Join Data
Questo articolo descrive come usare il componente Join Data nella finestra di progettazione di Azure Machine Learning per unire due set di dati usando un'operazione di join in stile database.
Come configurare i dati di join
Per eseguire un join su due set di dati, devono essere correlati da una colonna chiave. Sono supportate anche chiavi composite che usano più colonne.
Aggiungere i set di dati da combinare e quindi trascinare il componente Join Data nella pipeline.
È possibile trovare il componente nella categoria Trasformazione dati, in Manipolazione.
Connettere i set di dati al componente Join Data .
Selezionare Avvia selettore di colonna per scegliere le colonne chiave. Ricordarsi di scegliere le colonne per gli input sia a sinistra che a destra.
Per una singola chiave:
Selezionare una singola colonna chiave per entrambi gli input.
Per una chiave composta:
Selezionare tutte le colonne chiave dall'input sinistro e dall'input destro nello stesso ordine. Il componente Join Data unisce le tabelle quando tutte le colonne chiave corrispondono. Selezionare l'opzione Consenti duplicati e mantenere l'ordine delle colonne nella selezione se l'ordine delle colonne non corrisponde alla tabella originale.
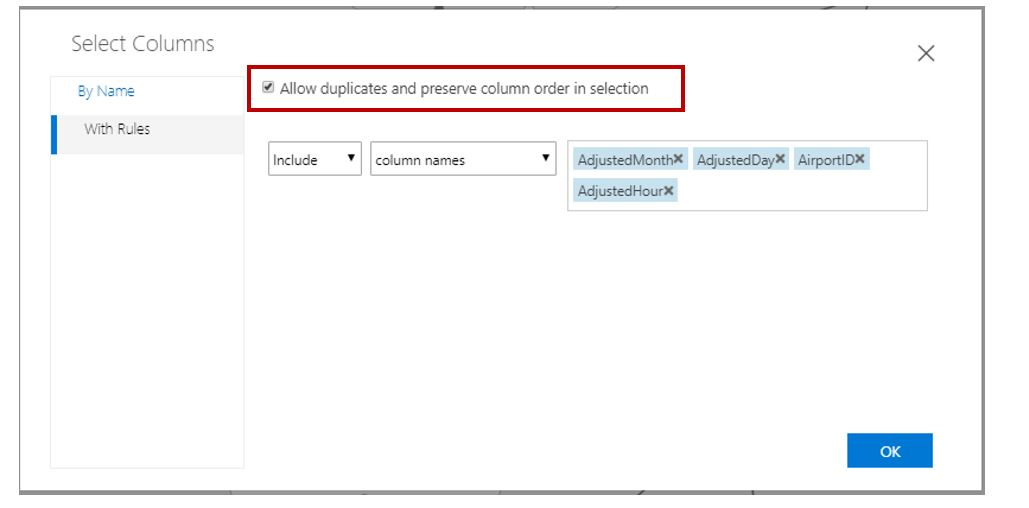
Selezionare l'opzione Maiuscole/minuscole se si desidera mantenere la distinzione tra maiuscole e minuscole in un join di colonna di testo.
Usare l'elenco a discesa Tipo di join per specificare come combinare i set di dati.
Inner Join: un inner join è l'operazione di join più comune. Restituisce le righe combinate solo quando i valori delle colonne chiave corrispondono.
Left Outer Join: un left outer join restituisce righe unite in join per tutte le righe della tabella a sinistra. Quando una riga della tabella a sinistra non contiene righe corrispondenti nella tabella a destra, la riga restituita contiene valori mancanti per tutte le colonne provenienti dalla tabella destra. È anche possibile specificare un valore di sostituzione per i valori mancanti.
Full Outer Join: un full outer join restituisce tutte le righe della tabella sinistra (table1) e dalla tabella a destra (table2).
Per ognuna delle righe di una tabella che non dispone di righe corrispondenti nell'altra, il risultato include una riga contenente valori mancanti.
Semi-join sinistro: un semi join sinistro restituisce solo i valori della tabella sinistra quando i valori delle colonne chiave corrispondono.
Per l'opzione Mantieni le colonne chiave corrette nella tabella unita in join:
- Selezionare questa opzione per visualizzare le chiavi di entrambe le tabelle di input.
- Deselezionare per restituire solo le colonne chiave dall'input sinistro.
Inviare la pipeline.
Per visualizzare i risultati, fare clic con il pulsante destro del mouse su Join Data (Join Data) e selezionare Visualize (Visualizza).
Passaggi successivi
Vedere il set di componenti disponibili per Azure Machine Learning.