Usare il pacchetto di interpretabilità Python per spiegare le previsioni e i modelli di Machine Learning (anteprima)
SI APPLICA A:  SDK azureml per Python v1
SDK azureml per Python v1
Questa guida pratica illustra come usare il pacchetto di interpretabilità di Python SDK per Azure Machine Learning per eseguire le seguenti attività:
Spiegare l'intero comportamento del modello o le singole previsioni nel computer personale in locale.
Abilitare le tecniche di interpretabilità per le funzionalità progettate.
Spiegare il comportamento dell'intero modello e delle singole previsioni in Azure.
Caricare le spiegazioni nella cronologia di esecuzioni di Azure Machine Learning.
Usare un dashboard di visualizzazione per interagire con le spiegazioni del modello, sia in un Jupyter Notebook che in Studio di Azure Machine Learning.
Distribuire un explainer dell'assegnazione di punteggi insieme al modello per osservare le spiegazioni durante l'inferenza.
Importante
Questa funzionalità è attualmente in anteprima pubblica. Questa versione di anteprima viene fornita senza contratto di servizio, pertanto se ne sconsiglia l’uso per i carichi di lavoro in ambienti di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate.
Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Per altre informazioni sulle tecniche di interpretabilità supportate e sui modelli di Machine Learning, vedere Interpretabilità dei modelli in Azure Machine Learning e notebook di esempio.
Per indicazioni su come abilitare l'interpretabilità per i modelli sottoposti a training con Machine Learning automatizzato, vedere Interpretabilità: spiegazioni sui modelli di Machine Learning automatizzati (anteprima).
Generare un valore di importanza della caratteristica nel computer personale
L'esempio seguente illustra come usare il pacchetto di interpretabilità nel computer personale senza contattare i servizi di Azure.
Installare il pacchetto
azureml-interpret.pip install azureml-interpretEseguire il training di un modello di esempio in un Jupyter Notebook locale.
# load breast cancer dataset, a well-known small dataset that comes with scikit-learn from sklearn.datasets import load_breast_cancer from sklearn import svm from sklearn.model_selection import train_test_split breast_cancer_data = load_breast_cancer() classes = breast_cancer_data.target_names.tolist() # split data into train and test from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(breast_cancer_data.data, breast_cancer_data.target, test_size=0.2, random_state=0) clf = svm.SVC(gamma=0.001, C=100., probability=True) model = clf.fit(x_train, y_train)Chiamare l'explainer in locale.
- Per inizializzare un oggetto explainer, passare il modello e alcuni dati di training al costruttore dell'explainer.
- Per rendere le spiegazioni e le visualizzazioni più informative, è possibile scegliere di passare i nomi delle funzionalità e i nomi delle classi di output se si esegue la classificazione.
I seguenti blocchi di codice illustrano come creare un'istanza di un oggetto explainer con
TabularExplainer,MimicExplainerePFIExplainerlocalmente.TabularExplainerchiama uno dei tre explainer SHAP sottostanti (TreeExplainer,DeepExplaineroKernelExplainer).TabularExplainerseleziona automaticamente quello più appropriato per il caso d'uso; tuttavia, è possibile chiamare direttamente ognuno dei tre explainer sottostanti.
from interpret.ext.blackbox import TabularExplainer # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=breast_cancer_data.feature_names, classes=classes)or
from interpret.ext.blackbox import MimicExplainer # you can use one of the following four interpretable models as a global surrogate to the black box model from interpret.ext.glassbox import LGBMExplainableModel from interpret.ext.glassbox import LinearExplainableModel from interpret.ext.glassbox import SGDExplainableModel from interpret.ext.glassbox import DecisionTreeExplainableModel # "features" and "classes" fields are optional # augment_data is optional and if true, oversamples the initialization examples to improve surrogate model accuracy to fit original model. Useful for high-dimensional data where the number of rows is less than the number of columns. # max_num_of_augmentations is optional and defines max number of times we can increase the input data size. # LGBMExplainableModel can be replaced with LinearExplainableModel, SGDExplainableModel, or DecisionTreeExplainableModel explainer = MimicExplainer(model, x_train, LGBMExplainableModel, augment_data=True, max_num_of_augmentations=10, features=breast_cancer_data.feature_names, classes=classes)or
from interpret.ext.blackbox import PFIExplainer # "features" and "classes" fields are optional explainer = PFIExplainer(model, features=breast_cancer_data.feature_names, classes=classes)
Spiegare l'intero comportamento del modello (spiegazione globale)
Fare riferimento all'esempio seguente per informazioni su come ottenere i valori di importanza delle caratteristiche aggregati (globali).
