Panoramica della continuità aziendale con Database di Azure per PostgreSQL - Server flessibile
SI APPLICA A:  Database di Azure per PostgreSQL - Server flessibile
Database di Azure per PostgreSQL - Server flessibile
Continuità del business nel server flessibile di Database di Azure per PostgreSQL fa riferimento a meccanismi, criteri e procedure che consentono all'azienda di continuare a operare in caso di interruzioni, in particolare per quanto riguarda la propria infrastruttura di calcolo. Nella maggior parte dei casi, il server flessibile di Database di Azure per PostgreSQL gestisce eventi di interruzione che possono verificarsi nell'ambiente cloud e mantiene in esecuzione le applicazioni e i processi aziendali. Esistono tuttavia alcuni eventi che non possono essere gestiti automaticamente, ad esempio:
- Un utente elimina o aggiorna accidentalmente una riga in una tabella.
- Il terremoto causa un'interruzione dell'alimentazione e disabilita temporaneamente una zona di disponibilità o un'area.
- Applicazione di patch al database necessaria per risolvere un problema di sicurezza o di bug.
Il server flessibile di Database di Azure per PostgreSQL offre funzionalità che proteggono i dati e riduce i tempi di inattività per i database cruciali durante gli eventi di inattività pianificati e non. Basato sull'infrastruttura di Azure che offre resilienza e disponibilità affidabili, il server flessibile di Database di Azure per PostgreSQL fornisce funzionalità di continuità aziendale con un'ulteriore protezione dagli errori, soddisfa i requisiti di tempo di ripristino e riduce l'esposizione alla perdita di dati. Quando si progettano le applicazioni, è consigliabile considerare la tolleranza al tempo di inattività, ovvero l'obiettivo del tempo di ripristino (RTO) e l'esposizione alla perdita di dati, ovvero l'obiettivo del punto di ripristino (RPO). Ad esempio, il database business critical richiede tempi di attività più rigorosi rispetto a un database di test.
La tabella seguente illustra le funzionalità offerte dal server flessibile di Database di Azure per PostgreSQL.
| Funzionalità | Descrizione | Considerazioni |
|---|---|---|
| Backup automatici | Il server flessibile di Database di Azure per PostgreSQL esegue automaticamente i backup quotidiani dei file di database ed esegue continuamente il backup dei log delle transazioni. I backup possono essere conservati da 7 fino a 35 giorni. Sarà possibile ripristinare il server di database in qualsiasi momento all'interno del periodo di conservazione dei backup. L'obiettivo RTO dipende dalle dimensioni dei dati da ripristinare e dal tempo necessario per eseguire il ripristino del log. Può andare da pochi minuti fino a 12 ore. Per altre informazioni, vedere Concetti - Backup e ripristino. | I dati di backup rimangono all'interno dell'area. |
| Disponibilità elevata di ridondanza della zona | Il server flessibile di Database di Azure per PostgreSQL può essere distribuito con una configurazione a disponibilità elevata con ridondanza della zona in cui i server primari e di standby vengono distribuiti in due diverse zone di disponibilità all'interno di un'area. Questa configurazione a disponibilità elevata protegge i database da errori a livello di zona e consente anche di ridurre i tempi di inattività delle applicazioni durante gli eventi di tempo di inattività pianificati e non pianificati. I dati del server primario vengono replicati in modo sincrono nella replica di standby. In caso di interruzione del server primario, il server viene sottoposto automaticamente a failover nella replica di standby. L'RTO nella maggior parte dei casi dovrebbe essere inferiore a 120 secondi. Il valore di RPO dovrà essere uguale a zero (nessuna perdita di dati). Per altre informazioni, vedere [Concetti - Disponibilità elevata]/azure/reliability/reliability-postgresql-flexible-server. | Supportato nei livelli di calcolo per utilizzo generico e ottimizzato per la memoria. Disponibile solo nelle aree in cui sono disponibili più zone. |
