Replica di messaggi e federazione tra aree
All'interno degli spazi dei nomi, bus di servizio di Azure supporta la creazione di topologie di code concatenati e sottoscrizioni di argomenti usando ilforwarding automatico per consentire l'implementazione di vari modelli di routing. Ad esempio, è possibile fornire ai partner code dedicate a cui dispongono di autorizzazioni di invio o ricezione e che possono essere sospese temporaneamente, se necessario, e connetterle in modo flessibile ad altre entità private all'applicazione. È anche possibile creare topologie di routing a più fasi complesse oppure creare code di tipo cassetta postale, che svuotano le sottoscrizioni simili a una coda di argomenti e consentono una maggiore capacità di archiviazione per sottoscrittore.
Molte soluzioni sofisticate richiedono anche la replica dei messaggi attraverso i limiti dello spazio dei nomi per implementare questi e altri modelli. I messaggi possono dover passare tra spazi dei nomi associati a più tenant di applicazioni diversi o tra più aree di Azure diverse.
La soluzione manterrà più spazi dei nomi bus di servizio in aree diverse e replica i messaggi tra code e argomenti e/o che verranno scambiati messaggi con origini e destinazioni come Hub eventi di Azure, hub IoT di Azure o Apache Kafka.
Questi scenari sono l'obiettivo di questo articolo.
Modelli di federazione
Esistono numerose potenziali motivazioni per il motivo per cui è consigliabile spostare messaggi tra entità bus di servizio come code o argomenti o tra bus di servizio e altre origini e destinazioni.
Rispetto al set di modelli simile per Hub eventi, la federazione per le entità simili a una coda è più complessa perché le code di messaggi promettono la proprietà esclusiva dei consumer su qualsiasi singolo messaggio, devono mantenere l'ordine di arrivo nel recapito dei messaggi e per consentire al broker di coordinare la distribuzione equa dei messaggi tra i consumer concorrenti.
Esistono ostacoli pratici, inclusi i vincoli del teorema CAP, che rendono difficile fornire una visualizzazione unificata di una coda disponibile simultaneamente in più aree e che consente ai consumatori distribuiti a livello regionale di assumere la proprietà esclusiva dei messaggi. Una coda con distribuzione geografica di questo tipo richiederebbe una replica completamente coerente non solo dei messaggi, ma anche dello stato di recapito di ogni messaggio prima che i messaggi possano essere resi disponibili ai consumer. L'obiettivo di una coerenza completa per una coda ipotetica e distribuita a livello di area è in conflitto diretto con l'obiettivo principale che praticamente tutti i clienti bus di servizio di Azure hanno quando si prendono in considerazione scenari di federazione: disponibilità e affidabilità massime per le proprie soluzioni.
I modelli presentati qui si concentrano quindi sulla disponibilità e sull'affidabilità, mirando anche a evitare al meglio la perdita di informazioni e la gestione duplicata dei messaggi.
Resilienza rispetto a eventi di disponibilità a livello di area
Sebbene la massima disponibilità e affidabilità siano le principali priorità operative per bus di servizio, esistono tuttavia molti modi in cui un produttore o un consumer potrebbe essere impedito di comunicare con il proprio bus di servizio "primario" assegnato a causa di problemi di rete o risoluzione dei nomi o dove bus di servizio l'entità potrebbe effettivamente non rispondere temporaneamente o restituire errori. Anche il processore di messaggi designato potrebbe diventare non disponibile.
Tali condizioni non sono "disastrose" in modo che si voglia abbandonare completamente la distribuzione a livello di area, come si potrebbe fare in una situazione di ripristino di emergenza, ma lo scenario aziendale di alcune applicazioni potrebbe essere già interessato da eventi di disponibilità che durano non più di pochi minuti o addirittura secondi. bus di servizio di Azure viene spesso usato in ambienti cloud ibridi e con i client che risiedono nella rete perimetrale, ad esempio nei punti vendita al dettaglio, nei ristoranti, nei rami bancari, nei siti di produzione, nelle strutture logistiche e negli aeroporti. È possibile che un problema di routing di rete o congestione influisca sulla capacità di un sito di raggiungere l'endpoint assegnato bus di servizio mentre un endpoint secondario in un'area diversa potrebbe essere raggiungibile. Allo stesso tempo, i sistemi che elaborano i messaggi provenienti da questi siti possono comunque avere accesso non implementato sia agli endpoint primario che a quello secondario bus di servizio.
Esistono molti esempi pratici di applicazioni cloud ibride e perimetrali con una bassa tolleranza aziendale per l'impatto dei problemi di routing di rete o di problemi di disponibilità temporanei di un'entità bus di servizio. Questi includono l'elaborazione dei pagamenti nei siti di vendita al dettaglio, l'imbarco ai cancelli dell'aeroporto e gli ordini di telefono cellulare nei ristoranti, tutti i quali arrivano a un istante, e completare l'standtill ogni volta che il percorso di comunicazione affidabile non è disponibile.
In questa categoria vengono illustrati tre modelli distribuiti distinti: replica "all-active", replica "active-passive" e replica "spillover".
Replica all-active
Il modello di replica "all-active" consente la disponibilità di una replica attiva dello stesso argomento logico (o coda) in più spazi dei nomi (e aree) e per tutti i messaggi diventano disponibili in tutte le repliche, indipendentemente dalla posizione in cui sono stati accodati. Il modello mantiene in genere l'ordine dei messaggi rispetto a qualsiasi server di pubblicazione.