# you can use the training data or the test data here, but test data would allow you to use Explanation Exploration
global_explanation = explainer.explain_global(x_test)
# if you used the PFIExplainer in the previous step, use the next line of code instead
# global_explanation = explainer.explain_global(x_train, true_labels=y_train)
# sorted feature importance values and feature names
sorted_global_importance_values = global_explanation.get_ranked_global_values()
sorted_global_importance_names = global_explanation.get_ranked_global_names()
dict(zip(sorted_global_importance_names, sorted_global_importance_values))
# alternatively, you can print out a dictionary that holds the top K feature names and values
global_explanation.get_feature_importance_dict()
Spiegare una singola previsione (spiegazione locale)
Ottenere i valori di importanza delle caratteristiche individuali di punti dati differenti chiamando spiegazioni per una singola istanza o un gruppo di istanze.
Nota
PFIExplainer non supporta le spiegazioni locali.
# get explanation for the first data point in the test set
local_explanation = explainer.explain_local(x_test[0:5])
# sorted feature importance values and feature names
sorted_local_importance_names = local_explanation.get_ranked_local_names()
sorted_local_importance_values = local_explanation.get_ranked_local_values()
Trasformazioni di funzionalità non elaborate
È possibile scegliere di ottenere spiegazioni in termini di funzionalità non elaborate e non trasformate anziché funzionalità progettate. Per questa opzione, si passa la pipeline di trasformazione delle funzionalità all'explainer in train_explain.py. In caso contrario, l'explainer fornisce spiegazioni in termini di funzionalità progettate.
Il formato delle trasformazioni supportate è uguale a quello descritto in sklearn-pandas. In generale, le trasformazioni sono supportate purché funzionino su una singola colonna, in modo che sia chiaro che siano uno-a-molte.
Ottenere una spiegazione delle funzionalità non elaborate usando un sklearn.compose.ColumnTransformer o con un elenco di tuple trasformatori montate. Nell'esempio seguente viene utilizzato sklearn.compose.ColumnTransformer:
from sklearn.compose import ColumnTransformer
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# append classifier to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=preprocessor)
Nel caso in cui si desideri eseguire l'esempio con l'elenco di tuple trasformatori montate, usare il codice seguente:
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn_pandas import DataFrameMapper
# assume that we have created two arrays, numerical and categorical, which holds the numerical and categorical feature names
numeric_transformations = [([f], Pipeline(steps=[('imputer', SimpleImputer(
strategy='median')), ('scaler', StandardScaler())])) for f in numerical]
categorical_transformations = [([f], OneHotEncoder(
handle_unknown='ignore', sparse=False)) for f in categorical]
transformations = numeric_transformations + categorical_transformations
# append model to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', DataFrameMapper(transformations)),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=transformations)
Generare valori di importanza delle caratteristiche tramite esecuzioni remote
Nell'esempio seguente viene illustrato come usare la classe ExplanationClient per abilitare l'interpretabilità del modello per le esecuzioni remote. È concettualmente simile al processo locale, ad eccezione di quanto riportato di seguito:
- Usare
ExplanationClientnell'esecuzione remota per caricare il contesto di interpretabilità. - Scaricare il contesto più avanti in un ambiente locale.
Installare il pacchetto
azureml-interpret.pip install azureml-interpretCreare uno script di training in un'istanza di Jupyter Notebook locale. Ad esempio,
train_explain.py.from azureml.interpret import ExplanationClient from azureml.core.run import Run from interpret.ext.blackbox import TabularExplainer run = Run.get_context() client = ExplanationClient.from_run(run) # write code to get and split your data into train and test sets here # write code to train your model here # explain predictions on your local machine # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=feature_names, classes=classes) # explain overall model predictions (global explanation) global_explanation = explainer.explain_global(x_test) # uploading global model explanation data for storage or visualization in webUX # the explanation can then be downloaded on any compute # multiple explanations can be uploaded client.upload_model_explanation(global_explanation, comment='global explanation: all features') # or you can only upload the explanation object with the top k feature info #client.upload_model_explanation(global_explanation, top_k=2, comment='global explanation: Only top 2 features')Configurare un ambiente di calcolo di Azure Machine Learning come destinazione di calcolo e inviare l'esecuzione del training. Per istruzioni, vedere Creare e gestire cluster di elaborazione di Azure Machine Learning. È anche possibile trovare utili i notebook di esempio.
