Informazioni su Machine Learning automatizzato
SI APPLICA A:  Python SDK azure-ai-ml v2 (corrente)
Python SDK azure-ai-ml v2 (corrente)
Machine Learning automatizzato, noto anche come ML automatizzato o AutoML, è il processo che consente di automatizzare le attività ripetitive e dispendiose in termini di tempo legate allo sviluppo di modelli di Machine Learning. Consente a data scientist, analisti e sviluppatori di creare modelli di Machine Learning con scalabilità, efficienza e produttività elevate, garantendo al tempo stesso la qualità del modello. ML automatizzato in Azure Machine Learning si basa su un'analisi approfondita da parte della divisione Microsoft Research.
- Per i clienti con esperienza nell’uso del codice, installare Azure Machine Learning Python SDK. Introduzione a Esercitazione: eseguire il training di un modello di rilevamento oggetti (anteprima) con AutoML e Python.
Come funziona AutoML?
Durante il training, Azure Machine Learning crea numerose pipeline in parallelo che tentano di usare diversi algoritmi e parametri per conto dell'utente. Il servizio esegue l'iterazione tramite gli algoritmi di Machine Learning abbinati alle selezioni di funzionalità, in cui ogni iterazione produce un modello con un punteggio di training. Migliore è il punteggio per la metrica che si vuole ottimizzare, migliore è il modello considerato "adatto" ai dati. Il servizio si arresta quando raggiunge i criteri di uscita definiti nell'esperimento.
Con Azure Machine Learning, è possibile progettare ed eseguire gli esperimenti di training di Machine Learning automatizzato con i passaggi seguenti:
Identificare il problema di Machine Learning da risolvere: classificazione, previsione, regressione, visione artificiale o NLP.
Scegliere se si vuole un'esperienza code-first o un'esperienza Web senza codice: gli utenti che preferiscono un'esperienza code-first possono usare l’Azure Machine Learning SDKv2 o il Azure Machine Learning CLIv2. Introduzione a Esercitazione: eseguire il training di un modello di rilevamento oggetti con AutoML e Python. Gli utenti che preferiscono un'esperienza limitata o senza codice possono usare l’interfaccia Web in studio di Azure Machine Learning all'indirizzo https://ml.azure.com. Introduzione a Esercitazione: creare un modello di classificazione con ML automatizzato in Azure Machine Learning.
Specificare l'origine dei dati di training etichettati: è possibile trasferire i dati in Azure Machine Learning in molti modi diversi.
Configurare i parametri di Machine Learning automatizzato che determinano il numero di iterazioni su modelli diversi, le impostazioni degli iperparametri, la definizione delle funzionalità/pre-elaborazione avanzata e le metriche da esaminare quando si determina il modello migliore.
Inviare il processo di training.
Esaminare i risultati.
La figura seguente illustra questo processo.
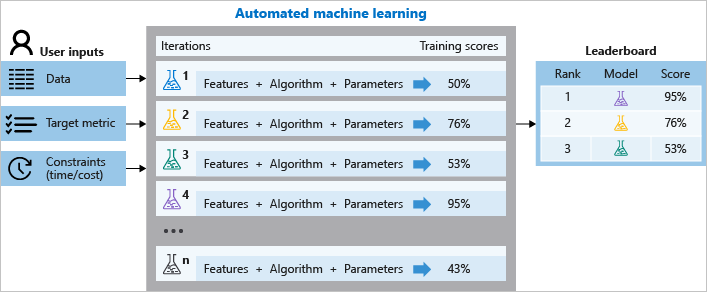
È possibile esaminare anche le informazioni registrate del processo, che contengono le metriche raccolte durante il processo. Il processo di training genera un oggetto Python serializzato (file .pkl) che contiene il modello e la pre-elaborazione dei dati.
Mentre la creazione di modelli è automatica, è anche possibile ottenere informazioni sull'importanza delle funzionalità per i modelli generati.
Quando usare AutoML: classificazione, regressione, previsione, visione artificiale e NLP
Applicare Machine Learning automatizzato in modo che Azure Machine Learning esegua il training e l'ottimizzazione di un modello usando la metrica di destinazione specificata. ML automatizzato semplifica il processo di sviluppo di modelli di Machine Learning e consente agli utenti, indipendentemente dal livello di esperienza di data science di ciascuno, di identificare una pipeline di Machine Learning end-to-end per qualsiasi problema.
