Usare gli archivi di metadati esterni in Azure HDInsight
Importante
Il metastore predefinito offre un database SQL di Azure di livello base con solo 5 DTU e 2 GB di dimensioni massime dei dati (NON AGGIORNABILE)! Usarlo solo a scopo di controllo di qualità e test. Per carichi di lavoro di produzione o di grandi dimensioni, è consigliabile eseguire la migrazione a un metastore esterno.
HDInsight consente di assumere il controllo dei dati e dei metadati con archivi dati esterni. Questa funzione è disponibile per il metastore Apache Hive, il metastore Apache Oozie e il database Apache Ambari.
Il metastore di Apache Hive in HDInsight è una parte essenziale dell'architettura di Apache Hadoop. Un metastore è il deposito centrale degli schemi. Il metastore viene usato da altri strumenti di accesso ai Big Data come Apache Spark, Interactive Query (LLAP), Presto o Apache Pig. HDInsight usa un Database SQL di Azure come il metastore Hive.
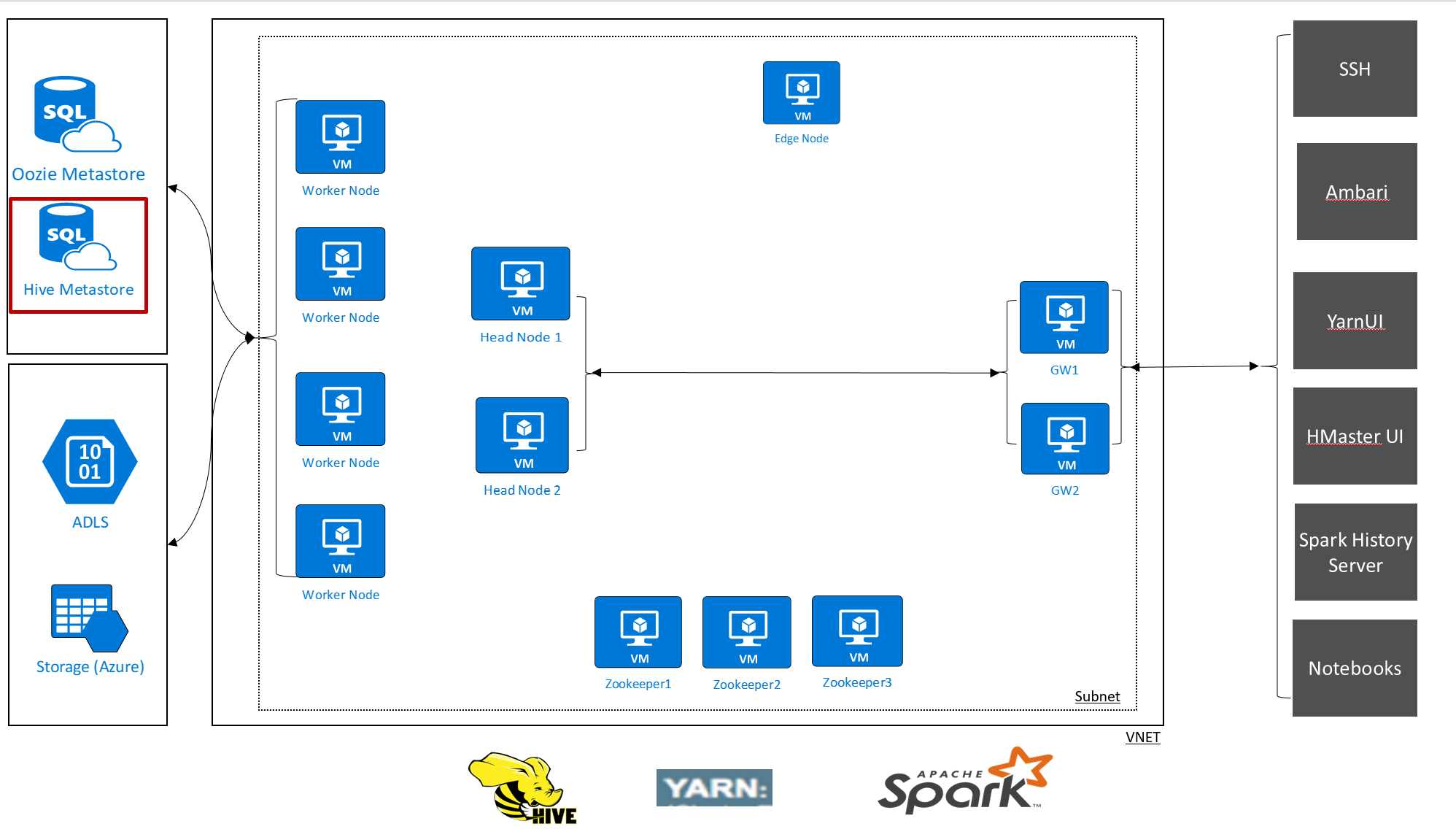
Esistono due modi per configurare un metastore per i cluster HDInsight:
Metastore predefinito
Per impostazione predefinita, HDInsight crea un metastore con ogni tipo di cluster. È invece possibile specificare un metastore personalizzato. Il metastore predefinito include quanto segue:
Risorse limitate. Vedere l'informativa nella parte superiore della pagina.
