Esercitazione: usare la finestra di progettazione per distribuire un modello di Machine Learning
Nella prima parte di questa esercitazione, è stato eseguito il training di un modello di regressione lineare che stima i prezzi delle automobili. In questa seconda parte, si userà la finestra di progettazione di Azure Machine Learning per distribuire il modello in modo che altri utenti possano usarlo.
Nota
La finestra di progettazione supporta due tipi di componenti: i componenti predefiniti classici (v1) e i componenti personalizzati (v2). Questi due tipi di componenti NON sono compatibili.
I componenti predefiniti classici forniscono componenti predefiniti principalmente per l'elaborazione dati e le attività di Machine Learning tradizionali come la regressione e la classificazione. Questo tipo di componente continua a essere supportato, ma non verranno aggiunti nuovi componenti.
I componenti personalizzati consentono di eseguire il wrapping del codice personalizzato come componente. Questi supportano la condivisione di componenti tra aree di lavoro e la creazione uniforme e senza interruzioni nelle interfacce di Machine Learning Studio, CLI v2 e SDK v2.
Per nuovi progetti, è consigliabile usare componenti personalizzati, che sono compatibili con Azure Machine Learning v2 e continueranno a ricevere nuovi aggiornamenti.
Questo articolo si applica ai componenti predefiniti classici e non è compatibile con CLI v2 e SDK v2.
In questa esercitazione:
- Creare una pipeline di inferenza in tempo reale.
- Creare un cluster di inferenza.
- Distribuire l'endpoint in tempo reale.
- Testare l'endpoint in tempo reale.
Prerequisiti
Completare la prima parte dell'esercitazione per apprendere come eseguire il training e assegnare un punteggio a un modello di Machine Learning nella finestra di progettazione.
Importante
Se gli elementi grafici citati in questo documento (ad esempio i pulsanti di Studio o della finestra di progettazione) non vengono visualizzati, è possibile che non si disponga del livello di autorizzazioni appropriato per l'area di lavoro. Contattare l'amministratore della sottoscrizione di Azure per verificare che sia stato concesso il livello di accesso corretto. Per altre informazioni, vedere Gestire utenti e ruoli.
Creare una pipeline di inferenza in tempo reale
Per distribuire la pipeline, è necessario prima convertire la pipeline di training in una pipeline di inferenza in tempo reale. Questo processo rimuove i componenti di training e aggiunge input e output del servizio Web per gestire le richieste.
Nota
La funzionalità Crea pipeline di inferenza supporta le pipeline di training che contengono solo i componenti predefiniti della finestra di progettazione e che dispongono di un componente come Train Model, che restituisce il modello sottoposto a training.
Creare una pipeline di inferenza in tempo reale
Selezionare Pipeline nel pannello di spostamento laterale e quindi aprire il processo della pipeline creato. Nella pagina dei dettagli, sopra l'area di disegno della pipeline, selezionare i puntini di sospensione ... e quindi scegliere Crea pipeline di inferenza>Pipeline di inferenza in tempo reale.
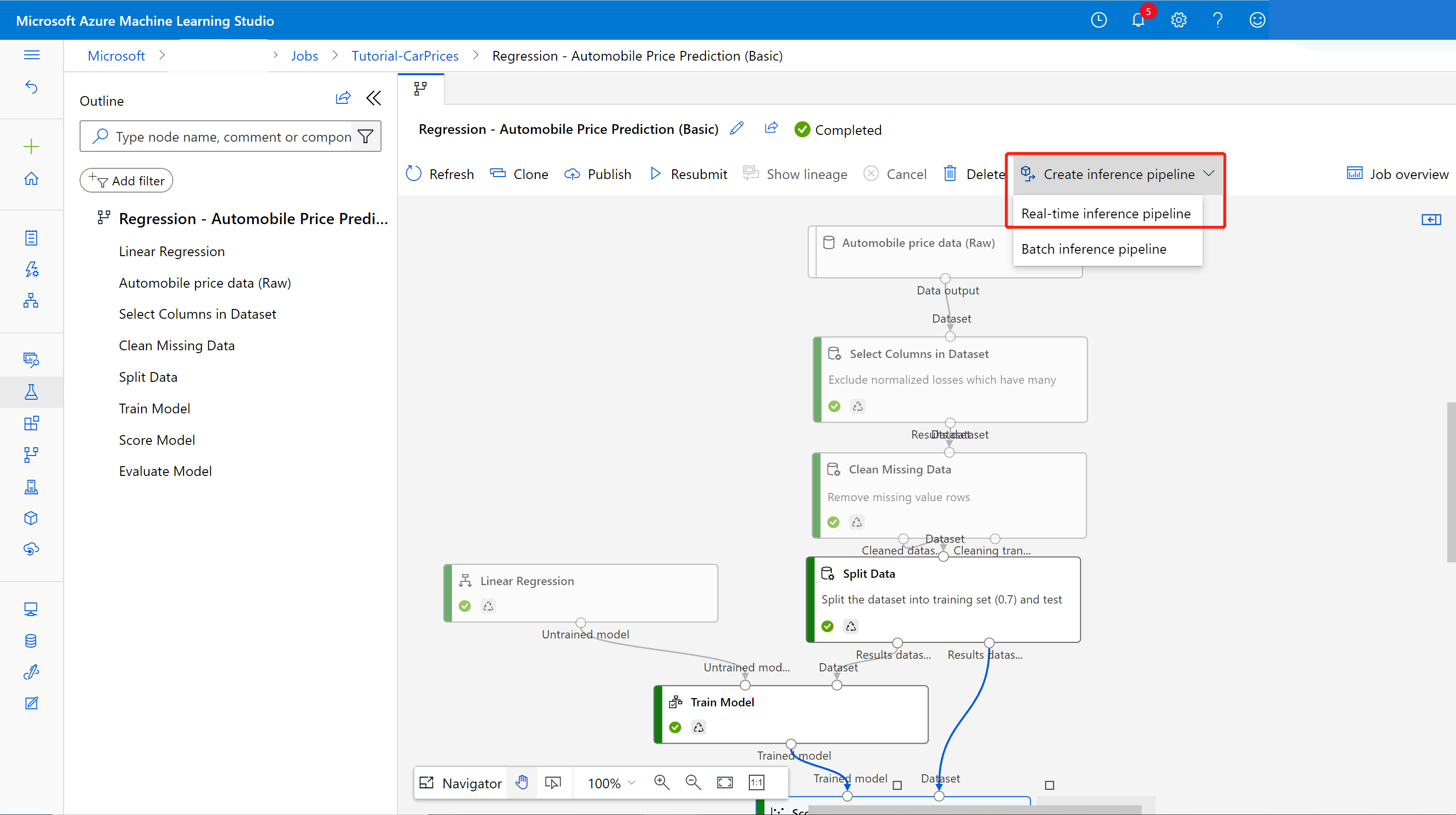
La nuova pipeline avrà ora un aspetto simile a questo:
Quando si seleziona Create inference pipeline accadono diverse cose:
- Il modello sottoposto a training viene archiviato come componente di Set di dati nel riquadro componenti. È possibile trovarlo in My Datasets (Set di dati personali).
- I componenti di training, come Training modello e Divisione dati, vengono rimossi.