I professionisti e gli sviluppatori di ML di tutti i settori possono usare Machine Learning automatizzato per:
- Implementare soluzioni di Machine Learning senza una conoscenza approfondita della programmazione
- Risparmiare tempo e risorse
- Applicare le procedure consigliate di data science
- Fornire efficaci soluzioni ai problemi
Classificazione
La classificazione è un tipo di apprendimento supervisionato in cui i modelli imparano a usare i dati di training e applicano tali informazioni ai nuovi dati. Azure Machine Learning offre funzionalità specifiche per queste attività, ad esempio la definizione delle funzionalità del testo per la rete neurale profonda per la classificazione. Per altre informazioni sulle opzioni di definizione delle funzionalità, vedere Definizione delle funzionalità dei dati. È inoltre possibile trovare l'elenco degli algoritmi supportati da AutoML nella sezione Algoritmi supportati.
L'obiettivo principale dei modelli di classificazione è quello di stimare le categorie in cui rientrano i nuovi dati in base alle informazioni sui dati di training. Esempi di classificazione comuni includono rilevamento delle frodi, riconoscimento della grafia e rilevamento degli oggetti.
Vedere un esempio di attività di classificazione e sull'uso di Machine Learning automatizzato in questi notebook Python: marketing bancario.
Regressione
Analogamente alla classificazione, anche quelle di regressione sono attività di apprendimento supervisionato comuni. Azure Machine Learning offre funzionalità specifiche per i problemi di regressione. Altre informazioni sulle opzioni di definizione delle funzionalità. È inoltre possibile trovare l'elenco degli algoritmi supportati da AutoML nella sezione Algoritmi supportati.
Diversamente dalla classificazione, dove i valori di output stimati sono categorici, i modelli di regressione stimano i valori di output numerici in base a predittori indipendenti. Nella regressione l'obiettivo è di stabilire la relazione tra le variabili indipendenti del predittore stimando il modo in cui una variabile influisce sulle altre. Ad esempio, il modello può predire il prezzo dell'automobile in base a caratteristiche come chilometri con un litro e classificazione di sicurezza.
Vedere un esempio di attività di regressione e sull'uso di Machine Learning automatizzato per le previsioni in questi notebook Python: Prestazioni hardware.
Previsione della serie temporale
La compilazione di previsioni è parte integrante di qualsiasi azienda, sia che si tratti di ricavi, scorte, vendite o richieste dei clienti. È possibile usare Machine Learning automatizzato per combinare tecniche e approcci e ottenere una previsione della serie temporale consigliata e di alta qualità. È possibile trovare l'elenco degli algoritmi supportati da AutoML nella sezione Algoritmi supportati.
Un esperimento di serie temporale automatizzato viene considerato un problema di regressione multivariata. I valori della serie temporale precedente vengono "trasformati tramite Pivot" per diventare dimensioni aggiuntive per il regressore insieme ad altri predittori. Questo approccio, a differenza dei metodi classici della serie temporale, ha il vantaggio di incorporare naturalmente più variabili contestuali e la relazione tra loro durante il training. Machine Learning automatizzato apprende un modello singolo, ma spesso con rami interni, per tutti gli elementi del set di dati e degli orizzonti di stima. Maggiori sono quindi i dati disponibili per la stima dei parametri del modello e più probabile diventa la generalizzazione per la serie non visibile.
La configurazione avanzata della previsione include:
- Rilevamento festività e definizione delle funzionalità
- Strumenti di apprendimento della serie temporale e della rete neurale profonda (Auto-ARIMA, Prophet, ForecastTCN)
- Supporto di numerosi modelli tramite raggruppamento
- Convalida incrociata dell'origine in sequenza
- Ritardi configurabili
- Funzionalità di aggregazione della finestra mobile
Vedere un esempio di attività di previsione e Machine Learning automatizzato in questi notebook Python: Domanda elettrica.
Visione artificiale
Il supporto per le attività di visione artificiale consente di generare facilmente modelli sottoposti a training sui dati delle immagini per scenari come la classificazione delle immagini e il rilevamento degli oggetti.
Con questa funzionalità è possibile:
- Integrare facilmente la funzionalità di etichettatura dei dati di Azure Machine Learning.
- Usare i dati etichettati per la generazione di modelli di immagine.
- Ottimizzare le prestazioni del modello specificando l'algoritmo del modello e ottimizzando gli iperparametri.
- Scaricare o distribuire il modello risultante come servizio Web in Azure Machine Learning.
- Rendere operativo su larga scala, sfruttando le funzionalità di MLOps e ML Pipelines.
La creazione di modelli AutoML per le attività di visione è supportata tramite l'SDK Azure Machine Learning di Python. I processi, i modelli e gli output risultanti dalla sperimentazione sono accessibili dall'interfaccia utente dello studio di Azure Machine Learning.