Non sono previsti costi aggiuntivi. HDInsight crea un metastore con ogni tipo di cluster senza alcun costo aggiuntivo per l'utente.
Il metastore predefinito fa parte del ciclo di vita del cluster. Quando si elimina un cluster verranno eliminati anche il metastore e i metadati corrispondenti.
Il metastore predefinito è consigliato solo per carichi di lavoro semplici. I carichi di lavoro relativamente semplici che non richiedono più cluster e che non hanno bisogno di conservare i metadati oltre il ciclo di vita del cluster.
Il metastore predefinito non può essere condiviso con altri cluster.
Metastore personalizzato
HDInsight supporta inoltre i metastore personalizzati, che sono consigliati per i cluster di produzione:
Specificare il database SQL di Azure come metastore.
Il ciclo di vita del metastore non è associato a un ciclo di vita dei cluster, pertanto è possibile creare ed eliminare i cluster senza perdere i metadati. I metadati come ad esempio gli schemi di Hive verranno mantenuti anche dopo aver eliminato e ricreato il cluster di HDInsight.
Un metastore personalizzato consente di collegare più cluster e tipi di cluster al metastore. Ad esempio, un singolo metastore può essere condiviso tra i cluster Interactive Query, Hive e Spark in HDInsight.
Si paga il costo di un metastore (database SQL di Azure) in base al livello di prestazioni scelto.
È possibile aumentare il metastore in base alle esigenze.
Il cluster e il metastore esterno devono trovarsi nella stessa area.
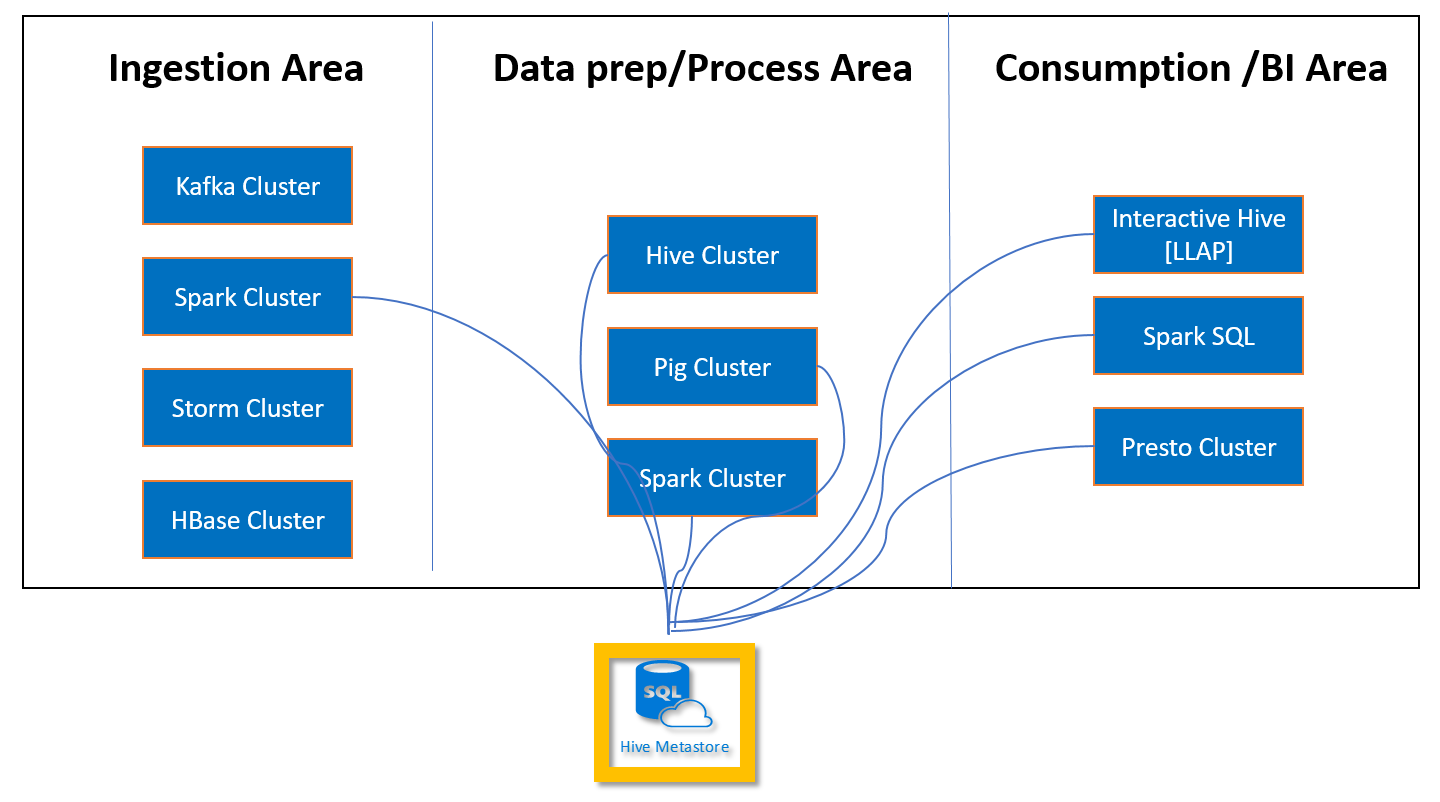
Creare e configurare il database SQL di Azure per il metastore personalizzato
Creare o disporre di un database SQL di Azure esistente prima di impostare un metastore Hive personalizzato per un cluster HDInsight. Per altre informazioni, vedere Guida introduttiva: Creare un singolo database in Azure SQL database SQL di Azure.
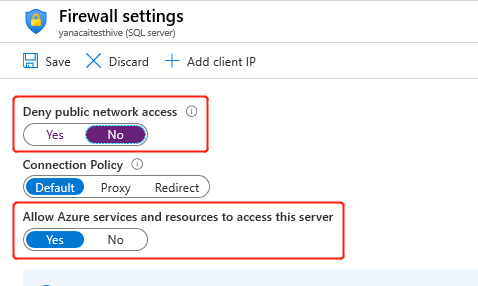
Quando si crea il cluster, il servizio HDInsight deve connettersi al metastore esterno e verificare le credenziali. Configurare le regole del firewall del database SQL di Azure per consentire ai servizi e alle risorse di Azure di accedere al server. Abilitare questa opzione nel portale di Azure selezionando Imposta firewall server. Quindi, selezionare No in corrispondenza di Nega accesso alla rete pubblica e Sì in corrispondenza di Consenti ai servizi e alle risorse di Azure di accedere a questo server per il database SQL di Azure. Per altre informazioni, vedere Creare e gestire le regole del firewall IP
Gli endpoint privati per gli archivi SQL sono supportati solo nei cluster creati con outbound ResourceProviderConnection. Per altre informazioni, vedere questa documentazione.

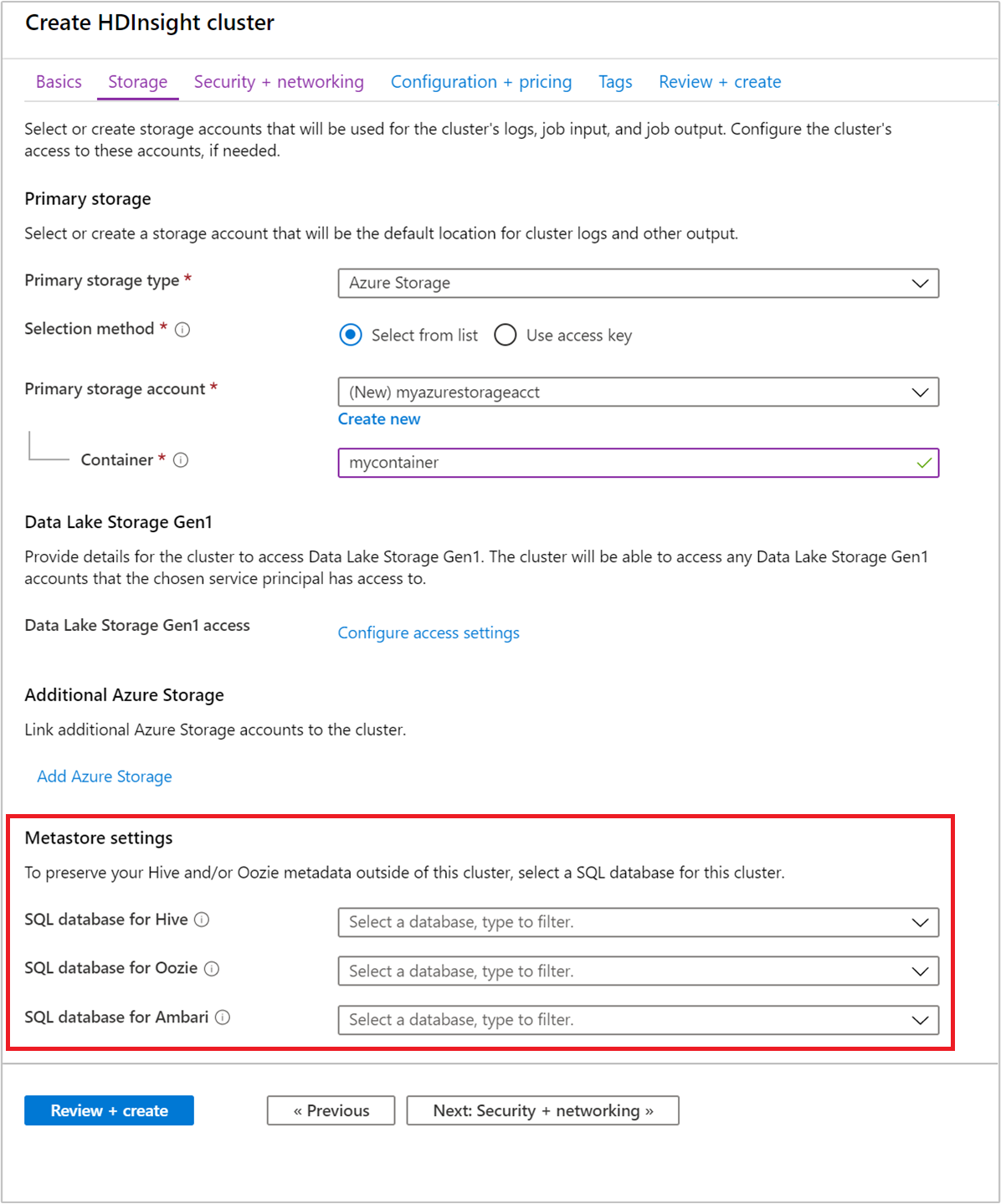
Selezionare un metastore personalizzato durante la creazione del cluster
È possibile puntare il cluster a un database Azure SQL creato in precedenza in qualsiasi momento. Per la creazione di cluster attraverso il portale, l'opzione viene specificata dalle Impostazioni metastore > di archiviazione.
Linee guida per il metastore Apache Hive
Nota
Usare un metastore personalizzato quando possibile per separare le risorse di calcolo (il cluster in esecuzione) e i metadati (archiviati nel metastore). Si parte dal livello S2, che offre 50 DTU e 250 GB di spazio di archiviazione. Se viene visualizzato un collo di bottiglia, è possibile aumentare il database.
Se si prevede l'accesso di più cluster HDInsight a dati separati, usare un database separato per il metastore in ogni cluster. Se un metastore è condiviso da più cluster HDInsight, significa che i cluster usano gli stessi metadati e file di dati utente sottostanti.
Eseguire periodicamente il backup del metastore personalizzato. Il database SQL di Azure genera automaticamente i backup, ma il periodo di conservazione dei backup varia. Per ulteriori informazioni, vedere Informazioni sui backup automatici del database SQL.
Individuare il metastore e un cluster HDInsight nella stessa area. Questa configurazione fornisce le prestazioni più elevate e i costi di uscita dalla rete più bassi.
Monitorare le prestazioni e la disponibilità del metastore usando gli strumenti di monitoraggio del Database SQL di Azure o i log di Monitoraggio di Azure.
Quando una nuova versione di Azure HDInsight viene creata in un database del metastore personalizzato esistente, il sistema aggiorna lo schema del metastore. L'aggiornamento è irreversibile senza il ripristino del database dal backup.
Se un metastore è condiviso da più cluster, assicurarsi che tutti i cluster abbiano la stessa versione HDInsight. Versioni Hive diverse usano schemi di database del metastore diversi. Ad esempio, non è possibile condividere un metastore tra cluster Hive 2.1 e Hive 3.1.
In HDInsight 4.0, Spark e Hive usano cataloghi indipendenti per accedere alle tabelle SparkSQL o Hive. Una tabella creata da Spark si trova nel catalogo Spark. Una tabella creata da Hive si trova nel catalogo Hive. Questo comportamento è diverso da quello di HDInsight 3.6 in cui Hive e Spark condividono un catalogo comune. L'integrazione di Hive e Spark in HDInsight 4.0 si basa su Hive Warehouse Connector (HWC). HWC funziona come bridge tra Spark e Hive. Informazioni su Hive Warehouse Connector.
In HDInsight 4.0 se si vuole condividere il metastore tra Hive e Spark, è possibile modificare la proprietà metastore.catalog.default in hive nel cluster Spark. Questa proprietà è disponibile in Ambari Advanced spark2-hive-site-override. È importante comprendere che la condivisione del metastore funziona solo per le tabelle hive esterne. Questa operazione non funzionerà se sono presenti tabelle hive interne/gestite o tabelle ACID.
Aggiornamento della password personalizzata del metastore Hive
Quando si utilizza un database metastore Hive personalizzato, è possibile modificare la password del DB SQL. Se si modifica la password del metastore personalizzato, i servizi Hive non funzionano finché la password nel cluster HDInsight non viene aggiornata.
Per aggiornare la password del metastore Hive occorre:
- Aprire l'interfaccia utente di Ambari.
- Fare clic su Servizi --> Hive --> Configurazioni --> Database.
- Aggiornare i campi Password del database con la nuova password del database del server SQL.
- Fare clic sul pulsante Test connessione per verificare che la nuova password funzioni.
- Fare clic sul pulsante Salva.
- Seguire le indicazioni di Ambari per salvare la configurazione e riavviare i servizi richiesti.
Metastore Apache Oozie
Apache Oozie è un sistema di coordinamento dei flussi di lavoro che consente di gestire i processi Hadoop. Oozie supporta i processi Hadoop per Apache MapReduce, Pig, Hive e altri. Oozie usa un metastore per archiviare i dettagli sui flussi di lavoro. Per ottenere un miglioramento delle prestazioni quando si usa Oozie, è possibile usare il database SQL di Azure come metastore personalizzato. Il metastore fornisce l'accesso ai dati di processo Oozie dopo l'eliminazione del cluster.
Per istruzioni sulla creazione di un metastore Oozie con il database SQL di Azure, vedere come usare Apache Oozie per i flussi di lavoro.
Aggiornamento della password personalizzata del metastore Oozie
Quando si utilizza un database metastore Oozie personalizzato, è possibile modificare la password del DB SQL. Se si modifica la password del metastore personalizzato, i servizi Oozie non funzionano finché la password nel cluster HDInsight non viene aggiornata.
Per aggiornare la password del metastore Oozie occorre:
- Aprire l'interfaccia utente di Ambari.
- Fare clic su Servizi --> Oozie --> Configurazioni --> Database.
- Aggiornare i campi Password del database con la nuova password del database del server SQL.
- Fare clic sul pulsante Test connessione per verificare che la nuova password funzioni.
- Fare clic sul pulsante Salva.
- Seguire le indicazioni di Ambari per salvare la configurazione e riavviare i servizi richiesti.
Database Ambari personalizzato
Per utilizzare un database esterno con Apache Ambari su HDInsight, vedere Database Apache Ambari personalizzato.