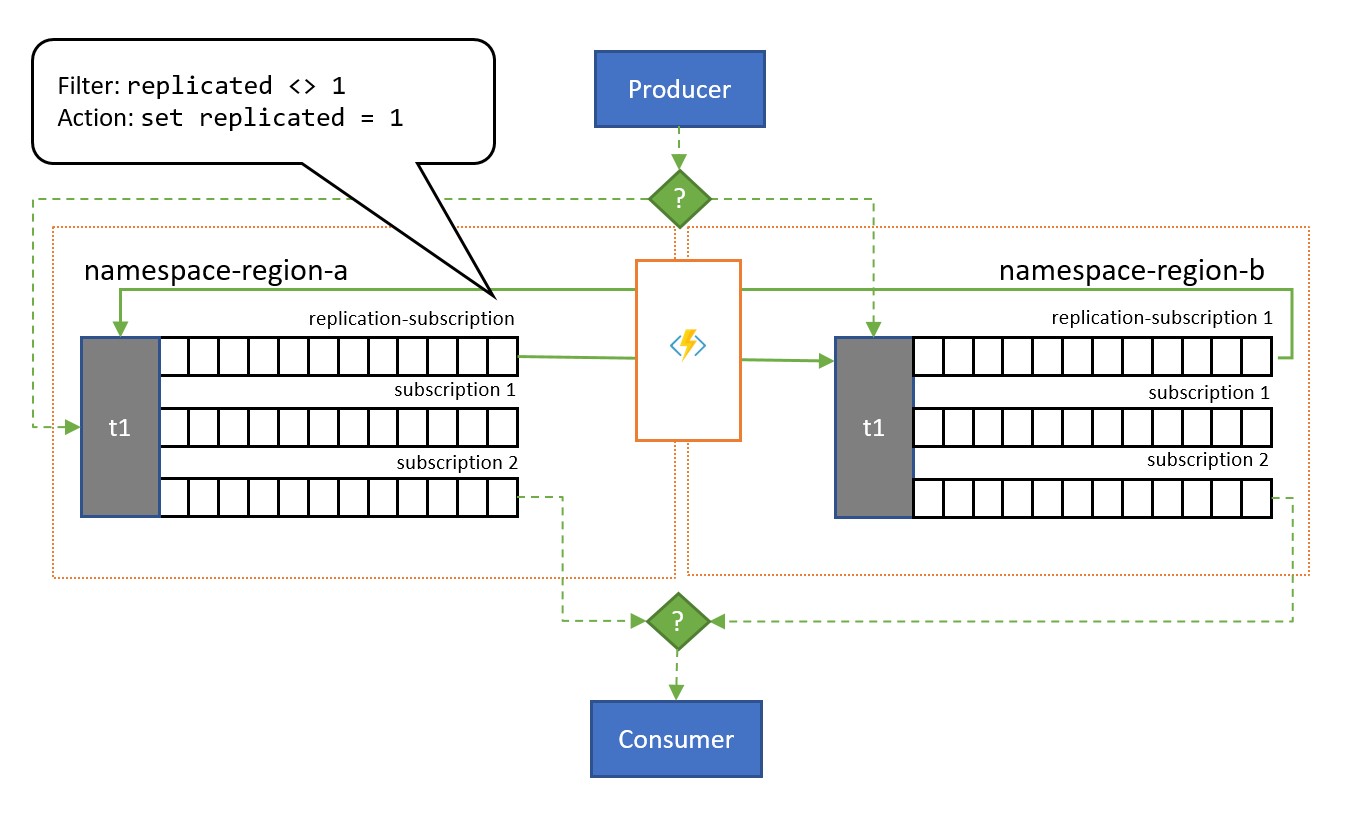
Come illustrato nell'illustrazione, il modello si appoggia in genere a bus di servizio Argomenti. Un argomento per ogni spazio dei nomi che deve partecipare allo schema di replica. Ognuno di questi argomenti include una "sottoscrizione di replica" per qualsiasi altro argomento in cui i messaggi devono essere replicati. Nella figura precedente è sufficiente avere una coppia di argomenti e quindi una singola sottoscrizione di replica per l'altro argomento. In uno scenario con tre spazi dei nomi {n1, n2, n3}, un argomento nello spazio dei nomi n1 include due sottoscrizioni di replica, una per l'argomento corrispondente in n2 e una per l'argomento corrispondente in n3.
Ogni sottoscrizione di replica ha una regola che combina un'espressione di filtro SQL (replicated <> 1) e un'azione SQL (set replicated = 1). Il filtro della regola garantisce che solo i messaggi in cui la proprietà replication personalizzata non sia impostata o non dispongano del valore 1 diventano idonei per questa sottoscrizione e l'azione imposta tale proprietà esatta sul valore 1 di ogni messaggio selezionato subito dopo. L'effetto è che quando il messaggio viene copiato nell'argomento corrispondente, non è più idoneo per la replica nella direzione opposta e pertanto si evitano i messaggi rimbalzi tra le repliche.
Una sottoscrizione con una rispettiva regola può essere aggiunta facilmente a qualsiasi argomento usando l'interfaccia della riga di comando di Azure in questo modo.
az servicebus topic subscription rule create --resource-group myresourcegroup \
--namespace mynamespace --topic-name mytopic \
--subscription-name replication --name replication \
--action-sql-expression "set replication = 1" \
--filter-sql-expression "replication IS NULL"
Per modellare una coda, ogni argomento è limitato a una sola sottoscrizione normale (diversa dalle sottoscrizioni di replica) condivise da tutti i consumer.
Il modello di replica all-active inserisce una copia di ogni messaggio inviato in uno degli argomenti in ognuno degli argomenti. Ciò significa che il codice dell'applicazione in ogni area visualizzerà ed elaborerà tutti i messaggi. Questo modello è adatto per scenari in cui i dati vengono condivisi in più aree o se l'elaborazione ridondante è in genere desiderata. Se è necessario elaborare ogni messaggio una sola volta, come con una coda regolare, è necessario considerare uno dei due modelli seguenti.
Replica attiva-passiva
Il modello di replica "attivo-passivo" è una variazione del modello precedente in cui solo uno degli argomenti ("primario") viene usato attivamente dall'applicazione per l'invio e la ricezione di messaggi e messaggi in un argomento secondario per il caso in cui l'argomento primario potrebbe diventare non disponibile o non raggiungibile.
