Esercitazione: Acquisire i dati di Hub eventi in formato parquet e analizzare con Azure Synapse Analytics
Questa esercitazione illustra come usare l'editor di analisi di flusso senza editor di codice per creare un processo che acquisisce i dati di Hub eventi in per Azure Data Lake Storage Gen2 in formato parquet.
In questa esercitazione verranno illustrate le procedure per:
- Distribuire un generatore di eventi che invia eventi di esempio a un hub eventi
- Creare un processo di Analisi di flusso usando l'editor di codice non
- Esaminare i dati di input e lo schema
- Configurare Azure Data Lake Storage Gen2 a cui verranno acquisiti i dati dell'hub eventi
- Eseguire il processo di Analisi di flusso
- Usare Azure Synapse Analytics per eseguire query sui file parquet
Prima di iniziare, assicurarsi di aver completato la procedura seguente:
- Se non si ha una sottoscrizione di Azure, creare un account gratuito.
- Distribuire l'app generatore di eventi TollApp in Azure. Impostare il parametro 'interval' su 1 e usare un nuovo gruppo di risorse per questo passaggio.
- Creare un'area di lavoro Azure Synapse Analytics con un account Data Lake Storage Gen2.
Individuare il gruppo di risorse in cui è stato distribuito il generatore di eventi TollApp.
Selezionare lo spazio dei nomi Hub eventi di Azure.
Nella pagina Spazio dei nomi hub eventi selezionare Hub eventi in Entità nel menu a sinistra.
Selezionare
entrystreamistanza.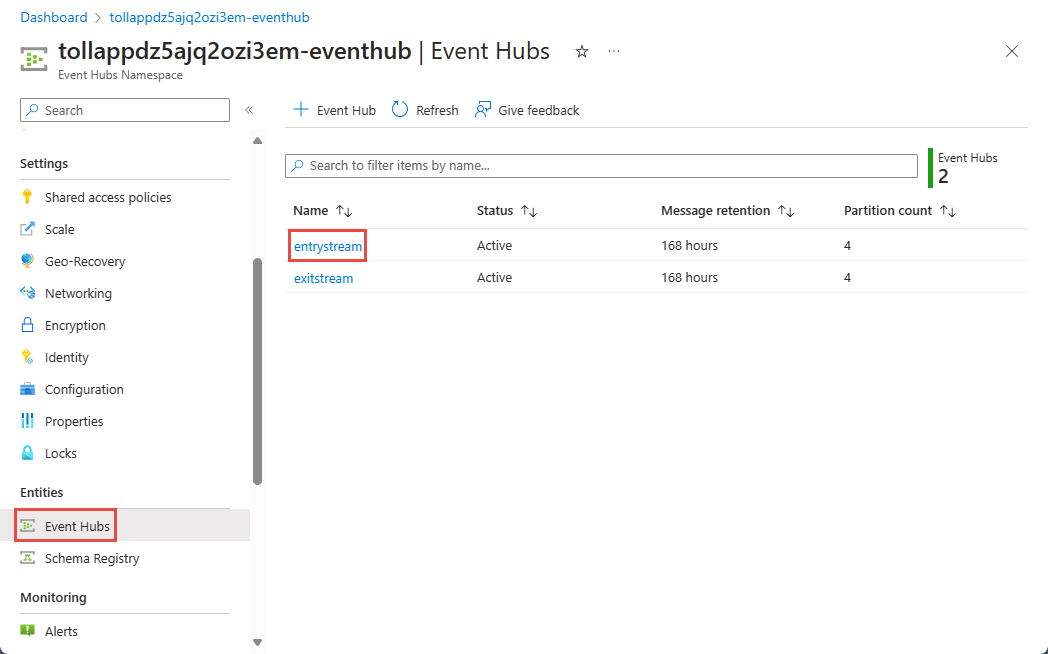
Nella pagina Dell'istanza di Hub eventi selezionare Elabora dati nella sezione Funzionalità nel menu a sinistra.
Selezionare Avvia nel riquadro Acquisisci dati in ADLS Gen2 nel riquadro Formato Parquet .
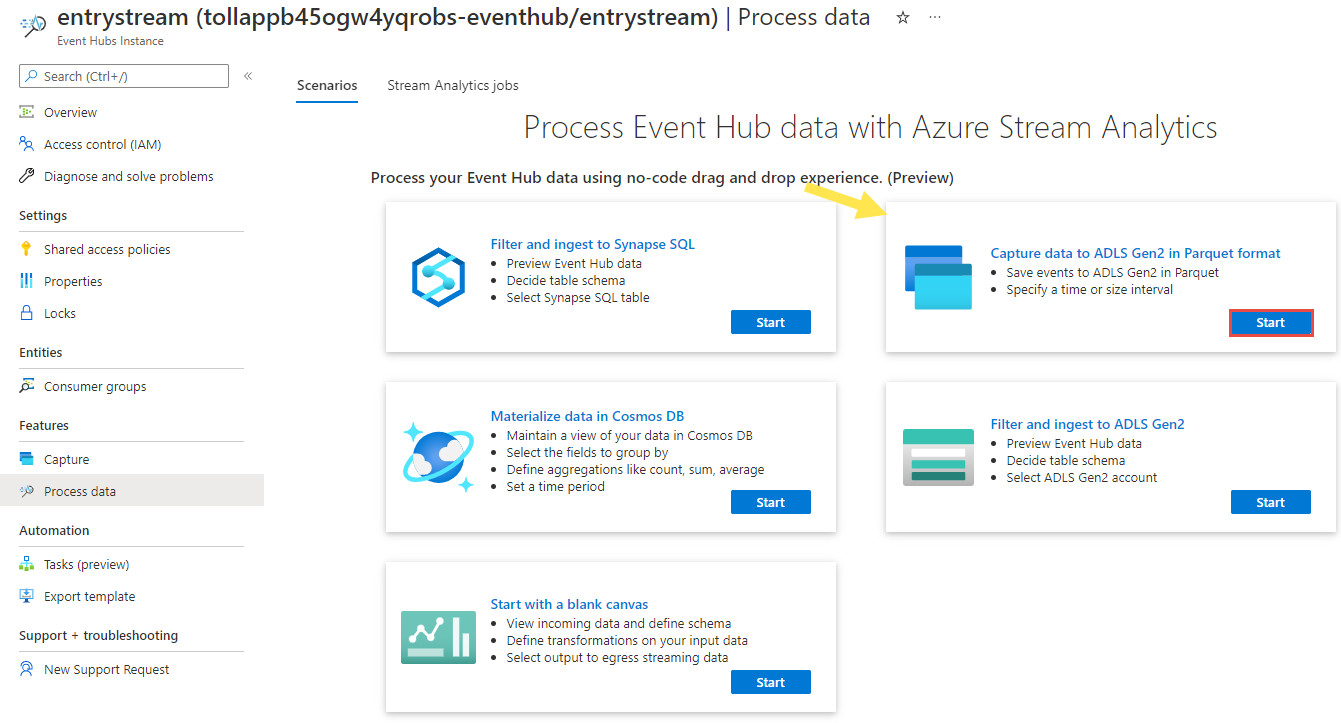
Assegnare un nome al processo
parquetcapturee selezionare Crea.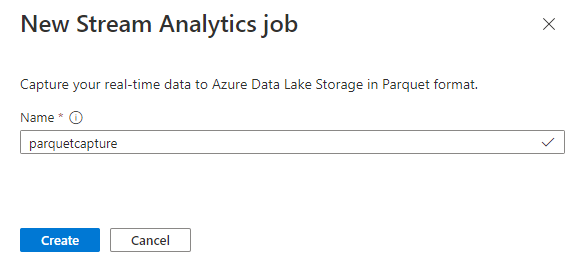
Nella pagina di configurazione dell'hub eventi confermare le impostazioni seguenti e quindi selezionare Connetti.
Gruppo consumer: impostazione predefinita
Tipo di serializzazione dei dati di input: JSON
Modalità di autenticazione che il processo userà per connettersi all'hub eventi: stringa di connessione.
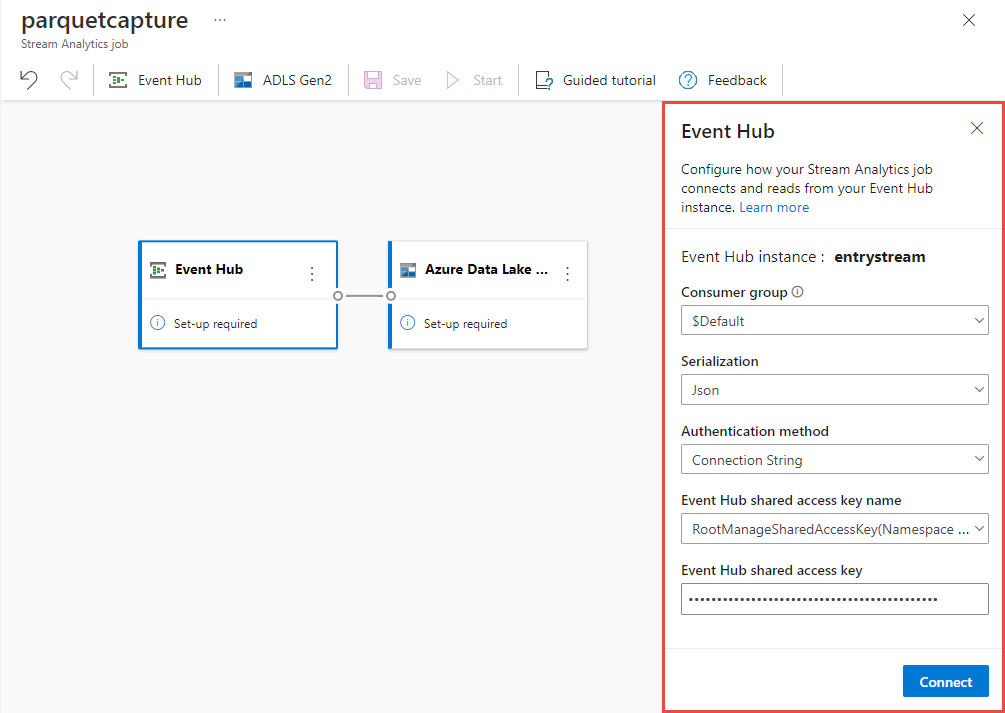
Entro pochi secondi, verranno visualizzati i dati di input di esempio e lo schema. È possibile scegliere di eliminare campi, rinominare campi o modificare il tipo di dati.
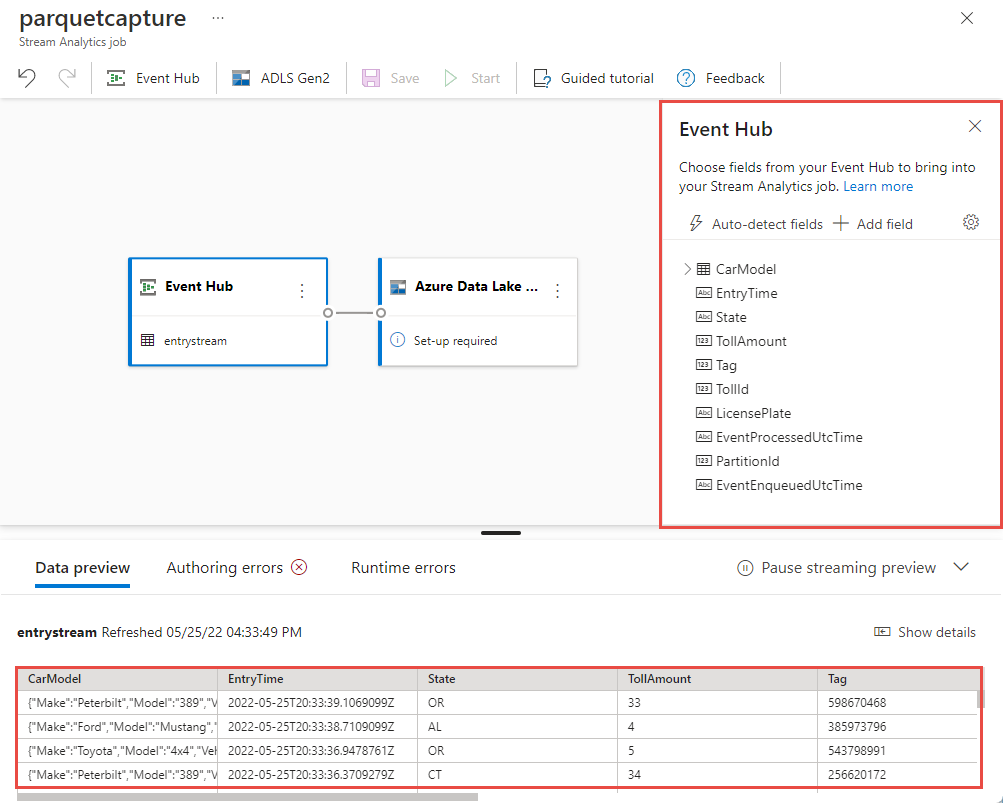
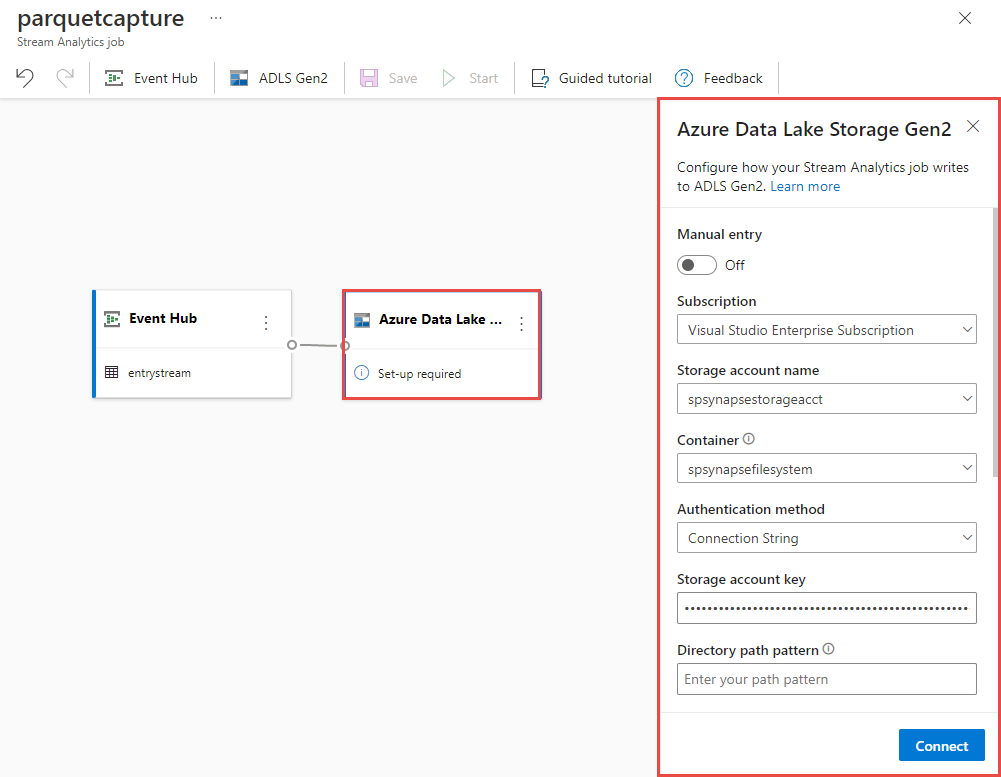
Selezionare il riquadro Azure Data Lake Storage Gen2 nell'area di disegno e configurarlo specificando
- Sottoscrizione in cui si trova l'account Azure Data Lake Gen2
- Nome dell'account di archiviazione, che deve essere lo stesso account ADLS Gen2 usato con l'area di lavoro Azure Synapse Analytics eseguita nella sezione Prerequisiti.
- Contenitore all'interno del quale verranno creati i file Parquet.
- Modello di percorso impostato su {date}/{time}
- Modello di data e ora come valore predefinito aaa-mm-gg e HH.
- Selezionare Connetti.
Selezionare Salva nella barra multifunzione superiore per salvare il processo e quindi selezionare Avvia per eseguire il processo. Dopo l'avvio del processo, selezionare X nell'angolo destro per chiudere la pagina del processo di Analisi di flusso .
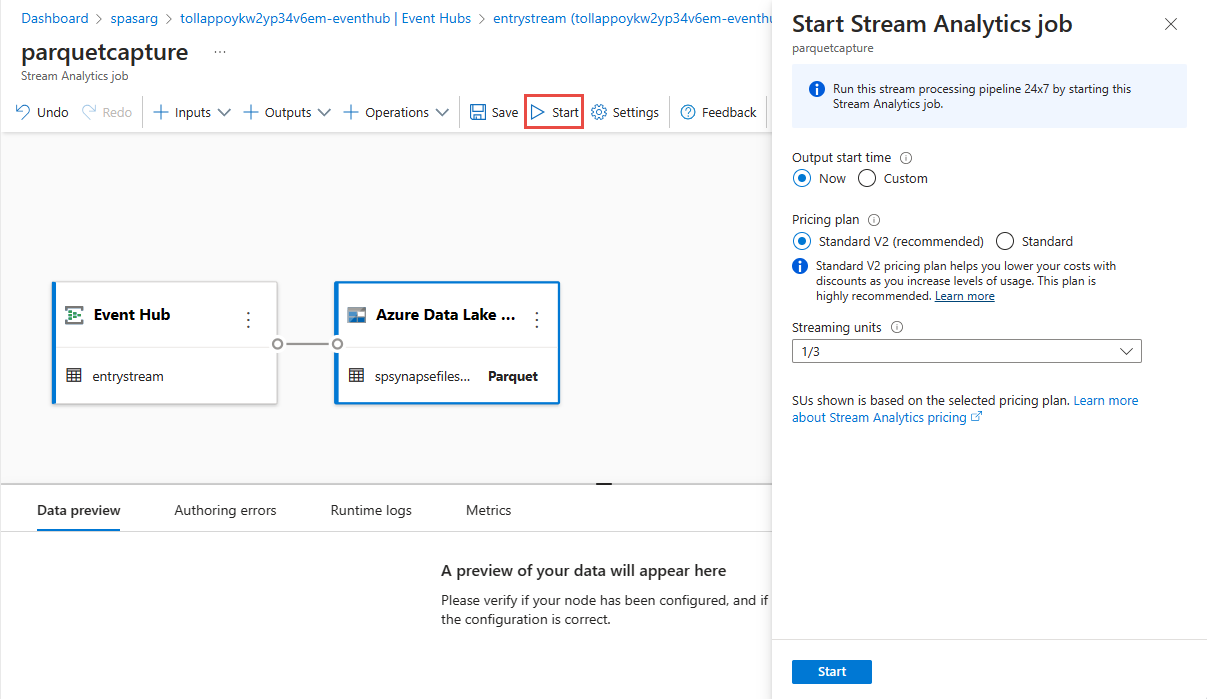
Verrà quindi visualizzato un elenco di tutti i processi di Analisi di flusso creati usando l'editor di codice no. E entro due minuti, il processo passerà a uno stato In esecuzione . Selezionare il pulsante Aggiorna nella pagina per visualizzare lo stato che cambia da Create - Starting ->> Running.
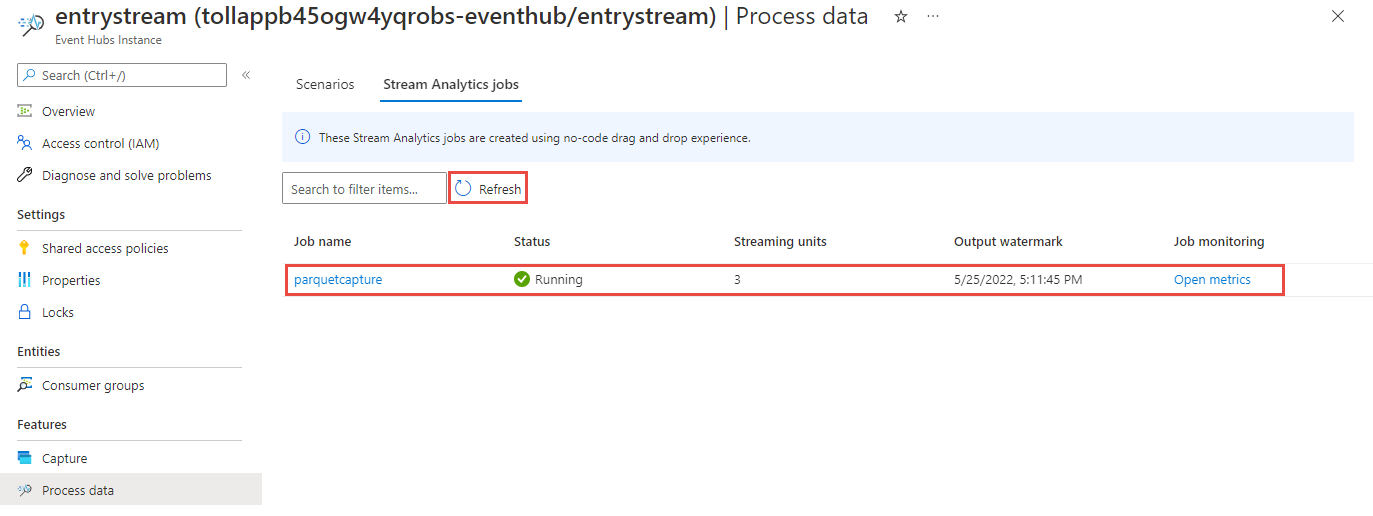








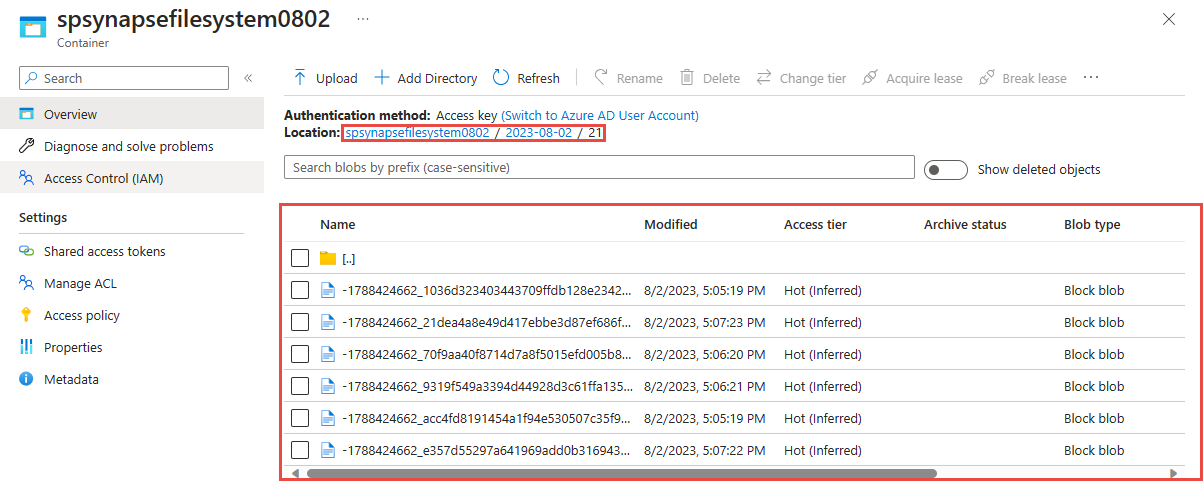
Individuare l'account Azure Data Lake Storage Gen2 usato nel passaggio precedente.
Selezionare il contenitore usato nel passaggio precedente. I file parquet verranno creati in base al modello di percorso {date}/{time} usato nel passaggio precedente.
Individuare l'area di lavoro Azure Synapse Analytics e aprire Synapse Studio.
Creare un pool Apache Spark serverless nell'area di lavoro se non esiste già.
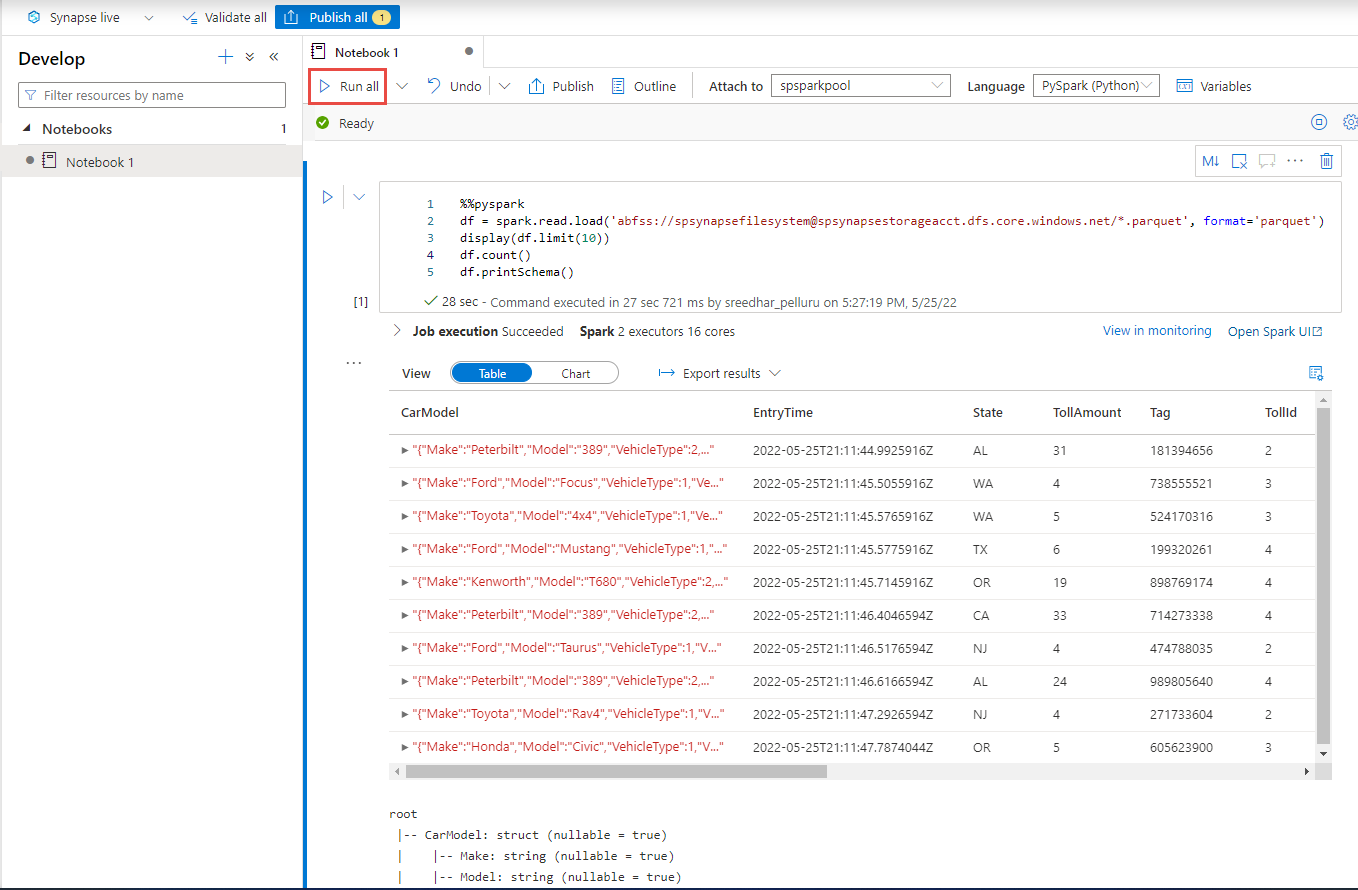
Nella Synapse Studio passare all'hub Sviluppo e creare un nuovo notebook.
Creare una nuova cella di codice e incollare il codice seguente in tale cella. Sostituire contenitore e adlsname con il nome del contenitore e dell'account ADLS Gen2 usato nel passaggio precedente.
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()Per Collega a sulla barra degli strumenti, selezionare il pool Spark dall'elenco a discesa.
Selezionare Esegui tutto per visualizzare i risultati

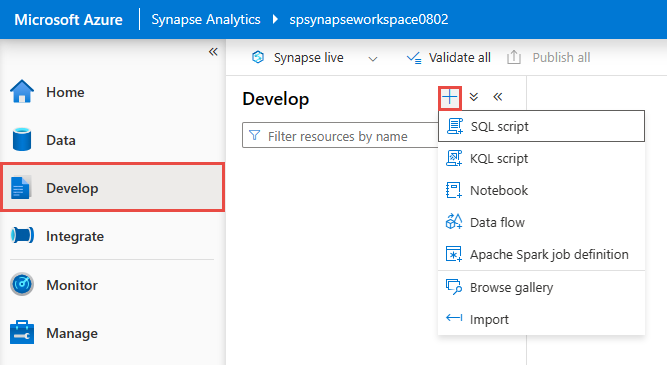
Nell'hub Di sviluppo creare un nuovo script SQL.
Incollare lo script seguente ed eseguirlo usando l'endpoint SQL serverless predefinito . Sostituire contenitore e adlsname con il nome del contenitore e dell'account ADLS Gen2 usato nel passaggio precedente.
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*/*.parquet', FORMAT='PARQUET' ) AS [result]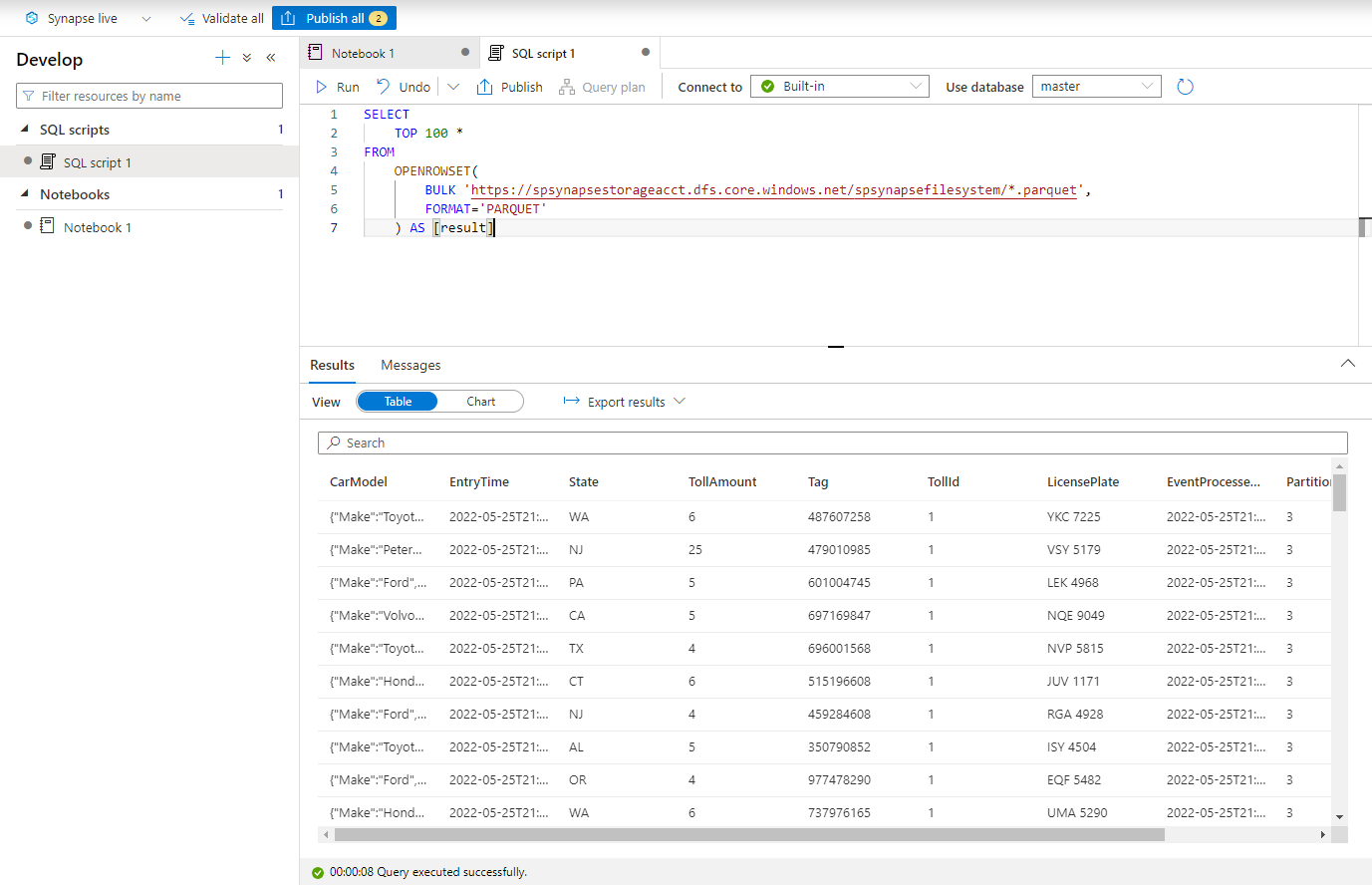

- Individuare l'istanza di Hub eventi e visualizzare l'elenco dei processi di Analisi di flusso nella sezione Elabora dati . Arrestare tutti i processi in esecuzione.
- Passare al gruppo di risorse usato durante la distribuzione del generatore di eventi TollApp.
- Selezionare Elimina gruppo di risorse. Digitare il nome del gruppo di attività per confermare l'eliminazione.
In questa esercitazione si è appreso come creare un processo di Analisi di flusso usando l'editor di codice per acquisire i flussi di dati di Hub eventi in formato Parquet. È stata quindi usata Azure Synapse Analytics per eseguire query sui file parquet usando Synapse Spark e Synapse SQL.