Data wrangling interattivo con Apache Spark in Azure Machine Learning
Il data wrangling diventa uno dei passaggi più importanti dei progetti di Machine Learning. L'integrazione di Azure Machine Learning, con Azure Synapse Analytics, fornisce l'accesso a un pool di Spark Apache, supportato da Azure Synapse, per il data wrangling interattivo usando i notebook di Azure Machine Learning.
In questo articolo si apprenderà come eseguire il data wrangling usando
- Calcolo Spark serverless
- Pool di Spark Synapse collegato
Prerequisiti
- Una sottoscrizione di Azure; se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
- Un'area di lavoro di Azure Machine Learning. Vedere Creare le risorse dell'area di lavoro.
- Un account di archiviazione di Azure Data Lake Storage (ADLS) Gen 2. Consultare Creare un account di archiviazione di Azure Data Lake Storage (ADLS) Gen 2.
- (Facoltativo): insieme di credenziali delle chiavi di Azure. Consultare Creare un Azure Key Vault.
- (Facoltativo): un'entità servizio. Consultare Creare un'entità servizio.
- (facoltativo): pool di Spark synapse collegato nell'area di lavoro di Azure Machine Learning.
Prima di iniziare le attività di data wrangling, è necessario scoprire le informazioni sul processo di archiviazione dei segreti
- Chiave di accesso dell'account di archiviazione BLOB di Azure
- Token di firma di accesso condiviso (SAS)
- Informazioni sull'entità servizio di Azure Data Lake Storage (ADLS) Gen 2
in Azure Key Vault. È anche necessario sapere come gestire le assegnazioni di ruolo negli account di archiviazione di Azure. Le seguenti sezioni esaminano questi concetti. Verranno quindi esaminati i dettagli del data wrangling interattivo usando i pool di Spark nei notebook di Azure Machine Learning.
Suggerimento
Per informazioni sulla configurazione dell'assegnazione di ruolo dell'account di archiviazione di Azure o se si accede ai dati negli account di archiviazione usando il pass-through dell'identità utente, consultare Aggiungere assegnazioni di ruolo negli account di archiviazione di Azure.
Data wrangling interattivo con Apache Spark
Azure Machine Learning offre risorse di calcolo Spark serverless e pool di Spark collegati per il data wrangling interattivo con Apache Spark nei notebook di Azure Machine Learning. L'ambiente di calcolo Spark serverless non richiede la creazione di risorse nell'area di lavoro di Azure Synapse. Al contrario, un ambiente di calcolo Spark serverless completamente gestito diventa direttamente disponibile nei notebook di Azure Machine Learning. L'uso di un ambiente di calcolo Spark serverless è l'approccio più semplice per accedere a un cluster Spark in Azure Machine Learning.
Calcolo Spark serverless nei notebook di Azure Machine Learning
Un ambiente di calcolo Spark serverless è disponibile nei notebook di Azure Machine Learning per impostazione predefinita. Per accedervi in un notebook, selezionare Calcolo Spark serverless in Spark serverless di Azure Machine Learning dal menu di selezione Calcolo.
L'interfaccia utente notebook offre anche opzioni per la configurazione della sessione Spark, per il calcolo Spark serverless. Per configurare una sessione Spark:
- Selezionare Configura sessione nella parte superiore della schermata.
- Selezionare Versione di Apache Spark dal menu a discesa.
Importante
Runtime di Azure Synapse per Apache Spark: annunci
- Runtime di Azure Synapse per Apache Spark 3.2:
- Data annuncio EOLA: 8 luglio 2023
- Data di fine supporto: 8 luglio 2024. Dopo questa data, il runtime verrà disabilitato.
- Per un supporto continuo e prestazioni ottimali, è consigliabile eseguire la migrazione ad Apache Spark 3.3.
- Runtime di Azure Synapse per Apache Spark 3.2:
- Selezionare il Tipo di istanza dal menu a discesa. Attualmente sono supportati i tipi di istanza seguenti:
Standard_E4s_v3Standard_E8s_v3Standard_E16s_v3Standard_E32s_v3Standard_E64s_v3
- Immettere un valore di timeout sessione Spark, espresso in minuti.
- Selezionare se allocare dinamicamente gli executor
- Selezionare il numero di executor per la sessione spark.
- Selezionare le dimensioni executor dal menu a discesa.
- Selezionare le dimensioni driver dal menu a discesa.
- Per usare un file Conda per configurare una sessione Spark, selezionare la casella di controllo Carica file conda. Selezionare quindi Sfogliae scegliere il file Conda con la configurazione della sessione Spark desiderata.
- Aggiungere le proprietà delle impostazioni di configurazione, i valori di input nelle caselle di testo Proprietà e Valore e selezionare Aggiungi.
- Selezionare Applica.