Scaricare la spiegazione nel Jupyter Notebook locale.
from azureml.interpret import ExplanationClient client = ExplanationClient.from_run(run) # get model explanation data explanation = client.download_model_explanation() # or only get the top k (e.g., 4) most important features with their importance values explanation = client.download_model_explanation(top_k=4) global_importance_values = explanation.get_ranked_global_values() global_importance_names = explanation.get_ranked_global_names() print('global importance values: {}'.format(global_importance_values)) print('global importance names: {}'.format(global_importance_names))
Visualizzazioni
Dopo aver scaricato le spiegazioni nel Jupyter Notebook locale, è possibile usare le visualizzazioni contenute nel dashboard delle spiegazioni per comprendere e interpretare il modello. Per caricare il widget del dashboard sulle spiegazioni nel Jupyter Notebook, usare il codice seguente:
from raiwidgets import ExplanationDashboard
ExplanationDashboard(global_explanation, model, datasetX=x_test)
Le visualizzazioni supportano le spiegazioni sia sulle funzionalità progettate che sulle quelle non elaborate. Le spiegazioni non elaborate si basano sulle funzionalità del set di dati originale, mentre quelle progettate si basano sulle funzionalità del set di dati con la progettazione delle funzionalità applicata.
Quando si tenta di interpretare un modello rispetto al set di dati originale, è consigliabile usare spiegazioni non elaborate, in quanto ogni importanza della caratteristica corrisponderà a una colonna del set di dati originale. Uno scenario in cui le spiegazioni progettate potrebbero essere utili è esaminare l'impatto delle singole categorie da una funzionalità categorica. Se una codifica one-hot viene applicata a una funzionalità categorica, le spiegazioni progettate risultanti includeranno un valore di importanza differente per categoria, uno per ogni funzionalità progettata one-hot. Questa codifica può essere utile quando si restringe il campo alla parte del set di dati più informativa per il modello.
Nota
Le spiegazioni progettate e non elaborate vengono calcolate in sequenza. Prima di tutto viene creata una spiegazione progettata in base al modello e alla pipeline di definizione delle funzionalità. Successivamente, la spiegazione non elaborata viene creata in base a tale spiegazione progettata aggregando l'importanza delle funzionalità progettate provenienti dalla stessa funzionalità non elaborata.
Creare, modificare e visualizzare le coorti dei set di dati
La barra multifunzione superiore mostra le statistiche complessive sul modello e sui dati. È possibile scomporre e analizzare i dati in coorti di set di dati o sottogruppi per analizzare o confrontare le prestazioni e le spiegazioni del modello nei sottogruppi definiti. Confrontando le statistiche e le spiegazioni del set di dati nei sottogruppi, è possibile comprendere il motivo per cui si verificano errori in un gruppo rispetto a un altro.

Comprendere l'intero comportamento del modello (spiegazione globale)
Le prime tre schede del dashboard di spiegazione forniscono un'analisi complessiva del modello sottoposto a training insieme alle relative previsioni e spiegazioni.
Prestazioni modello
Valutare le prestazioni del modello esplorando la distribuzione dei valori di previsione e i valori delle metriche delle prestazioni del modello. È possibile analizzare ulteriormente il modello esaminando un'analisi comparativa delle prestazioni in coorti o sottogruppi differenti del set di dati. Selezionare i filtri lungo i valori x e y e per attraversare le varie dimensioni. Visualizzare metriche come accuratezza, precisione, richiamo, tasso di falsi positivi (FPR) e tasso di falsi negativi (FNR).

Esplora set di dati
Esplorare le statistiche del set di dati selezionando diversi filtri lungo gli assi X, Y e colore per filtrare i dati in base a dimensioni differenti. Creare coorti di set di dati precedenti per analizzare le statistiche del set di dati con filtri come il risultato stimato, le funzionalità del set di dati e i gruppi di errori. Usare l'icona a forma di ingranaggio nell'angolo in alto a destra del grafico per modificare i tipi di grafico.

