Installare Jupyter Notebook nel computer e connettersi ad Apache Spark in HDInsight
Questo articolo illustra come installare Jupyter Notebook con i kernel PySpark personalizzati (per Python) e Apache Spark (per Scala) con Spark magic. Si connette quindi il notebook a un cluster HDInsight.
L'installazione di Jupyter e la connessione ad Apache Spark in HDInsight comporta quattro passaggi chiave.
- Configurare il cluster Spark.
- Installare Jupyter Notebook.
- Installare i kernel PySpark e Spark con il magic Spark.
- Configurare il magic Spark per l'accesso al cluster Spark in HDInsight.
Per altre informazioni sui kernel personalizzati e sui magic Spark, vedere Kernel disponibili per jupyter Notebook con cluster Apache Spark Linux in HDInsight.
Prerequisiti
Un cluster Apache Spark in HDInsight. Per istruzioni, vedere l'articolo dedicato alla creazione di cluster Apache Spark in Azure HDInsight. Il notebook locale si connette al cluster HDInsight.
Familiarità nell'uso di Jupyter Notebook con Spark in HDInsight.
Installare Jupyter Notebook nel computer
Installare Python prima di installare Jupyter Notebooks. La distribuzione di Anaconda installerà sia Python che Jupyter Notebook.
Scaricare il programma di installazione di Anaconda per la piattaforma in uso ed eseguirlo. Quando si esegue l'installazione guidata, assicurarsi di selezionare l'opzione per l'aggiunta di Anaconda alla variabile PATH. Vedere anche Installazione di Jupyter con Anaconda.
Installare Spark magic
Immettere il comando
pip install sparkmagic==0.13.1per installare Spark magic per i cluster HDInsight versione 3.6 e 4.0. Vedere anche la documentazione di Sparkmagic.Verificare che
ipywidgetssia installato correttamente eseguendo il comando seguente:jupyter nbextension enable --py --sys-prefix widgetsnbextension
Installare i kernel PySpark e Spark
Identificare dove
sparkmagicè installato immettendo il comando seguente:pip show sparkmagicModificare quindi la directory di lavoro impostando il percorso identificato con il comando precedente.
Nella nuova directory di lavoro immettere uno o più dei comandi seguenti per installare i kernel desiderati:
Kernel Comando Spark jupyter-kernelspec install sparkmagic/kernels/sparkkernelSparkR jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernelFacoltativo. Immettere il comando seguente per abilitare l'estensione del server:
jupyter serverextension enable --py sparkmagic
Configurare il magic Spark per la connessione al cluster HDInsight Spark
In questa sezione viene configurato il magic Spark installato in precedenza per connettersi a un cluster Apache Spark.
Avviare la shell Python con il comando seguente:
pythonLe informazioni di configurazione di Jupyter sono in genere archiviate nella home directory dell'utente. Immettere il comando seguente per identificare la home directory e creare una cartella denominata .sparkmagic. Verrà restituito il percorso completo.
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit()All'interno della cartella
.sparkmagiccreare un file denominato config.json e aggiungere il frammento JSON seguente al suo interno.{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }Apportare le modifiche seguenti al file:
Valore del modello Nuovo valore {U edizione Standard RNAME} Account di accesso al cluster, il valore predefinito è admin.{CLUSTERDNSNAME} Nome cluster {BA edizione Standard 64ENCODEDPASSWORD} Password con codifica Base64 per la password effettiva. È possibile generare una password base64 in https://www.url-encode-decode.com/base64-encode-decode/. "livy_server_heartbeat_timeout_seconds": 60Mantenere se si usa sparkmagic 0.12.7(cluster v3.5 e v3.6). Se si usasparkmagic 0.2.3(cluster v3.4), sostituire con"should_heartbeat": true.È possibile visualizzare un file di esempio completo in config.json di esempio.