- Selezionare Arresta sessione nella finestra popup Configura nuova sessione?
Le modifiche alla configurazione della sessione vengono mantenute e diventano disponibili per un'altra sessione del notebook avviata usando il calcolo Spark serverless.
Suggerimento
Se si usano pacchetti Conda a livello di sessione, è possibile migliorare l'avvio a freddo della sessione Spark se si imposta la variabile spark.hadoop.aml.enable_cache di configurazione su true. L'avvio a freddo di una sessione con i pacchetti Conda a livello di sessione richiede in genere da 10 a 15 minuti all'avvio della sessione per la prima volta. Tuttavia, l'accesso sporadico successivo alla sessione inizia con la variabile di configurazione impostata su true richiede in genere da tre a cinque minuti.
Importare e radunare dati da Azure Data Lake Storage (ADLS) Gen 2
È possibile accedere e radunare dati archiviati in account di archiviazione di Azure Data Lake Storage (ADLS) Gen 2 con URI dati abfss:// seguendo uno dei due meccanismi di accesso ai dati:
- Pass-through dell'identità utente
- Accesso ai dati basato sull'entità servizio
Suggerimento
Il data wrangling con un calcolo Spark serverless e il pass-through dell'identità utente per accedere ai dati in un account di archiviazione di Azure Data Lake Storage (ADLS) Gen 2, richiede il minor numero di passaggi di configurazione.
Avviare il data wrangling interattivo con il pass-through dell'identità utente:
Verificare che l’identità utente disponga delle assegnazioni di ruolo Collaboratore e Collaboratore ai dati dei BLOB di archiviazione nell’account di archiviazione di Azure Data Lake Storage (ADLS) Gen 2.
Per usare il calcolo Spark serverless, selezionare Calcolo Spark serverless in Azure Machine Learning Serverless Spark dal menu di selezione Calcolo.
Per usare un pool di Spark Synapse collegato, selezionare un pool di Spark Synapse collegato in Pool di Spark Synapse dal menu di selezione Calcolo.
Questo esempio di codice di data wrangling Titanic mostra l'uso di un URI di dati in formato
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>conpyspark.pandasepyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled", index_col="PassengerId", )Nota
Questo esempio di codice Python usa
pyspark.pandas. Questo supporto è supportato solo dal runtime Spark versione 3.2 o successiva.
Radunare dati tramite l'accesso tramite un'entità servizio:
Verificare che l’entità servizio disponga delle assegnazioni di ruolo Collaboratore e Collaboratore ai dati dei BLOB di archiviazione nell’account di archiviazione di Azure Data Lake Storage (ADLS) Gen 2.
Creare segreti di Azure Key Vault per l'ID tenant dell'entità servizio, l'ID client e i valori dei segreti client.
Selezionare Calcolo Spark serverless in Azure Machine Learning Serverless Spark dal menu di selezione Calcolo oppure selezionare un pool di Spark Synapse collegato in Pool di Spark Synapse dal menu di selezione Calcolo.
Per impostare l'ID tenant dell'entità servizio, l'ID client e il segreto client nella configurazione ed eseguire l'esempio di codice seguente.
La chiamata
get_secret()nel codice dipende dal nome dell'insieme di credenziali delle chiavi di Azure e dai nomi dei segreti di Azure Key Vault creati per l'ID tenant dell'entità servizio, l'ID client e il segreto client. Impostare i valori/nome della proprietà corrispondenti nella configurazione:- Proprietà ID client:
fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Proprietà del segreto client:
fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Proprietà ID tenant:
fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Valore ID tenant:
https://login.microsoftonline.com/<TENANT_ID>/oauth2/token
from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary # Set up service principal tenant ID, client ID and secret from Azure Key Vault client_id = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_ID_SECRET_NAME>") tenant_id = token_library.getSecret("<KEY_VAULT_NAME>", "<TENANT_ID_SECRET_NAME>") client_secret = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_SECRET_NAME>") # Set up service principal which has access of the data sc._jsc.hadoopConfiguration().set( "fs.azure.account.auth.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "OAuth" ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth.provider.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_id, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_secret, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "https://login.microsoftonline.com/" + tenant_id + "/oauth2/token", )- Proprietà ID client:
Importare e radunare dati usando l'URI dei dati nel formato
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>come illustrato nell'esempio di codice, usando i dati Titanic.
Importare e radunare dati da Archiviazione BLOB di Azure
È possibile accedere ai dati di Archiviazione BLOB di Azure con la chiave di accesso dell'account di archiviazione o un token di firma di accesso (SAS) condiviso. È necessario archiviare queste credenziali in Azure Key Vault come segretoe impostarle come proprietà nella configurazione della sessione.
Avviare il data wrangling interattivo:
Nel pannello sinistro di studio di Azure Machine Learning selezionare Notebook.