- Il modello con training salvato viene aggiunto nuovamente alla pipeline.
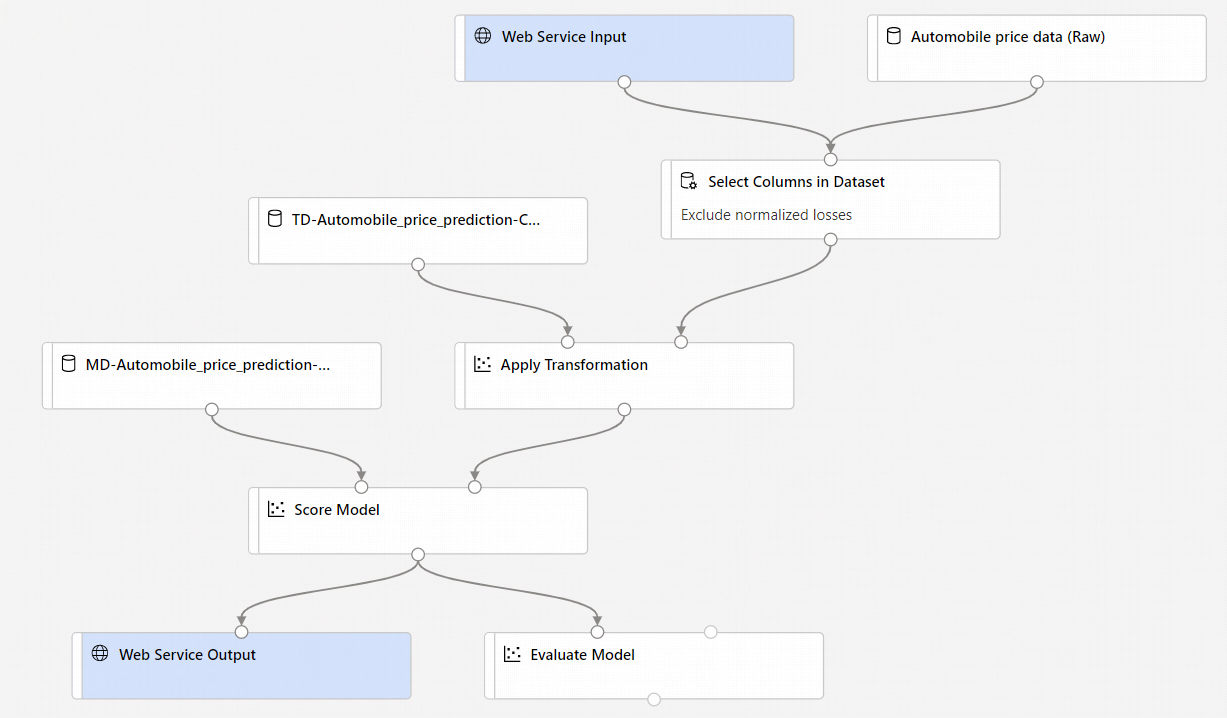
- Vengono aggiunti i componenti Input servizio Web e Output servizio Web. Tali componenti mostrano il punto in cui i dati dell'utente vengono immessi nella pipeline e il punto in cui vengono restituiti.
Nota
Per impostazione predefinita, l'input del servizio Web prevede lo stesso schema di dati dei dati di output del componente che si connette alla stessa porta downstream. In questo esempio, Input del servizio Web e Dati prezzi automobile (non elaborati) si connettono allo stesso componente downstream, pertanto Input del servizio Web prevede lo stesso schema di dati di Dati prezzi automobile (non elaborati) e la colonna delle variabili di destinazione
priceè inclusa nello schema. Tuttavia, quando si assegnano punteggi ai dati non si conoscono i valori delle variabili di destinazione. In questo caso è possibile rimuovere la colonna della variabile di destinazione nella pipeline di inferenza usando il componente Seleziona colonne nel set di dati. Assicurarsi che l'output di Seleziona colonne nel set di dati che rimuove la colonna delle variabili di destinazione sia connesso alla stessa porta dell'output del componente Input del servizio Web.Selezionare Configura e invia e usare la stessa destinazione di calcolo e lo stesso esperimento usati nella prima parte.
Se si tratta del primo processo, potrebbero essere necessari fino a 20 minuti per completare l'esecuzione della pipeline. Le impostazioni di calcolo predefinite prevedono una dimensione minima del nodo pari a 0, il che significa che la finestra di progettazione deve allocare risorse dopo l'inattività. I processi di pipeline ripetuti richiedono meno tempo perché le risorse di calcolo sono già allocate. Inoltre, la finestra di progettazione usa i risultati memorizzati nella cache per ogni componente per migliorare ulteriormente l'efficienza.
Passare al dettaglio del processo di inferenza in tempo reale selezionando Dettagli processo nel riquadro sinistro.
Selezionare Distribuisci nella pagina dei dettagli del processo.
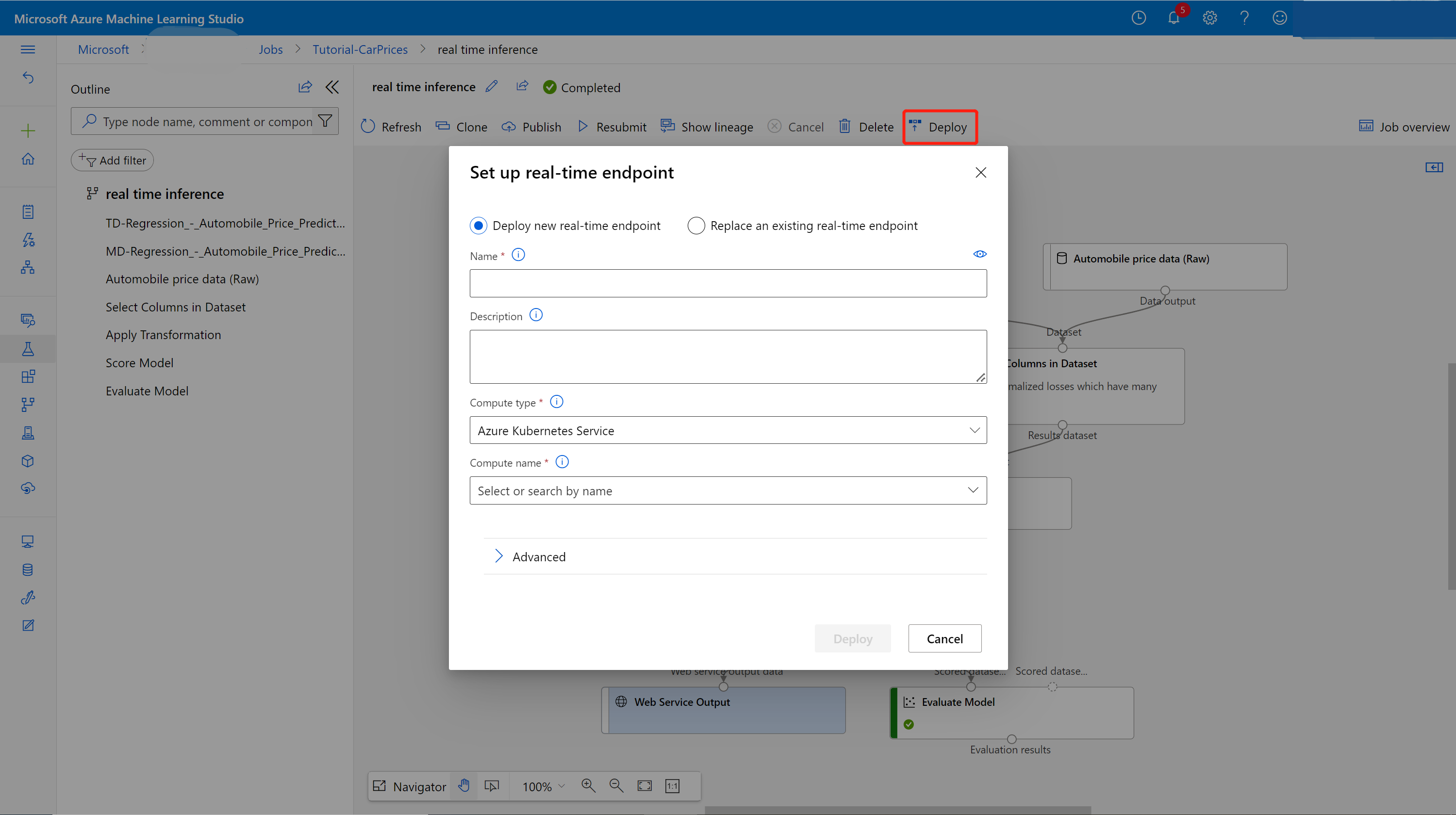


Creare un cluster di inferenza
Nella finestra di dialogo visualizzata è possibile selezionare uno dei cluster del servizio Azure Kubernetes esistenti in cui distribuire il modello. Se non si ha un cluster del servizio Azure Kubernetes, seguire questa procedura per crearne uno.
