Esercitazione: Analizzare i report di inventario BLOB
La comprensione delle modalità di archiviazione, organizzazione e uso dei BLOB e dei contenitori nell’ambiente di produzione consente di ottimizzare il bilanciamento tra costi e prestazioni.
Questa esercitazione mostra come generare e visualizzare statistiche come la crescita dei dati nel tempo, i dati aggiunti nel tempo, il numero di file modificati, le dimensioni degli snapshot BLOB, i modelli di accesso su ogni livello e le modalità con cui i dati vengono distribuiti sia attualmente che nel tempo (ad es. dati tra livelli, tipi di file, in contenitori e tipi di BLOB).
In questa esercitazione apprenderai a:
- Generare un report di inventario BLOB
- Configurare un'area di lavoro di Synapse
- Configurare Synapse Studio
- Generare dati analitici in Synapse Studio
- Visualizzare i risultati in Power BI
Prerequisiti
Una sottoscrizione di Azure: creare un account gratuito
Un account di archiviazione di Azure: creare un account di archiviazione
Accertarsi che all'identità utente sia assegnato il ruolo di Collaboratore ai dati del BLOB di archiviazione.
Generare un report di inventario
Abilitare i report di inventario BLOB per l'account di archiviazione. Vedere Abilitare i report dell'inventario BLOB di Archiviazione di Azure.
Per la generazione del primo report potrebbe essere necessario attendere fino a 24 ore dopo l’abilitazione dei report di inventario.
Configurare un'area di lavoro di Synapse
Creare un'area di lavoro di Azure Synapse. Vedere Creare un'area di lavoro di Azure Synapse.
Nota
Durante la creazione dell'area di lavoro, verrà creato un account di archiviazione con uno spazio dei nomi gerarchico. Azure Synapse archivia tabelle Spark e registri applicazioni in questo account. Azure Synapse fa riferimento a questo account come account di archiviazione primario. Per evitare confusione, questo articolo usa il termine account del report di inventario per fare riferimento all'account contenente report di inventario.
Nell'area di lavoro Synapse assegnare il ruolo di Collaboratore all'identità utente. Vedere Controllo degli accessi in base al ruolo di Azure (Azure RBAC): ruolo Proprietario per l'area di lavoro.
Concedere all'area di lavoro di Synapse l'autorizzazione per l’accesso ai report di inventario nell'account di archiviazione passando all'account del report di inventario e assegnando, quindi, il ruolo Collaboratore ai dati dei BLOB di archiviazione all'identità gestita dal sistema dell'area di lavoro. Vedere Assegnare ruoli di Azure usando il portale di Azure.
Passare all'account di archiviazione primario e assegnare il ruolo Collaboratore all’archiviazione BLOB all'identità utente.
Configurare Synapse Studio
Aprire l’area di lavoro di Synapse in Synapse Studio. Vedere Aprire Synapse Studio.
In Synapse Studio, accertarsi che all'identità sia assegnato il ruolo di Amministratore di Synapse. Vedere Controllo degli accessi in base al ruolo di Synapse (Synapse RBAC): ruolo di Amministratore di Synapse per l'area di lavoro.
Creare un pool di Apache Spark. Vedere Creare un pool di Apache Spark serverless.
Configurare ed eseguire il notebook di esempio
In questa sezione verranno generati dati statistici che saranno visualizzati in un report. Per semplificare questa esercitazione, questa sezione usa un file di configurazione di esempio e un notebook PySpark di esempio. Il notebook contiene una raccolta di query eseguite in Azure Synapse Studio.
Modificare e caricare il file di configurazione di esempio
Scaricare il file BlobInventoryStorageAccountConfiguration.json.
Aggiornare i seguenti segnaposto del file:
Impostare
storageAccountNamesul nome dell'account del report di inventario.Impostare
destinationContainersul nome del contenitore che include i report di inventario.Impostare
blobInventoryRuleNamesul nome della regola del report di inventario che ha generato i risultati da analizzare.Impostare
accessKeysulla chiave account dell'account del report di inventario.
Caricare questo file nel contenitore nell'account di archiviazione primario specificato al momento della creazione dell'area di lavoro di Synapse.
Importare il notebook PySpark di esempio
Scaricare il notebook di esempio ReportAnalysis.ipynb.
