Configurare AutoML in modo da eseguire il training dei modelli di visione del computer con Python (v1)
SI APPLICA A:  Python SDK azureml v1
Python SDK azureml v1
Importante
Alcuni comandi dell'interfaccia della riga di comando (CLI) di Azure in questo articolo usano l'estensione azure-cli-ml, o v1, per Azure Machine Learning. L'assistenza per l'estensione v1 terminerà il 30 settembre 2025. Sarà possibile installare e usare l'estensione v1 fino a tale data.
Consigliamo di passare all'estensione ml, o v2, prima del 30 settembre 2025. Per ulteriori informazioni sull'estensione v2, consultare Estensione dell'interfaccia della riga di comando (CLI) di Azure Machine Learning e Python SDK v2.
Importante
Questa funzionalità è attualmente in anteprima pubblica. Questa versione di anteprima viene fornita senza un contratto di servizio. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Questo articolo illustra come eseguire il training di modelli di visione artificiale sui dati delle immagini con Machine Learning automatizzato in Azure Machine Learning Python SDK.
ML automatizzato supporta il training dei modelli per attività di visione dei computer, ad esempio la classificazione immagini, il rilevamento oggetti e la segmentazione delle istanze. La creazione di modelli AutoML per le attività di visione dei computer è attualmente supportata tramite l'SDK Azure Machine Learning di Python. Le prove, i modelli e gli output della sperimentazione risultanti sono accessibili dall'interfaccia utente dello studio di Azure Machine Learning. Ulteriori informazioni su ML automatizzato per le attività di visione artificiale sui dati di immagini.
Nota
Il Machine Learning automatizzato per le attività di visione artificiale è disponibile solo tramite Azure Machine Learning Python SDK.
Prerequisiti
Un'area di lavoro di Azure Machine Learning. Per creare l'area di lavoro, consultare Creare risorse dell'area di lavoro.
Azure Machine Learning Python SDK installato. Per installare l'SDK, è possibile,
Creare un'istanza di ambiente di calcolo che installa automaticamente l'SDK ed è preconfigurata per i flussi di lavoro di Machine Learning. Per altre informazioni, vedere Creare e gestire un'istanza di ambiente di calcolo di Azure Machine Learning.
Installare manualmente il
automlpacchetto, inclusa l'installazione predefinita dell'SDK.
Nota
Per le attività di visione artificiale, solo Python 3.7 e 3.8 sono compatibili con il supporto di ML automatizzato.
Selezionare il tipo di attività
ML automatizzato per le immagini supporta i seguenti tipi di attività:
| Tipo di attività | Sintassi di configurazione AutoMLimage |
|---|---|
| Classificazione immagini | ImageTask.IMAGE_CLASSIFICATION |
| classificazione immagini multietichetta | ImageTask.IMAGE_CLASSIFICATION_MULTILABEL |
| rilevamento oggetti immagine | ImageTask.IMAGE_OBJECT_DETECTION |
| segmentazione istanze immagine | ImageTask.IMAGE_INSTANCE_SEGMENTATION |
Questo tipo di attività è un parametro obbligatorio e viene passato usando il parametro task in AutoMLImageConfig.
Ad esempio:
from azureml.train.automl import AutoMLImageConfig
from azureml.automl.core.shared.constants import ImageTask
automl_image_config = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION)
Dati di training e convalida
Per generare modelli di visione artificiale, è necessario inserire dati di immagine etichettati come input per il training del modello sotto forma di un TabularDataset di Azure Machine Learning. È possibile usare un TabularDataset esportato da un progetto di etichettatura dati, oppure creare uno nuovo TabularDataset con i dati di training etichettati.
Se i dati di training sono in un formato diverso (ad esempio, Pascal VOC o COCO), è possibile applicare gli script helper inclusi nei notebook di esempio per convertirli in JSONL. Ulteriori informazioni su come preparare i dati per le attività di visione artificiale con ML automatizzato.