Suggerimento
Gli heartbeat vengono inviati per assicurare che le sessioni non vengano perse. Quando un computer va in sospensione o viene arrestato, l'heartbeat non verrà inviato e la sessione verrà quindi eliminata. Per disabilitare questo comportamento per i cluster v3.4, è possibile impostare la configurazione di Livy
livy.server.interactive.heartbeat.timeoutsu0dall'interfaccia utente di Ambari. Per i cluster v3.5, se non si imposta la configurazione 3.5 precedente, la sessione non verrà eliminata.Avviare Jupyter. Usare il comando seguente dal prompt dei comandi.
jupyter notebookVerificare che sia possibile usare il magic Spark disponibile con i kernel. Effettuare i seguenti passaggi.
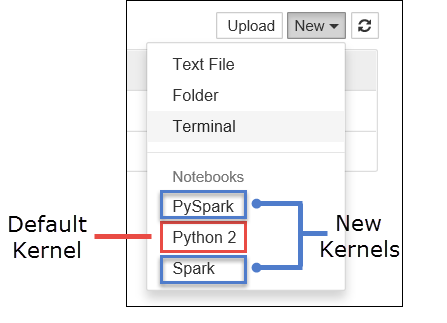
a. Creare un nuovo notebook. Nell'angolo a destra selezionare Nuovo. Dovrebbe essere visualizzato il kernel predefinito Python 2 o Python 3 e i kernel installati. I valori effettivi possono variare a seconda delle scelte di installazione. Selezionare PySpark.
Importante
Dopo aver selezionato Nuova verifica la shell per eventuali errori. Se viene visualizzato l'errore
TypeError: __init__() got an unexpected keyword argument 'io_loop'potrebbe verificarsi un problema noto con determinate versioni di Tornado. In tal caso, arrestare il kernel e quindi effettuare il downgrade dell'installazione tornado con il comando seguente:pip install tornado==4.5.3.b. Eseguire il frammento di codice seguente.
%%sql SELECT * FROM hivesampletable LIMIT 5Se è stato possibile recuperare l'output, viene verificata la connessione al cluster HDInsight.
Se si vuole aggiornare la configurazione del notebook per connettersi a un cluster diverso, aggiornare il config.json con il nuovo set di valori, come illustrato nel passaggio 3 precedente.
Perché installare Jupyter nel computer locale
Motivi per installare Jupyter nel computer e quindi connetterlo a un cluster Apache Spark in HDInsight:
- Offre la possibilità di creare i notebook in locale, testare l'applicazione in un cluster in esecuzione e quindi caricare i notebook nel cluster. Per caricare i notebook nel cluster, è possibile caricarli usando Jupyter Notebook in esecuzione o il cluster oppure salvarli nella
/HdiNotebookscartella nell'account di archiviazione associato al cluster. Per altre informazioni su come vengono archiviati i notebook nel cluster, vedere Dove sono archiviati i notebook di Jupyter? - Con i notebook disponibili in locale è possibile connettersi a cluster Spark diversi in base alle esigenze dell'applicazione.
- È possibile usare GitHub per implementare un sistema di controllo del codice sorgente e usare il controllo della versione per il notebook. È anche possibile avere a disposizione un ambiente di collaborazione in cui più utenti possono lavorare allo stesso notebook.
- È possibile lavorare con i notebook in locale anche senza avere un cluster. È necessario avere un cluster solo per eseguire i test dei notebook, non per gestire manualmente i notebook o un ambiente di sviluppo.
- Potrebbe essere più semplice configurare il proprio ambiente di sviluppo locale rispetto a quello di configurare l'installazione di Jupyter nel cluster. È possibile sfruttare tutti i software installati in locale senza configurare uno o più cluster remoti.
Avviso
Con Jupyter installato nel computer locale più utenti possono eseguire contemporaneamente lo stesso notebook nello stesso cluster Spark. In questo caso, vengono create più sessioni di Livy. Se si verifica un problema e si vuole eseguire il debug, tenere traccia della sessione di Livy che appartiene l'utente sarà un'attività complessa.