| Disponibilità elevata nella stessa zona | Il server flessibile di Database di Azure per PostgreSQL può essere distribuito con una configurazione a disponibilità elevata nella stessa zona in cui i server primari e di standby vengono distribuiti nella stessa zona di disponibilità all'interno di un'area. Questa configurazione a disponibilità elevata protegge i database da errori a livello di nodo e consente anche di ridurre i tempi di inattività delle applicazioni durante gli eventi di tempo di inattività pianificati e non pianificati. I dati del server primario vengono replicati in modo sincrono nella replica di standby. In caso di interruzione del server primario, il server viene sottoposto automaticamente a failover nella replica di standby. L'RTO nella maggior parte dei casi dovrebbe essere inferiore a 120 secondi. Il valore di RPO dovrà essere uguale a zero (nessuna perdita di dati). Per altre informazioni, vedere [Concetti - Disponibilità elevata]/azure/reliability/reliability-postgresql-flexible-server. | Supportato nei livelli di calcolo per utilizzo generico e ottimizzato per la memoria. |
| Dischi gestiti Premium | I file di database vengono archiviati in una risorsa di archiviazione durevole gestita in modo affidabile. In questo modo si garantisce la ridondanza dei dati con tre copie di replica archiviate all'interno di una zona di disponibilità con funzionalità di ripristino automatico dei dati. Per altre informazioni, vedere la Documentazione di Managed Disks. | Dati archiviati all'interno di una zona di disponibilità. |
| Backup con ridondanza della zona | I backup del server flessibile di Database di Azure per PostgreSQL vengono archiviati automaticamente e in modo sicuro in un'archiviazione con ridondanza della zona all'interno di un'area, se l'area supporta le zone di disponibilità. Durante un errore a livello di zona in cui è stato effettuato il provisioning del server, se il server non è configurato con ridondanza della zona, è comunque possibile ripristinare il database usando il punto di ripristino più recente in un'altra zona. Per altre informazioni, vedere Concetti - Backup e ripristino. | Applicabile solo nelle aree in cui sono disponibili più zone. |
| Backup con ridondanza geografica | I backup dei server flessibili di Database di Azure per PostgreSQL vengono copiati in un'area remota. Ciò consente il ripristino di emergenza nel caso in cui l'area del server primario sia inattiva. | Questa funzionalità è attualmente abilitata nelle aree selezionate. Sono necessari un RTO più lungo e un RPO superiore, a seconda delle dimensioni dei dati da ripristinare e dalla quantità di ripristino da effettuare. |
| Replica in lettura | Le repliche in lettura tra aree possono essere distribuite per proteggere i database da errori a livello di area. Le repliche in lettura vengono aggiornate in modo asincrono usando la tecnologia di replica fisica di PostgreSQL e possono causare un ritardo nel database primario. Per altre informazioni, vedere Concetti - Repliche di lettura. | Supportato nei livelli di calcolo per utilizzo generico e ottimizzato per la memoria. |
La tabella seguente confronta RTO e RPO in uno scenario tipico di carico di lavoro:
| Funzionalità | Possibilità di burst | Utilizzo generico | Ottimizzato per la memoria |
|---|---|---|---|
| Ripristino temporizzato dal backup | Qualsiasi punto di ripristino compreso nel periodo di conservazione RTO - Varie RPO < 5 min |
Qualsiasi punto di ripristino compreso nel periodo di conservazione RTO - Varie RPO < 5 min |
Qualsiasi punto di ripristino compreso nel periodo di conservazione RTO - Varie RPO < 5 min |
| Ripristino geografico dai backup con replica geografica | RTO - Varie RPO < 1 h |
RTO - Varie RPO < 1 h |
RTO - Varie RPO < 1 h |
| Repliche in lettura | RTO - Minuti* RPO < 5 min* |
RTO - Minuti* RPO < 5 min* |
RTO - Minuti* RPO < 5 min* |
* RTO e RPO possono essere molto più elevati in alcuni casi a seconda di vari fattori, tra cui la latenza tra siti, la quantità di dati da trasmettere e un carico di lavoro di scrittura del database primario.
