Gestire i timeout della stored procedure nel connettore SQL per App per la logica di Azure
Si applica a: App per la logica di Azure (consumo)
Quando l'app per la logica funziona con set di risultati così grandi che il connettore SQL non restituisce tutti i risultati contemporaneamente o se si vuole più controllare le dimensioni e la struttura per i set di risultati, è possibile creare una stored procedure che organizza i risultati nel modo desiderato. Il connettore SQL offre molte funzionalità back-end che è possibile accedere usando App per la logica di Azure in modo che sia possibile automatizzare più facilmente le attività aziendali che funzionano con tabelle di database SQL.
Ad esempio, quando si ottengono o inseriscono più righe, l'app per la logica può scorrere queste righe usando un ciclo Until entro questi limiti. Tuttavia, quando l'app per la logica deve funzionare con migliaia o milioni di righe, è necessario ridurre al minimo i costi derivanti dalle chiamate al database. Per altre informazioni, vedere Gestire i dati bulk usando il connettore SQL.
Limite di timeout per l'esecuzione della stored procedure
Il connettore SQL ha un limite di timeout della stored procedure inferiore a 2 minuti. Alcune stored procedure potrebbero richiedere più tempo di questo limite per completare, causando un 504 Timeout errore. A volte questi processi a esecuzione prolungata vengono codificati come stored procedure in modo esplicito per questo scopo. A causa del limite di timeout, chiamare queste procedure da App per la logica di Azure potrebbe creare problemi. Anche se il connettore SQL non supporta in modo nativo una modalità asincrona, è possibile risolvere questo problema e simulare questa modalità usando un trigger di completamento SQL, una query pass-through SQL nativa, una tabella di stato e processi lato server. Per questa attività, è possibile usare Azure Elastic Job Agent per Azure SQL Database. Per SQL Server locale e Istanza gestita di SQL di Azure, è possibile usare la SQL Server Agent.
Si supponga, ad esempio, di avere la stored procedure a esecuzione prolungata seguente, che richiede più tempo del limite di timeout per completare l'esecuzione. Se si esegue questa stored procedure da un'app per la logica usando il connettore SQL, viene visualizzato un HTTP 504 Gateway Timeout errore come risultato.
CREATE PROCEDURE [dbo].[WaitForIt]
@delay char(8) = '00:03:00'
AS
BEGIN
SET NOCOUNT ON;
WAITFOR DELAY @delay
END
Anziché chiamare direttamente la stored procedure, è possibile eseguire in modo asincrono la procedura in background usando un agente di processo. È possibile archiviare gli input e gli output in una tabella di stato che è quindi possibile interagire con tramite l'app per la logica. Se non sono necessari gli input e gli output oppure se si scrivono già i risultati in una tabella nella stored procedure, è possibile semplificare questo approccio.
Importante
Assicurarsi che la stored procedure e tutti i processi siano idempotenti, che significa che possono essere eseguiti più volte senza influire sui risultati. Se l'elaborazione asincrona ha esito negativo o timeout, l'agente di processo potrebbe riprovare il passaggio e quindi la stored procedure, più volte. Per evitare la duplicazione dell'output, prima di creare oggetti, esaminare queste procedure consigliate e approcci.
La sezione successiva descrive come usare Azure Elastic Job Agent per Azure SQL Database. Per SQL Server e Istanza gestita di SQL di Azure, è possibile usare la SQL Server Agent. Alcuni dettagli di gestione differiscono, ma i passaggi fondamentali rimangono uguali alla configurazione di un agente di processo per Azure SQL Database.
Agente del processo per Azure SQL Database
Per creare un processo che può eseguire la stored procedure per Azure SQL Database, usare Azure Elastic Job Agent. Creare l'agente di processo nel portale di Azure. Questo approccio aggiungerà diverse stored procedure al database usato dall'agente, noto anche come database agente. È quindi possibile creare un processo che esegue la stored procedure nel database di destinazione e acquisisce l'output al termine.
Prima di poter creare il processo, è necessario configurare autorizzazioni, gruppi e destinazioni, come descritto dalla documentazione completa per Azure Elastic Job Agent. È anche necessario creare una tabella di supporto nel database di destinazione, come descritto nelle sezioni seguenti.
Creare una tabella di stato per la registrazione dei parametri e l'archiviazione degli input
I processi di SQL Agent non accettano parametri di input. Nel database di destinazione creare invece una tabella di stato in cui registrare i parametri e archiviare gli input da usare per chiamare le stored procedure. Tutti i passaggi del processo dell'agente vengono eseguiti nel database di destinazione, ma le stored procedure del processo vengono eseguite nel database dell'agente.