Selezionare Calcolo Spark serverless in Azure Machine Learning Serverless Spark dal menu di selezione Calcolo oppure selezionare un pool di Spark Synapse collegato in Pool di Spark Synapse dal menu di selezione Calcolo.
Configurare la chiave di accesso dell'account di archiviazione o un token di firma di accesso (SAS) condiviso per l'accesso ai dati nei notebook di Azure Machine Learning:
Per la chiave di accesso, impostare la proprietà
fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netcome illustrato in questo frammento di codice:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary access_key = token_library.getSecret("<KEY_VAULT_NAME>", "<ACCESS_KEY_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", access_key )Per il token di firma di accesso (SAS) condiviso, impostare la proprietà
fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netcome illustrato nel frammento di codice seguente:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary sas_token = token_library.getSecret("<KEY_VAULT_NAME>", "<SAS_TOKEN_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", sas_token, )Nota
Le chiamate
get_secret()nei frammenti di codice precedenti richiedono il nome di Azure Key Vault e i nomi dei segreti creati per la chiave di accesso dell'account di Archiviazione BLOB di Azure o il token di firma di accesso (SAS) condiviso
Eseguire il codice di dati nello stesso notebook. Formattare l'URI dei dati come
wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/<PATH_TO_DATA>, in modo analogo a quanto illustrato da questo frammento di codice:import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/wrangled", index_col="PassengerId", )Nota
Questo esempio di codice Python usa
pyspark.pandas. Questo supporto è supportato solo dal runtime Spark versione 3.2 o successiva.
Importare e radunare i dati dall'archivio dati di Azure Machine Learning
Per accedere ai dati dall’archivio dati di Azure Machine Learning, definire un percorso ai dati nell’archivio dati con formato URI azureml://datastores/<DATASTORE_NAME>/paths/<PATH_TO_DATA>. Radunare dati da un archivio dati di Azure Machine Learning in una sessione notebook in modo interattivo:
Selezionare Calcolo Spark serverless in Azure Machine Learning Serverless Spark dal menu di selezione Calcolo oppure selezionare un pool di Spark Synapse collegato in Pool di Spark Synapse dal menu di selezione Calcolo.
Questo esempio di codice illustra come leggere e radunare dati Titanic da un archivio dati di Azure Machine Learning, usando l'URI dell'archivio dati
azureml://,pyspark.pandasepyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "azureml://datastores/workspaceblobstore/paths/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "azureml://datastores/workspaceblobstore/paths/data/wrangled", index_col="PassengerId", )Nota
Questo esempio di codice Python usa
pyspark.pandas. Questo supporto è supportato solo dal runtime Spark versione 3.2 o successiva.
Gli archivi dati di Azure Machine Learning possono accedere ai dati usando le credenziali dell'account di archiviazione di Azure
- Chiave di accesso
- Token di firma di accesso condiviso
- entità servizio
o fornendo l'accesso ai dati senza credenziali. A seconda del tipo di archivio dati e del tipo di account di archiviazione di Azure sottostante, selezionare un meccanismo di autenticazione appropriato per garantire l'accesso ai dati. Questa tabella riepiloga i meccanismi di autenticazione per accedere ai dati negli archivi dati di Azure Machine Learning:
| Storage account type | Accesso ai dati senza credenziali | Meccanismo di accesso ai dati | Assegnazioni di ruolo |
|---|---|---|---|
| BLOB Azure | No | Chiave di accesso o token di firma di accesso (SAS) condiviso | Nessuna assegnazione di ruolo necessaria |
| BLOB Azure | Sì | Pass-through dell'identità utente* | L'identità utente deve avere assegnazioni di ruolo appropriate nell'account di archiviazione BLOB di Azure |
| Azure Data Lake Storage (ADLS) Gen2 | No | Entità servizio | L'entità servizio deve avere assegnazioni di ruolo appropriate nell'account di archiviazione di Azure Data Lake Storage (ADLS) Gen 2 |
| Azure Data Lake Storage (ADLS) Gen2 | Sì | Pass-through dell'identità utente | L'identità utente deve avere assegnazioni di ruolo appropriate nell'account di archiviazione di Azure Data Lake Storage (ADLS) Gen 2 |
* il pass-through dell'identità utente funziona per gli archivi dati senza credenziali che puntano agli account di archiviazione BLOB di Azure, solo se l’eliminazione temporanea non è abilitata.
Accesso ai dati nella condivisione file predefinita
La condivisione file predefinita viene montata sia nel calcolo Spark serverless che nei pool di Spark collegati.