Avviso
Per questa funzionalità, la creazione di TabularDataset dai dati in formato JSONL è supportata solo con l'SDK. La creazione del dataset tramite interfaccia utente non è al momento supportata. In questo momento, l'interfaccia utente non riconosce il tipo di dati StreamInfo, ovvero il tipo di dati usato per gli URL di immagine in formato JSONL.
Nota
Il set di dati di training deve disporre di almeno 10 immagini per poter inviare un'esecuzione AutoML.
Esempi di schemi JSONL
La struttura dell'oggetto TabularDataset dipende dall'attività. Per le attività di tipo visione artificiale, è costituita dai campi seguenti:
| Campo | Descrizione |
|---|---|
image_url |
Contiene il percorso file come oggetto StreamInfo |
image_details |
Informazioni sui metadati dell'immagine costituite da altezza, larghezza e formato. Questo campo è facoltativo e può esistere o no. |
label |
Rappresentazione JSON dell'etichetta dell'immagine, in base al tipo di attività. |
Di seguito è riportato un file JSONL campione per la classificazione delle immagini:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "AmlDatastore://image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
Il seguente codice è un file JSONL di esempio per il rilevamento oggetti:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "AmlDatastore://image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Dati di utilizzo
Quando i dati sono in formato JSONL, è possibile creare un oggetto TabularDataset con il seguente codice:
ws = Workspace.from_config()
ds = ws.get_default_datastore()
from azureml.core import Dataset
training_dataset = Dataset.Tabular.from_json_lines_files(
path=ds.path('odFridgeObjects/odFridgeObjects.jsonl'),
set_column_types={'image_url': DataType.to_stream(ds.workspace)})
training_dataset = training_dataset.register(workspace=ws, name=training_dataset_name)
Per attività di visione artificiale, ML automatizzato non impone vincoli sulle dimensioni dei dati di training o convalida. Le dimensioni massime del set di dati sono limitate solo dal livello di archiviazione sottostante (ad esempio, un archivio di BLOB). Non è previsto un numero minimo di immagini o etichette. È tuttavia consigliabile iniziare con almeno 10-15 campioni per etichetta per garantire che il modello di output sia sottoposto a training sufficiente. Maggiore è il numero totale di etichette/classi, maggiore è il numero di campioni necessari per etichetta.
I dati di training sono obbligatori e vengono passati tramite il parametro training_data. Facoltativamente, è possibile specificare un altro oggetto TabularDataset come set di dati di convalida da usare per il modello con il parametro validation_data di AutoMLImageConfig. Se non viene specificato alcun set di dati di convalida, il 20% dei dati di training verrà usato per la convalida per impostazione predefinita, a meno che non si passi l’argomento validation_size con un valore diverso.
Ad esempio:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(training_data=training_dataset)
Calcolo per eseguire l'esperimento
Specificare una destinazione di calcolo per ML automatizzato per eseguire il training del modello. I modelli di ML automatizzato per le attività di visione artificiale richiedono SKU di GPU e supportano famiglie NC e ND. È consigliabile usare la serie NCsv3 (con GPU v100) per un training più rapido. Una destinazione di calcolo con uno SKU di macchina virtuale multi-GPU sfrutta più GPU anche per velocizzare il training. Inoltre, quando si configura una destinazione di calcolo con più nodi, è possibile eseguire più velocemente il training del modello tramite parallelismo durante l'ottimizzazione degli iperparametri per il modello.
Nota
Se si usa un'istanza di ambiente di calcolo come destinazione di calcolo, assicurarsi più processi AutoML non vengano eseguiti contemporaneamente. Assicurarsi anche che max_concurrent_iterations sia impostato su 1 nelle risorse dell'esperimento.
La destinazione di calcolo è un parametro obbligatorio e viene passata usando il parametro compute_target di AutoMLImageConfig. Ad esempio:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(compute_target=compute_target)
Configurare algoritmi di modello e iperparametri
Con il supporto per le attività di visione artificiale, è possibile controllare l'algoritmo del modello e gli iperparametri di sweep. Questi algoritmi di modello e iperparametri vengono passati come spazio dei parametri per lo sweep.
