Creare script di assegnazione dei punteggi per le distribuzioni batch
SI APPLICA A: Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Gli endpoint batch consentono di distribuire modelli che eseguono l'inferenza su larga scala. Quando si distribuiscono modelli, occorre creare e specificare uno script di punteggio (noto anche come script driver batch) per indicare come usarlo sui dati di input per creare stime. In questo articolo si apprenderà come usare gli script di punteggio nelle distribuzioni di modelli per diversi scenari. Inoltre sarà possibile conoscere le procedure consigliate per gli endpoint batch.
Suggerimento
Tenere presente che i modelli MLflow non richiedono uno script di punteggio. Viene generato automaticamente. Per altre informazioni sul funzionamento degli endpoint batch con i modelli MLflow, visitare l'esercitazione dedicata Uso di modelli MLflow nelle distribuzioni batch.
Avviso
Per distribuire un modello di ML automatizzato in un endpoint batch, si noti che ML automatizzato fornisce uno script di punteggio che funziona solo per gli endpoint online. Lo script di punteggio non è progettato per l'esecuzione batch. Seguire queste linee guida per altre informazioni su come creare uno script di punteggio personalizzato per le operazioni del modello.
Informazioni sullo script di assegnazione dei punteggi
Lo script di punteggio è un file Python (.py) che specifica come eseguire il modello e legge i dati di input inviati dall'executor di distribuzione batch. Ogni distribuzione modello fornisce lo script di punteggio (insieme a tutte le altre dipendenze necessarie) in fase di creazione. In genere lo script di punteggio è simile al seguente:
deployment.yml
code_configuration:
code: code
scoring_script: batch_driver.py
Lo script di assegnazione dei punteggi deve contenere due metodi:
Metodo init
Usare il metodo init() per le preparazioni dispendiose o comuni. Ad esempio, usarlo per caricare il modello in memoria. L'avvio dell'intero processo batch chiama questa funzione una sola volta. I file del modello sono disponibili in un percorso determinato dalla variabile di ambiente AZUREML_MODEL_DIR. A seconda della modalità di registrazione del modello, i relativi file potrebbero essere contenuti in una cartella. Nell'esempio seguente il modello include diversi file in una cartella denominata model. Per altre informazioni, vedere come determinare la cartella usata dal modello.
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
# load the model
model = load_model(model_path)
In questo esempio il modello viene inserito nella variabile globale model. Per rendere disponibili gli asset necessari per eseguire l'inferenza nella funzione di punteggio, usare le variabili globali.
Metodo run
Usare il metodo run(mini_batch: List[str]) -> Union[List[Any], pandas.DataFrame] per gestire il punteggio di ciascun mini-batch generato dalla distribuzione batch. Questo metodo verrà chiamato una volta per ogni mini_batch generato per i dati di input. Le distribuzioni batch leggono i dati in batch in base alla configurazione della distribuzione.
import pandas as pd
from typing import List, Any, Union
def run(mini_batch: List[str]) -> Union[List[Any], pd.DataFrame]:
results = []
for file in mini_batch:
(...)
return pd.DataFrame(results)
Il metodo riceve un elenco di percorsi di file come parametro (mini_batch). È possibile usare questo elenco per eseguire l'iterazione ed elaborare singolarmente ciascun file, oppure per leggere l'intero batch ed elaborare tutti i file contemporaneamente. L'opzione migliore dipenderà dalla memoria di calcolo e dalla velocità effettiva che è necessario ottenere. Per un esempio che descrive come leggere interi batch di dati contemporaneamente, vedere Distribuzioni a velocità effettiva elevata.
Nota
Come viene distribuito il lavoro?
Le distribuzioni batch distribuiscono il lavoro a livello di file, il che significa che una cartella contenente 100 file con mini-batch di 10 file genera 10 batch di 10 file ciascuno. Si noti che le dimensioni dei file pertinenti non hanno rilevanza. Per i file sono troppo grandi per essere elaborati in mini-batch di grandi dimensioni, è consigliabile suddividere i file in file più piccoli per ottenere un livello di parallelismo superiore o ridurre il numero di file per mini-batch. Al momento, la distribuzione batch non può tenere conto delle differenze nella distribuzione delle dimensioni del file.
Il metodo run() deve restituire un Pandas DataFrameo una matrice/un elenco. Ogni elemento di output restituito indica un'esecuzione riuscita di un elemento di input nell'input mini_batch. Per gli asset di dati di file o cartelle, ogni riga/elemento restituito rappresenta un singolo file elaborato. Per un asset di dati tabulari, ogni riga/elemento restituito rappresenta una riga in un file elaborato.
Importante
Come scrivere le previsioni
Tutti gli elementi restituiti dalla funzione run() verranno accodati nel file di stime di output generato dal processo batch. È importante restituire il tipo di dati corretto da questa funzione. Restituire matrici quando è necessario eseguire l'output di una singola previsione. Restituire dataframe Pandas quando è necessario restituire più informazioni. Ad esempio, per i dati tabulari, sarebbe possibile accodare le previsioni al record originale. Usare un DataFrame Pandas per eseguire questa operazione. Sebbene un DataFrame Pandas può contenere nomi di colonna, il file di output non include tali nomi.
Per scrivere le previsioni in modo diverso, è possibile personalizzare gli output nelle distribuzioni batch.
Avviso
Nella funzione run, non generare tipi di dati complessi (o elenchi di tipi di dati complessi) invece di pandas.DataFrame. Questi output saranno trasformati in stringhe e diventeranno difficili da leggere.
Il DataFrame o la matrice risultante viene aggiunto al file di output indicato. Non è necessario specificare la cardinalità dei risultati. Un file può generare 1 o più righe/elementi nell'output. Tutti gli elementi nel dataframe o nella matrice risultante verranno scritti nel file di output così come sono (considerando che output_action non è summary_only).
Pacchetti Python per l'assegnazione dei punteggi
È necessario indicare le librerie richieste dallo script di punteggio per eseguire nell'ambiente in cui viene eseguita la distribuzione batch. Per quanto riguarda gli script di punteggio, gli ambienti sono indicati per distribuzione. In genere, si indicano i requisiti usando un file di dipendenze conda.yml, che potrebbe essere simile a questo:
mnist/environment/conda.yaml
name: mnist-env
channels:
- conda-forge
dependencies:
- python=3.8.5
- pip<22.0
- pip:
- torch==1.13.0
- torchvision==0.14.0
- pytorch-lightning
- pandas
- azureml-core
- azureml-dataset-runtime[fuse]
Per altre informazioni su come indicare l'ambiente per il modello, visitare Creare una distribuzione batch.
Scrivere le previsioni in modo diverso
Per impostazione predefinita, la distribuzione batch scrive le previsioni del modello in un singolo file, come indicato nella distribuzione. In alcuni casi, tuttavia, è necessario scrivere le stime in più file. Ad esempio, per i dati di input partizionati, probabilmente si vorrà generare anche l'output partizionato. In questi casi è possibile Personalizzare gli output nelle distribuzioni batch per indicare:
- Il formato di file usato (CSV, Parquet, JSON e così via) per scrivere previsioni
- La modalità di partizionamento dei dati nell'output
Per altre informazioni su come ottenerlo, vedere Personalizzare gli output nelle distribuzioni batch.
Controllo del codice sorgente degli script di assegnazione dei punteggi
È consigliabile collocare gli script di punteggio nel controllo del codice sorgente.
Procedure consigliate per la scrittura di script di assegnazione dei punteggi
Quando si scrivono script di punteggio che gestiscono grandi quantità di dati, è necessario tenere conto di diversi fattori, tra cui
- Dimensioni di ogni file
- Quantità di dati in ogni file
- Quantità di memoria necessaria per leggere ogni file
- Quantità di memoria necessaria per leggere un intero batch di file
- Footprint della memoria del modello
- Footprint della memoria del modello durante l'esecuzione dei dati di input
- Memoria disponibile nel calcolo
Le distribuzioni batch distribuiscono il lavoro a livello di file. Questo significa che una cartella contenente 100 file in mini-batch di 10 file, genera 10 batch di 10 file ciascuno (indipendentemente dalle dimensioni dei file). Se i file sono troppo grandi per essere elaborati in mini-batch di grandi dimensioni, è consigliabile suddividerli in file più piccoli per ottenere un livello di parallelismo superiore, o ridurre il numero di file per mini-batch. Al momento, la distribuzione batch non può tenere conto delle differenze nella distribuzione delle dimensioni del file.
Relazione tra il grado di parallelismo e lo script di assegnazione dei punteggi
La configurazione della distribuzione controlla sia dimensioni di ogni mini batch sia il numero di ruoli di lavoro in ogni nodo. Questo diventa importante quando si decide se leggere o meno l'intero mini-batch per eseguire l'inferenza, per eseguire l'inferenza per singolo file o per eseguire l'inferenza per singola riga (se tabulare). Per altre informazioni, vedere Esecuzione dell'inferenza a livello di mini-batch, file o riga.
Quando si eseguono più ruoli di lavoro nella stessa istanza, occorre tenere presente il fatto che la memoria sarà condivisa tra tutti i ruoli di lavoro. Generalmente, un aumento del numero di ruoli di lavoro per nodo deve accompagnarsi a una diminuzione delle dimensioni del mini-batch o a una modifica della strategia di punteggio (se dimensioni dei dati e SKU di calcolo non variano).
Esecuzione dell'inferenza a livello di mini batch, file o riga
Gli endpoint batch chiamano la funzione run() nello script di punteggio una volta per ciascun mini-batch. Tuttavia, è possibile decidere se si vuole eseguire l'inferenza sull'intero batch, su un file alla volta o su una riga alla volta, in caso di dati tabulari.
Livello mini batch
In genere, per ottenere una velocità effettiva elevata nel processo di punteggio batch è consigliabile eseguire l'inferenza sull'intero batch. Questo avviene se si esegue l'inferenza su una GPU in cui si vuole ottenere la saturazione del dispositivo di inferenza. È anche possibile basarsi su un caricatore di dati in grado di gestire da solo l'invio in batch se i dati non si adattano alla memoria, come i caricatori di dati TensorFlow o PyTorch. In questi casi, potrebbe essere necessario eseguire l'inferenza nell'intero batch.
Avviso
L'esecuzione dell'inferenza a livello di batch potrebbe richiedere uno stretto controllo sulle dimensioni dei dati di input per poter tenere conto correttamente dei requisiti di memoria ed evitare eccezioni di memoria insufficiente. Che sia possibile o meno caricare l'intero mini-batch in memoria, dipende dalle dimensioni dello stesso, dalle dimensioni delle istanze del cluster e dal numero di ruoli di lavoro in ogni nodo.
Per informazioni su come ottenere questo risultato, vedere Distribuzioni a velocità effettiva elevata. In questo esempio viene elaborato un intero batch di file alla volta.
Livello file
Uno dei modi più semplici per eseguire l'inferenza è l'iterazione su tutti i file del mini-batch, seguita dall'esecuzione del modello su di esso. In alcuni casi, ad esempio l'elaborazione di immagini, potrebbe essere una buona idea. Per i dati tabulari, potrebbe essere necessario eseguire una stima valida sul numero di righe in ogni file. Questa stima può indicare se il modello può gestire o meno i requisiti di memoria, sia per caricare tutti i dati in memoria sia per eseguirne l'inferenza. Alcuni modelli (in particolare quelli basati su reti neurali ricorrenti) si aprono e presentano un footprint della memoria con un conteggio di righe potenzialmente non lineare. Per un modello con spesa di memoria alta, prendere in considerazione l'esecuzione dell'inferenza a livello di riga.
Suggerimento
Prendere in considerazione la possibilità di suddividere i file troppo grandi così da leggerli contemporaneamente in più file più piccoli, per rappresentare una migliore parallelizzazione.
Per informazioni su come eseguire questa operazione, vedere Elaborazione di immagini con distribuzioni batch. L'esempio elabora un file alla volta.
Livello riga (tabulare)
Per i modelli che presentano problemi con le dimensioni di input, è possibile eseguire l'inferenza a livello di riga. La distribuzione batch fornisce comunque lo script di punteggio con un mini-batch dei file. Tuttavia, si leggerà un file, una riga alla volta. Questo approccio può sembrare inefficiente, ma per alcuni modelli di Deep Learning potrebbe essere l'unico modo per eseguire l'inferenza senza ridimensionare le risorse hardware.
Per informazioni su come eseguire questa operazione, vedere Elaborazione di testo con distribuzioni batch. L'esempio elabora una riga alla volta.
Uso di modelli che sono cartelle
La variabile di ambiente AZUREML_MODEL_DIR contiene il percorso alla posizione del modello selezionato e la funzione init() lo usa per caricare il modello in memoria. Tuttavia, alcuni modelli potrebbero contenere i relativi file in una cartella e potrebbe essere necessario tenerne conto durante il caricamento. È possibile identificare la struttura di cartelle del modello come mostrato qui:
Andare al portale di Azure Machine Learning.
Andare alla sezione Modelli.
Scegliere il modello da distribuire, quindi selezionare la scheda Artifacts.
Prendere nota della cartella visualizzata. Tale cartella è stata specificata al momento della registrazione del modello.
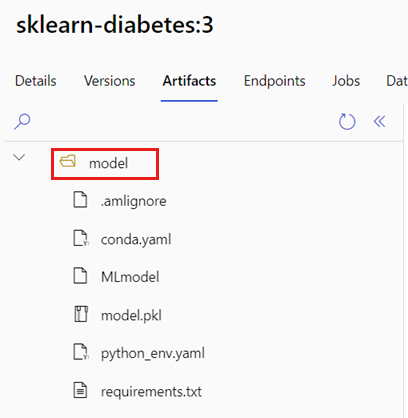

Usare questo percorso per caricare il modello:
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
model = load_model(model_path)