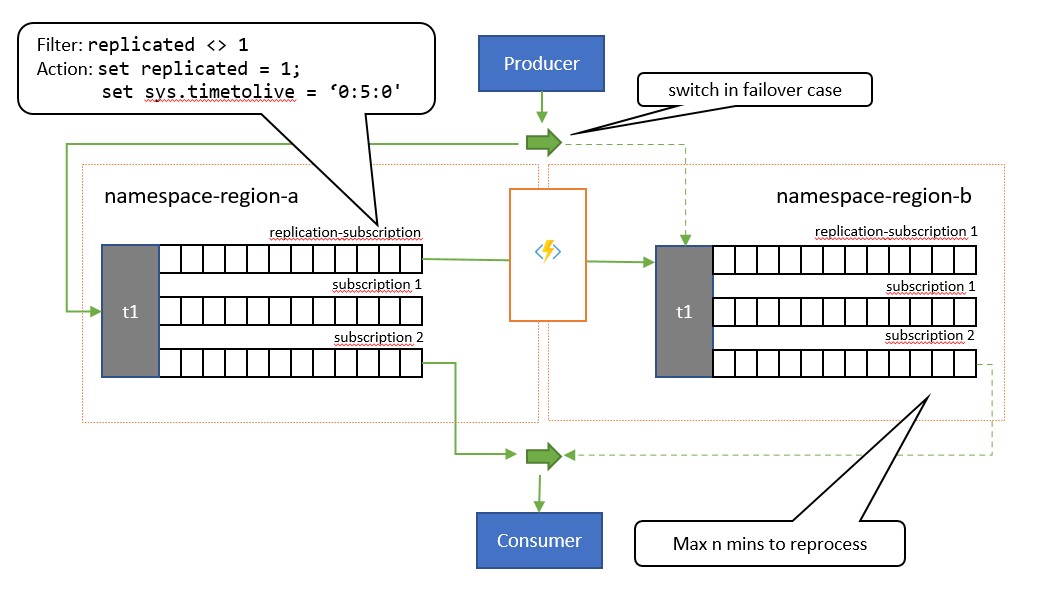
La differenza principale tra questo modello e il modello precedente è che la replica è unidirezionale dall'argomento primario nell'argomento secondario. L'argomento secondario non diventa mai primario, ma è un'opzione di backup per quando l'argomento primario è temporaneamente inutilizzabile.
Lo svantaggio dell'uso di questo modello è che tenta di ridurre al minimo l'elaborazione duplicata. Durante la replica, la TimeToLive proprietà del messaggio viene impostata su una durata dei messaggi replicati che riflette il tempo previsto durante il quale un errore del database primario porterà a un failover. Ad esempio, se lo scenario del caso d'uso richiede un passaggio del consumer al database secondario entro un massimo di 1 minuto dal momento in cui il recupero dei messaggi dall'inizio principale mostra problemi, il database secondario dovrebbe idealmente avere tutti i messaggi disponibili che non è stato possibile accedere nel database primario, ma un numero minimo di messaggi già elaborati dalla replica primaria prima che si verificassero i problemi. Se si imposta su TimeToLive due volte quel periodo, 2 minuti, durante la replica (set sys.TimeToLive = '0:2:0' nell'azione della regola), il database secondario manterrà solo i messaggi per 2 minuti e eliminerà quelli meno recenti. Ciò significa che quando il ricevitore passa al database secondario, può leggere e rimuovere rapidamente i messaggi precedenti all'ultimo elaborato e quindi elaborare dal primo messaggio che non è ancora stato visualizzato. La durata effettiva della conservazione dipende dal caso d'uso specifico e da quando si vuole e può passare rapidamente al database secondario nell'applicazione. L'impostazione TimeToLive viene rispettata nell'intervallo da pochi secondi a giorni.
Anche se l'applicazione usa il database secondario, può anche pubblicare direttamente nell'argomento secondario, che funge quindi da qualsiasi argomento regolare. Dopo il passaggio al database secondario, il consumer visualizzerà quindi una combinazione di messaggi e messaggi replicati pubblicati direttamente nel database secondario. L'applicazione deve quindi prima tornare alla pubblicazione nel database primario e consentire comunque lo svuotamento dei messaggi pubblicati localmente prima di tornare al consumer al database secondario. A causa della ripresa automatica della replica dopo che il database primario è nuovamente disponibile, il consumer riceverà anche nuovi messaggi pubblicati nel database primario durante tale periodo, anche se con una latenza leggermente superiore.
Questo modello è adatto per scenari in cui i messaggi devono essere elaborati una sola volta. L'applicazione deve cooperare per tenere traccia dei messaggi elaborati dal database primario perché troverà duplicati per la durata della finestra di failover nel database secondario e troverà di nuovo duplicati durante il cambio. Il criterio di deduplicazione deve essere un elemento fornito dall'applicazione
MessageId. IlEnqueuedTimeUtcvalore è adatto anche come indicatore di filigrana, ma l'applicazione deve consentire una certa deviazione del clock (diversi secondi) tra primario e secondario come con qualsiasi sistema distribuito.
Replica di spillover
Il modello di replica "spillover" consente l'uso attivo/attivo di più entità bus di servizio in più aree per gestire lo scenario in cui bus di servizio è integro, ma il consumer diventa sovraccarico con il numero di messaggi in sospeso o non è disponibile. Un motivo potrebbe essere che un database che esegue il backup del processo consumer potrebbe essere lento o non disponibile. Questo modello funziona con code semplici e con sottoscrizioni di argomenti.