L'algoritmo del modello è obbligatorio e viene passato tramite il parametro model_name. È possibile specificare un singolo model_name o scegliere tra diverse opzioni.
Algoritmi supportati per i modelli
La seguente tabella riepiloga i modelli supportati per ogni attività di visione artificiale.
| Attività | Algoritmi di modello | Sintassi di valori letterali stringadefault_model* indicato con * |
|---|---|---|
| Classificazione immagini (multiclasse e multietichetta) |
MobileNet: modelli leggeri per applicazioni per dispositivi mobili ResNet: reti residue ResNeSt: reti con attenzione divisa SE-ResNeXt50: reti Squeeze-and-Excitation ViT: reti di trasformatori di visione |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (piccolo) vitb16r224* (base) vitl16r224 (grande) |
| Rilevamento oggetti | YOLOv5: modello di rilevamento oggetti in un'unica fase Faster RCNN ResNet FPN: modelli di rilevamento oggetti in due fasi RetinaNet ResNet FPN: soluzione per lo squilibrio di classi con perdita focale Nota: per informazioni sulle dimensioni dei modelli YOLOv5, consultare model_sizeiperparametro . |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Segmentazione delle istanze | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn maskrcnn_resnet50_fpn |
Oltre a controllare l'algoritmo del modello, è anche possibile ottimizzare gli iperparametri usati per il training del modello. Sebbene molti iperparametri esposti siano indipendenti dal modello, in alcuni casi sono specifici dell'attività o specifici del modello. Ulteriori informazioni sugli iperparametri disponibili per questi casi.
Aumento dei dati
In genere, le prestazioni del modello di Deep Learning possono spesso migliorare con più dati. L'aumento dei dati è una tecnica pratica per amplificare le dimensioni e la variabilità dei dati di un set di dati, il che consente di evitare l'overfitting e di migliorare la capacità di generalizzazione del modello su dati non visibili. Il ML automatizzato applica diverse tecniche di aumento dei dati in base all'attività di visione artificiale prima di inviare le immagini di input al modello. Attualmente, non esiste alcun iperparametro esposto per controllare gli aumenti dei dati.
| Attività | Set di dati interessato | Tecnica o tecniche di aumento dei dati applicate |
|---|---|---|
| Classificazione immagini (multiclasse e multietichetta) | Formazione Convalida e test |
Ridimensionamento e ritaglio casuali, capovolgimento orizzontale, instabilità del colore (luminosità, contrasto, saturazione e tonalità), normalizzazione tramite deviazione media e standard di ImageNet a livello di canale Ridimensionamento, ritaglio al centro, normalizzazione |
| Rilevamento oggetti, segmentazione di istanze | Formazione Convalida e test |
Ritaglio casuale intorno ai rettangoli di selezione, espansione, capovolgimento orizzontale, normalizzazione, ridimensionamento Normalizzazione, ridimensionamento |
| Rilevamento oggetti con yolov5 | Formazione Convalida e test |
Mosaico, trasformazione affine casuale (rotazione, traslazione, scala, inclinazione), capovolgimento orizzontale Ridimensionamento in formato 16:9 |
Configurare le impostazioni di esperimento
Prima di eseguire uno sweep di grandi dimensioni per cercare i modelli e gli iperparametri ottimali, è consigliabile provare i valori predefiniti per una prima baseline. Successivamente, è possibile esplorare più iperparametri per lo stesso modello prima di eseguire lo sweep su più modelli e sui relativi parametri. In questo modo, si può usare un approccio più iterativo, poiché con più modelli e più iperparametri per ciascuno, lo spazio di ricerca crescerà in modo esponenziale e saranno necessarie più iterazioni per trovare configurazioni ottimali.
Se si desidera utilizzare i valori degli iperparametri predefiniti per un determinato algoritmo (ad esempio, yolov5), è possibile specificare la configurazione per l'esecuzione dell'immagine AutoML come indicato di seguito:
from azureml.train.automl import AutoMLImageConfig
from azureml.train.hyperdrive import GridParameterSampling, choice
from azureml.automl.core.shared.constants import ImageTask
automl_image_config_yolov5 = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION,
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
hyperparameter_sampling=GridParameterSampling({'model_name': choice('yolov5')}),
iterations=1)
Dopo aver creato un modello di base, è possibile ottimizzare le prestazioni del modello per eseguire lo sweep sull'algoritmo del modello e sullo spazio degli iperparametri. È possibile usare la seguente configurazione campione per eseguire lo sweep sugli iperparametri per ogni algoritmo, scegliendo tra un intervallo di valori per learning_rate, ottimizzatore, lr_scheduler e così via, per generare un modello con la metrica primaria ottimale. Se i valori degli iperparametri non vengono specificati, verranno usati i valori predefiniti per l'algoritmo specificato.
Primary metric (Metrica principale)
La metrica primaria usata per l'ottimizzazione del modello e l'ottimizzazione degli iperparametri dipende dal tipo di attività. L'uso di altri valori metrici primari non è attualmente supportato.
accuracyper IMAGE_CLASSIFICATIONiouper IMAGE_CLASSIFICATION_MULTILABELmean_average_precisionper IMAGE_OBJECT_DETECTIONmean_average_precisionper IMAGE_INSTANCE_SEGMENTATION
Budget dell'esperimento
Facoltativamente, è possibile specificare il budget di tempo massimo per l'esperimento di Visione AutoML, ovvero la quantità di tempo in ore prima del termine dell’esperimento, usando experiment_timeout_hours. Se non specificato, il timeout dell'esperimento predefinito è di sette giorni (massimo 60 giorni).
Effettuare lo sweep degli iperparametri per il modello
Quando si esegue il training di modelli di visione artificiale, le prestazioni del modello dipendono in larga misura dai valori degli iperparametri selezionati. Spesso, si può scegliere di ottimizzare gli iperparametri per ottenere prestazioni ottimali. Con il supporto per le attività di visione artificiale in Machine Learning automatizzato, è possibile eseguire lo sweep degli iperparametri per trovare le impostazioni ottimali per il modello. Questa funzionalità applica le funzionalità di ottimizzazione degli iperparametri di Azure Machine Learning. Informazioni su come ottimizzare gli iperparametri.
Definire lo spazio di ricerca dei parametri
È possibile definire gli algoritmi del modello e gli iperparametri da sottoporre a sweep nello spazio dei parametri.
- Per l'elenco degli algoritmi di modello supportati per ogni tipo di attività, consultare Configurare algoritmi di modello e iperparametri.
- Consultare Iperparametri per ogni tipo di attività di visione artificiale.
- Consultare informazioni dettagliate sulle distribuzioni supportate per iperparametri discreti e continui.
Metodi di campionamento per lo sweep
Quando si esegue lo sweep degli iperparametri, è necessario specificare il metodo di campionamento da usare nello spazio dei parametri definito. Attualmente, i seguenti metodi di campionamento sono supportati con il parametro hyperparameter_sampling:
Nota
Attualmente, solo i campionamenti casuale e a griglia supportano spazi di iperparametri condizionali.
Criteri di interruzione anticipata
È possibile interrompere automaticamente le esecuzioni con prestazioni insufficienti con un criterio di interruzione anticipata. L'interruzione anticipata migliora l'efficienza di calcolo, facendo risparmiare risorse di calcolo che sarebbero state altrimenti spese per configurazioni meno promettenti. ML automatizzato per le immagini supporta i seguenti criteri di interruzione anticipata tramite il parametro early_termination_policy. Se non viene specificato alcun criterio di interruzione, tutte le configurazioni vengono eseguite fino a completamento.
Per ulteriori informazioni, consultare come configurare i criteri di interruzione anticipata per lo sweep degli iperparametri.
Risorse per lo sweep
È possibile controllare le risorse usate per lo sweep degli iperparametri specificando iterations e max_concurrent_iterations per lo sweep.
| Parametro | Dettagli |
|---|---|
iterations |
Parametro per il numero massimo di configurazioni su cui eseguire lo sweep. Deve essere un numero intero compreso tra 1 e 1000. Quando si esplorano solo gli iperparametri predefiniti per un algoritmo del modello specificato, impostare questo parametro su 1. |
max_concurrent_iterations |
Numero massimo di esecuzioni simultanee. Se non specificato, tutte le esecuzioni vengono avviate in parallelo. Se specificato, deve essere un numero intero compreso tra 1 e 100. NOTA: il numero di esecuzioni simultanee è limitato dalle risorse disponibili nella destinazione di calcolo specificata. Verificare che nella destinazione di calcolo siano disponibili risorse sufficienti per la concorrenza desiderata. |
Nota
Per un esempio completo di configurazione dello sweep, vedere questa esercitazione.
Argomenti
È possibile passare impostazioni o parametri che rimangono fissi durante lo sweep dello spazio dei parametri come argomenti. Gli argomenti vengono passati in coppie nome-valore e il nome deve essere preceduto da un trattino doppio.
from azureml.train.automl import AutoMLImageConfig
arguments = ["--early_stopping", 1, "--evaluation_frequency", 2]
automl_image_config = AutoMLImageConfig(arguments=arguments)
Training incrementale (facoltativo)
Al termine dell'esecuzione del training, è possibile eseguire ulteriore training del modello caricando il checkpoint del modello sottoposto a training. Per il training incrementale, è possibile usare lo stesso set di dati o uno diverso.
Sono disponibili due opzioni per il training incrementale. È possibile,
- Passare l'ID di esecuzione da cui si vuole caricare il checkpoint.
- Passare i checkpoint tramite un oggetto FileDataset.
Passare il checkpoint tramite l'ID di esecuzione
Per trovare l'ID di esecuzione del modello desiderato, è possibile usare il seguente codice.
# find a run id to get a model checkpoint from
target_checkpoint_run = automl_image_run.get_best_child()
Per passare un checkpoint tramite l'ID esecuzione, è necessario usare il parametro checkpoint_run_id.
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_run_id= target_checkpoint_run.id,
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
Passare il checkpoint tramite FileDataset
Per passare un checkpoint tramite un oggetto FileDataset, è necessario usare i parametri checkpoint_dataset_id e checkpoint_filename.
# download the checkpoint from the previous run
model_name = "outputs/model.pt"
model_local = "checkpoints/model_yolo.pt"
target_checkpoint_run.download_file(name=model_name, output_file_path=model_local)
# upload the checkpoint to the blob store
ds.upload(src_dir="checkpoints", target_path='checkpoints')
# create a FileDatset for the checkpoint and register it with your workspace
ds_path = ds.path('checkpoints/model_yolo.pt')
checkpoint_yolo = Dataset.File.from_files(path=ds_path)
checkpoint_yolo = checkpoint_yolo.register(workspace=ws, name='yolo_checkpoint')
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_dataset_id= checkpoint_yolo.id,
checkpoint_filename='model_yolo.pt',
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
Inviare l'esecuzione
Quando l'oggetto AutoMLImageConfig è pronto, è possibile inviare l'esperimento.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-image-object-detection")
automl_image_run = experiment.submit(automl_image_config)
Output e metriche di valutazione
Le esecuzioni di training ML automatizzato generano file del modello di output, metriche di valutazione, log e artefatti di distribuzione; ad esempio, il file di punteggi e il file di ambiente, che possono essere visualizzati dalle schede output e log e metriche delle esecuzioni figlio.
Suggerimento
Per informazioni su come passare ai risultati dell’esecuzione, consultare la sezione Visualizzare i risultati dell’esecuzione.
Per definizioni ed esempi dei grafici delle prestazioni e delle metriche fornite per ogni esecuzione, consultare Valutare i risultati dell'esperimento di Machine Learning automatizzato
Registrare e distribuire modelli
Al termine del processo, è possibile registrare il modello creato dalla prova migliore (configurazione che ha generato la metrica primaria migliore)
best_child_run = automl_image_run.get_best_child()
model_name = best_child_run.properties['model_name']
model = best_child_run.register_model(model_name = model_name, model_path='outputs/model.pt')
Dopo aver registrato il modello da usare, è possibile distribuirlo come servizio Web in Istanze di Azure Container (ACI) o nel servizio Azure Kubernetes (AKS). Istanze di Azure Container è ideale per testare le distribuzioni, mentre il servizio Azure Kubernetes è più adatto per l'uso in ambiente di produzione su larga scala.
Questo esempio distribuisce il modello come servizio Web nel servizio Azure Kubernetes. Per eseguire la distribuzione nel servizio Azure Kubernetes, creare prima di tutto un cluster di calcolo del servizio Azure Kubernetes o usarne uno esistente. È possibile usare SKU di VM GPU o CPU per il cluster di distribuzione.
from azureml.core.compute import ComputeTarget, AksCompute
from azureml.exceptions import ComputeTargetException
# Choose a name for your cluster
aks_name = "cluster-aks-gpu"
# Check to see if the cluster already exists
try:
aks_target = ComputeTarget(workspace=ws, name=aks_name)
print('Found existing compute target')
except ComputeTargetException:
print('Creating a new compute target...')
# Provision AKS cluster with GPU machine
prov_config = AksCompute.provisioning_configuration(vm_size="STANDARD_NC6",
location="eastus2")
# Create the cluster
aks_target = ComputeTarget.create(workspace=ws,
name=aks_name,
provisioning_configuration=prov_config)
aks_target.wait_for_completion(show_output=True)
Quindi, è possibile definire la configurazione dell'inferenza che descrive come configurare il servizio Web contenente il modello. È possibile usare lo script di assegnazione dei punteggi e l'ambiente dall'esecuzione del training nella configurazione dell'inferenza.
from azureml.core.model import InferenceConfig
best_child_run.download_file('outputs/scoring_file_v_1_0_0.py', output_file_path='score.py')
environment = best_child_run.get_environment()
inference_config = InferenceConfig(entry_script='score.py', environment=environment)
È quindi possibile distribuire il modello come servizio Web del servizio Azure Kubernetes.
# Deploy the model from the best run as an AKS web service
from azureml.core.webservice import AksWebservice
from azureml.core.webservice import Webservice
from azureml.core.model import Model
from azureml.core.environment import Environment
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
cpu_cores=1,
memory_gb=50,
enable_app_insights=True)
aks_service = Model.deploy(ws,
models=[model],
inference_config=inference_config,
deployment_config=aks_config,
deployment_target=aks_target,
name='automl-image-test',
overwrite=True)
aks_service.wait_for_deployment(show_output=True)
print(aks_service.state)
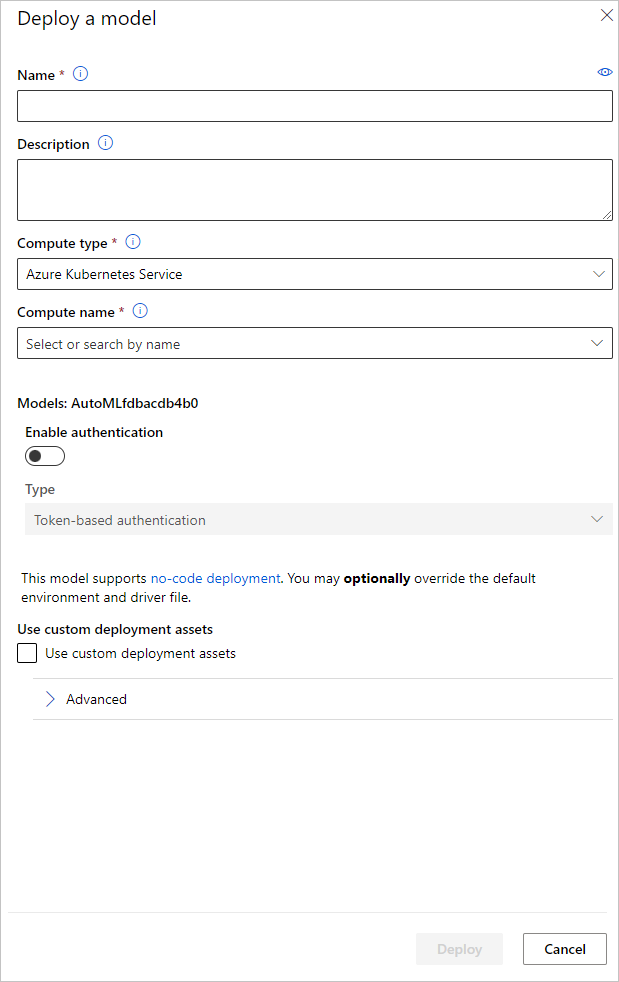
In alternativa, è possibile distribuire il modello dall'interfaccia utente dello studio di Azure Machine Learning. Passare al modello che si vuole distribuire nella scheda Modelli dell'esecuzione automatizzata di Machine Learning e selezionare Distribuisci.
È possibile configurare il nome dell'endpoint di distribuzione del modello e il cluster di inferenza da usare per la distribuzione del modello nel riquadro Distribuisci un modello.
Definire la configurazione dell'inferenza
Nel passaggio precedente, è stato scaricato il file di punteggio outputs/scoring_file_v_1_0_0.py dal miglior modello in un file locale score.py ed è stato usato per creare un oggetto InferenceConfig. Se necessario, questo script può essere modificato dopo il download e prima della creazione di InferenceConfig per cambiare le impostazioni di inferenza specifiche del modello. Ad esempio, si tratta della sezione di codice che inizializza il modello nel file di punteggio:
...
def init():
...
try:
logger.info("Loading model from path: {}.".format(model_path))
model_settings = {...}
model = load_model(TASK_TYPE, model_path, **model_settings)
logger.info("Loading successful.")
except Exception as e:
logging_utilities.log_traceback(e, logger)
raise
...
Ognuna delle attività (e alcuni modelli) dispongono di un set di parametri nel dizionario model_settings. Per impostazione predefinita, gli stessi valori usati durante il training e la convalida vengono impiegati per i parametri. A seconda del comportamento necessario per l’uso del modello per inferenza, è possibile cambiare questi parametri. Di seguito è riportato un elenco di parametri per ogni tipo di attività e modello.
| Attività | Nome parametro | Default |
|---|---|---|
| Classificazione immagini (multiclasse e multietichetta) | valid_resize_sizevalid_crop_size |
256 224 |
| Rilevamento oggetti | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0,3 0.5 100 |
Rilevamento oggetti con yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 medium 0,1 0.5 |
| Segmentazione delle istanze | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0,3 0.5 100 0.5 100 Falso JPG |
Per una descrizione dettagliata sugli iperparametri specifici dell'attività, consultare Iperparametri per le attività di visione artificiale in Machine Learning automatizzato.
Se si vuole usare l'affiancamento e controllare il relativo comportamento, sono disponibili i seguenti parametri: tile_grid_size, tile_overlap_ratio e tile_predictions_nms_thresh. Per ulteriori informazioni su questi parametri, consultare Eseguire il training di un modello di rilevamento oggetti di piccole dimensioni con AutoML.
Notebook di esempio
Esaminare esempi di codice e casi d'uso dettagliati nel repository di notebook GitHub per esempi di Machine Learning automatizzato. Per esempi specifici relativi alla creazione di modelli di visione artificiale, controllare le cartelle con il prefisso 'image-'.