Passare alla pagina Calcolo selezionando Calcolo nella finestra di dialogo.
Nella barra multifunzione di spostamento, selezionare Cluster Kubernetes>+ Nuovo.
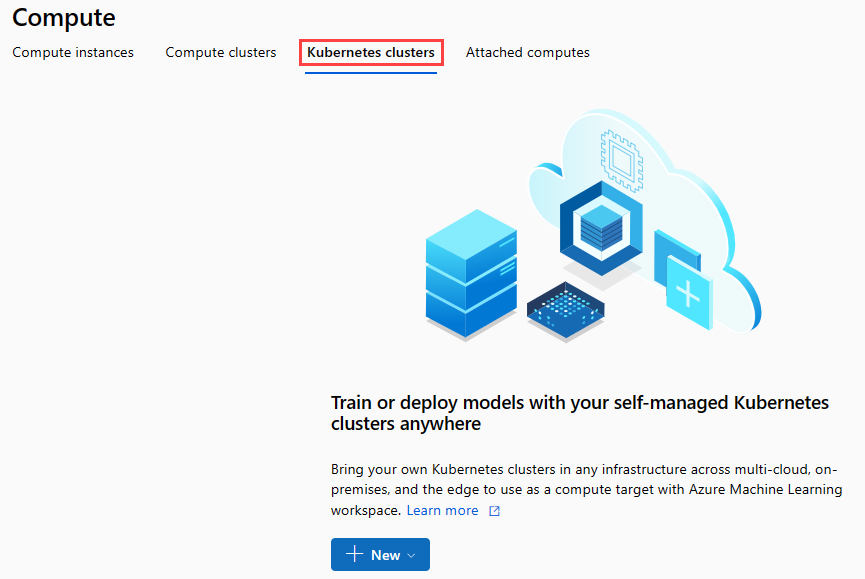
Nel riquadro del cluster di inferenza configurare un nuovo servizio Kubernetes.
Immettere aks-compute in Compute name (Nome del calcolo).
Selezionare un'area vicina disponibile per Region (Area).
Seleziona Crea.
Nota
La creazione di un nuovo servizio Azure Kubernetes richiede circa 15 minuti. È possibile controllare lo stato del provisioning nella pagina Inference Clusters (Cluster di inferenza)
Distribuire l'endpoint in tempo reale
Al termine del provisioning del servizio Azure Kubernetes, tornare alla pipeline di inferenza in tempo reale per completare la distribuzione.
Selezionare Deploy (Distribuisci) sopra il canvas.
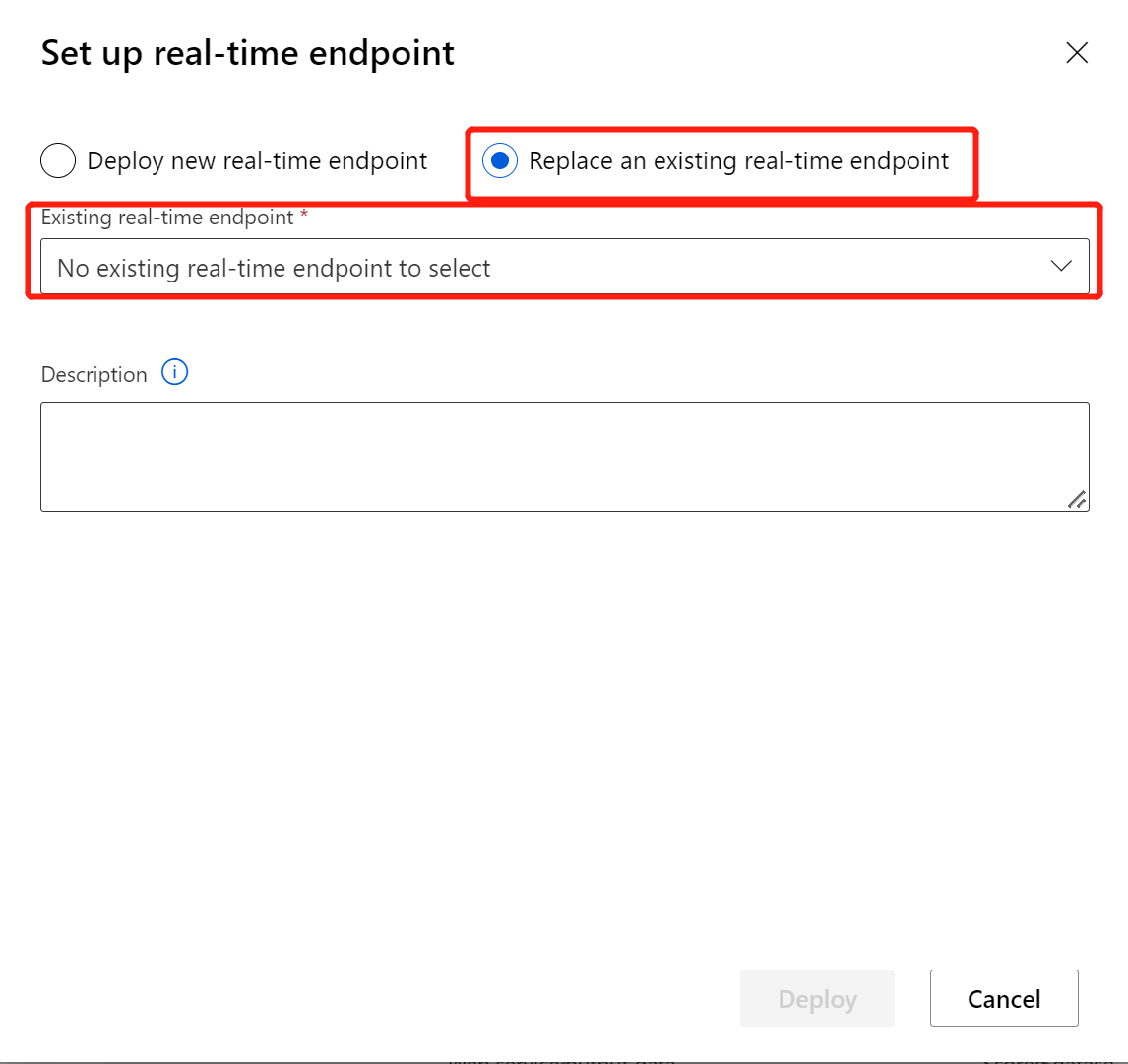
Selezionare Deploy new real-time endpoint (Distribuisci nuovo endpoint in tempo reale).
Selezionare il cluster del servizio Azure Kubernetes creato.
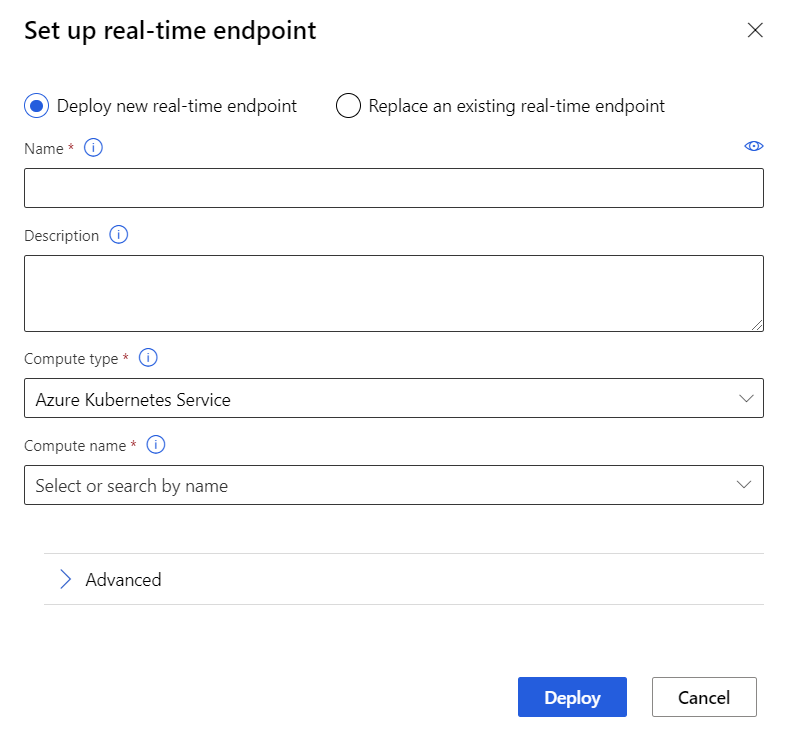
È anche possibile modificare l'impostazione Avanzata per l'endpoint in tempo reale.
Impostazione avanzata Descrizione Abilitare la diagnostica e la raccolta dati di Application Insights Questa consente ad Azure Application Insights di raccogliere dati dagli endpoint distribuiti.
Impostazione predefinita: falso.Timeout punteggio Timeout in millisecondi da applicare per l'assegnazione del punteggio alle chiamate al servizio Web.
Impostazione predefinita: 60000.Scalabilità automatica abilitata Consente la scalabilità automatica per il servizio Web.
Impostazione predefinita: true.Numero minimo di repliche Il numero minimo di contenitori da usare per la scalabilità automatica di questo servizio Web.
Impostazione predefinita: 1.Numero massimo di repliche Il numero massimo di contenitori da usare per la scalabilità automatica di questo servizio Web.
Impostazione predefinita: 10.Utilizzo di destinazione L'utilizzo di destinazione (come percentuale) che è necessario provare a mantenere per la scalabilità automatica di questo servizio Web.
Impostazione predefinita: 70.Periodo di aggiornamento Frequenza (in secondi) dei tentativi di ridimensionamento automatico del servizio Web.
Impostazione predefinita: 1.Capacità di riserva della CPU Il numero di core di CPU da allocare per questo servizio Web.
Impostazione predefinita: 0,1.Capacità di riserva della memoria La quantità di memoria (in GB) da allocare per questo servizio Web.
Impostazione predefinita: 0,5.Seleziona Distribuisci.
Al termine della distribuzione verrà visualizzata una notifica di esito positivo dal Centro notifiche. Potrebbe richiedere alcuni minuti.

Suggerimento
È anche possibile eseguire la distribuzione in Istanza di contenitore di Azure (ACI) se si seleziona Istanza di contenitore di Azure per Tipo di calcolo nella casella impostazioni dell'endpoint in tempo reale. L'istanza di contenitore di Azure viene usata per il test o lo sviluppo. Usare l'istanza di Azure Container per carichi di lavoro basati su CPU a scala ridotta che richiedono meno di 48 GB di RAM.
Testare l'endpoint in tempo reale
Una volta completata la distribuzione, è possibile visualizzare l'endpoint in tempo reale passando alla pagina Endpoints.
Nella pagina Endpoints selezionare l'endpoint appena distribuito.
Nella scheda Dettagli sono disponibili altre informazioni, tra cui l'URI REST, la definizione di Swagger, lo stato e i tag.
Nella scheda Utilizza è possibile trovare il codice di utilizzo di esempio, le chiavi di sicurezza e impostare i metodi di autenticazione.
Nella scheda Log di distribuzione sono disponibili i log di distribuzione dettagliati dell'endpoint in tempo reale.
Per testare l'endpoint, passare alla scheda Test. Da qui è possibile immettere i dati di test e selezionare Test per verificare l'output dell'endpoint.
Aggiornare l'endpoint in tempo reale
È possibile aggiornare l'endpoint online con il nuovo modello sottoposto a training nella finestra di progettazione. Nella pagina dei dettagli dell'endpoint online, è possibile trovare il processo precedente della pipeline di training e il processo di inferenza della pipeline.
È possibile trovare e modificare la bozza della pipeline di training nella home page della finestra di progettazione.
In alternativa, per continuare la modifica, è possibile aprire il collegamento al processo della pipeline di training e clonarlo in una nuova bozza di pipeline.

Dopo aver inviato la pipeline di training modificata, passare alla pagina dei dettagli del processo.
Al termine del processo, fare clic con il pulsante destro del mouse su Esegui il training del processo e selezionare Registra dati.