Eventi di inattività pianificati
Di seguito vengono forniti alcuni scenari di manutenzione pianificata. Questi eventi in genere comportano fino a pochi minuti di tempo di inattività, senza perdita di dati.
| Scenario | Processo |
|---|---|
| Scalabilità di calcolo (avviata dall'utente) | Durante l'operazione di ridimensionamento del calcolo, i checkpoint attivi sono autorizzati a completare, le connessioni client vengono svuotate, tutte le transazioni non sottoposte a commit vengono annullate, l'archiviazione viene scollegata e quindi viene arrestata. Viene effettuato il provisioning di una nuova istanza del server flessibile di Database di Azure per PostgreSQL con lo stesso nome del server di database con la configurazione di calcolo ridimensionata. Lo spazio di archiviazione viene quindi collegato al nuovo server e il database viene avviato ed esegue il ripristino, se necessario, prima di accettare le connessioni client. |
| Dimensionamento dell'archiviazione (avviato dall'utente) | Quando viene avviata un'operazione di aumento delle risorse di archiviazione, i checkpoint attivi sono autorizzati a completare, le connessioni client vengono svuotate e tutte le transazioni di cui non è stato eseguito il commit vengono annullate. Dopodiché, il server viene arrestato. Lo spazio di archiviazione viene ridimensionato in base alle dimensioni desiderate e quindi collegato al nuovo server. Se necessario, viene eseguito un ripristino prima di accettare le connessioni client. Si noti che il dimensionamento delle dimensioni di archiviazione non è supportato. |
| Nuova distribuzione software (avviata da Azure) | Le nuove funzionalità di implementazione o correzione di bug vengono eseguite automaticamente come parte della manutenzione pianificata del servizio ed è possibile programmarne la frequenza. Per altre informazioni, vedere il portale. |
| Aggiornamenti della versione secondaria (avviati da Azure) | Database di Azure per PostgreSQL applica automaticamente patch di server di database alla versione secondaria determinata da Azure. Ciò si verifica come parte della manutenzione pianificata del servizio. Il server di database viene riavviato automaticamente con la nuova versione secondaria. Per altre informazioni, vedere la documentazione. È anche possibile controllare il portale. |
Quando l'istanza del server flessibile di Database di Azure per PostgreSQL è configurata con disponibilità elevata, il servizio esegue prima il ridimensionamento e le operazioni di manutenzione nel server di standby. Per altre informazioni, vedere [Concetti - Disponibilità elevata]/azure/reliability/reliability-postgresql-flexible-server.
Mitigazione dei tempi di inattività non pianificati
Tempi di inattività non pianificati possono verificarsi a causa di interruzioni impreviste, ad esempio errori hardware sottostanti, problemi di rete e bug software. Se il server di database configurato con disponibilità elevata diventa inattivo in modo imprevisto, la replica di standby viene attivata e i client possono riprendere le operazioni. Se non è configurato con disponibilità elevata e se il tentativo di riavvio non riesce, viene eseguito automaticamente il provisioning di un nuovo server di database. Anche se non è possibile evitare tempi di inattività non pianificati, il server flessibile di Database di Azure per PostgreSQL consente di ridurre i tempi di inattività eseguendo automaticamente operazioni di ripristino senza richiedere l'intervento umano.
Anche se ci impegniamo continuamente a garantire la disponibilità elevata, in alcuni casi il server flessibile di Database di Azure per PostgreSQL causa un'interruzione che porta all'indisponibilità dei database e quindi influisce sull'applicazione. Quando il nostro monitoraggio del servizio rileva problemi che causano errori di connettività, errori o problemi di prestazioni, il servizio dichiara automaticamente un'interruzione per mantenere l'utente informato.