Per creare la tabella di stato, usare questo schema:
CREATE TABLE [dbo].[LongRunningState](
[jobid] [uniqueidentifier] NOT NULL,
[rowversion] [timestamp] NULL,
[parameters] [nvarchar](max) NULL,
[start] [datetimeoffset](7) NULL,
[complete] [datetimeoffset](7) NULL,
[code] [int] NULL,
[result] [nvarchar](max) NULL,
CONSTRAINT [PK_LongRunningState] PRIMARY KEY CLUSTERED
( [jobid] ASC
)WITH (STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
Ecco come viene visualizzata la tabella risultante in SQL Server Management Studio (SMSS):
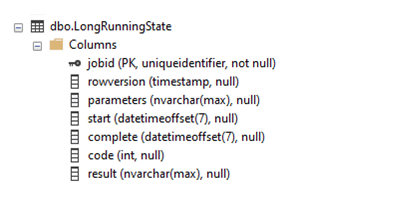
Per garantire prestazioni ottimali e assicurarsi che il processo dell'agente possa trovare il record associato, la tabella usa l'ID di esecuzione del processo (jobid) come chiave primaria. Se si vuole, è anche possibile aggiungere singole colonne per i parametri di input. Lo schema descritto in precedenza può gestire più parametri, ma è limitato alle dimensioni calcolate da NVARCHAR(MAX).
Creare un processo di primo livello per eseguire la stored procedure
Per eseguire la stored procedure a esecuzione prolungata, creare questo agente di processo di primo livello nel database dell'agente:
EXEC jobs.sp_add_job
@job_name='LongRunningJob',
@description='Execute Long-Running Stored Proc',
@enabled = 1
Aggiungere ora i passaggi al processo che parametrizza, eseguire e completare la stored procedure. Per impostazione predefinita, un passaggio del processo viene eseguito dopo 12 ore. Se la stored procedure richiede più tempo o se si vuole che la procedura venga timeout in precedenza, è possibile modificare il step_timeout_seconds parametro in un altro valore specificato in secondi. Per impostazione predefinita, un passaggio include 10 tentativi predefiniti con un timeout backoff tra ogni tentativo, che è possibile usare per sfruttare i vantaggi.
Ecco i passaggi da aggiungere:
Attendere che i parametri vengano visualizzati nella
LongRunningStatetabella.Questo primo passaggio attende che i parametri venga aggiunto nella
LongRunningStatetabella, che si verifica subito dopo l'avvio del processo. Se l'ID di esecuzione del processo (jobid) non viene aggiunto allaLongRunningStatetabella, il passaggio ha esito negativo e il timeout di ripetizione o backoff predefinito esegue l'attesa:EXEC jobs.sp_add_jobstep @job_name='LongRunningJob', @step_name= 'Parameterize WaitForIt', @step_timeout_seconds = 30, @command= N' IF NOT EXISTS(SELECT [jobid] FROM [dbo].[LongRunningState] WHERE jobid = $(job_execution_id)) THROW 50400, ''Failed to locate call parameters (Step1)'', 1', @credential_name='JobRun', @target_group_name='DatabaseGroupLongRunning'Eseguire una query sui parametri dalla tabella di stato e passarli alla stored procedure. Questo passaggio esegue anche la procedura in background.
Se la stored procedure non richiede parametri, chiamare direttamente la stored procedure. In caso contrario, per passare il
@timespanparametro, usare ,@callparamsche è anche possibile estendere per passare parametri aggiuntivi.EXEC jobs.sp_add_jobstep @job_name='LongRunningJob', @step_name='Execute WaitForIt', @command=N' DECLARE @timespan char(8) DECLARE @callparams NVARCHAR(MAX) SELECT @callparams = [parameters] FROM [dbo].[LongRunningState] WHERE jobid = $(job_execution_id) SET @timespan = @callparams EXECUTE [dbo].[WaitForIt] @delay = @timespan', @credential_name='JobRun', @target_group_name='DatabaseGroupLongRunning'Completare il processo e registrare i risultati.
EXEC jobs.sp_add_jobstep @job_name='LongRunningJob', @step_name='Complete WaitForIt', @command=N' UPDATE [dbo].[LongRunningState] SET [complete] = GETUTCDATE(), [code] = 200, [result] = ''Success'' WHERE jobid = $(job_execution_id)', @credential_name='JobRun', @target_group_name='DatabaseGroupLongRunning'
Avviare il processo e passare i parametri
Per avviare il processo, usare una query nativa pass-through con l'azione Esegui una query SQL e eseguire immediatamente il push dei parametri del processo nella tabella di stato. Per fornire input all'attributo jobid nella tabella di destinazione, App per la logica aggiunge un ciclo Per ogni ciclo che esegue l'iterazione dell'output della tabella dall'azione precedente. Per ogni ID esecuzione del processo, eseguire un'azione Inserisci riga che usa l'output dei dati dinamici, , ResultSets JobExecutionIdper aggiungere i parametri per il processo per decomprimere e passare alla stored procedure di destinazione.
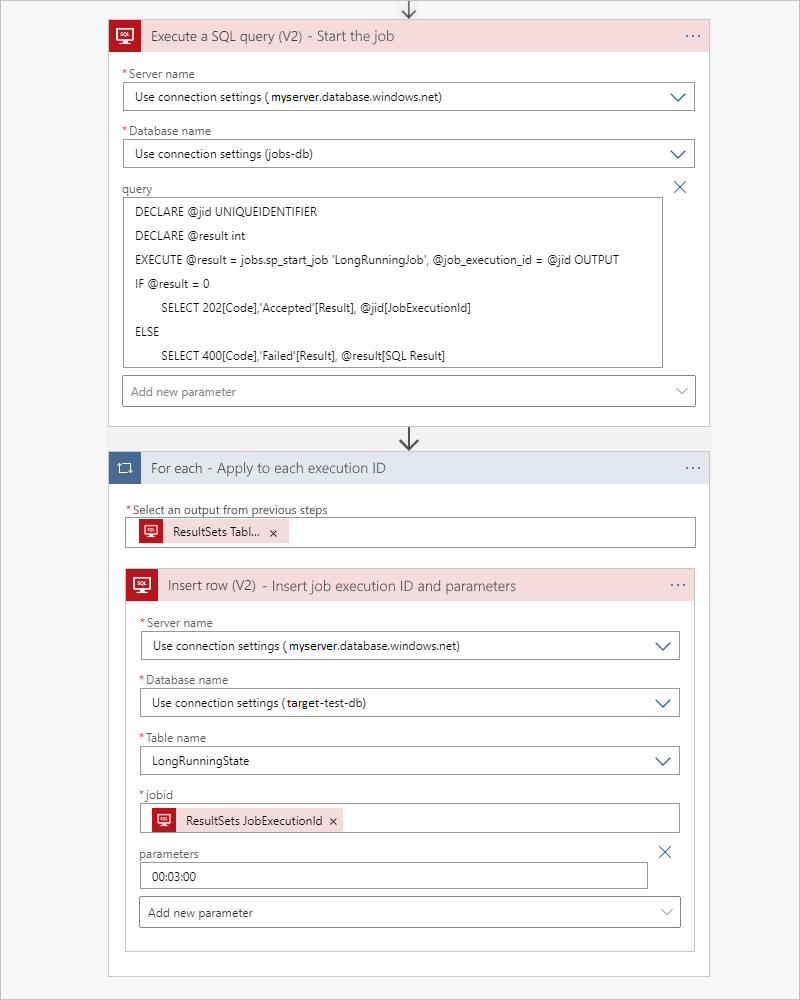
Al termine del processo, il processo aggiorna la LongRunningState tabella in modo che sia possibile attivare facilmente il risultato usando il trigger Quando un elemento viene modificato. Se non è necessario l'output o se si dispone già di un trigger che monitora una tabella di output, è possibile ignorare questa parte.
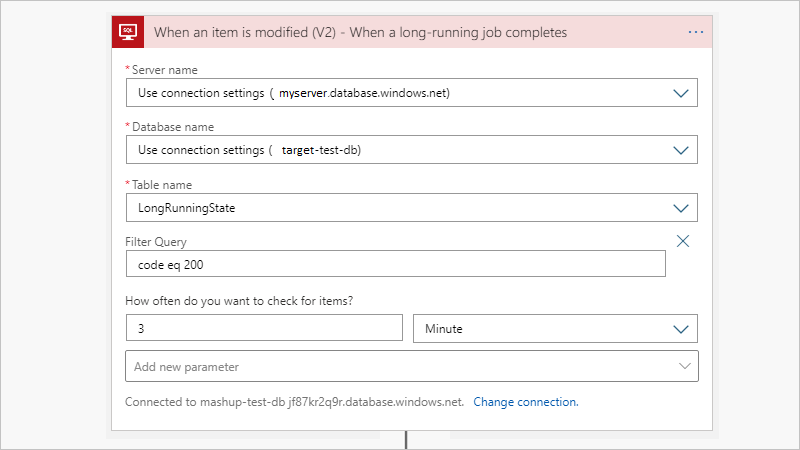
Agente di processo per SQL Server o Istanza gestita di SQL di Azure
Per lo stesso scenario, è possibile usare la SQL Server Agent per SQL Server in locale e Istanza gestita di SQL di Azure. Anche se alcuni dettagli di gestione differiscono, i passaggi fondamentali rimangono uguali alla configurazione di un agente di processo per Azure SQL Database.
Passaggi successivi
Connettersi a SQL Server, Azure SQL database o Istanza gestita di SQL di Azure