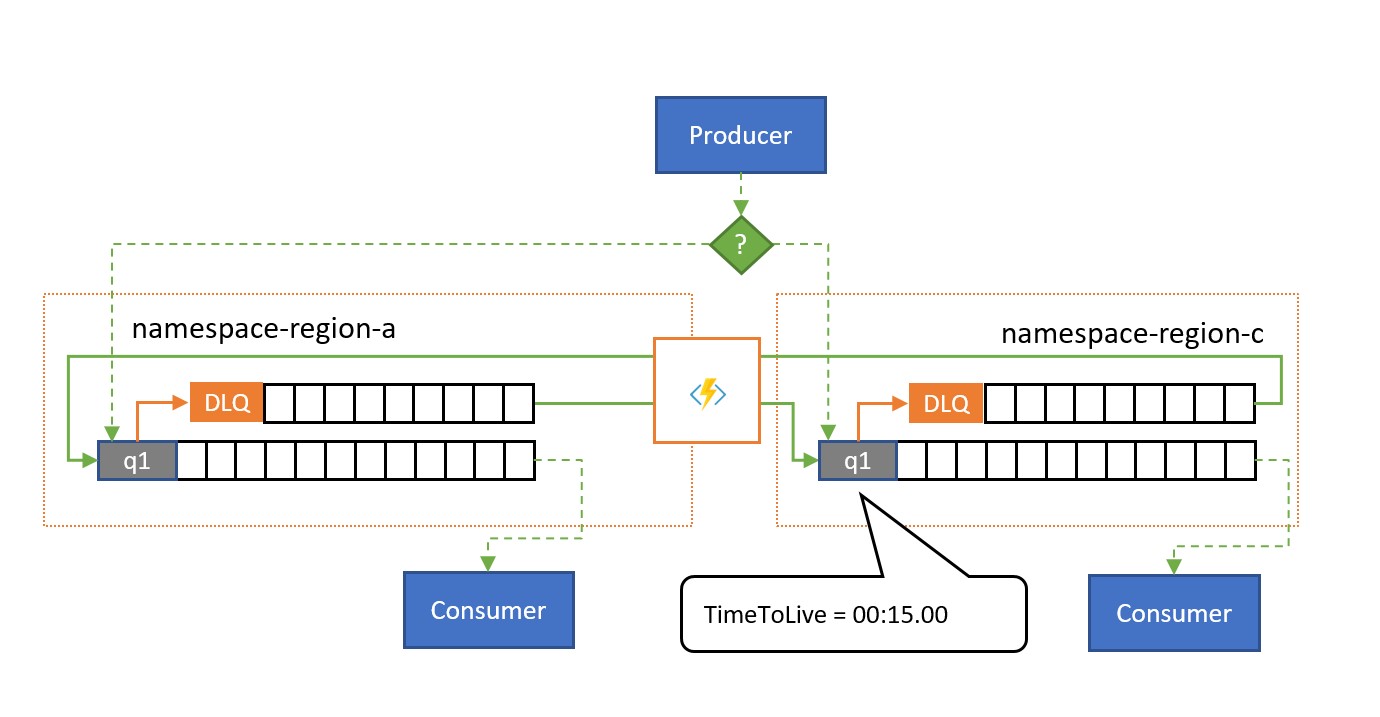
Come illustrato nell'illustrazione, il modello di replica di spillover replica i messaggi dalla coda o dalla coda di messaggi non recapitabili associati a una coda o a un argomento associato in uno spazio dei nomi diverso.
Senza che si verifichi una situazione di errore, i due spazi dei nomi vengono usati in parallelo, ognuno dei quali riceve un subset del traffico complessivo dei messaggi e i relativi consumer associati che gestiscono tale subset. Una volta che uno dei consumer inizia a presentare tassi di errore elevati o si arresta in modo definitivo, i rispettivi messaggi finiranno nella coda dei messaggi non recapitabili tramite il superamento del numero di recapito o perché scade. Le attività di replica li raccoglieranno e le accoderanno nuovamente nella coda abbinata, dove vengono quindi presentate al consumer presumibilmente integro.
Se l'elaborazione deve essere eseguita entro una determinata scadenza, l'oggetto TimeToLive per la coda e/o i messaggi deve essere impostato in modo che l'elaborazione possa essere ancora eseguita nel tempo dal database secondario di spillover, ad esempio TimeToLive potrebbe essere impostata su metà del tempo consentito.
Come per il modello all-active, l'applicazione può aggiungere un indicatore al messaggio se il messaggio è già stato replicato una volta in modo che non rimbalzino tra la coppia di code, ma vengono invece inseriti in una coda ausiliaria che funge da coda di messaggi non recapitabili per il modello composito.
Questo modello è adatto per gli scenari in cui il principale problema è quello di difendersi dai problemi di disponibilità nei consumer o nelle risorse su cui si basano i consumer e anche per ridistribuire i picchi di traffico in una delle code abbinate. Fornisce inoltre protezione da uno degli spazi dei nomi che diventano non disponibili se i consumer leggono da entrambe le code, ma il ritardo di replica imposto dalla
TimeToLivescadenza può causare la chiusura dei messaggi all'interno di tale intervallo di tempo nello spazio dei nomi non disponibile.
Ottimizzazione della latenza
Gli argomenti vengono usati per distribuire informazioni a più consumer. In alcuni casi, in particolare i consumer con una distribuzione geografica estesa, potrebbe essere utile replicare i messaggi da un argomento in un argomento in uno spazio dei nomi secondario più vicino ai consumer.