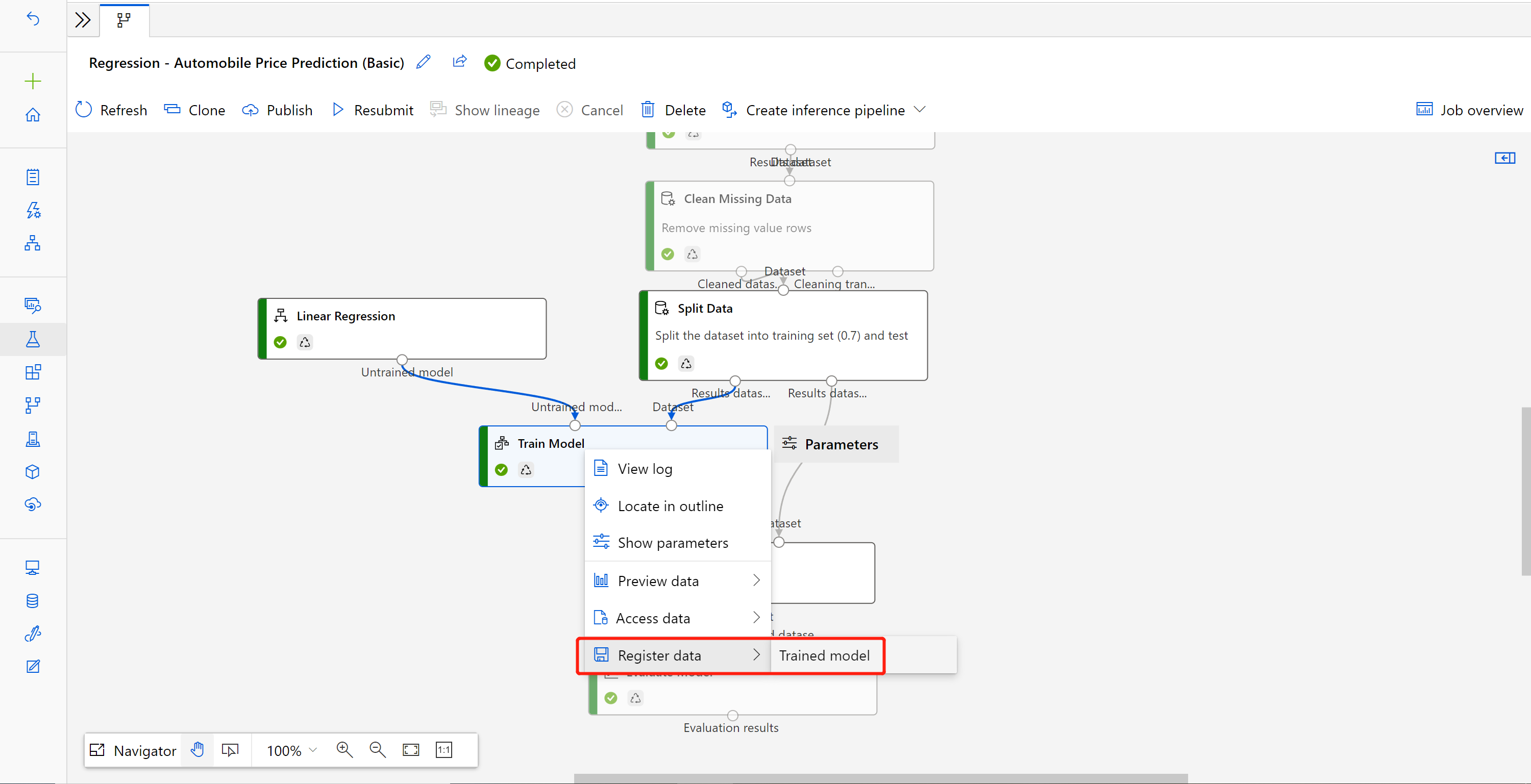
Immettere il nome e selezionare il tipo di File.
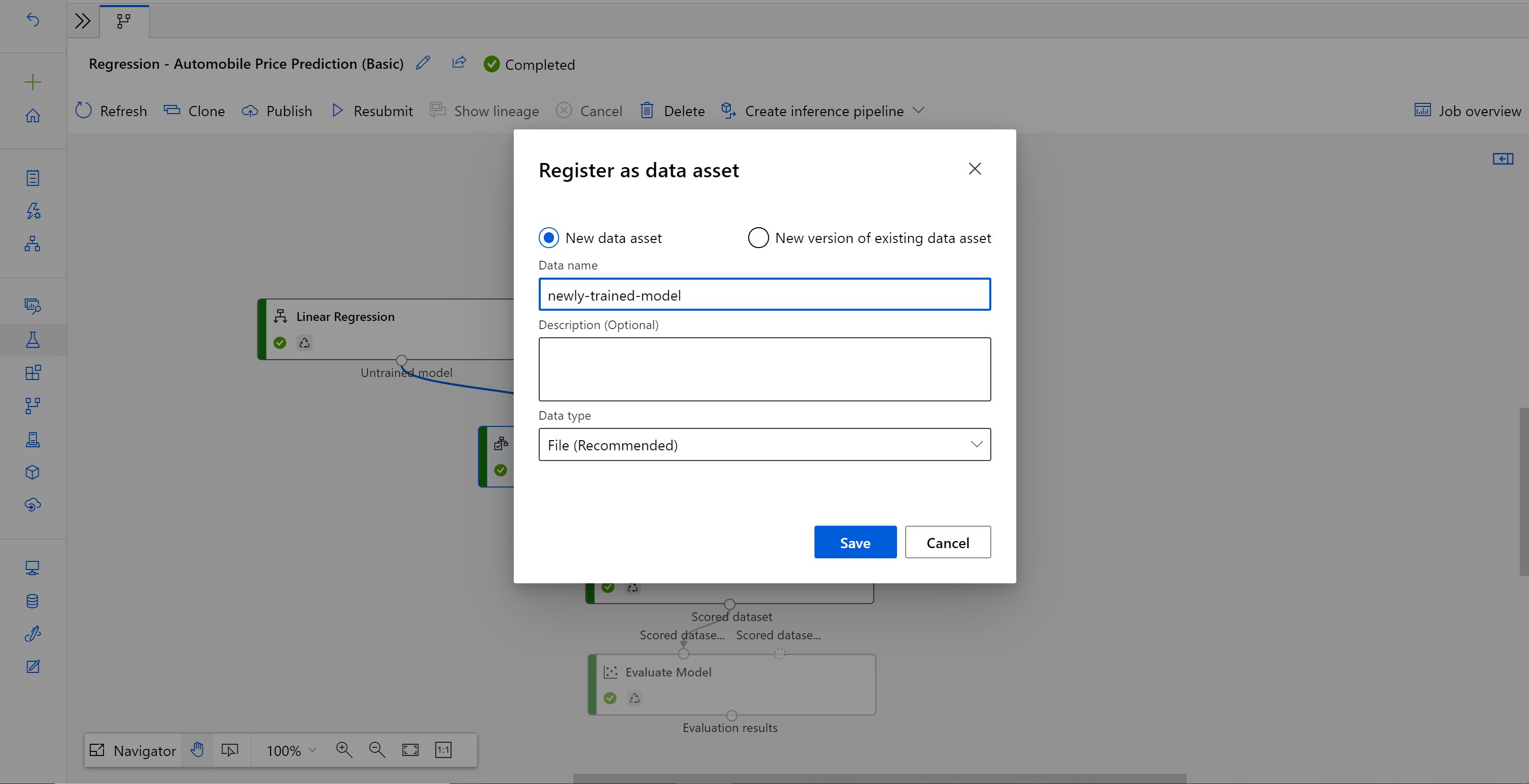
Dopo aver completato la registrazione del set di dati, aprire la bozza della pipeline di inferenza o clonare il processo della pipeline di inferenza precedente in una nuova bozza. Nella bozza della pipeline di inferenza sostituire il modello sottoposto a training precedente mostrato come nodo MD-XXXX connesso al componente Assegna punteggio al modello con il set di dati appena registrato.