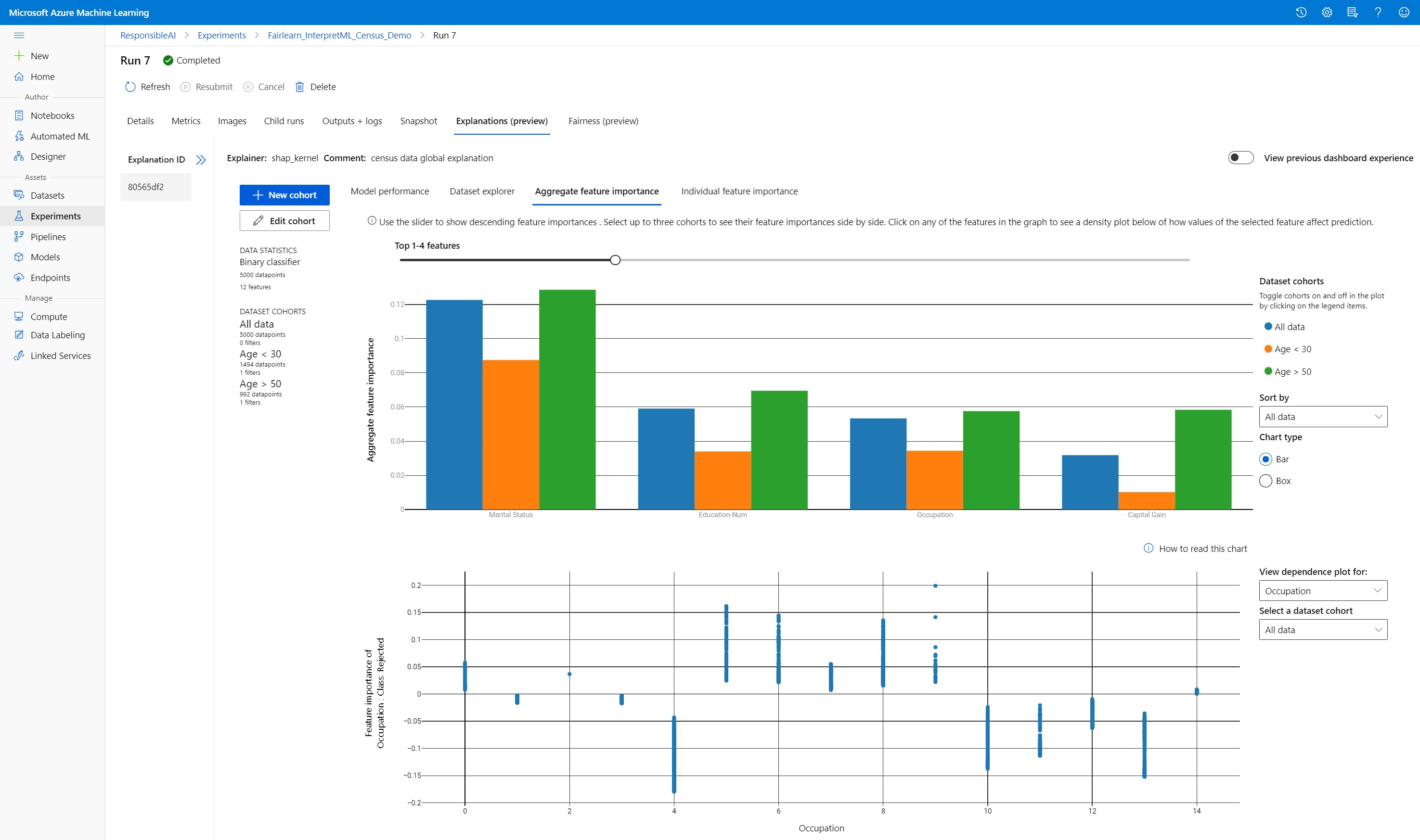
Importanza delle caratteristiche aggregate
Esplorare le funzionalità top-k importanti che influiscono sulle previsioni complessive del modello (note anche come spiegazioni globali). Usare il dispositivo di scorrimento per visualizzare i valori di importanza delle caratteristiche in ordine decrescente. Selezionare fino a tre coorti per visualizzare i relativi valori di importanza delle caratteristiche affiancati. Selezionare una delle barre delle funzionalità nel grafico per visualizzare il modo in cui i valori della funzionalità selezionata influiscono sulla previsione del modello nel tracciato delle dipendenze riportato di seguito.

Informazioni sulle singole previsioni (spiegazione locale)
La quarta sezione della scheda Spiegazione consente di esaminare un singolo punto dati e le relative importanze delle caratteristiche individuali. È possibile caricare il tracciato delle importanze delle caratteristiche individuali per qualsiasi punto dati facendo clic su uno dei singoli punti dati nel grafico a dispersione principale o selezionando un punto di dati specifico nella procedura guidata del pannello a destra.
| Grafico | Descrizione |
|---|---|
| Importanza delle caratteristiche individuali | Mostra le funzionalità top-k importanti per una singola previsione. Contribuisce a illustrare il comportamento locale del modello sottostante in un punto dati specifico. |
| Analisi di simulazione | Consente di modificare i valori delle funzionalità del punto dati reale selezionato e osservare le modifiche risultanti al valore di previsione generando un punto dati ipotetico con i nuovi valori di funzionalità. |
| Aspettativa Condizionale Individuale (ICE) | Consente di modificare il valore della funzionalità da un valore minimo a uno massimo. Contribuisce a illustrare il modo in cui cambia la previsione del punto dati quando cambia una funzionalità. |

Nota
Sono spiegazioni basate su molte approssimazioni e non sono la "causa" delle previsioni. Senza una robustezza matematica rigorosa dell'inferenza causale, non consigliamo agli utenti di prendere decisioni reali in base alle perturbazioni delle caratteristiche dello strumento Simulazione. Questo strumento serve principalmente a comprendere il modello e il debug.
Visualizzazione in Studio di Azure Machine Learning
Se si completano i passaggi di interpretabilità remota (caricamento di spiegazioni generate nella Cronologia di esecuzione di Azure Machine Learning), è possibile vedere le visualizzazioni nel dashboard delle spiegazioni in Studio di Azure Machine Learning. Questo dashboard è una versione più semplice del widget del dashboard generato all'interno del Jupyter Notebook. La generazione dei punti dati di simulazione e i tracciati ICE sono disabilitati perché non è disponibile alcun calcolo attivo in Studio di Azure Machine Learning in grado di eseguire i calcoli in tempo reale.
Se sono disponibili il set di dati, le spiegazioni globali e locali, i dati popolano tutte le schede. Tuttavia, se è disponibile solo una spiegazione globale, la scheda Importanza della caratteristica individuale verrà disabilitata.
Seguire uno di questi percorsi per accedere al dashboard delle spiegazioni in Studio di Azure Machine Learning:
Riquadro Esperimenti (anteprima)
- Selezionare Esperimenti nel riquadro a sinistra per visualizzare un elenco di esperimenti eseguiti in Azure Machine Learning.
- Selezionare un esperimento specifico per visualizzare tutte le esecuzioni nell'esperimento.
- Selezionare un'esecuzione e quindi la scheda Spiegazioni per aprire il dashboard per la visualizzazione della spiegazione.
Riquadro Modelli
- Se il modello originale è stato registrato seguendo la procedura descritta in Distribuire modelli con Azure Machine Learning, è possibile selezionare Modelli nel riquadro sinistro per visualizzarlo.
- Selezionare un modello e successivamente la scheda Spiegazioni per visualizzare il dashboard delle spiegazioni.

Interpretabilità in fase di inferenza
È possibile distribuire l'explainer insieme al modello originale e usarlo in fase di inferenza per fornire i singoli valori di importanza delle caratteristiche (spiegazione locale) per qualsiasi nuovo punto dati. Sono inoltre disponibili explainer sull'assegnazione dei punteggi più leggeri per migliorare le prestazioni di interpretazione in fase di inferenza; al momento, tali explainer sono supportati soltanto in Azure Machine Learning SDK. Il processo di distribuzione di un explainer sull'assegnazione dei punteggi più leggero è simile alla distribuzione di un modello e include i passaggi seguenti:
Creare un oggetto di spiegazione. È ad esempio possibile usare
TabularExplainer:from interpret.ext.blackbox import TabularExplainer explainer = TabularExplainer(model, initialization_examples=x_train, features=dataset_feature_names, classes=dataset_classes, transformations=transformations)Creare un explainer sull'assegnazione dei punteggi con l'oggetto spiegazione.
from azureml.interpret.scoring.scoring_explainer import KernelScoringExplainer, save # create a lightweight explainer at scoring time scoring_explainer = KernelScoringExplainer(explainer) # pickle scoring explainer # pickle scoring explainer locally OUTPUT_DIR = 'my_directory' save(scoring_explainer, directory=OUTPUT_DIR, exist_ok=True)Configurare e registrare un'immagine che usa il modello dell'explainer sull'assegnazione dei punteggi.
# register explainer model using the path from ScoringExplainer.save - could be done on remote compute # scoring_explainer.pkl is the filename on disk, while my_scoring_explainer.pkl will be the filename in cloud storage run.upload_file('my_scoring_explainer.pkl', os.path.join(OUTPUT_DIR, 'scoring_explainer.pkl')) scoring_explainer_model = run.register_model(model_name='my_scoring_explainer', model_path='my_scoring_explainer.pkl') print(scoring_explainer_model.name, scoring_explainer_model.id, scoring_explainer_model.version, sep = '\t')Come passaggio facoltativo, è possibile recuperare l'explainer sull'assegnazione dei punteggi dal cloud e testare le spiegazioni.
from azureml.interpret.scoring.scoring_explainer import load # retrieve the scoring explainer model from cloud" scoring_explainer_model = Model(ws, 'my_scoring_explainer') scoring_explainer_model_path = scoring_explainer_model.download(target_dir=os.getcwd(), exist_ok=True) # load scoring explainer from disk scoring_explainer = load(scoring_explainer_model_path) # test scoring explainer locally preds = scoring_explainer.explain(x_test) print(preds)Procedere come segue per distribuire l'immagine in una destinazione di calcolo:
Se necessario, registrare il modello di previsione originale, seguire la procedura descritta in Distribuire modelli con Azure Machine Learning.
Creare un file di assegnazione dei punteggi.
%%writefile score.py import json import numpy as np import pandas as pd import os import pickle from sklearn.externals import joblib from sklearn.linear_model import LogisticRegression from azureml.core.model import Model def init(): global original_model global scoring_model # retrieve the path to the model file using the model name # assume original model is named original_prediction_model original_model_path = Model.get_model_path('original_prediction_model') scoring_explainer_path = Model.get_model_path('my_scoring_explainer') original_model = joblib.load(original_model_path) scoring_explainer = joblib.load(scoring_explainer_path) def run(raw_data): # get predictions and explanations for each data point data = pd.read_json(raw_data) # make prediction predictions = original_model.predict(data) # retrieve model explanations local_importance_values = scoring_explainer.explain(data) # you can return any data type as long as it is JSON-serializable return {'predictions': predictions.tolist(), 'local_importance_values': local_importance_values}Definire la configurazione della distribuzione.
Questa configurazione dipende dai requisiti del modello. L'esempio seguente definisce una configurazione che usa un core CPU e un GB di memoria.
from azureml.core.webservice import AciWebservice aciconfig = AciWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, tags={"data": "NAME_OF_THE_DATASET", "method" : "local_explanation"}, description='Get local explanations for NAME_OF_THE_PROBLEM')Creare un file con dipendenze dell'ambiente.
from azureml.core.conda_dependencies import CondaDependencies # WARNING: to install this, g++ needs to be available on the Docker image and is not by default (look at the next cell) azureml_pip_packages = ['azureml-defaults', 'azureml-core', 'azureml-telemetry', 'azureml-interpret'] # specify CondaDependencies obj myenv = CondaDependencies.create(conda_packages=['scikit-learn', 'pandas'], pip_packages=['sklearn-pandas'] + azureml_pip_packages, pin_sdk_version=False) with open("myenv.yml","w") as f: f.write(myenv.serialize_to_string()) with open("myenv.yml","r") as f: print(f.read())Creare un dockerfile personalizzato con g++ installato.
%%writefile dockerfile RUN apt-get update && apt-get install -y g++Distribuire l'immagine creata.
Il completamento di questo processo richiede circa cinque minuti.
from azureml.core.webservice import Webservice from azureml.core.image import ContainerImage # use the custom scoring, docker, and conda files we created above image_config = ContainerImage.image_configuration(execution_script="score.py", docker_file="dockerfile", runtime="python", conda_file="myenv.yml") # use configs and models generated above service = Webservice.deploy_from_model(workspace=ws, name='model-scoring-service', deployment_config=aciconfig, models=[scoring_explainer_model, original_model], image_config=image_config) service.wait_for_deployment(show_output=True)
Testare la distribuzione.
import requests # create data to test service with examples = x_list[:4] input_data = examples.to_json() headers = {'Content-Type':'application/json'} # send request to service resp = requests.post(service.scoring_uri, input_data, headers=headers) print("POST to url", service.scoring_uri) # can covert back to Python objects from json string if desired print("prediction:", resp.text)Eseguire la pulizia.
Per eliminare un servizio Web distribuito, usare
service.delete().
Risoluzione dei problemi
Dati di tipo sparse non supportati: il dashboard di spiegazione del modello si interrompe/rallenta notevolmente con un numero elevato di funzionalità; pertanto al momento il formato dati sparse non è al momento supportato. Inoltre, si verificheranno problemi di memoria generali con set di dati di grandi dimensioni e un numero elevato di caratteristiche.
Matrice delle funzionalità di spiegazioni supportate
| Scheda Spiegazione supportata | Funzionalità non elaborate (dense) | Funzionalità non elaborate (sparse) | Funzionalità progettate (dense) | Funzionalità progettate (sparse) |
|---|---|---|---|---|
| Prestazioni modello | Supportata (senza previsione) | Supportata (senza previsione) | Supportata | Supportata |
| Esplora set di dati | Supportata (senza previsione) | Non supportato. Poiché i dati di tipo sparse non vengono caricati e l'interfaccia utente presenta problemi di rendering dei dati di tipo sparse. | Supportata | Non supportato. Poiché i dati di tipo sparse non vengono caricati e l'interfaccia utente presenta problemi di rendering dei dati di tipo sparse. |
| Importanza delle caratteristiche aggregate | Supportata | Supportato | Supportato | Supportata |
| Importanza delle caratteristiche individuali | Supportata (senza previsione) | Non supportato. Poiché i dati di tipo sparse non vengono caricati e l'interfaccia utente presenta problemi di rendering dei dati di tipo sparse. | Supportata | Non supportato. Poiché i dati di tipo sparse non vengono caricati e l'interfaccia utente presenta problemi di rendering dei dati di tipo sparse. |
I modelli di previsione non sono supportati con le spiegazioni del modello: l'interpretabilità, la spiegazione del modello migliore, non è disponibile per gli esperimenti di previsione AutoML che consigliano gli algoritmi seguenti come modello migliore: TCNForecaster, AutoArima, Prophet, ExponentialSmoothing, Average, Naive, Stagional Average e Stagionale Naive. I modelli di regressione di previsione autoML supportano le spiegazioni. Tuttavia, nel dashboard di spiegazione la scheda "Importanza delle caratteristiche individuali" non è supportata per la previsione a causa della complessità nelle pipeline di dati.
Spiegazione locale per l'indice dei dati: il dashboard di spiegazione non supporta la correlazione dei valori di importanza locale a un identificatore di riga del set di dati di convalida originale se tale set di dati è maggiore di 5000 punti dati, poiché l dashboard esegue il sotto-campionamento casuale dei dati. Tuttavia, il dashboard mostra i valori delle funzionalità del set di dati non elaborati per ogni punto dati passato nel dashboard nella scheda Importanza delle caratteristiche individuali. Gli utenti possono eseguire il mapping delle importanze locali al set di dati originale tramite la corrispondenza dei valori delle funzionalità del set di dati non elaborati. Se le dimensioni del set di dati di convalida sono inferiori a 5000 campioni, la
indexfunzionalità in Studio di Azure Machine Learning corrisponderà all'indice nel set di dati di convalida.Tracciati di simulazione/ICE non supportati in Studio: i tracciati di simulazione e delle aspettative condizionali individuali (ICE) non sono supportati in Studio di Azure Machine Learning nella scheda Spiegazioni, in quanto la spiegazione caricata richiede un calcolo attivo per ricalcolare le previsioni e le probabilità delle funzionalità perturbate. È attualmente supportato nei Jupyter Notebook quando viene eseguito come widget usando l'SDK.
Passaggi successivi
Tecniche per l'interpretabilità del modello in Azure Machine Learning
Vedere notebook di esempio di interpretabilità di Azure Machine Learning