Nota
Accertarsi di salvare questo file con l'estensione
.ipynb.Aprire l’area di lavoro di Synapse in Synapse Studio. Vedere Aprire Synapse Studio.
In Synapse Studio, passare alla scheda Sviluppo.
Selezionare il segno più (+) per aggiungere un elemento.
Selezionare Importa, passare al file di esempio scaricato, selezionare questo fil, quindi selezionare Apri.
Viene visualizzata la finestra di dialogo Proprietà.
Nella finestra di dialogo Proprietà selezionare la scheda Configura sessione.
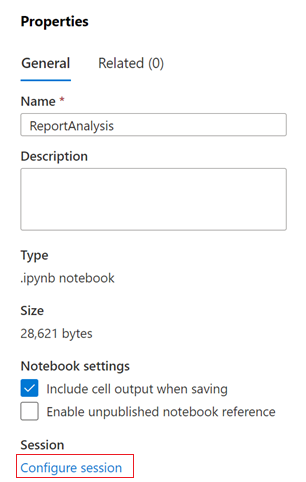
Si apre la finestra di dialogo Configura sessione.
Nell'elenco a discesa Collega a della finestra di dialogo Configura sessione selezionare il pool di Spark creato in precedenza in questo articolo. Selezionare, quindi, il pulsante Applica.
Modificare il notebook Python
Nella prima cella del notebook Python impostare il valore della variabile
storage_accountsul nome dell'account di archiviazione primario.Aggiornare il valore della variabile
container_namesul nome del contenitore in tale account specificato al momento della creazione dell'area di lavoro di Synapse.Selezionare il pulsante Pubblica.
Eseguire il notebook PySpark
Nel notebook PySpark selezionare Esegui tutti.
L'avvio della sessione Spark richiederà alcuni minuti e altri minuti per l’elaborazione dei report di inventario. Se i report di inventario da elaborare sono numerosi, la prima esecuzione potrebbe richiedere tempo. Le esecuzioni successive elaborano solo i nuovi report di inventario creati dall'ultima esecuzione.
Nota
Se si apportano modifiche al notebook mentre è in esecuzione, accertarsi di pubblicare tali modifiche usando il pulsante Pubblica.
Accertarsi che il notebook sia stato eseguito correttamente selezionando la scheda Dati.
Viene visualizzato un database denominato reportdata nella scheda Area di lavoro del riquadro Dati. Se il database non viene visualizzato, potrebbe essere necessario aggiornare la pagina Web.
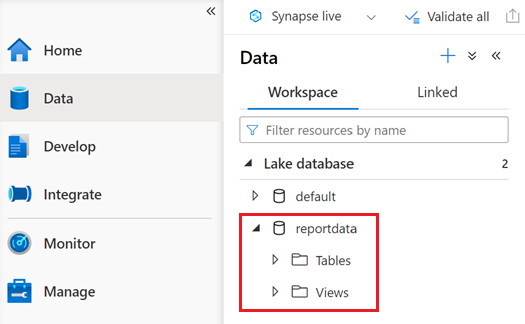
Il database contiene un insieme di tabelle. Ogni tabella contiene informazioni ottenute eseguendo le query dal notebook PySpark.
Per esaminare il contenuto di una tabella, espandere la cartella Tabelle del database reportdata. A questo punto, fare clic con il pulsante destro del mouse su una tabella, selezionare Seleziona script SQL, quindi selezionare Seleziona le prime 100 righe.
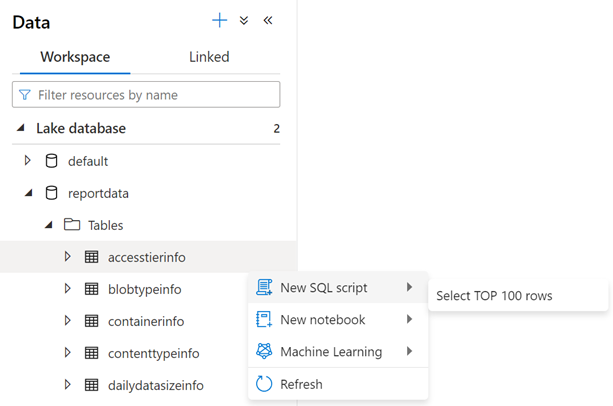
È possibile modificare la query in base alle esigenze, quindi selezionare Esegui per visualizzare i risultati.
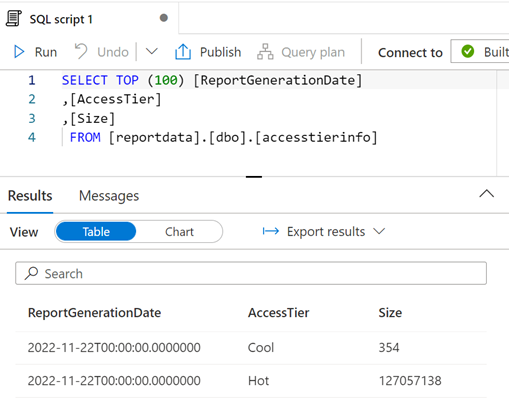
Visualizzare i dati
Scaricare il file di report di esempio ReportAnalysis.pbit.
Apri Power BI Desktop. Per indicazioni sull'installazione, vedere Ottenere Power BI Desktop.
In Power BI selezionare File, Apri report, quindi Sfoglia report.
Nella finestra di dialogo Apri, modificare il tipo di file in File modello di Power BI (*.pbit).

Passare alla posizione del file ReportAnalysis.pbit scaricato, quindi selezionare Apri.
Viene visualizzata una finestra di dialogo che chiede di fornire il nome dell'area di lavoro di Synapse e il nome del database.
Nella finestra di dialogo impostare il campo synapse_workspace_name sul nome dell'area di lavoro, quindi impostare il campo database_name su