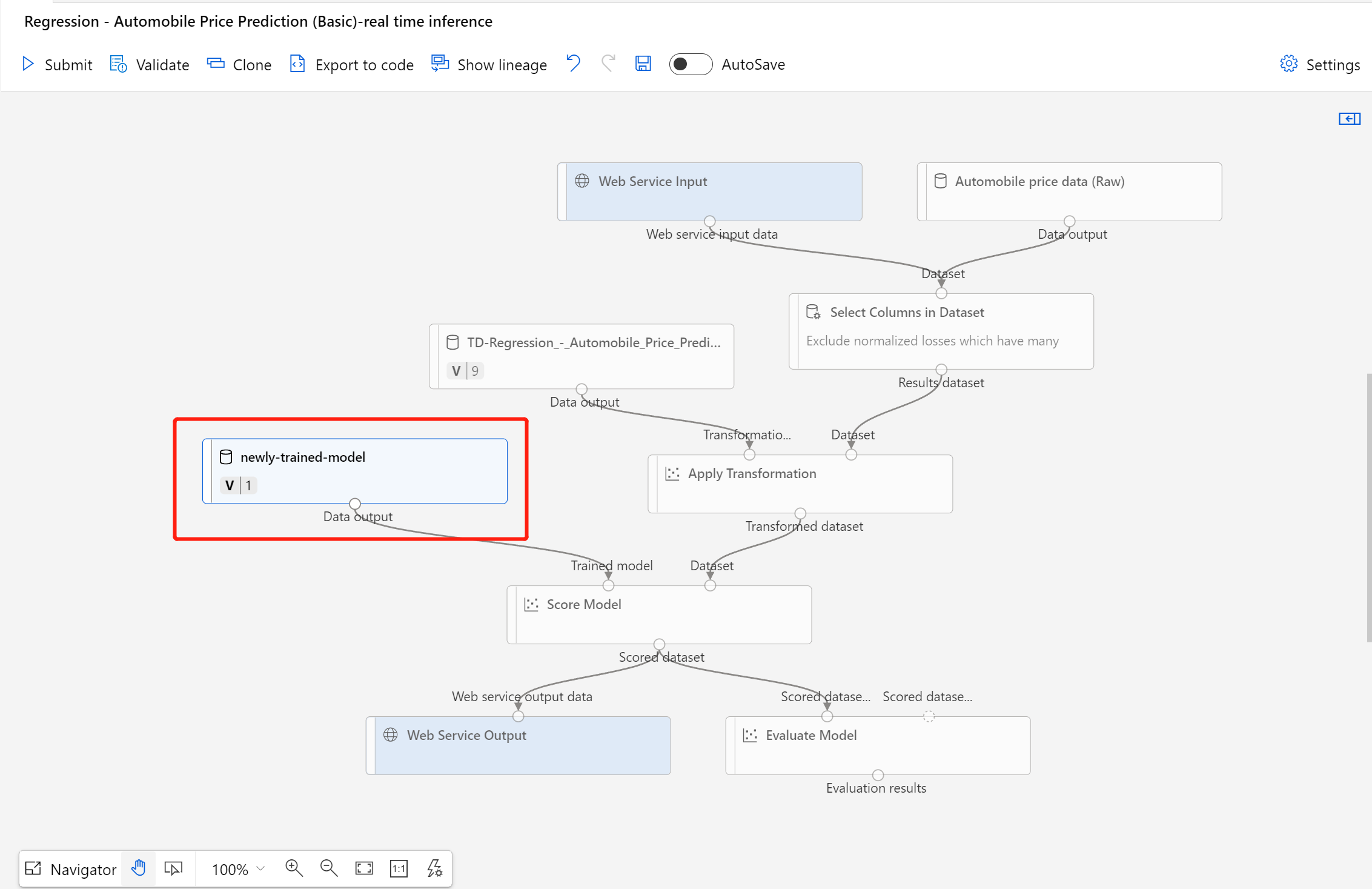
Se occorre aggiornare la parte di pre-elaborazione dei dati nella pipeline di training e aggiornarla nella pipeline di inferenza, l'elaborazione è simile alla procedura precedente.
È sufficiente registrare l'output della trasformazione del componente di trasformazione come set di dati.
Quindi, sostituire manualmente il componente TD- nella pipeline di inferenza con il set di dati registrato.
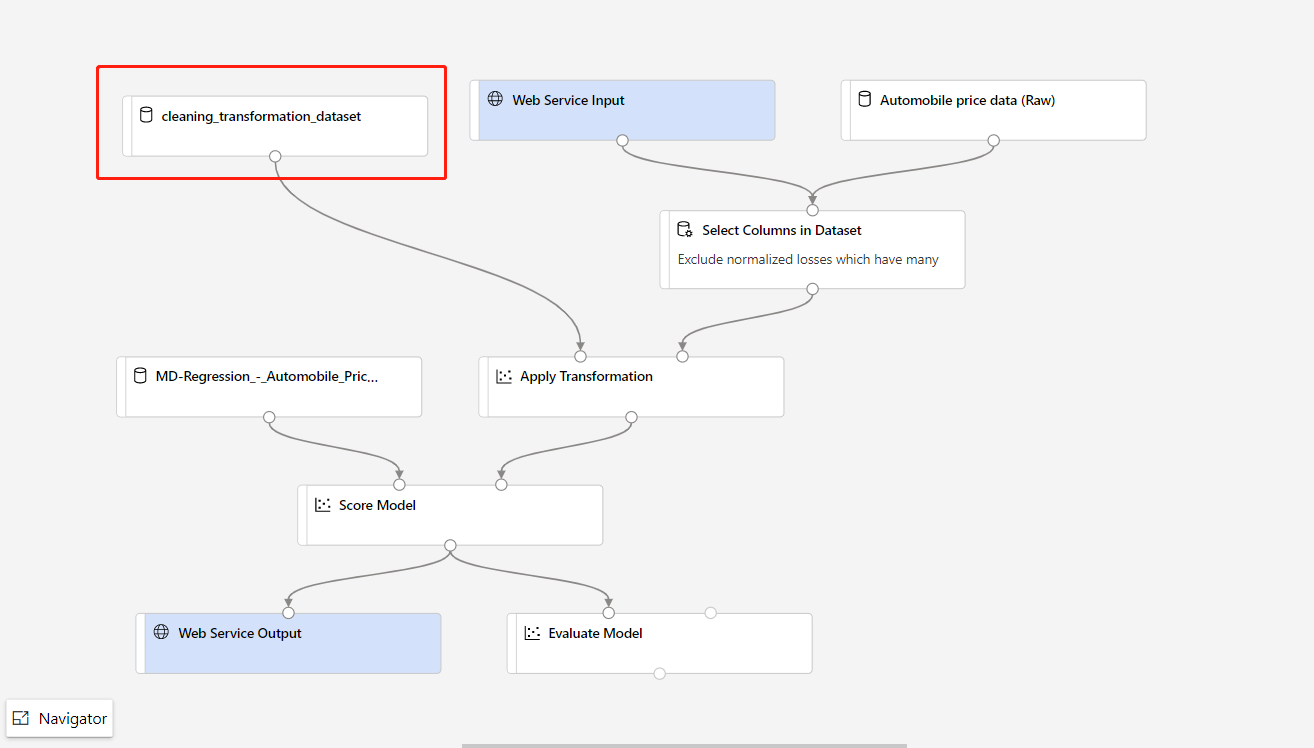
Dopo aver modificato la pipeline di inferenza con il modello o la trasformazione appena sottoposta a training, inviarla. Al termine del processo, distribuirla nell'endpoint online esistente e distribuito in precedenza.