Informazioni su come configurare il training AutoML per i modelli di visione artificiale.
 Immagine da: http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
Immagine da: http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
ML automatizzato per le immagini supporta le attività di visione dei computer seguenti:
| Attività | Descrizione |
|---|---|
| Classificazione immagini in più classi | Attività in cui un'immagine viene classificata con una sola etichetta di un set di classi, ad esempio ogni immagine viene classificata come immagine di un gatto, di un cane o di una papera. |
| Classificazione di immagini multietichetta | Attività in cui un'immagine può avere una o più etichette di un set di etichette, ad esempio un'immagine può essere etichettata sia con "gatto" che con "cane". |
| Rilevamento oggetti | Attività per identificare gli oggetti in un'immagine e individuare ogni oggetto con un rettangolo di selezione, ad esempio individuare tutti i cani e i gatti in un'immagine e disegnare un rettangolo di selezione intorno a ognuno. |
| Segmentazione delle istanze | Attività per identificare gli oggetti in un'immagine a livello di pixel, disegnando un poligono intorno a ogni oggetto nell'immagine. |
Elaborazione del linguaggio naturale (NLP)
Il supporto per le attività di elaborazione del linguaggio naturale (NLP) in Machine Learning automatizzato consente di generare facilmente modelli sottoposti a training sui dati di testo per la classificare testi e scenari di riconoscimento di entità denominate. La creazione di modelli NLP con training automatizzato di Ml è supportata tramite Azure Machine Learning Python SDK. I processi, i modelli e gli output risultanti dalla sperimentazione sono accessibili dall'interfaccia utente dello studio di Azure Machine Learning.
La funzionalità NLP supporta:
- Training NLP della rete neurale profonda end-to-end con i modelli BERT con training preliminare più recente
- Integrazione perfetta con etichettatura dei dati di Azure Machine Learning
- Usare i dati etichettati per la generazione di modelli NLP
- Supporto multilingue con 104 lingue
- Training distribuito con Horovod
Informazioni su come configurare il training AutoML per i modelli NLP.
Training, convalida e test dei dati
Con ML automatizzato è possibile fornire i dati di training per eseguire il training dei modelli di Machine Learning ed è possibile specificare il tipo di convalida del modello da eseguire. Machine Learning automatizzato esegue la convalida del modello come parte del training. Ovvero, ML automatizzato usa dati di convalida per ottimizzare gli iperparametri del modello in base all'algoritmo applicato per trovare la combinazione più adatta ai dati di training. Tuttavia, gli stessi dati di convalida vengono usati per ogni iterazione dell'ottimizzazione, che introduce distorsioni di valutazione del modello poiché il modello continua a migliorare e adattarsi ai dati di convalida.
Per verificare che tale distorsione non venga applicata al modello consigliato finale, ML automatizzato supporta l'uso di dati di test per valutare il modello finale consigliato da ML automatizzato alla fine dell'esperimento. Quando si forniscono dati di test come parte della configurazione dell'esperimento AutoML, questo modello consigliato viene testato per impostazione predefinita alla fine dell'esperimento (anteprima).
Importante
Il test dei modelli con un set di dati di test per valutare i modelli generati è una funzionalità di anteprima. Questa è una funzionalità di anteprima sperimentale e può cambiare in qualsiasi momento.
Informazioni su come configurare esperimenti AutoML per usare i dati di test (anteprima) con l'SDK o con Studio di Azure Machine Learning.
Progettazione delle caratteristiche
La progettazione delle funzionalità è il processo nel quale si usano le conoscenze del dominio dei dati per creare funzionalità che consentono agli algoritmi di Machine Learning di apprendere meglio. In Azure Machine Learning, le tecniche di ridimensionamento e normalizzazione vengono applicate per semplificare la definizione delle funzionalità. Collettivamente, queste tecniche di ingegneria delle funzionalità prendono il nome di definizione delle funzionalità.
Per gli esperimenti automatizzati di Machine Learning, la definizione delle funzionalità viene applicata automaticamente, ma può anche essere personalizzata in base ai dati. Altre informazioni sulle funzionalità incluse (SDK v1) e sul modo in cui AutoML aiuta aprevenire l'overfitting e i sbilanciati nei modelli dell’utente.
Nota
I passaggi di definizione delle funzionalità di Machine Learning automatizzato (ad esempio, normalizzazione delle funzionalità, gestione dei dati mancanti o conversione dei valori di testo in formato numerico) diventano parte del modello sottostante. Quando si usa il modello per le previsioni, gli stessi passaggi di definizione delle funzionalità applicati durante il training vengono automaticamente applicati ai dati di input.
Personalizzare la definizione delle funzionalità
Sono disponibili anche altre tecniche di ingegneria delle funzionalità, ad esempio la codifica e le trasformazioni.
Abilitare questa impostazione con:
Studio di Azure Machine Learning: abilitare Automatic featurization (Definizione delle funzionalità automatica) nella sezione View additional configuration (Visualizza configurazione aggiuntiva) con questi passaggi.
Python SDK: specificare la definizione delle funzionalità nell'oggetto processo AutoML. Altre informazioni sull'abilitazione delle funzionalità.
Modelli Ensemble
Machine Learning automatizzato supporta i modelli Ensemble, che sono abilitati per impostazione predefinita. L'apprendimento dell'insieme migliora i risultati di Machine Learning e le prestazioni predittive combinando più modelli rispetto all'uso di modelli singoli. Le iterazioni dell'insieme vengono visualizzate come iterazioni finali del processo. Machine Learning automatizzato usa i metodi Ensemble di voto e sovrapposizione per combinare i modelli:
- Voto: stima in base alla media ponderata delle probabilità della classe stimata (per le attività di classificazione) o alle destinazioni di regressione stimate (per le attività di regressione).
- Sovrapposizione: combina modelli eterogenei ed esegue il training di un metamodello in base all'output dei singoli modelli. I metamodelli predefiniti correnti sono LogisticRegression per le attività di classificazione ed ElasticNet per le attività di regressione/previsione.
L'algoritmo di selezione dell'insieme Caruana con l'inizializzazione dell'insieme ordinato viene usato per decidere quali modelli usare nell'insieme. A un livello elevato, questo algoritmo inizializza l'insieme con un massimo di cinque modelli con i punteggi individuali migliori e verifica che questi modelli siano entro il 5% di soglia del punteggio migliore per evitare un insieme iniziale scadente. Per ogni iterazione dell'insieme, viene aggiunto un nuovo modello all'insieme esistente e viene calcolato il punteggio risultante. Se un nuovo modello migliora il punteggio dell'insieme esistente, l'insieme viene aggiornato in modo da includere il nuovo modello.
Per la modifica delle impostazioni dell'insieme predefinite in Machine Learning automatizzato, vedere la Pacchetto AutoML.
Machine Learning automatizzato e ONNX
Con Azure Machine Learning è possibile usare Machine Learning automatizzato per creare un modello Python e convertirlo nel formato ONNX. Quando i modelli sono nel formato ONNX, possono essere eseguiti in varie piattaforme e dispositivi. Altre informazioni sull'accelerazione dei modelli di Machine Learning con ONNX.
Vedere come eseguire la conversione nel formato ONNX in questo esempio di notebook Jupyter. Informazioni sugli algoritmi supportati in ONNX.
Il runtime di ONNX supporta anche C#, quindi è possibile usare il modello creato automaticamente nelle app C# senza la necessità di ricodificare o di una delle latenze di rete introdotte dagli endpoint REST. Altre informazioni sull’uso di un modello ONNX AutoML in un'applicazione .NET con ML.NET e inferenza di modelli ONNX con l'API C# di runtime ONNX.
Passaggi successivi
Sono disponibili più risorse per iniziare a usare AutoML.
Esercitazioni/guide pratiche
Le esercitazioni sono esempi introduttivi end-to-end di scenari AutoML.
Per un'esperienza Code First, seguire l'esercitazione: Eseguire il training di un modello di rilevamento oggetti con AutoML e Python
Per un'esperienza con poco o senza codice, vedere l'esercitazione: Eseguire il training di un modello di classificazione senza codice AutoML in studio di Azure Machine Learning.
Gli articoli sulle procedure forniscono dettagli aggiuntivi sulle funzionalità offerte da Machine Learning automatizzato. ad esempio:
Configurare le impostazioni per esperimenti di training automatico
Informazioni su come eseguire il training dei modelli di visione del computer con Python.
Informazioni su come visualizzare il codice generato dai modelli di Machine Learning automatizzati (SDK v1).
Esempi di Jupyter Notebook
Esaminare esempi di codice e casi d'uso dettagliati nel repository di notebook GitHub per esempi di Machine Learning automatizzato.
Informazioni di riferimento su Python SDK
Approfondire l'esperienza dei modelli di progettazione e delle specifiche delle classi SDK con la documentazione di riferimento della classe processo AutoML.
Nota
Le funzionalità di Machine Learning automatizzato sono disponibili anche in altre soluzioni Microsoft, ad esempio ML.NET, HDInsight, Power BI e SQL Server.