reportdata. Selezionare, quindi, il pulsante Carica.
Viene visualizzato un report che fornisce visualizzazioni dei dati recuperati dal notebook. Le immagini seguenti mostrano i tipi di grafici e diagrammi visualizzati in questo report.
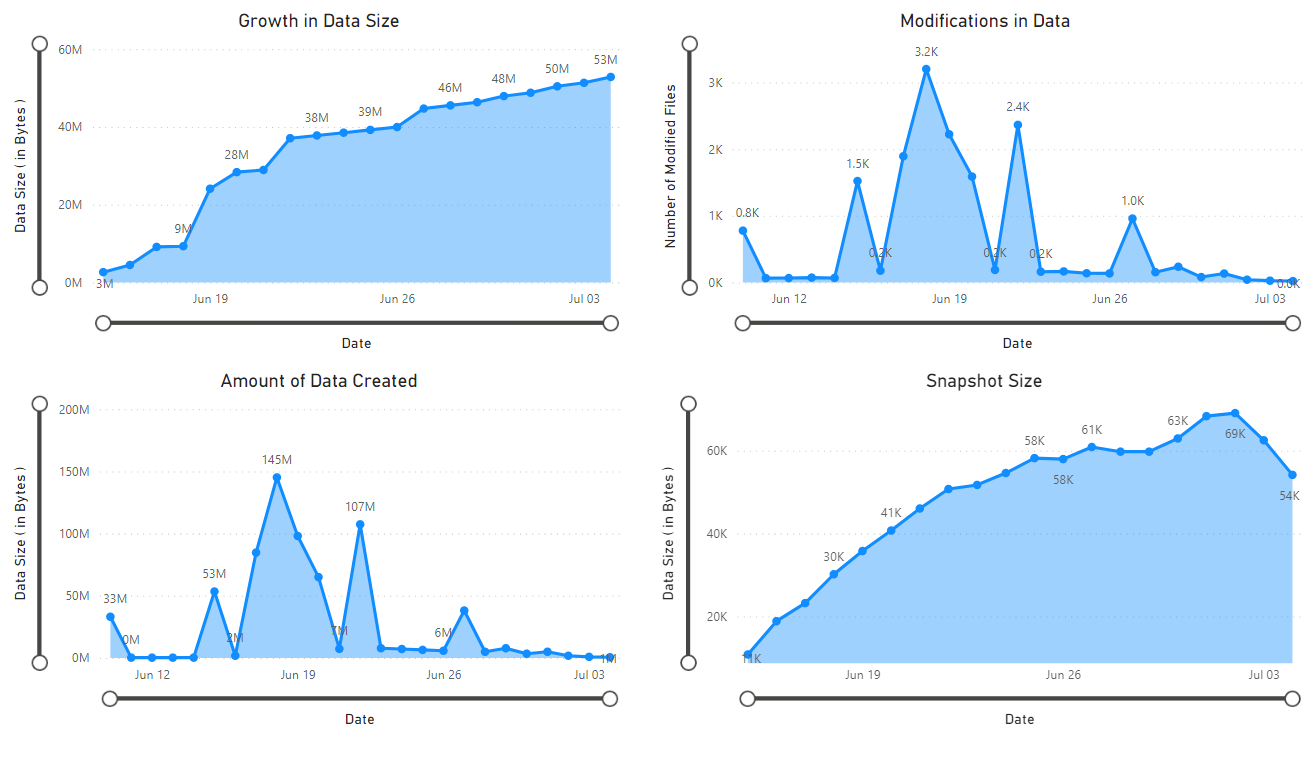
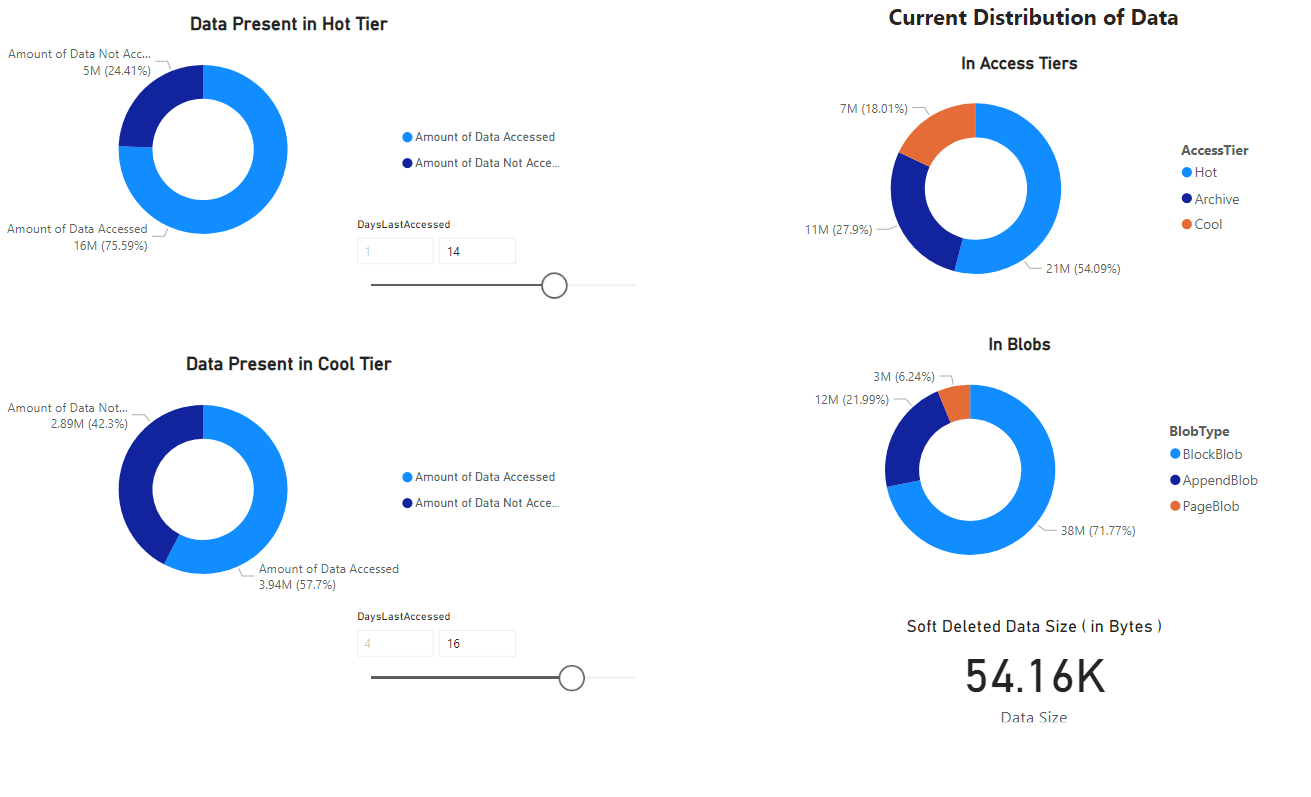
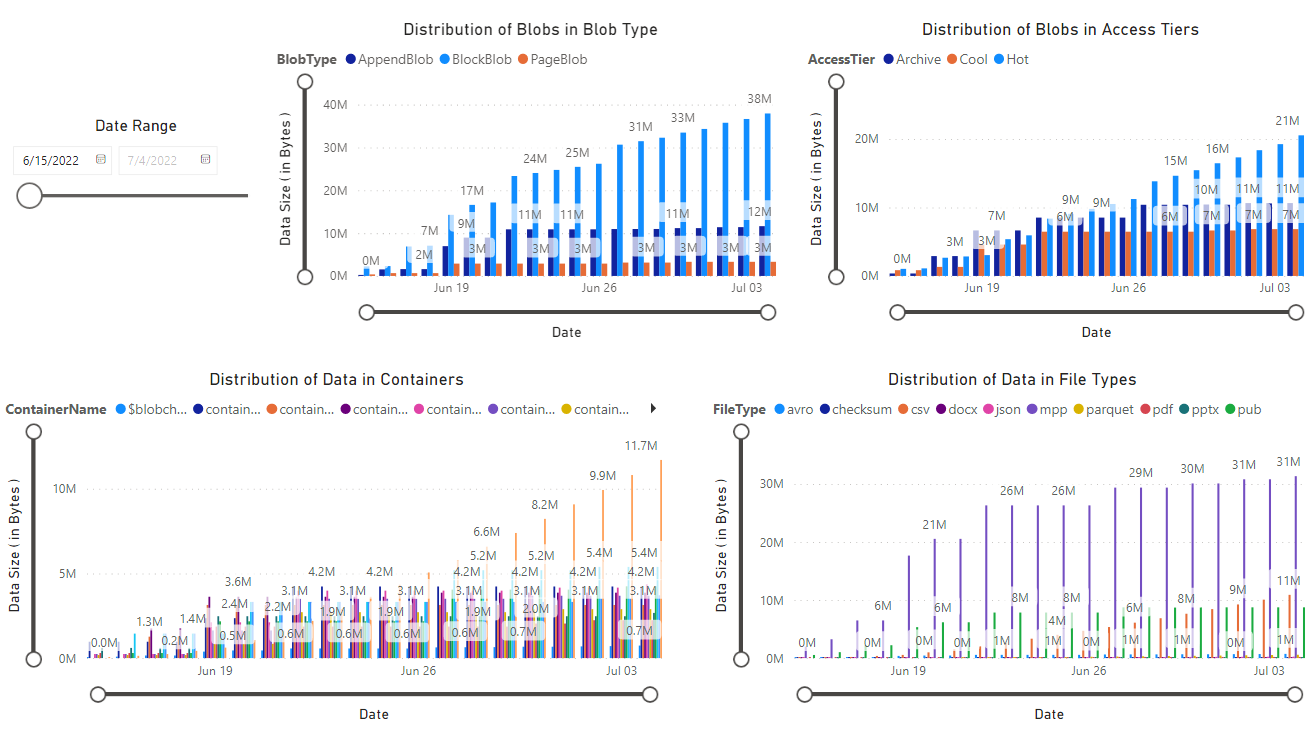
Passaggi successivi
Configurare una pipeline di Azure Synapse per continuare l’esecuzione del notebook a intervalli regolari. In questo modo è possibile elaborare nuovi report di inventario quando vengono creati. Dopo l'esecuzione iniziale, ognuna delle esecuzioni successive analizzerà i dati incrementali, quindi aggiornerà le tabelle con i risultati di tale analisi. Per indicazioni, vedere Integrare con le pipeline.
Informazioni sulle modalità di analisi di singoli contenitori nell'account di archiviazione. Vedere i seguenti articoli:
Esercitazione: Calcolare le statistiche dei contenitori usando Databricks
Informazioni sulle modalità di ottimizzazione dei costi in base all'analisi dei BLOB e dei contenitori. Vedere i seguenti articoli:
Pianificare e gestire i costi dell'Archiviazione BLOB di Azure
Stimare il costo dell'archiviazione dei dati
Ottimizzare i costi gestendo automaticamente il ciclo di vita dei dati