Limiti
A causa della limitazione dell'accesso all'archivio dati, se la pipeline di inferenza contiene i componenti Importa dati o Esporta dati, questi verranno rimossi auto nella distribuzione all’endpoint in tempo reale.
Se nella pipeline di inferenza in tempo reale sono presenti set di dati e si vuole distribuirli in un endpoint in tempo reale, al momento questo flusso supporta solo set di dati registrati da un archivio dati BLOB. Se si vogliono usare set di dati di archivi dati di altro tipo, è possibile usare Seleziona colonna per connettersi al set di dati iniziale con l’impostazione di selezione di tutte le colonne, registrare gli output del set di dati di Seleziona colonna come file e quindi sostituire il set di dati iniziale nella pipeline di inferenza in tempo reale con il set di dati appena registrato.
Se il grafico di inferenza contiene il componente Immetti dati manualmente che non è connesso alla stessa porta del componente Input del servizio Web, il componente Immetti dati manualmente non viene eseguito durante l'elaborazione delle chiamate HTTP. Una soluzione alternativa consiste nel registrare gli output del componente Immetti dati manualmente come set di dati, quindi sostituire il componente Immetti dati manualmente con il set di dati registro nella bozza della pipeline di inferenza.
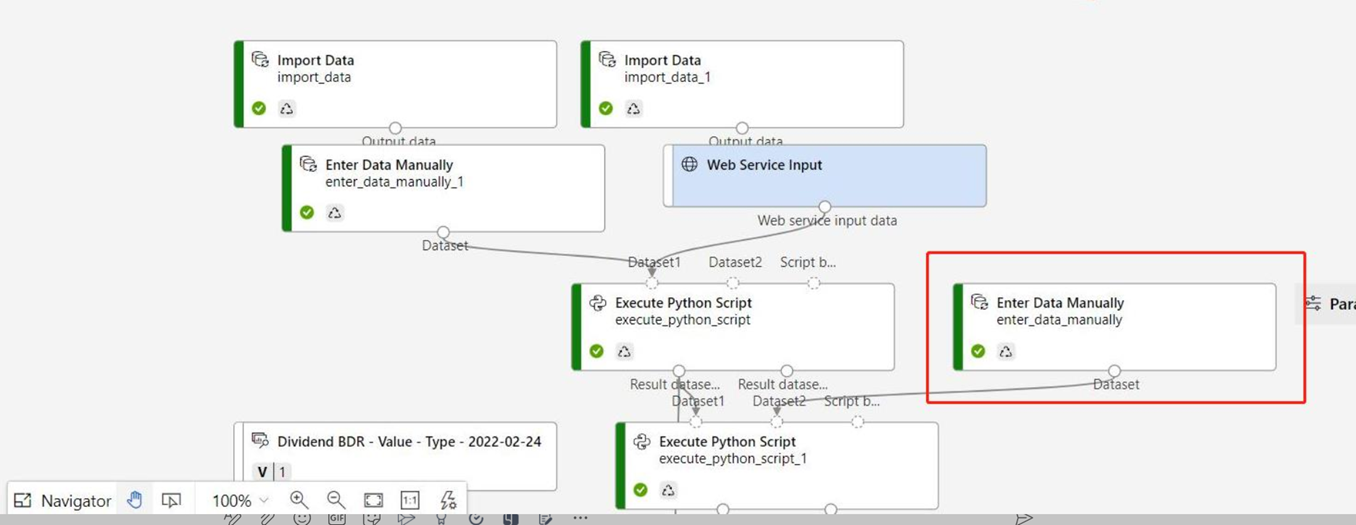

Pulire le risorse
Importante
È possibile usare le risorse create come prerequisiti per altre esercitazioni e procedure dettagliate relative ad Azure Machine Learning.
Eliminare tutto
Se non si prevede di usare le risorse create, eliminare l'intero gruppo di risorse per evitare addebiti.
Nel portale di Azure, selezionare Gruppi di risorse nella parte sinistra della finestra.
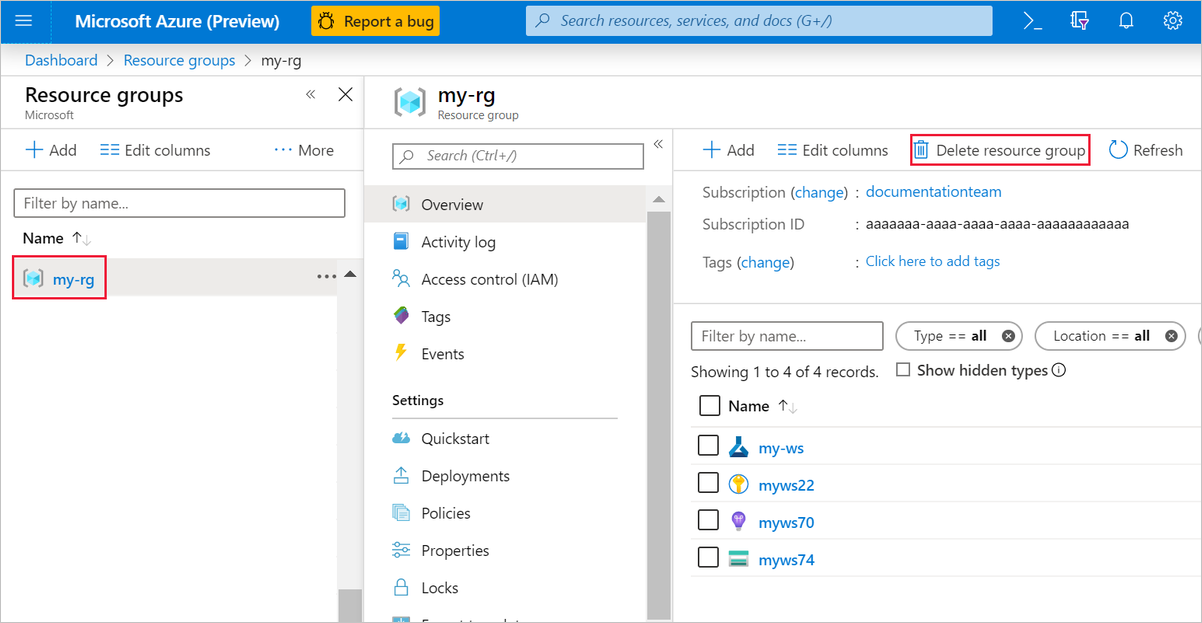
Nell'elenco selezionare il gruppo di risorse creato.
Selezionare Elimina gruppo di risorse.
Se si elimina il gruppo di risorse, vengono eliminate anche tutte le risorse create nella finestra di progettazione.
