Output di Hub eventi da Analisi di flusso di Azure
Il servizio Hub eventi di Azure è un inseritore eventi di pubblicazione-sottoscrizione altamente scalabile. Può raccogliere milioni di eventi al secondo. L'uso di un hub eventi come output si verifica quando l'output di un processo di Analisi di flusso di Azure diventa l'input di un altro processo di streaming. Per informazioni sulle dimensioni massime dei messaggi e sull'ottimizzazione delle dimensioni del batch, vedere la sezione Dimensione del batch di output.
Configurazione di output
La tabella seguente contiene i parametri necessari per configurare i flussi di dati da hub eventi come output.
| Nome proprietà | Descrizione |
|---|---|
| Alias di output | Nome descrittivo usato nelle query per indirizzare l'output delle query a questo hub eventi. |
| Spazio dei nomi dell'hub eventi | Contenitore per un set di entità di messaggistica. Quando si crea un nuovo hub eventi, viene anche creato uno spazio dei nomi dell'hub eventi. |
| Nome hub eventi | Nome dell'output dell'hub eventi. |
| Nome criteri hub eventi | Criteri di accesso condivisi che è possibile creare nella scheda Configura dell'hub eventi. Tutti i criteri di accesso condiviso dispongono di un nome e di autorizzazioni impostati, nonché di chiavi di accesso. |
| Chiave criteri hub eventi | Chiave di accesso condivisa usata per autenticare l'accesso allo spazio dei nomi dell'hub eventi. |
| Colonna chiave di partizione | Facoltativa. Colonna che contiene la chiave di partizione per l'output dell'hub eventi. |
| Formato di serializzazione eventi | Formato di serializzazione per i dati di output. Sono supportati i formati JSON, CSV e Avro. |
| Codifica | Al momento UTF-8 è l'unico formato di codifica supportato per i formati CSV e JSON. |
| Delimitatore | Applicabile solo per la serializzazione CSV. Analisi di flusso supporta una serie di delimitatori comuni per la serializzazione dei dati in formato CSV. I valori supportati sono virgola, punto e virgola, spazio, tabulazione e barra verticale. |
| Format | Applicabile solo per la serializzazione JSON. Separato da righe specifica che l'output viene formattato separando ciascun oggetto JSON con una nuova riga. Se si seleziona Separato da righe, JSON viene letto un oggetto alla volta. L'intero contenuto non è di per sé un oggetto JSON valido. Matrice specifica che l'output viene formattato come matrice di oggetti JSON. |
| Colonne delle proprietà | Facoltativa. Colonne delimitate da virgole che devono essere associate come proprietà utente del messaggio in uscita anziché del payload. Altre informazioni su questa funzionalità sono illustrate nella sezione Proprietà dei metadati personalizzati per l'output. |
Partizionamento
Il partizionamento varia a seconda dell'allineamento della partizione. Quando la chiave di partizione per l'output dell'hub eventi è ugualmente allineata al passaggio di query upstream (precedente), il numero di writer è uguale al numero di partizioni dell'hub eventi. Ogni writer usa la classe EventHubSender, per inviare eventi alla partizione specifica. Quando la chiave di partizione per l'output dell'hub eventi non è allineata al passaggio di query upstream (precedente), il numero di writer è uguale al numero di partizioni in tale passaggio precedente. Ogni writer usa la classe SendBatchAsync in EventHubClient, per inviare eventi a tutte le partizioni di output.
Dimensione del batch di output
La dimensione massima del messaggio è 256 KB o 1 MB per messaggio. Per altre informazioni, vedere Limiti di Hub eventi. Quando il partizionamento di input/output non è allineato, ogni evento viene inserito individualmente in EventData e inviato in un batch che può raggiungere le dimensioni massime del messaggio. Ciò si verifica anche se vengono usate proprietà dei metadati personalizzate. Quando il partizionamento di input/output è allineato, più eventi vengono inseriti in una singola istanza di EventData, fino alle dimensioni massime del messaggio, e inviati.
Proprietà dei metadati personalizzati per l'output
È possibile aggiungere colonne di query come proprietà utente ai messaggi in uscita. Queste colonne non vengono inserite nel payload. Le proprietà sono presenti sotto forma di dizionario nel messaggio di output. Key è il nome della colonna e value è il valore della colonna nel dizionario delle proprietà. Sono supportati tutti i tipi di dati di Analisi di flusso, ad eccezione di record e matrice.
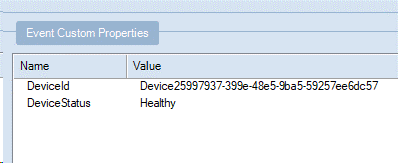
Nell'esempio seguente i campi DeviceId e DeviceStatus vengono aggiunti ai metadati.
Utilizzare la query seguente:
select *, DeviceId, DeviceStatus from iotHubInputConfigurare
DeviceId,DeviceStatuscome colonne di proprietà nell'output.
L'immagine seguente è delle proprietà del messaggio di output previste controllate in un hub eventi usando Esplora bus di servizio.
Esattamente una volta recapitata
Esattamente una volta che il recapito è supportato nell'output di Hub eventi per impostazione predefinita. Indipendentemente dall'input, Analisi di flusso garantisce alcuna perdita di dati o nessun duplicato in un output di Hub eventi, nei riavvii avviati dall'utente dall'ultima ora di output, impedendo la produzione di duplicati. Ciò semplifica notevolmente la pipeline di streaming senza dover monitorare, implementare e risolvere i problemi di logica di deduplicazione.