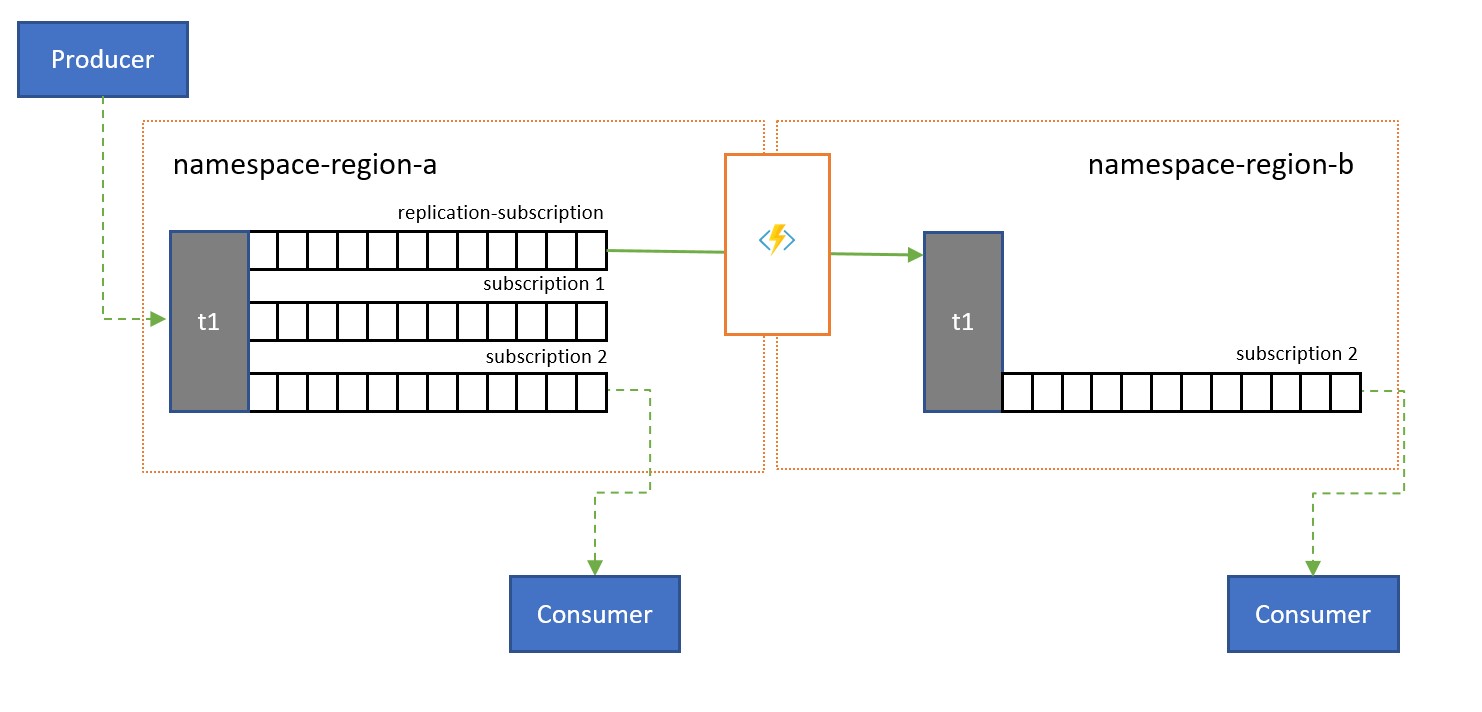
Ad esempio, quando si condividono i dati tra hub regionali e continentali, è più efficiente trasferire le informazioni una sola volta tra hub e chiedere ai consumer di ottenere la copia dei dati da tali hub.
I trasferimenti di replica possono essere eseguiti in batch, che spesso i consumer ottengono e liquidano i messaggi uno alla sola. Con una latenza di rete di base di 100 ms tra, ad esempio, America del Nord ed Europa, ogni messaggio richiede più di 200 ms per elaborare per i due round trip a un'entità remota per acquisire e stabilire i messaggi, rispetto a un'entità nella stessa area.
Convalida, riduzione e arricchimento
I messaggi possono essere inviati in una coda di bus di servizio o in un argomento da parte dei client esterni alla propria soluzione.
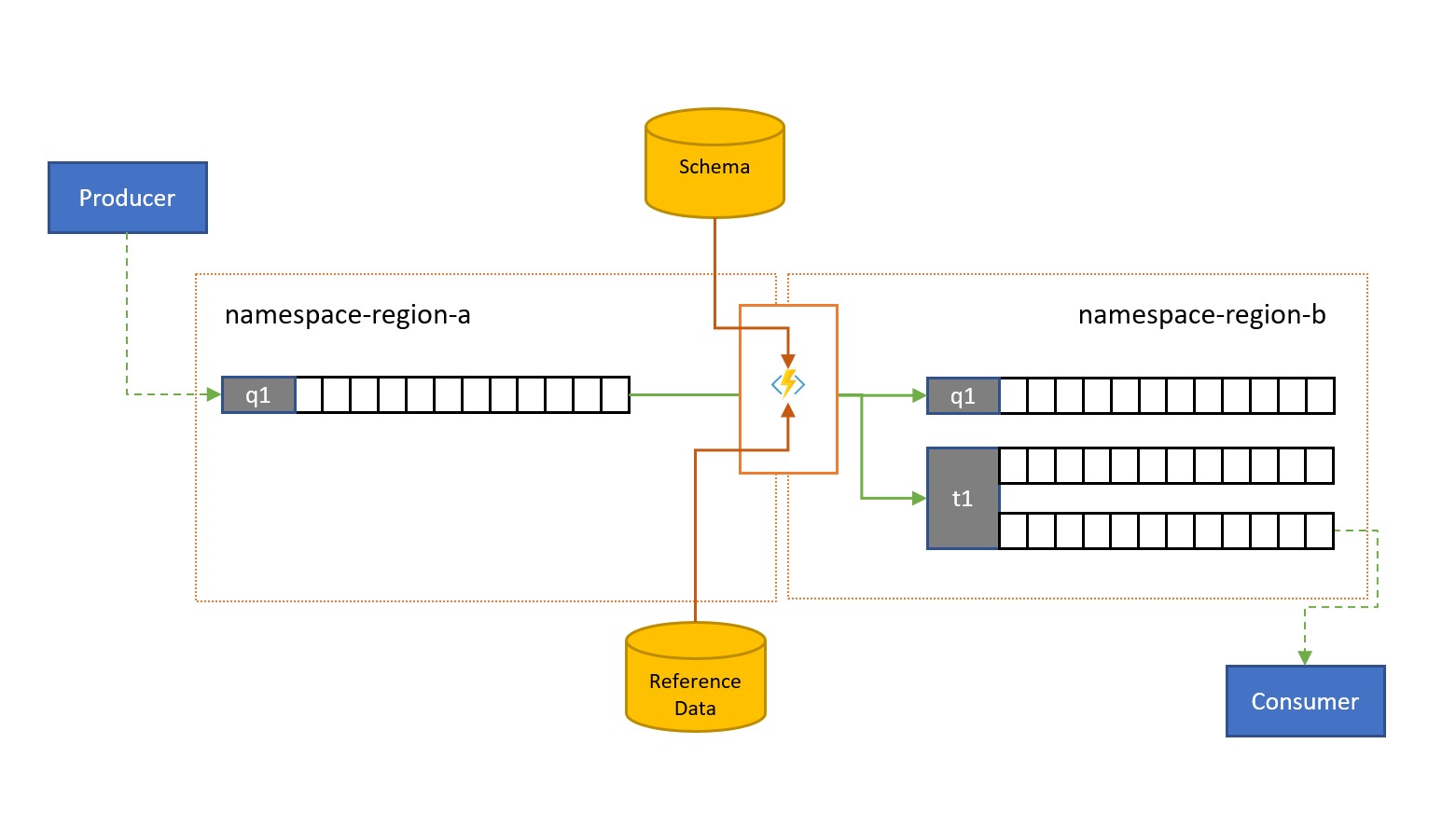
Tali messaggi possono richiedere la verifica della conformità con uno schema specifico e la presenza di messaggi non conformi da eliminare o inviare messaggi non recapitabili. Alcuni messaggi possono essere ridotti in complessità omettendo i dati e