Eliminare singole risorse
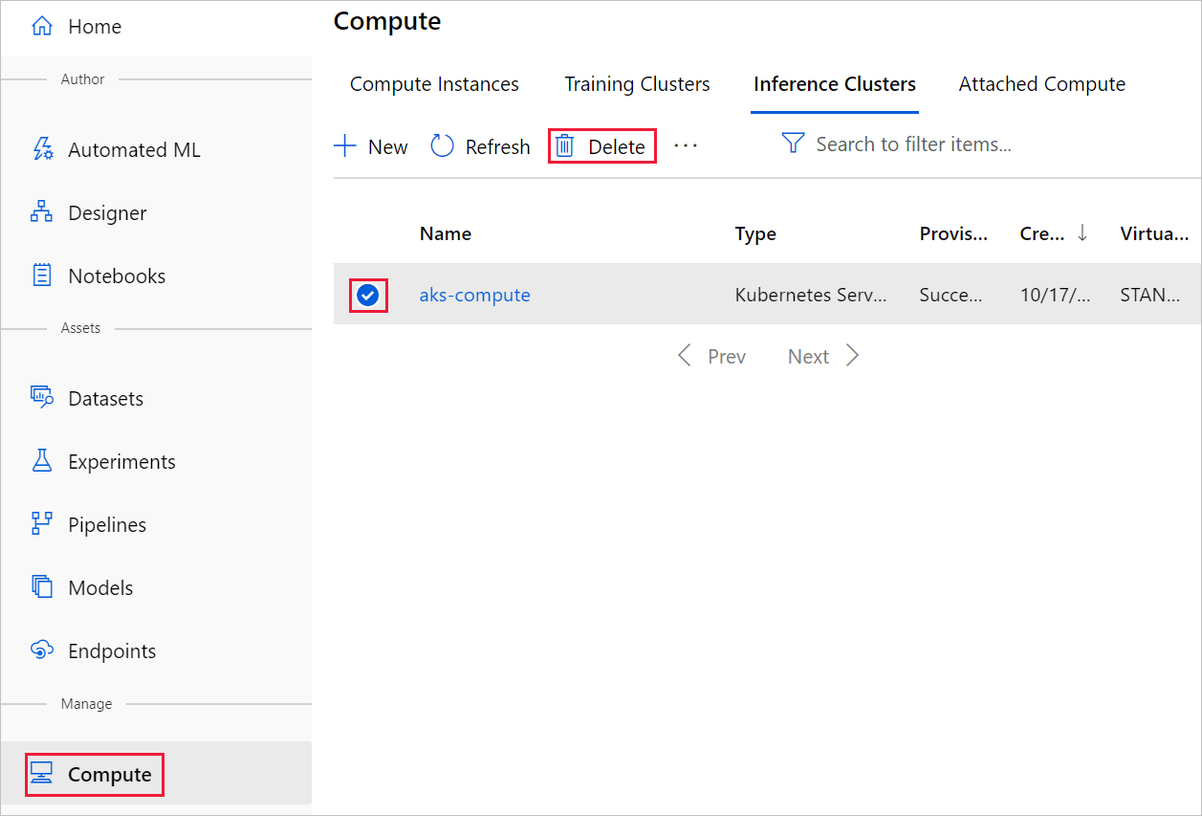
Nella finestra di progettazione in cui è stato creato l'esperimento eliminare le singole risorse selezionandole e quindi selezionando il pulsante Elimina.
La destinazione di calcolo creata qui viene ridimensionata automaticamente a zero nodi quando non viene usata, Questa azione viene intrapresa per ridurre al minimo gli addebiti. Se si vuole eliminare la destinazione di calcolo, eseguire le operazioni seguenti:
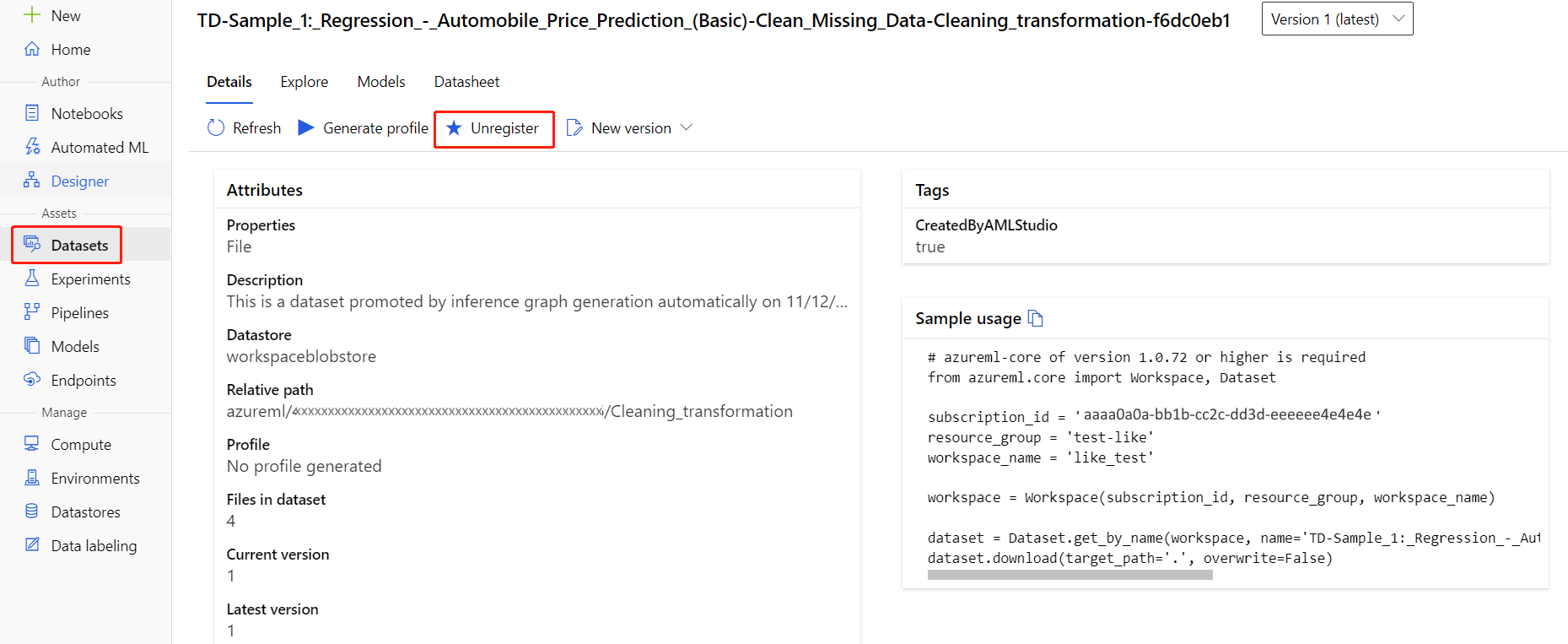
La registrazione dei set di dati nell'area di lavoro può essere annullata selezionando ogni set di dati e quindi Annulla registrazione.
Per eliminare un set di dati, passare all'account di archiviazione tramite il portale di Azure o Azure Storage Explorer ed eliminare manualmente tali asset.
Contenuto correlato
In questa esercitazione si è appreso come creare, distribuire e usare un modello di Machine Learning nella finestra di progettazione. Per informazioni su come usare la finestra di progettazione, vedere gli articoli seguenti: