Esercitazione: Creare un'applicazione di Scala Maven per Apache Spark in HDInsight usando IntelliJ
In questa esercitazione si apprenderà come creare un'applicazione Apache Spark scritta in Scala usando Apache Maven con IntelliJ IDEA. Il sistema di compilazione usato in questo articolo è Apache Maven e all'inizio viene usato un archetipo Maven per Scala esistente fornito da IntelliJ IDEA. La creazione di un'applicazione Scala in IntelliJ IDEA comporta i passaggi seguenti:
- Usare Maven come sistema di compilazione.
- Aggiornare il file del modello a oggetti dei progetti (POM) per risolvere le dipendenze del modulo Spark.
- Scrivere l'applicazione in Scala.
- Generare un file con estensione jar che può essere inviato ai cluster HDInsight Spark.
- Eseguire l'applicazione in un cluster Spark usando Livy.
In questa esercitazione apprenderai a:
- Installare il plug-in Scala per IntelliJ IDEA
- Usare IntelliJ per sviluppare un'applicazione in Scala Maven
- Creare un progetto Scala autonomo
Prerequisiti
Un cluster Apache Spark in HDInsight. Per istruzioni, vedere l'articolo dedicato alla creazione di cluster Apache Spark in Azure HDInsight.
Kit di sviluppo di Oracle Java. Questa esercitazione usa Java versione 8.0.202.
Ambiente IDE Java. Questo articolo usa IntelliJ IDEA Community 2018.3.4.
Azure Toolkit for IntelliJ. Vedere Installazione di Azure Toolkit for IntelliJ.
Installare il plug-in Scala per IntelliJ IDEA
Per installare il plug-in di Scala, seguire questa procedura:
Aprire IntelliJ IDEA.
Nella schermata iniziale, passare a Configure (Configura)>Plugin per aprire la finestra Plugin.
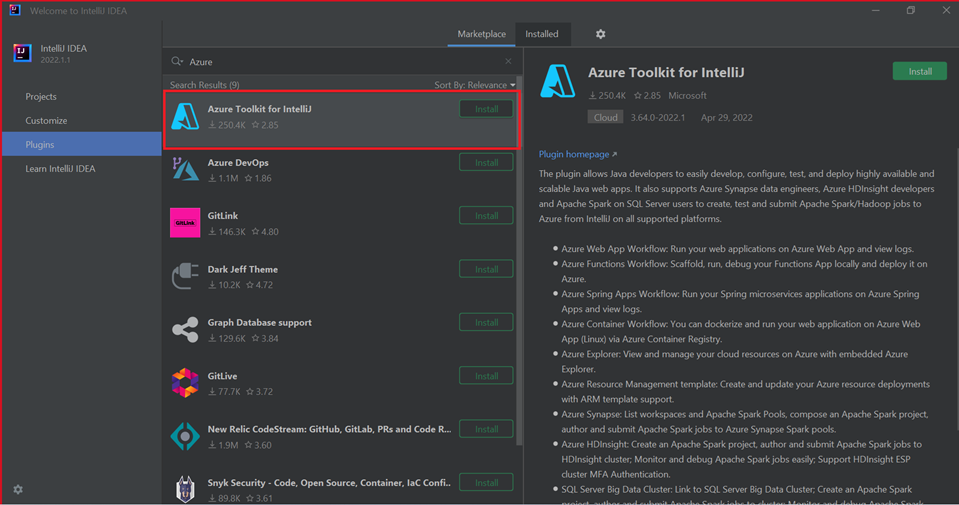
Selezionare Installa per Azure Toolkit for IntelliJ.