alcuni potrebbero dover essere arricchiti aggiungendo dati in base alle ricerche dei dati di riferimento. Le operazioni possono essere eseguite con funzionalità personalizzate nell'attività di replica.
Replica da flusso a coda
Hub eventi di Azure è una soluzione ideale per gestire volumi estremi di eventi in ingresso. Ma né Hub eventi né motori simili come Apache Kafka forniscono un modello consumer concorrente gestito dal servizio in cui più consumer possono gestire i messaggi dalla stessa origine simultaneamente senza rischiare l'elaborazione duplicata e infine risolvere tali messaggi dopo l'elaborazione.
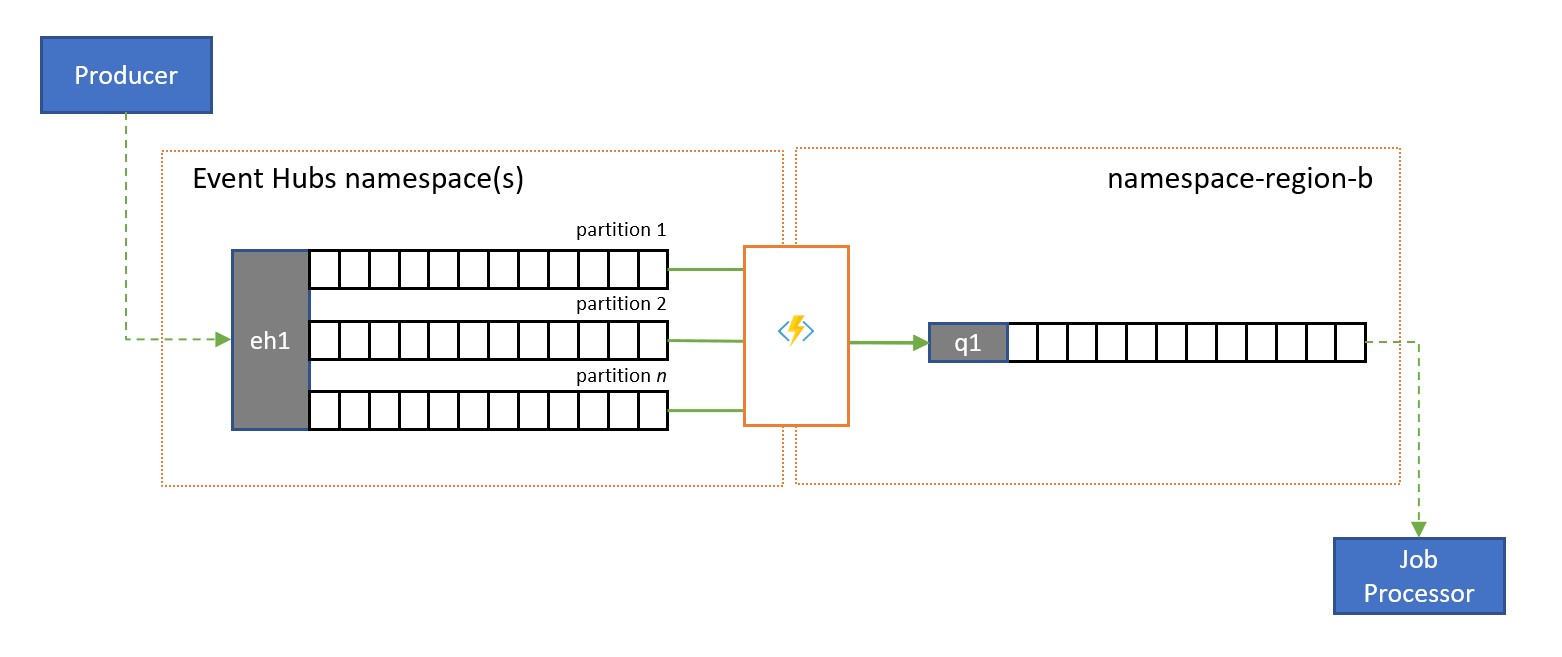
Una replica da flusso a coda trasferisce il contenuto di una singola partizione di Hub eventi o il contenuto di un hub eventi completo in una coda di bus di servizio, da dove i messaggi possono essere elaborati in modo sicuro, transazionale e con consumer concorrenti. Questa replica consente anche di usare tutte le altre funzionalità di bus di servizio per tali messaggi, incluso il routing con argomenti e demultiplexing basato su sessione.
Consolidamento e normalizzazione
Le soluzioni globali sono spesso costituite da footprint regionali che sono in gran parte indipendenti, tra cui avere le proprie capacità di elaborazione, ma prospettive sovra-regionali e globali richiederanno l'integrazione dei dati e quindi un consolidamento centrale degli stessi dati di messaggio valutati nei rispettivi footprint regionali per la prospettiva locale.
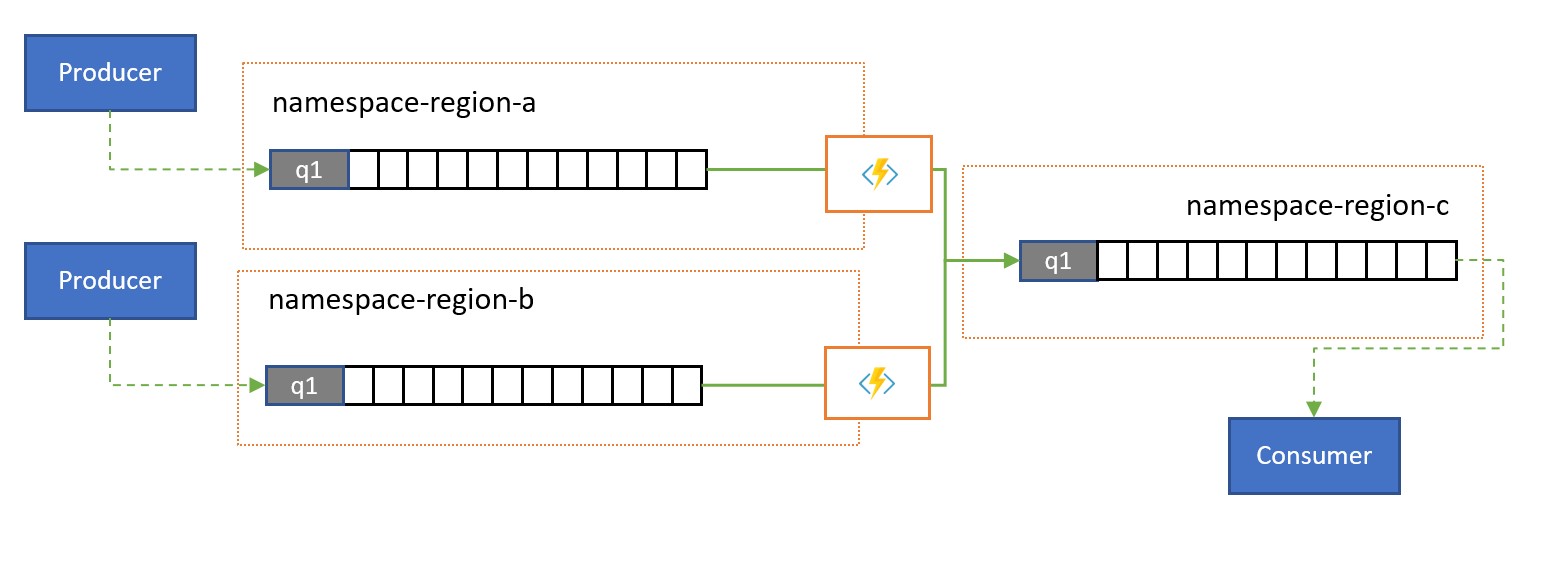
La normalizzazione è un sapore dello scenario di consolidamento, in cui due o più sequenze in ingresso di messaggi contengono lo stesso tipo di informazioni, ma con strutture diverse o codifiche diverse e i messaggi devono essere transcodificati o trasformati prima che possano essere utilizzati.
La normalizzazione può includere anche il lavoro crittografico, ad esempio la decrittografia di payload crittografati end-to-end e la ricrittografia con chiavi e algoritmi diversi per il pubblico consumer downstream.
Suddivisione e routing
bus di servizio argomenti e le relative regole di sottoscrizione vengono spesso usati per filtrare un flusso di messaggi per un gruppo di destinatari specifico e che il gruppo di destinatari ha quindi ottenuto il set filtrato da una sottoscrizione.