Interruzione del servizio
In caso di interruzione del server flessibile di Database di Azure per PostgreSQL, è possibile visualizzare altri dettagli relativi all'interruzione nelle posizioni seguenti:
- Banner del portale di Azure: se la sottoscrizione è identificata come interessata, verrà visualizzato un avviso di interruzione del servizio nelle Notifiche del portale di Azure.
- Guida e supporto o Supporto e risoluzione dei problemi: quando si crea un ticket di supporto da Guida e supporto o Supporto e risoluzione dei problemi, verranno fornite informazioni su eventuali problemi che influiscono sulle risorse. Selezionare Visualizza dettagli dell'interruzione per altre informazioni e un riepilogo dell'impatto. Nella pagina Nuova richiesta di supporto verrà visualizzato anche un avviso.

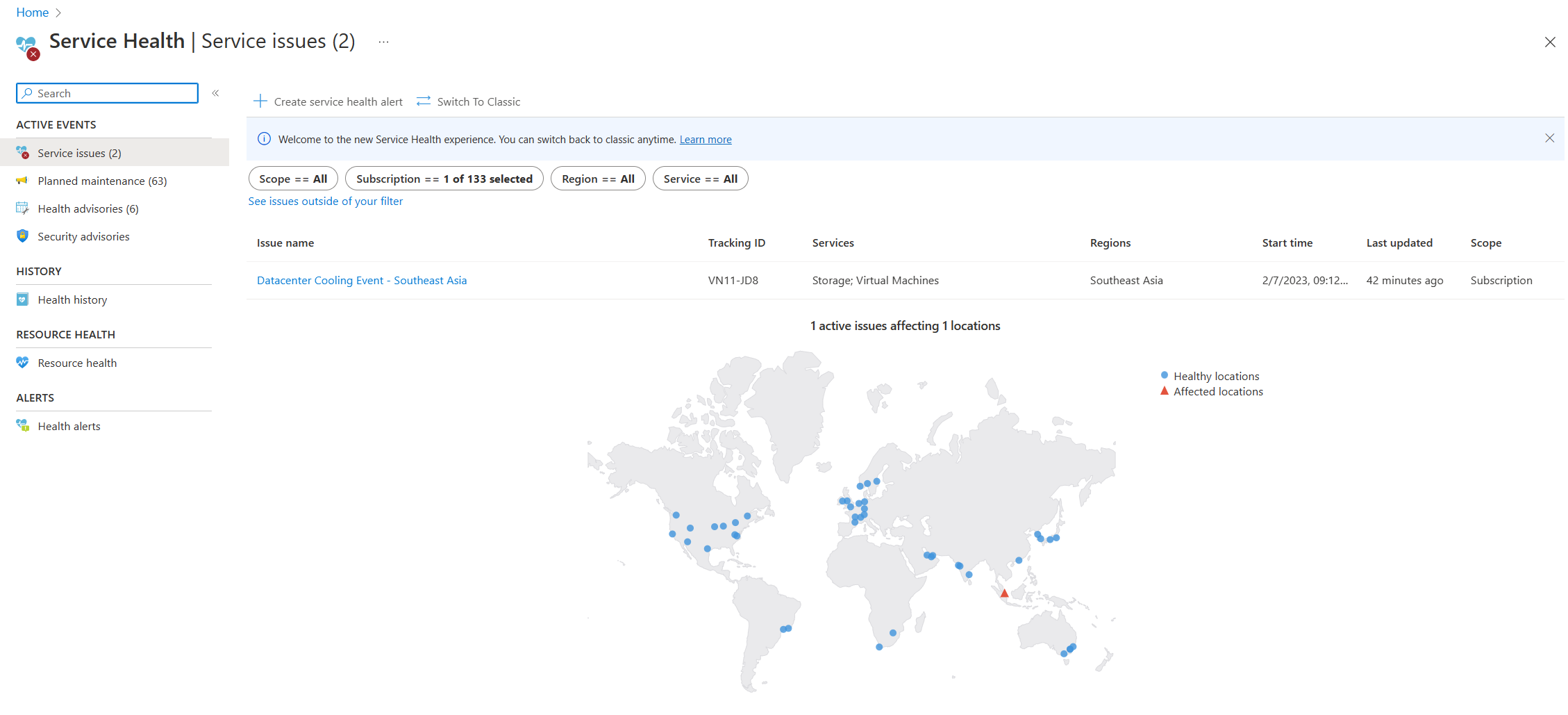
- Guida del servizio: la pagina Integrità dei servizi nel portale di Azure contiene informazioni sullo stato del data center di Azure a livello globale. Cercare "integrità dei servizi" nella barra di ricerca nel portale di Azure, quindi visualizzare i problemi del servizio nella categoria Eventi attivi. È anche possibile visualizzare l'integrità delle singole risorse nella pagina Integrità risorse di qualsiasi risorsa nel menu ?. Di seguito è riportato uno screenshot di esempio della pagina Integrità dei servizi con informazioni su un problema di servizio attivo in Asia sud-orientale.
- Notifica tramite posta elettronica: se sono stati configurati avvisi, si riceverà una notifica tramite posta elettronica quando un'interruzione del servizio influisce sulla sottoscrizione e sulla risorsa. Le e-mail provengono da "azure-noreply@microsoft.com". Il corpo dell'e-mail inizia con "L'avviso del log attività ... è stato attivato da un problema di servizio per la sottoscrizione di Azure...". Per maggiori informazioni sugli avvisi di integrità dei servizi, vedere Ricevere avvisi del log attività sulle notifiche del servizio di Azure tramite portale di Azure.
Importante
Come suggerisce il nome, gli spazi di tabella temporanei in PostgreSQL vengono usati per gli oggetti temporanei, nonché per altre operazioni di database interne, ad esempio l'ordinamento. Non è pertanto consigliabile creare oggetti schema utente nello spazio tabelle temporaneo, perché non si garantisce la durabilità di tali oggetti dopo il riavvio del server, i failover a disponibilità elevata e così via.
Tempi di inattività non pianificati: scenari di errore e ripristino del servizio
Di seguito sono riportati alcuni scenari di errore non pianificati e il processo di ripristino.
| Scenario | Processo di ripristino [Server configurati senza disponibilità elevata con ridondanza della zona] |
Processo di ripristino [Server configurati con disponibilità elevata e ridondanza della zona] |
|---|---|---|
| Errore del server di database | Se il server di database è inattivo, Azure tenterà di riavviarlo. In caso di errore, il server di database verrà riavviato in un altro nodo fisico. Il tempo di ripristino (RTO) dipende da vari fattori, tra cui l'attività al momento dell'errore, ad esempio transazioni di grandi dimensioni, e il volume di ripristino da eseguire durante il processo di avvio del server di database. Le applicazioni che usano database PostgreSQL devono essere compilate in modo da rilevare e ripetere le connessioni eliminate e le transazioni non riuscite. |
Se viene rilevato un errore del server di database, il server viene sottoposto a failover nel server di standby, riducendo così il tempo di inattività. Per altre informazioni, vedere [pagina Concetti a disponibilità elevata]/azure/reliability/reliability-postgresql-flexible-server. L'obiettivo RTO dovrebbe essere di 60-120 secondi, con una perdita di dati pari a zero. |
| Errore di archiviazione | Le applicazioni non riscontrano alcun impatto da problemi correlati all'archiviazione, ad esempio un errore del disco o un danneggiamento del blocco fisico. Poiché i dati vengono archiviati in tre copie, la copia dei dati viene servita dall'archiviazione sopravvissuta. Il blocco di dati danneggiato viene ripristinato automaticamente e viene creata automaticamente una nuova copia dei dati. | Per eventuali errori rari e non ripristinabili, ad esempio se non è possibile accedere all'intera risorsa di archiviazione, l'istanza del server flessibile di Database di Azure per PostgreSQL viene sottoposta a failover nella replica di standby per ridurre il tempo di inattività. Per altre informazioni, vedere [pagina Concetti a disponibilità elevata]/azure/reliability/reliability-postgresql-flexible-server. |
| Errori logici/utente | Per eseguire il ripristino da errori utente, ad esempio tabelle eliminate accidentalmente o dati aggiornati in modo non corretto, è necessario eseguire un ripristino temporizzato (PITR). Durante l'esecuzione dell'operazione di ripristino, è necessario specificare il punto di ripristino personalizzato, ovvero l'ora prima dell'errore. Se si desidera ripristinare solo un subset di database o tabelle specifiche anziché tutti i database nel server di database, è possibile ripristinare il server di database in una nuova istanza, esportare le tabelle tramite pg_dump e quindi usare pg_restore per ripristinare tali tabelle nel database. |
Questi errori utente non sono controbilanciati dalla disponibilità elevata perché tutte le modifiche vengono replicate in modo sincrono nella replica di standby. È necessario eseguire il ripristino temporizzato per tali errori. |
| Errore nella zona di disponibilità | Per eseguire il ripristino da un errore a livello di zona, è possibile eseguire il ripristino temporizzato usando il backup e scegliendo un punto di ripristino personalizzato con l'ora più recente per ripristinare i dati più recenti. Una nuova istanza del server flessibile di Database di Azure per PostgreSQL viene distribuita in un'altra zona non interessata. Il tempo necessario per il ripristino dipende dal backup precedente e dal volume dei log delle transazioni da ripristinare. | Il server flessibile di Database di Azure per PostgreSQL viene sottoposto automaticamente a failover nel server di standby entro 60-120 secondi senza perdita di dati. Per altre informazioni, vedere [pagina Concetti a disponibilità elevata]/azure/reliability/reliability-postgresql-flexible-server. |
| Errore dell'area | Se il server è configurato con il backup con ridondanza geografica, è possibile eseguire il ripristino geografico nell'area abbinata. Verranno eseguiti il provisioning e il ripristino di un nuovo server agli ultimi dati disponibili copiati in questa area. È anche possibile usare repliche in lettura tra aree. In caso di errore dell'area, è possibile eseguire un'operazione di ripristino di emergenza promuovendo la replica in lettura come server scrivibile in lettura autonomo. È previsto che l'RPO arrivi a 5 minuti (possibile perdita di dati) tranne nel caso di un errore a livello di area grave, dove l'RPO può essere vicino al ritardo della replica al momento dell'errore. |
Stesso processo. |
Configurare il database dopo il ripristino da un errore a livello di area
- Se si esegue il ripristino da un'interruzione del servizio usando il ripristino geografico o la replica geografica, è necessario assicurarsi che la connettività ai nuovi server sia configurata correttamente in modo da poter riprendere il normale funzionamento dell'applicazione. È possibile seguire le Attività successive al ripristino.
- Se in precedenza è stata configurata un'impostazione di diagnostica nel server originale, assicurarsi di eseguire la stessa operazione nel server di destinazione, se necessario, come illustrato in Configurare e accedere ai log in Database di Azure per PostgreSQL - Server flessibile.
- Configurare gli avvisi di telemetria, è necessario assicurarsi che le impostazioni delle regole di avviso esistenti vengano aggiornate per eseguire il mapping al nuovo server. Per altre informazioni sulle regole di avviso, vedere Usare il portale di Azure per configurare avvisi per le metriche per Database di Azure per PostgreSQL - Server flessibile.
Importante
I server eliminati non possono essere ripristinati. Se si elimina il server, è possibile seguire le indicazioni riportate in Ripristinare un database di Azure eliminato - Database di Azure per PostgreSQL - Server flessibile per il ripristino. Usare il blocco delle risorse di Azure per impedire l'eliminazione accidentale del server.
Contenuto correlato
- Disponibilità elevata in Database di Azure per PostgreSQL - Server flessibile.
- Ripristino temporizzato di un'istanza del server flessibile Database di Azure per PostgreSQL.