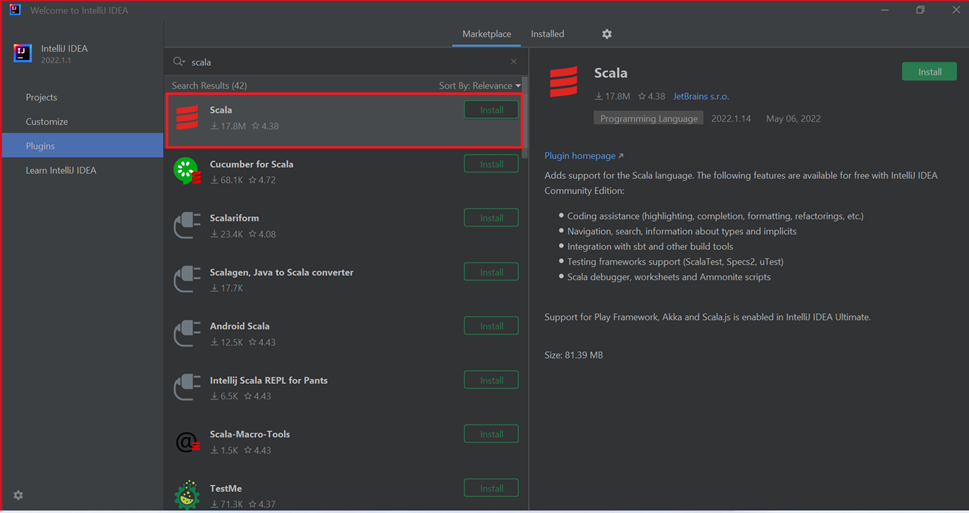
Selezionare Installa per il plug-in Scala che è disponibile nella nuova finestra.
Dopo che il plug-in è stato installato correttamente, è necessario riavviare l'IDE.
Usare IntelliJ per creare un'applicazione
Avviare IntelliJ IDEA e selezionare Crea nuovo progetto per aprire la finestra Nuovo progetto.
Selezionare Apache Spark/HDInsight nel riquadro sinistro.
Selezionare Progetto Spark (Scala) dalla finestra principale.
Nell'elenco a discesa Strumento di compilazione selezionare uno dei valori seguenti:
- Maven, per ottenere supporto per la creazione guidata di un progetto Scala.
- SBT, per la gestione delle dipendenze e la compilazione per il progetto Scala.
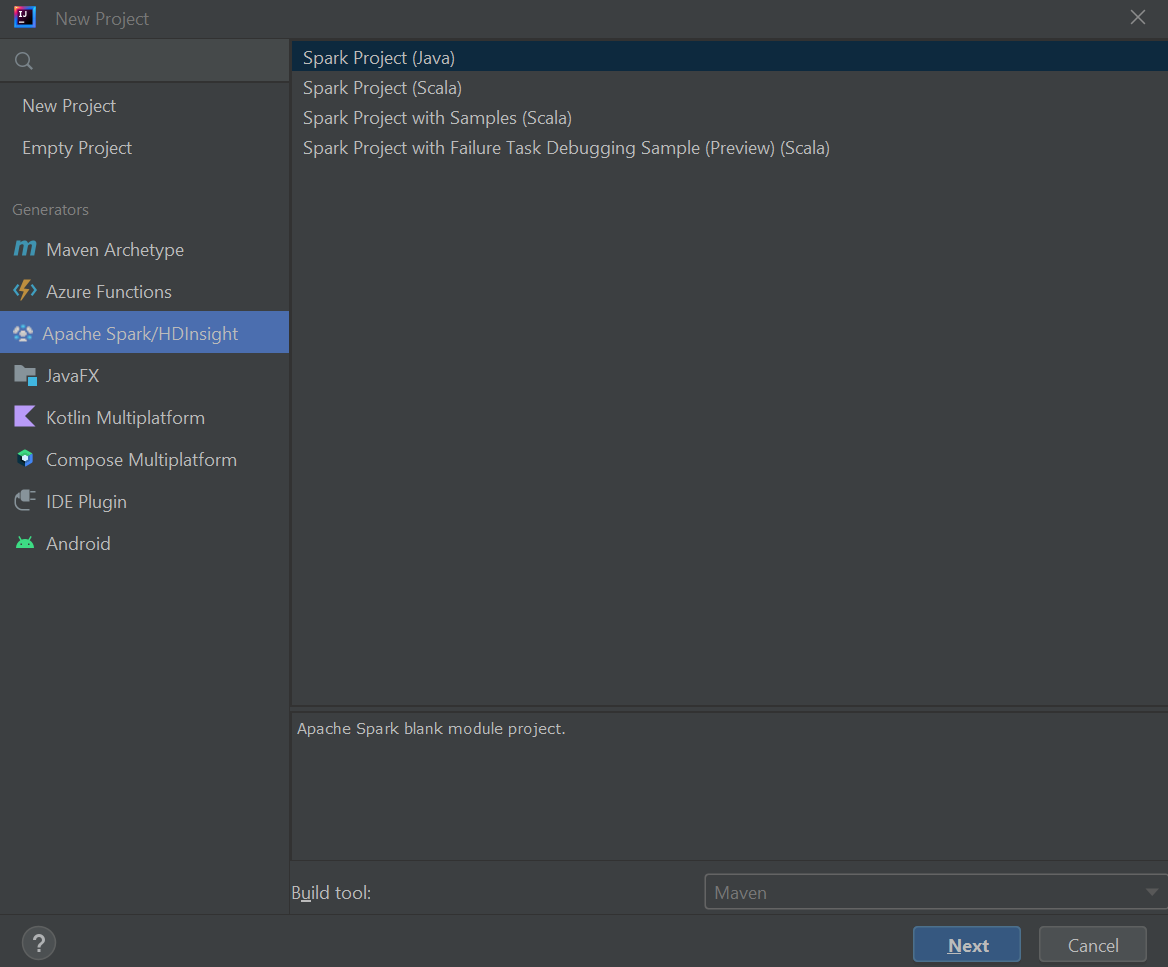
Selezionare Avanti.
Nella finestra Nuovo progetto specificare le informazioni seguenti:
Proprietà Descrizione Nome progetto Immetti un nome. Posizione del progetto Immettere il percorso in cui salvare il progetto. Project SDK (SDK progetto) Questo campo sarà vuoto quando si usa IDEA per la prima volta. Selezionare New (Nuovo) e passare al proprio JDK. Versione Spark La creazione guidata integra la versione corretta dell'SDK di Spark e Scala. Se la versione del cluster Spark è precedente alla 2.0, selezionare Spark 1.x. In caso contrario, selezionare Spark2.x. In questo esempio viene usata la versione Spark 2.3.0 (Scala 2.11.8). 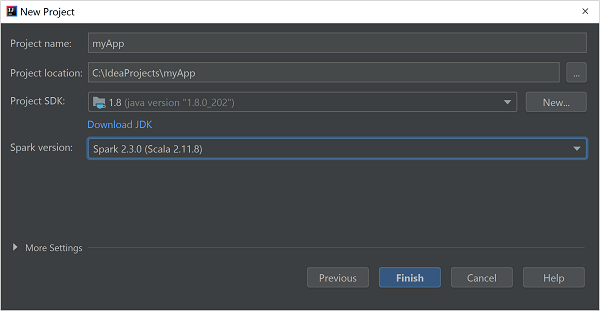
Selezionare Fine.
Creare un progetto Scala autonomo
Avviare IntelliJ IDEA e selezionare Crea nuovo progetto per aprire la finestra Nuovo progetto.
Selezionare Maven nel riquadro sinistro.
Specificare un valore per Project SDK. Se vuoto, selezionare New (Nuovo) e passare alla directory di installazione Java.
Selezionare la casella di controllo Create from archetype (Crea da archetipo).
Nell'elenco degli archetipi selezionare
org.scala-tools.archetypes:scala-archetype-simple. Questo archetipo crea la struttura di directory appropriata e scarica le dipendenze predefinite necessarie per scrivere un programma Scala.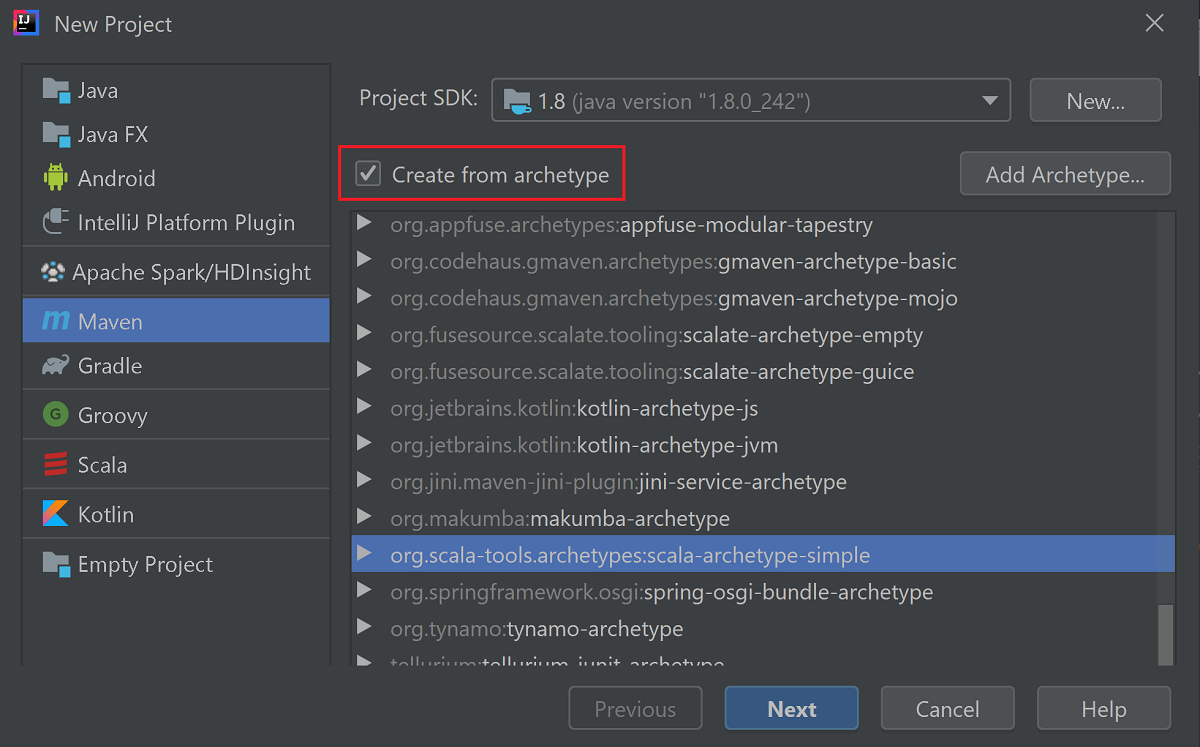
Selezionare Avanti.
Espandere Artifact Coordinates (Coordinate artefatto). Specificare i valori pertinenti per GroupId (ID gruppo) e ArtifactId (ID artefatto). I valori per Name (Nome) e Location (Località) verranno inseriti automaticamente. In questa esercitazione vengono usati i valori seguenti:
- GroupId: com.microsoft.spark.example
- ArtifactId: SparkSimpleApp
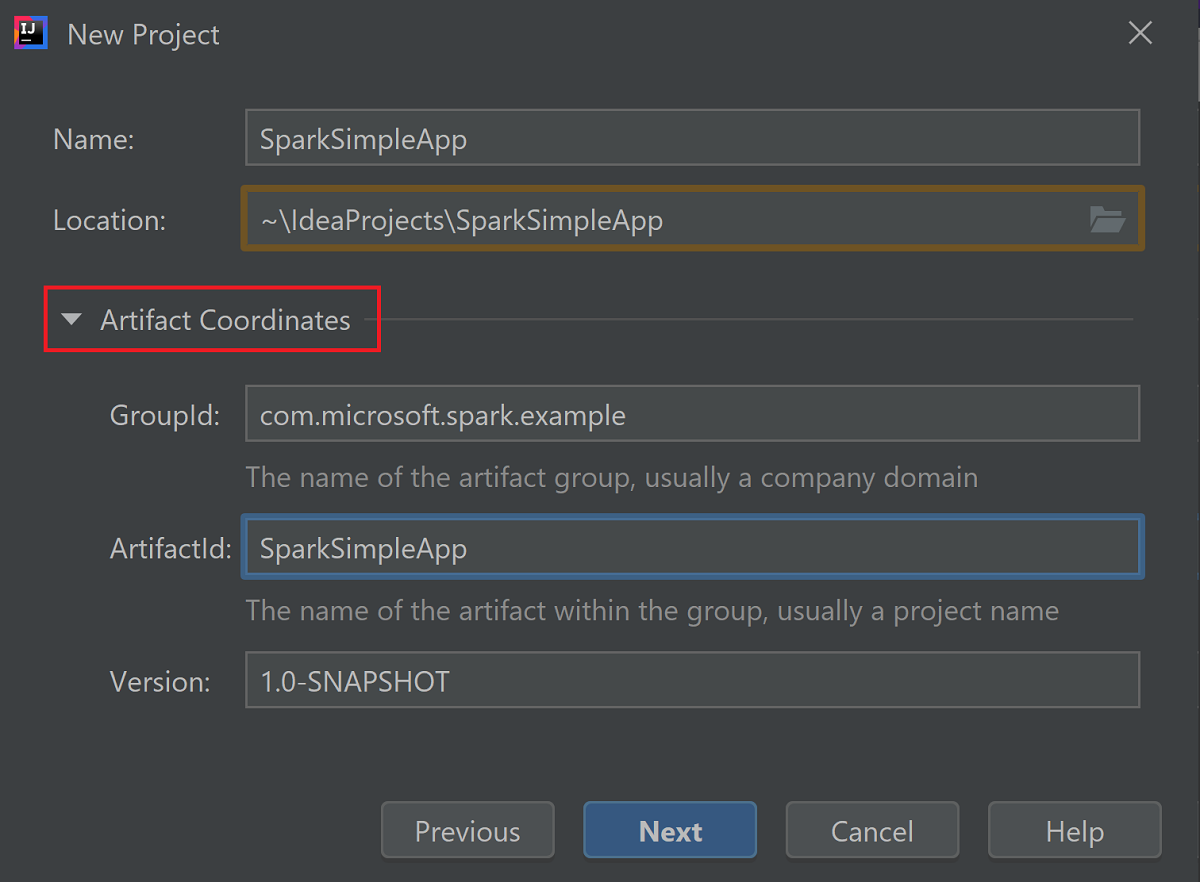
Selezionare Avanti.
Rivedere le impostazioni e selezionare Next (Avanti).
Verificare il nome e la posizione del progetto e quindi scegliere Finish (Fine). L'importazione del progetto richiederà alcuni minuti.
Dopo aver importato il progetto, nel riquadro sinistro passare a SparkSimpleApp>src>test>scala>com>microsoft>spark>example. Fare clic con il pulsante destro del mouse su MySpec e quindi scegliere Elimina. Non è necessario questo file per l'applicazione. Nella finestra di dialogo, selezionare OK.
Nei passaggi successivi si aggiornerà il file pom.xml per definire le dipendenze per l'applicazione Spark in Scala. Affinché tali dipendenze vengano scaricate e risolte automaticamente, è necessario configurare Maven.
Nel menu File selezionare Settings per aprire la finestra Settings (Impostazioni).
Nella finestra Settings (Impostazioni) passare a Build, Execution, Deployment (Compilazione, esecuzione, distribuzione) >Build Tools (Strumenti di compilazione) >Maven>Importing (Importazione).
Selezionare la casella di controllo Import Maven projects automatically (Importa automaticamente progetti Maven).
Selezionare Apply (Applica) e quindi OK. Verrà visualizzata nuovamente la finestra del progetto.
:::image type="content" source="./media/apache-spark-create-standalone-application/configure-maven-download.png" alt-text="Configure Maven for automatic downloads." border="true":::Nel riquadro sinistro, passare a src>main>scala>com.microsoft.spark.example, quindi fare doppio clic su App per aprire App.scala.
Aprire e sostituire il codice di esempio esistente con il codice seguente e salvare le modifiche. Questo codice legge i dati da HVAC.csv disponibile in tutti i cluster HDInsight Spark. Recupera le righe con una sola cifra nella sesta colonna e scrive l'output in /HVACOut nel contenitore di archiviazione predefinito per il cluster.
package com.microsoft.spark.example import org.apache.spark.SparkConf import org.apache.spark.SparkContext /** * Test IO to wasb */ object WasbIOTest { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("WASBIOTest") val sc = new SparkContext(conf) val rdd = sc.textFile("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasb:///HVACout") } }Nel riquadro sinistro, fare doppio clic su pom.xml.
Aggiungere i segmenti seguenti in
<project>\<properties>:<scala.version>2.11.8</scala.version> <scala.compat.version>2.11.8</scala.compat.version> <scala.binary.version>2.11</scala.binary.version>Aggiungere i segmenti seguenti in
<project>\<dependencies>:<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>2.3.0</version> </dependency>Save changes to pom.xml.Creare il file con estensione jar. IntelliJ IDEA consente di creare un file con estensione jar come elemento di un progetto. Seguire questa procedura.
Dal menu File selezionare Project Structure... (Struttura progetto).
Dalla finestra Project Structure (Struttura progetto) passare ad Artifacts>il simbolo più +>JAR>From modules with dependencies....
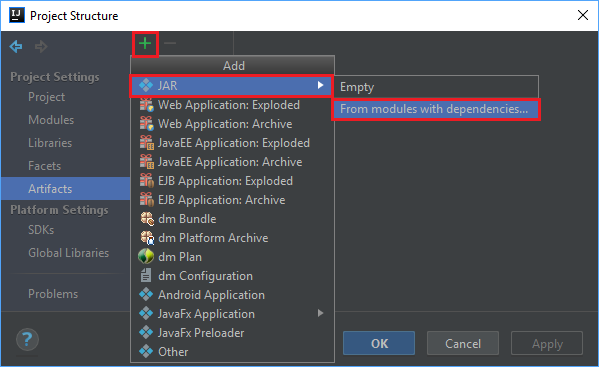
Nella finestra Create JAR from Modules (Crea file con estensione jar da moduli) selezionare l'icona della cartella nella casella di testo Main Class (Classe principale).
Nella finestra Select Main Class (Seleziona classe principale) selezionare la classe visualizzata per impostazione predefinita e quindi scegliere OK.
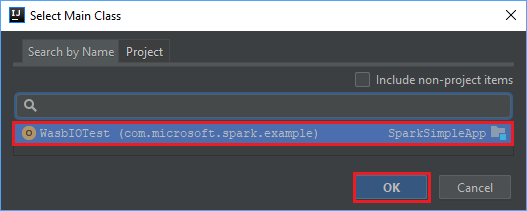
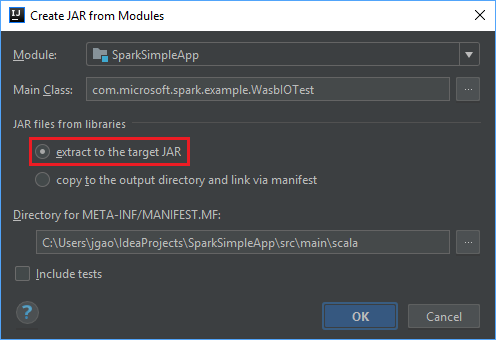
Nella finestra Create JAR from Modules (Crea file con estensione jar da moduli) verificare che l'opzione extract to the target JAR (Estrai nel file con estensione jar di destinazione) sia selezionata e quindi scegliere OK. Questa impostazione crea un singolo file con estensione jar con tutte le dipendenze.
Nella scheda Output Layout sono elencati tutti i file JAR inclusi nel progetto Maven. È possibile selezionare ed eliminare quelli in cui l'applicazione Scala non ha dipendenze dirette. Per l'applicazione creata in questo caso, è possibile rimuovere tutti i file tranne l'ultimo (output di compilazione di SparkSimpleApp). Selezionare i file con estensione jar da eliminare e quindi selezionare il simbolo negativo -.
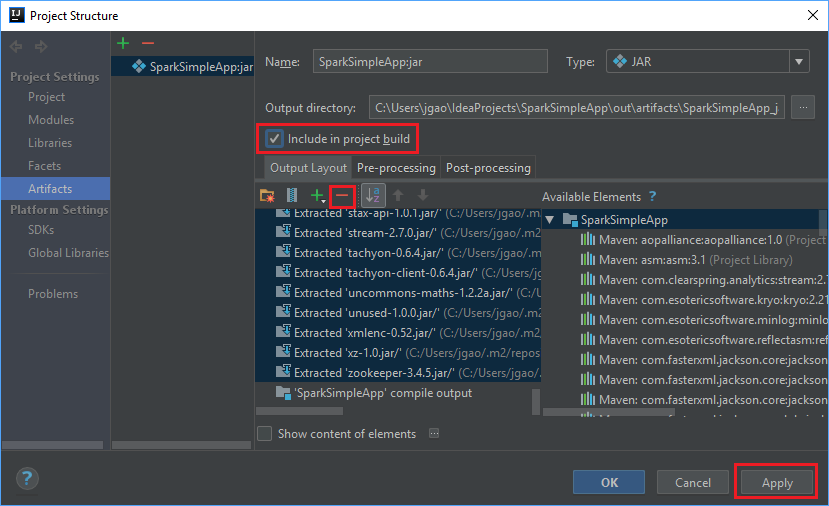
Assicurarsi che la casella di controllo Include in project build (Includi nella compilazione del progetto) sia selezionata. Questa opzione garantisce che il file jar venga creato ogni volta che il progetto viene creato o aggiornato. Selezionare Apply (Applica) e quindi OK.
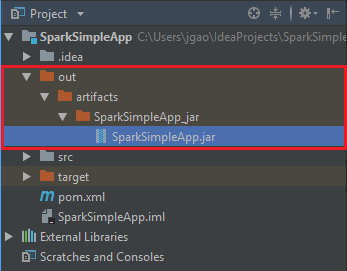
Per creare il file jar, passare a Build>Build Artifacts>Build. Il progetto verrà compilato in circa 30 secondi. Il file JAR di output viene creato in \out\artifacts.
Eseguire l'applicazione nel cluster Apache Spark
Per eseguire l'applicazione nel cluster, è possibile usare gli approcci seguenti:
Copiare il file JAR dell'applicazione nel BLOB del servizio di archiviazione di Azure associato al cluster. A tale scopo è possibile usare AzCopy, un'utilità della riga di comando. È possibile usare molti altri client per caricare i dati. Altre informazioni in merito sono disponibili in Caricare dati per processi Apache Hadoop in HDInsight.
Usare Apache Livy per inviare un processo dell'applicazione in modalità remota al cluster Spark. I cluster Spark in HDInsight includono Livy che espone gli endpoint REST per inviare in modalità remota i processi Spark. Per altre informazioni, vedere Inviare processi Apache Spark in modalità remota usando Apache Livy con cluster Spark in HDInsight.
Pulire le risorse
Se non si intende continuare a usare questa applicazione, eliminare il cluster creato con i passaggi seguenti:
Accedere al portale di Azure.
Nella casella Ricerca in alto digitare HDInsight.
Selezionare Cluster HDInsight in Servizi.
Nell'elenco di cluster HDInsight visualizzato selezionare ... accanto al cluster creato per questa esercitazione.
Selezionare Elimina. Selezionare Sì.
Passaggio successivo
In questo articolo è stato descritto come creare un'applicazione Scala di Apache Spark. Passare all'articolo successivo per informazioni su come eseguire questa applicazione in un cluster HDInsight Spark tramite Livy.