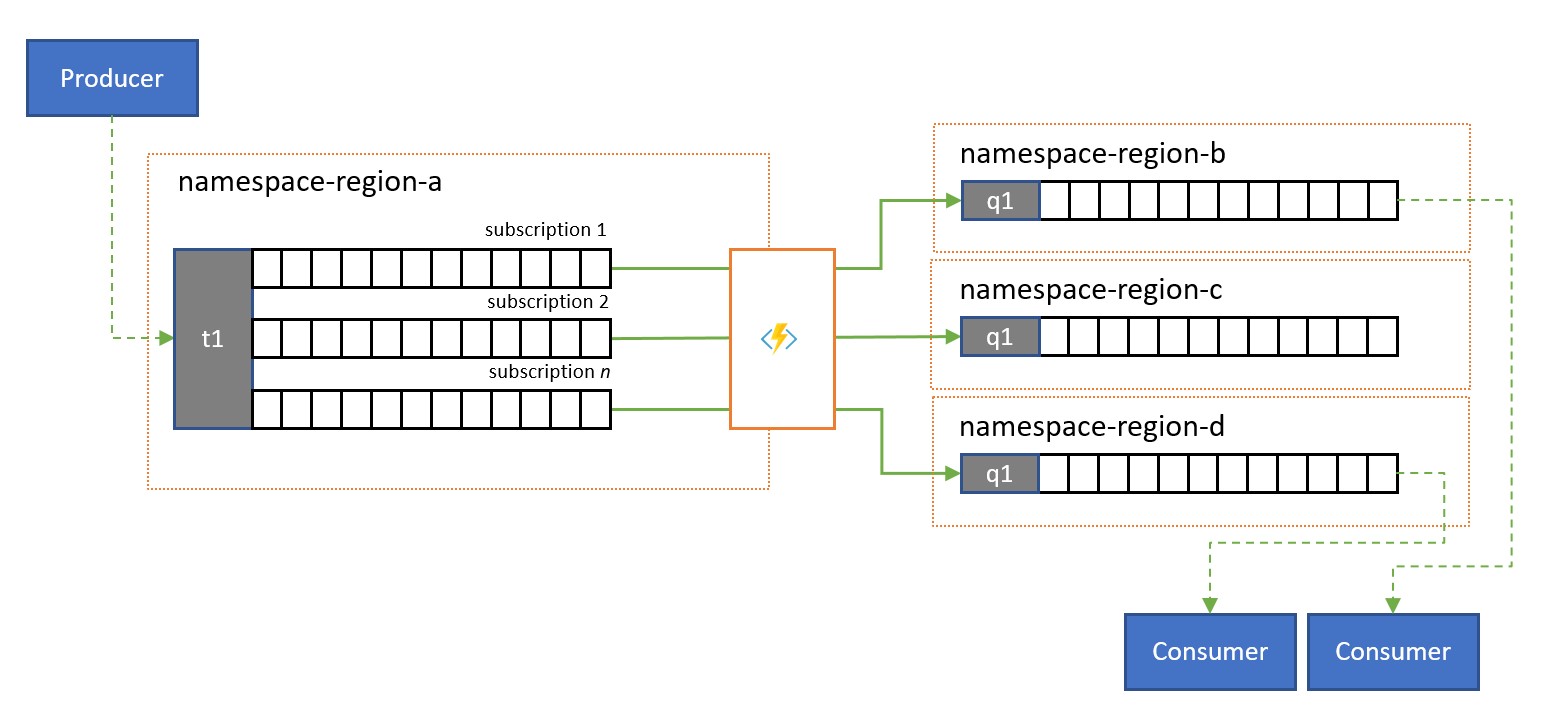
In un sistema globale in cui il gruppo di destinatari di tali messaggi viene distribuito a livello globale o appartiene a applicazioni diverse, la replica può essere usata per trasferire messaggi da una sottoscrizione di questo tipo a una coda o a un argomento in uno spazio dei nomi diverso da cui vengono utilizzati.
Applicazioni di replica in Funzioni di Azure
L'implementazione dei modelli precedenti richiede un ambiente di esecuzione scalabile e affidabile per le attività di replica da configurare ed eseguire. In Azure l'ambiente di runtime più adatto per le attività senza stato è Funzioni di Azure.
Funzioni di Azure può essere eseguito in un Identità gestita di Azure in modo che le attività di replica possano integrarsi con le regole di controllo degli accessi in base al ruolo dei servizi di origine e di destinazione senza dover gestire i segreti lungo il percorso di replica. Per le origini e le destinazioni di replica che richiedono credenziali esplicite, Funzioni di Azure possono contenere i valori di configurazione per tali credenziali in una risorsa di archiviazione strettamente controllata dall'accesso all'interno di Azure Key Vault.
Funzioni di Azure consente inoltre alle attività di replica di integrarsi direttamente con le reti virtuali di Azure e gli endpoint di servizio per tutti i servizi di messaggistica di Azure ed è facilmente integrato con Monitoraggio di Azure.
Soprattutto, Funzioni di Azure include trigger predefiniti, trigger scalabili e associazioni di output per Hub eventi di Azure, hub IoT di Azure, bus di servizio di Azure, Griglia di eventi di Azure e Archiviazione code di Azure, estensioni personalizzate per RabbitMQ e Apache Kafka. La maggior parte dei trigger si adatterà in modo dinamico alle esigenze di velocità effettiva ridimensionando il numero di istanze in esecuzione simultanea su e giù in base alle metriche documentate.
Con il piano a consumo Funzioni di Azure, i trigger predefiniti possono anche ridurre fino a zero, mentre non sono disponibili messaggi per la replica, il che significa che non si comportano costi per mantenere la configurazione pronta per aumentare le prestazioni di backup. Lo svantaggio principale dell'uso del piano a consumo è che la latenza per le attività di replica "riattivazione" da questo stato è significativamente superiore rispetto ai piani di hosting in cui l'infrastruttura viene mantenuta in esecuzione.
A differenza di tutto questo, i motori di replica più comuni per la messaggistica e l'evento, ad esempio MirrorMaker di Apache Kafka, richiedono di fornire un ambiente di hosting e ridimensionare manualmente il motore di replica. Ciò include la configurazione e l'integrazione delle funzionalità di sicurezza e di rete e facilita il flusso dei dati di monitoraggio, quindi non è ancora possibile inserire attività di replica personalizzate nel flusso.
Attività di replica con App per la logica di Azure
Un'alternativa non di codifica all'esecuzione della replica tramite Funzioni consiste nell'usare invece App per la logica. Le app per la logica hanno attività di replica predefinite per bus di servizio. Questi possono essere utili per configurare la replica tra istanze diverse e possono essere modificati per un'ulteriore personalizzazione.
Passaggi successivi
In questo articolo è stata esaminata una serie di modelli di federazione e è stato illustrato il ruolo di Funzioni di Azure come runtime di replica di eventi e messaggistica in Azure.
Successivamente, è possibile leggere come configurare un'applicazione di replicatore con Funzioni di Azure e quindi come replicare i flussi di eventi tra Hub eventi e vari altri sistemi di eventi e messaggistica: