco di stringhe state Stato batch String Nota
La configurazione livy assegnata viene visualizzata nel riquadro di output quando si invia lo script.
Eseguire l'integrazione con Azure HDInsight da Explorer
È possibile visualizzare in anteprima la tabella Hive nei cluster direttamente tramite Azure HDInsight Explorer:
Connettersi all'account Azure, se ancora non è stato fatto.
Selezionare l'icona di Azure nella colonna all'estrema sinistra.
Nel riquadro sinistro espandere AZURE: HDINSIGHT. Sono elencate le sottoscrizioni e i cluster disponibili.
Espandere il cluster per visualizzare il database dei metadati Hive e lo schema della tabella.
Fare clic con il pulsante destro del mouse sulla tabella Hive. Ad esempio: hivesampletable. Seleziona Anteprima.
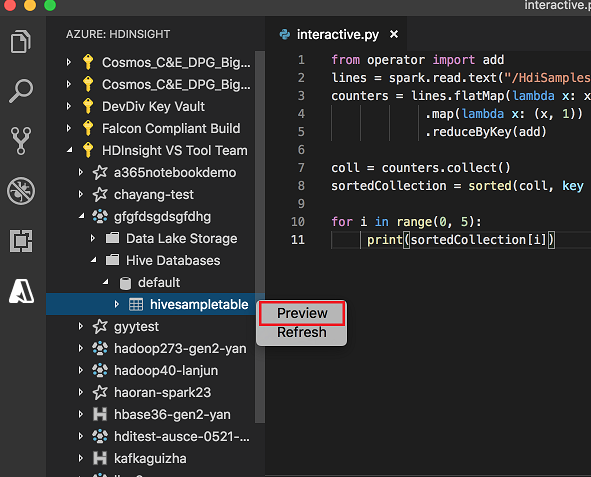
Verrà visualizzata la finestra Anteprima risultati :
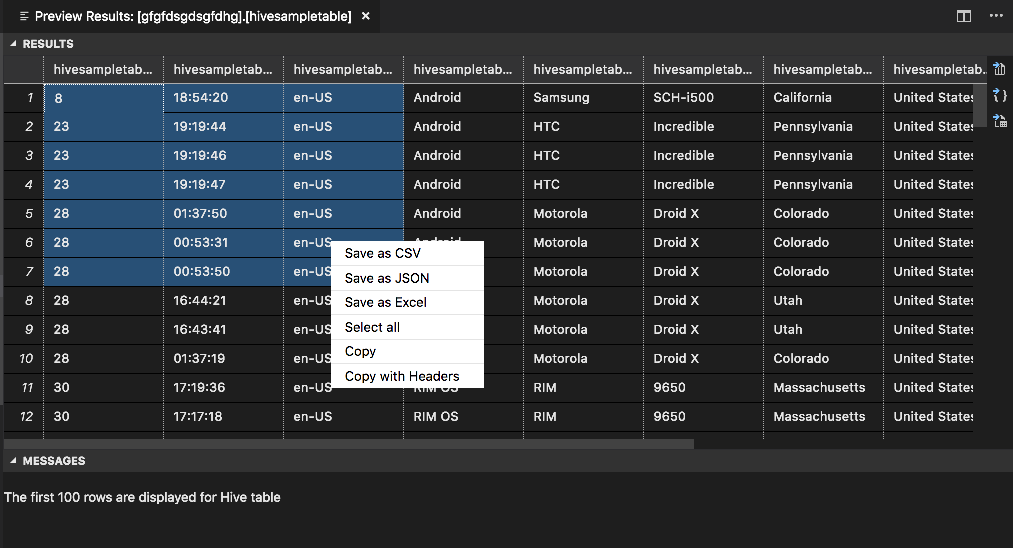
Pannello RISULTATI
È possibile salvare l'intero risultato come file CSV, JSON o Excel in un percorso locale oppure selezionare solo più righe.
Pannello MESSAGES
Quando il numero di righe nella tabella è maggiore di 100, viene visualizzato il messaggio seguente: "Le prime 100 righe vengono visualizzate per la tabella Hive".
Quando il numero di righe nella tabella è minore o uguale a 100, viene visualizzato il messaggio seguente: "60 righe vengono visualizzate per la tabella Hive".
Quando nella tabella non è presente alcun contenuto, viene visualizzato il messaggio seguente: "
0 rows are displayed for Hive table."Nota
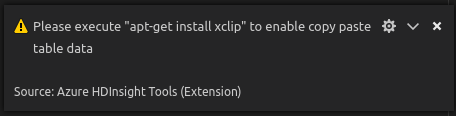
In Linux installare xclip per abilitare i dati della tabella di copia.
Funzionalità aggiuntive
Spark & Hive per Visual Studio Code supporta anche le funzionalità seguenti:
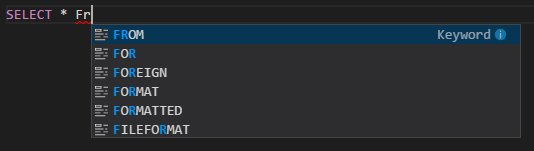
Completamento automatico di IntelliSense. Vengono visualizzati suggerimenti per parole chiave, metodi, variabili e altri elementi di programmazione. Icone diverse rappresentano vari tipi di oggetti:
Marcatori di errore di IntelliSense. Il servizio di linguaggio sottolinea gli errori di modifica nello script Hive.
Evidenziazioni della sintassi. Il servizio di linguaggio usa colori diversi per distinguere variabili, parole chiave, tipo di dati, funzioni e altri elementi di programmazione:
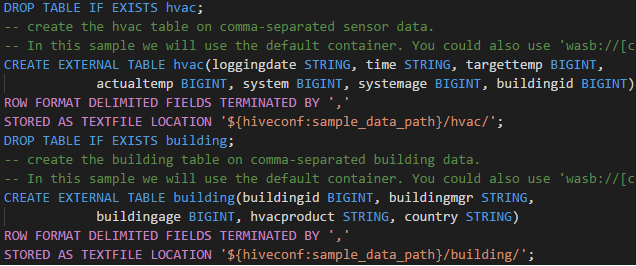
Ruolo di sola lettura
Gli utenti a cui è assegnato il ruolo di sola lettura per il cluster non possono inviare processi al cluster HDInsight, né visualizzare il database Hive. Contattare l'amministratore del cluster per aggiornare il ruolo all'operatore cluster HDInsight nel portale di Azure. Se si dispone di credenziali Ambari valide, è possibile collegare manualmente il cluster usando le indicazioni seguenti.
Esplorare il cluster HDInsight
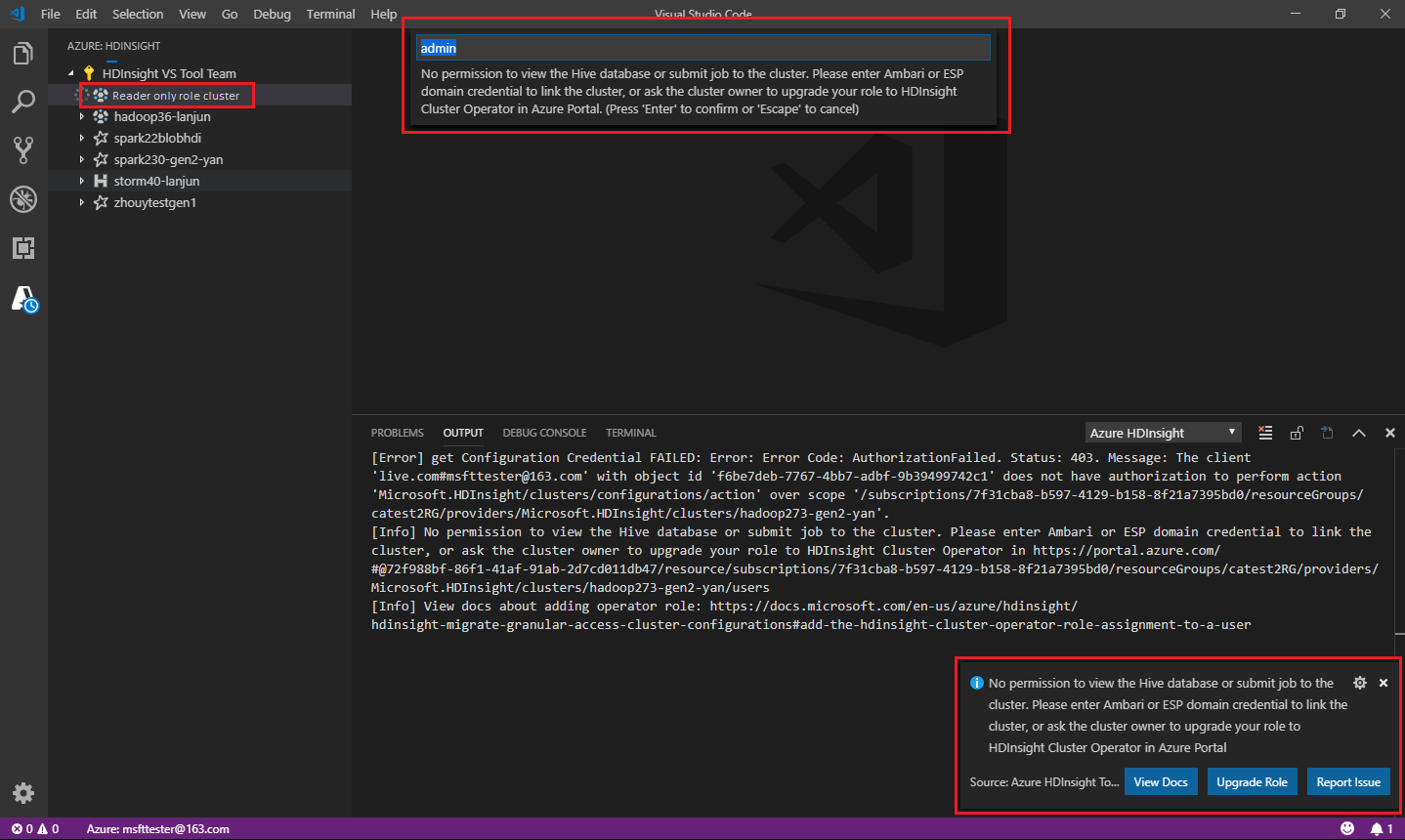
Quando si seleziona Azure HDInsight Explorer per espandere un cluster HDInsight, viene richiesto di collegare il cluster se si ha il ruolo di sola lettura per il cluster. Usare il metodo seguente per collegarsi al cluster usando le credenziali di Ambari.
Inviare il processo al cluster HDInsight
Quando si invia un processo a un cluster HDInsight, viene richiesto di collegare il cluster se si è nel ruolo di sola lettura per il cluster. Usare la procedura seguente per collegarsi al cluster usando le credenziali di Ambari.
Collegamento al cluster
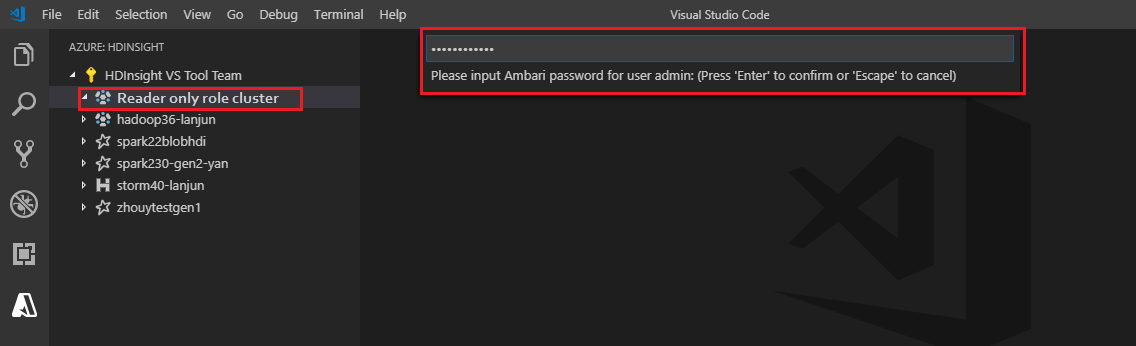
Immettere un nome utente Ambari valido.
Immettere una password valida.
Nota
È possibile usare
Spark / Hive: List Clusterper controllare il cluster collegato:
Azure Data Lake Storage Gen2
Esplorare un account Data Lake Storage Gen2
Selezionare Azure HDInsight Explorer per espandere un account Data Lake Storage Gen2. Viene richiesto di immettere la chiave di accesso alle risorse di archiviazione se l'account Azure non ha accesso all'archiviazione gen2. Dopo la convalida della chiave di accesso, l'account Data Lake Storage Gen2 viene espanso automaticamente.
Inviare processi a un cluster HDInsight con Data Lake Storage Gen2
Inviare un processo a un cluster HDInsight usando Data Lake Storage Gen2. Viene richiesto di immettere la chiave di accesso alle risorse di archiviazione se l'account Azure non ha accesso in scrittura all'archiviazione Gen2. Dopo la convalida della chiave di accesso, il processo verrà inviato correttamente.

Nota
È possibile ottenere la chiave di accesso per l'account di archiviazione dal portale di Azure. Per altre informazioni, vedere Gestire le chiavi di accesso dell'account di archiviazione.
Scollegare il cluster
Dalla barra dei menu passare a Visualizza>riquadro comandi e quindi immettere Spark/Hive: Scollega un cluster.
Selezionare un cluster da scollegare.
Vedere la visualizzazione OUTPUT per la verifica.
Disconnettersi
Dalla barra dei menu passare a Visualizza>Riquadro comandi, quindi immettere Azure: disconnetti.
Problemi noti
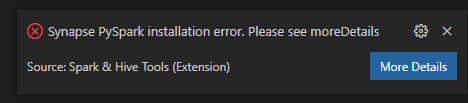
Errore di installazione di Synapse PySpark.
Per l'errore di installazione di Synapse PySpark, poiché la relativa dipendenza non verrà più mantenuta da altri team, non verrà più gestita. Se si prova a usare Synapse Pyspark interactive, usare invece Azure Synapse Analytics . Ed è un cambiamento a lungo termine.
Passaggi successivi
Per un video che illustra l'uso di Spark & Hive per Visual Studio Code, vedere Spark & Hive per Visual Studio Code.