Implementare il controllo delle versioni e tenere traccia dei set di dati di Azure Machine Learning
Si applica a:  Python SDK azureml v1
Python SDK azureml v1
Questo articolo illustra come implementare il controllo delle versioni e tenere traccia dei set di dati di Azure Machine Learning per la riproducibilità. Il controllo delle versioni dei set di dati include segnalibri specifici degli stati dei dati, in modo da poter applicare una versione specifica del set di dati per esperimenti futuri.
È consigliabile creare una versione delle risorse di Azure Machine Learning in questi scenari tipici:
- Quando nuovi dati diventano disponibili per ripetere il training
- Quando si applicano approcci diversi alla preparazione dei dati o all'ingegneria delle funzionalità
Prerequisiti
SDK Azure Machine Learning per Python. Questo SDK include il pacchetto azureml-datasets.
Un'area di lavoro di Azure Machine Learning. Creare una nuova area di lavoro o recuperare un'area di lavoro esistente con questo esempio di codice:
import azureml.core from azureml.core import Workspace ws = Workspace.from_config()
Registrare e recuperare le versioni dei set di dati
È possibile variare in base alla versione, riutilizzare e condividere un set di dati registrato tra diversi esperimenti e tra colleghi. È possibile registrare più set di dati con lo stesso nome e recuperare una versione specifica in base al nome e al numero di versione.
Registrare una versione di un set di dati
Questo esempio di codice imposta il parametro create_new_version del set di dati titanic_ds su True per registrare una nuova versione del set di dati. Se l'area di lavoro non dispone di un set di dati titanic_ds esistente registrato, il codice crea un nuovo set di dati con il nome titanic_ds e ne imposta la versione su 1.
titanic_ds = titanic_ds.register(workspace = workspace,
name = 'titanic_ds',
description = 'titanic training data',
create_new_version = True)
Recuperare un set di dati in base al nome
Per impostazione predefinita, il metodo Dataset di classe get_by_name() restituisce la versione più recente del set di dati registrato nell'area di lavoro.
Questo codice restituisce la versione 1 del set di dati titanic_ds.
from azureml.core import Dataset
# Get a dataset by name and version number
titanic_ds = Dataset.get_by_name(workspace = workspace,
name = 'titanic_ds',
version = 1)
Procedura consigliata relativa al controllo delle versioni
Quando si crea una versione del set di dati, non viene creata una copia aggiuntiva dei dati nell'area di lavoro. Poiché i set di dati sono riferimenti ai dati nel servizio di archiviazione, è disponibile un'unica origine di riferimento gestita dal servizio di archiviazione.
Importante
Se i dati a cui il set di dati fa riferimento vengono sovrascritti o eliminati, la chiamata di una versione specifica del set di dati non annulla la modifica.
Quando si caricano dati da un set di dati, il contenuto dei dati corrente a cui fa riferimento il set di dati viene sempre caricato. Per assicurarsi che ogni versione del set di dati sia riproducibile, è consigliabile evitare di modificare il contenuto dei dati a cui la versione del set di dati fa riferimento. Quando sono disponibili nuovi dati, salvare i nuovi file di dati in una cartella diversa e quindi creare una nuova versione del set di dati che includa i dati di tale cartella.
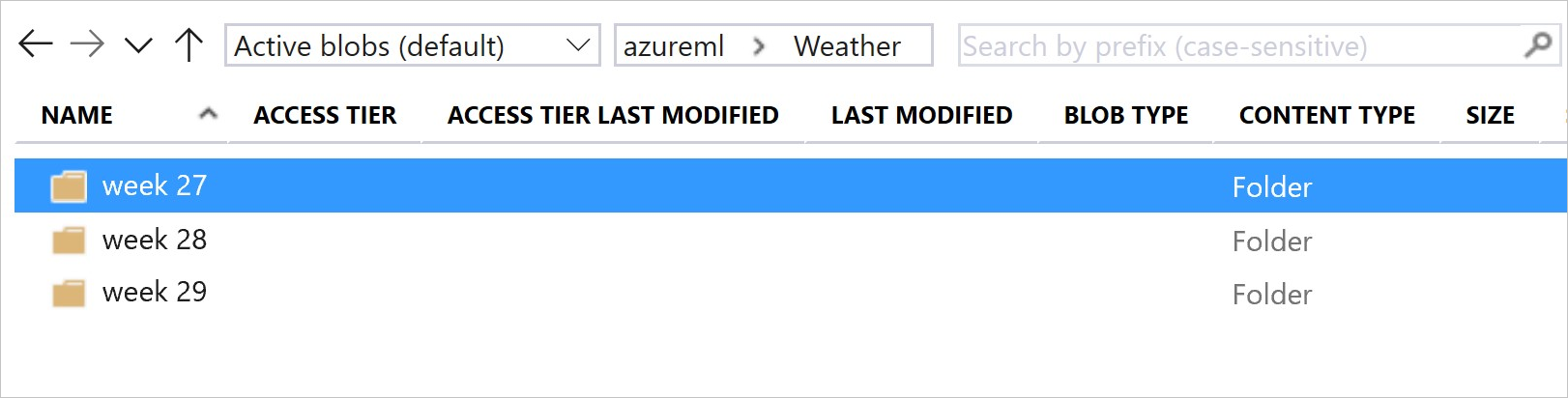
Questa immagine e codice di esempio illustrano il metodo consigliato sia per strutturare le cartelle di dati che per creare versioni del set di dati che fanno riferimento a tali cartelle:
from azureml.core import Dataset
# get the default datastore of the workspace
datastore = workspace.get_default_datastore()
# create & register weather_ds version 1 pointing to all files in the folder of week 27
datastore_path1 = [(datastore, 'Weather/week 27')]
dataset1 = Dataset.File.from_files(path=datastore_path1)
dataset1.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27',
create_new_version = True)
# create & register weather_ds version 2 pointing to all files in the folder of week 27 and 28
datastore_path2 = [(datastore, 'Weather/week 27'), (datastore, 'Weather/week 28')]
dataset2 = Dataset.File.from_files(path = datastore_path2)
dataset2.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27, 28',
create_new_version = True)
Implementare il controllo delle versioni per un set di dati di output della pipeline di ML
È possibile usare un set di dati come input e output di ogni passaggio della pipeline di ML. Quando si eseguono di nuovo le pipeline, l'output di ogni passaggio della pipeline viene registrato come nuova versione del set di dati.
Le pipeline di Machine Learning popolano l'output di ogni passaggio in una nuova cartella ogni volta che la pipeline viene eseguita di nuovo. I set di dati di output con controllo delle versioni diventano quindi riproducibili. Per altre informazioni, vedere Set di dati nelle pipeline.
from azureml.core import Dataset
from azureml.pipeline.steps import PythonScriptStep
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.core. runconfig import CondaDependencies, RunConfiguration
# get input dataset
input_ds = Dataset.get_by_name(workspace, 'weather_ds')
# register pipeline output as dataset
output_ds = PipelineData('prepared_weather_ds', datastore=datastore).as_dataset()
output_ds = output_ds.register(name='prepared_weather_ds', create_new_version=True)
conda = CondaDependencies.create(
pip_packages=['azureml-defaults', 'azureml-dataprep[fuse,pandas]'],
pin_sdk_version=False)
run_config = RunConfiguration()
run_config.environment.docker.enabled = True
run_config.environment.python.conda_dependencies = conda
# configure pipeline step to use dataset as the input and output
prep_step = PythonScriptStep(script_name="prepare.py",
inputs=[input_ds.as_named_input('weather_ds')],
outputs=[output_ds],
runconfig=run_config,
compute_target=compute_target,
source_directory=project_folder)
Tenere traccia dei dati negli esperimenti
Azure Machine Learning tiene traccia dei dati durante l'esperimento come set di dati di input e output. In questi scenari, i dati vengono rilevati come set di dati di input:
Come oggetto
DatasetConsumptionConfigtramite il parametroinputsoargumentsdell'oggettoScriptRunConfigquando si invia il processo dell'esperimentoQuando lo script chiama determinati metodi, ad esempio
get_by_name()oget_by_id(). Il nome assegnato al set di dati al momento della sua registrazione nell'area di lavoro è il nome visualizzato
In questi scenari, i dati vengono rilevati come set di dati di output:
Passaggio di un oggetto
OutputFileDatasetConfigtramite il parametrooutputsoargumentsquando si invia un processo di un esperimento. Gli oggettiOutputFileDatasetConfigpossono anche rendere persistenti i dati tra i passaggi della pipeline. Per altre informazioni, vedere Spostare dati tra passaggi della pipeline di Machine LearningRegistrazione di un set di dati nello script. Il nome assegnato al set di dati al momento della sua registrazione nell'area di lavoro è il nome visualizzato. In questo esempio di codice,
training_dsè il nome visualizzato:training_ds = unregistered_ds.register(workspace = workspace, name = 'training_ds', description = 'training data' )Invio di un processo figlio con un set di dati non registrato nello script. Questo invio genera un set di dati anonimo salvato
Analizzare i set di dati nei processi dell'esperimento
Per ogni esperimento di Machine Learning, è possibile tracciare i set di dati di input per l’oggetto Job dell’esperimento. Questo esempio di codice usa il metodo get_details() per tenere traccia dei set di dati di input usati con l'esecuzione dell'esperimento:
# get input datasets
inputs = run.get_details()['inputDatasets']
input_dataset = inputs[0]['dataset']
# list the files referenced by input_dataset
input_dataset.to_path()
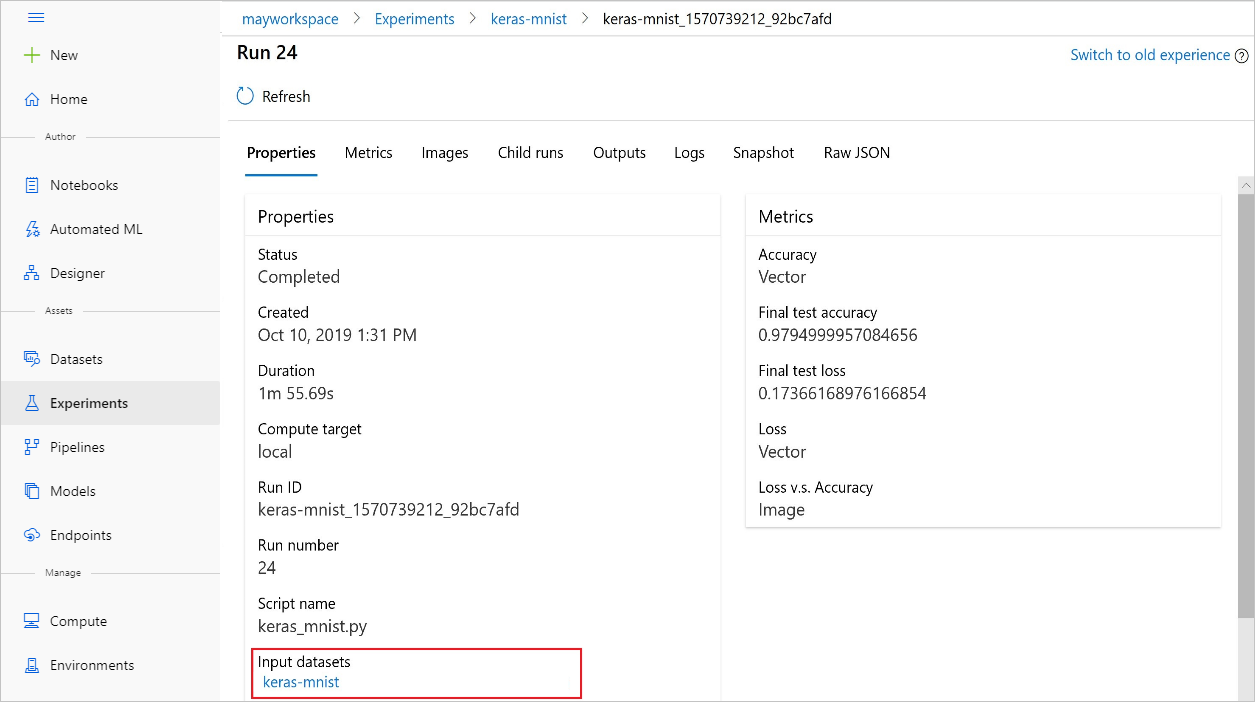
È anche possibile trovare input_datasets da esperimenti con Azure Machine Learning Studio.
Questo screenshot mostra dove trovare il set di dati di input di un esperimento in Azure Machine Learning Studio. Per questo esempio, iniziare al riquadro Esperimenti e aprire la scheda Proprietà per un'esecuzione specifica dell'esperimento, keras-mnist.
Questo codice registra i modelli con set di dati:
model = run.register_model(model_name='keras-mlp-mnist',
model_path=model_path,
datasets =[('training data',train_dataset)])
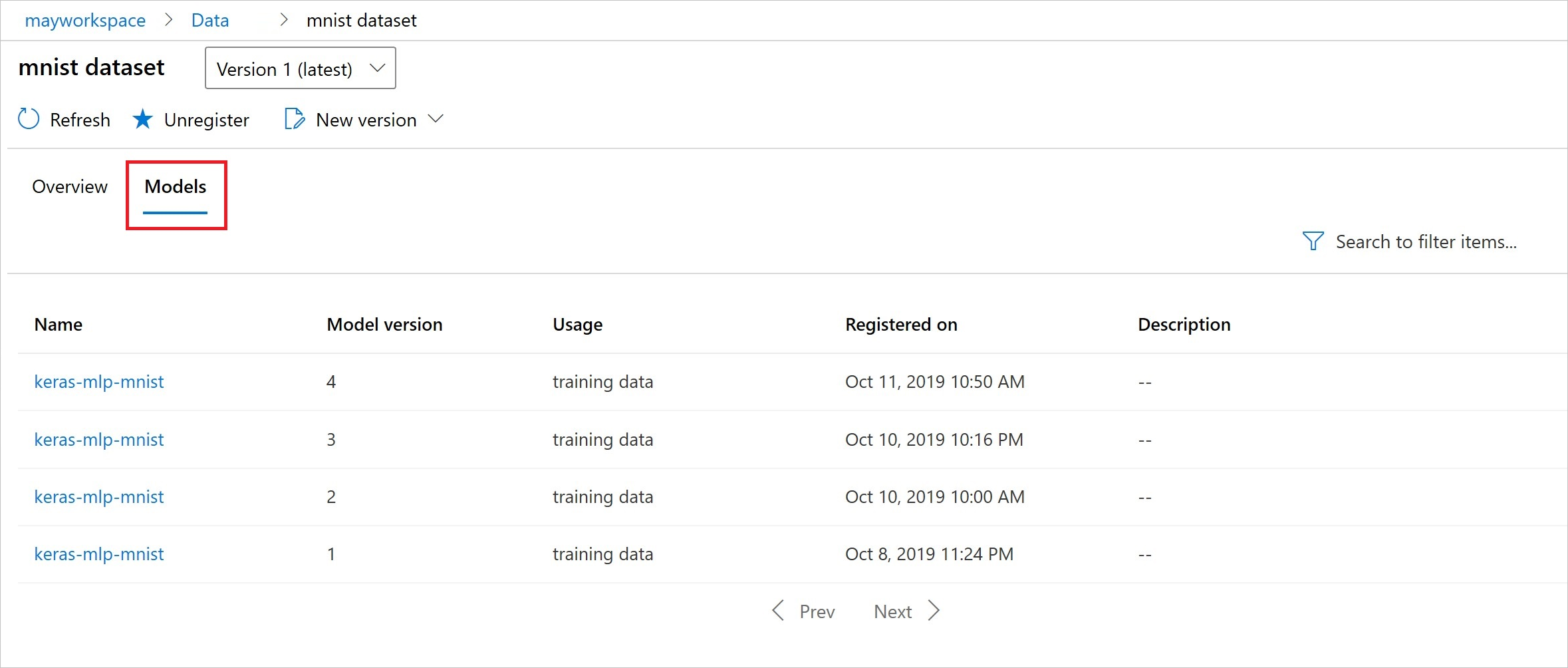
Dopo la registrazione, è possibile visualizzare l'elenco dei modelli registrati con il set di dati tramite Python o Studio.
Questo screenshot è disponibile nel riquadro Set di dati in Asset. Selezionare il set di dati e quindi selezionare la scheda Modelli per un elenco dei modelli registrati con il set di dati.