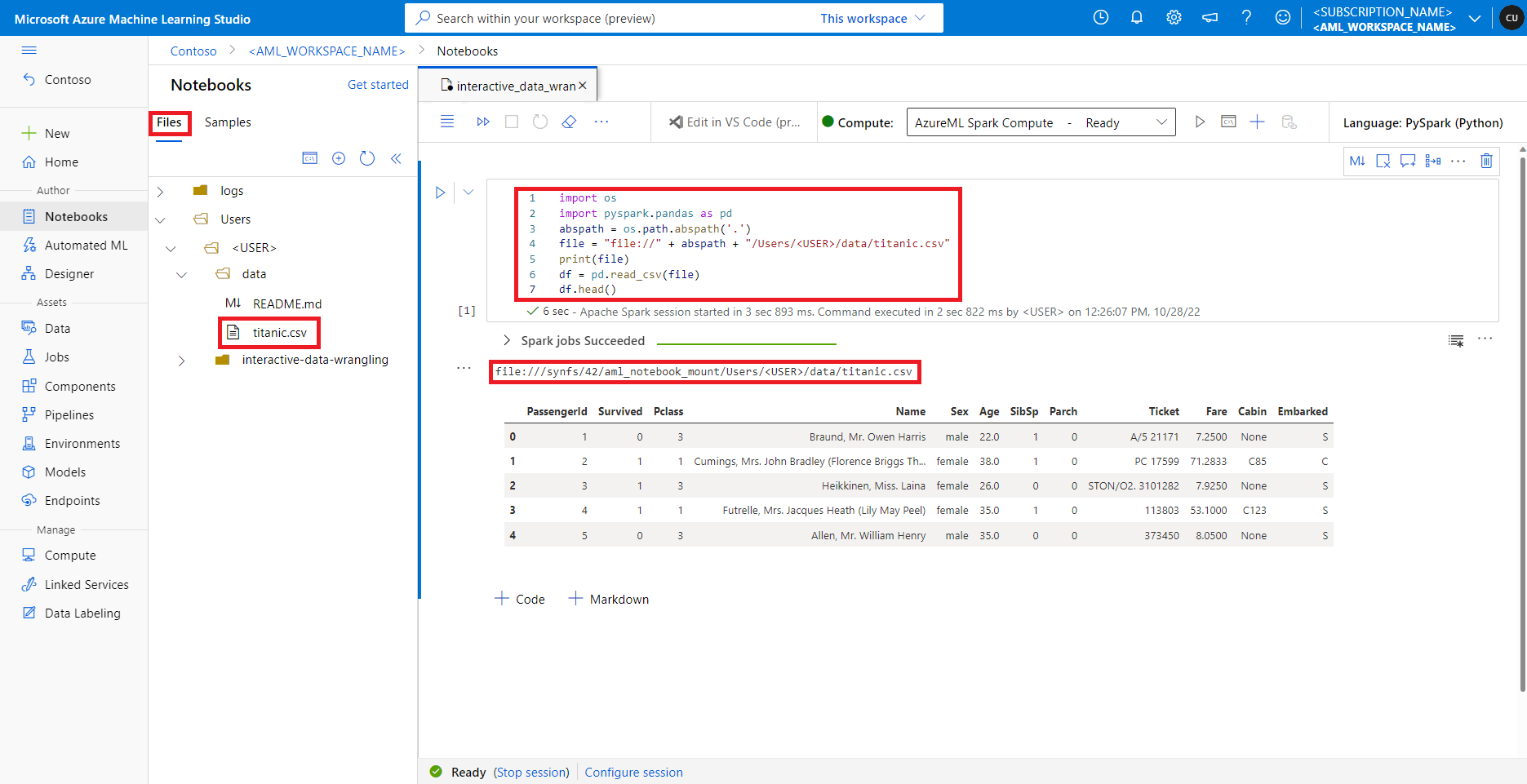
In studio di Azure Machine Learning i file nella condivisione file predefinita vengono visualizzati nell'albero delle directory nella scheda File. Il codice del notebook può accedere direttamente ai file archiviati in questa condivisione file con il protocollo file://, insieme al percorso assoluto del file, senza più configurazioni. Questo frammento di codice mostra come accedere a un file archiviato nella condivisione file predefinita:
import os
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
abspath = os.path.abspath(".")
file = "file://" + abspath + "/Users/<USER>/data/titanic.csv"
print(file)
df = pd.read_csv(file, index_col="PassengerId")
imputer = Imputer(
inputCols=["Age"],
outputCol="Age").setStrategy("mean") # Replace missing values in Age column with the mean value
df.fillna(value={"Cabin" : "None"}, inplace=True) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
output_path = "file://" + abspath + "/Users/<USER>/data/wrangled"
df.to_csv(output_path, index_col="PassengerId")
Nota
Questo esempio di codice Python usa pyspark.pandas. Questo supporto è supportato solo dal runtime Spark versione 3.2 o successiva.