Usare l'editor senza codice di Analisi di flusso di Azure per trasformare e archiviare i dati nel database SQL di Azure
Questo articolo descrive come usare l'editor di codice senza creare facilmente un processo di Analisi di flusso, che legge continuamente i dati da un'istanza di Hub eventi (hub eventi), trasforma i dati e quindi scrive i risultati in un database SQL di Azure.
Prerequisiti
Le risorse Hub eventi di Azure e database SQL di Azure devono essere accessibili pubblicamente e non essere protette da un firewall o protette in un'Rete virtuale di Azure. I dati negli hub eventi devono essere serializzati in formato JSON, CSV o Avro.
Per provare i passaggi descritti in questo articolo, seguire questa procedura.
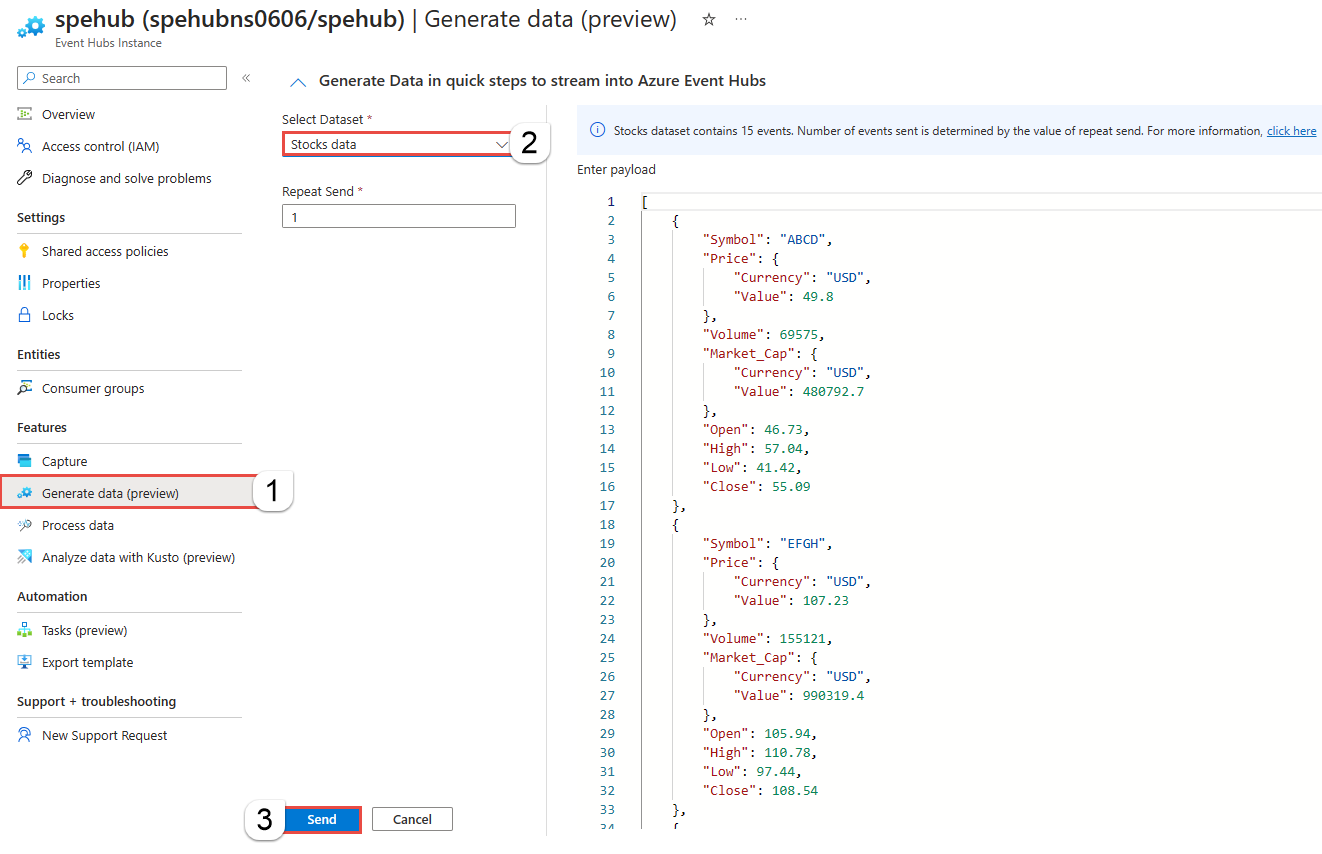
Creare un hub eventi se non ne è già disponibile uno. Generare dati nell'hub eventi. Nella pagina Istanza di Hub eventi selezionare Genera dati (anteprima) nel menu a sinistra, selezionare Dati titoli per Set di dati e quindi selezionare Invia per inviare alcuni dati di esempio all'hub eventi. Questo passaggio è obbligatorio se si vuole testare i passaggi in questo articolo.
Creare un database SQL Azure. Ecco alcuni aspetti importanti da notare durante la creazione del database.
Nella pagina Informazioni di base selezionare Crea nuovo per Server. Quindi, nella pagina Crea database SQL server selezionare Usa autenticazione SQL e specificare l'ID utente amministratore e la password.
Nella pagina Rete seguire questa procedura:
- Abilitare Endpoint pubblico.
- Selezionare Sì per Consenti alle risorse e ai servizi di Azure di accedere a questo server.
- Selezionare Sì per Aggiungi indirizzo IP client corrente.
Nella pagina Impostazioni aggiuntive selezionare Nessuno per Usa dati esistenti.
Nell'articolo ignorare i passaggi nelle sezioni Eseguire query sul database e Pulire le risorse .
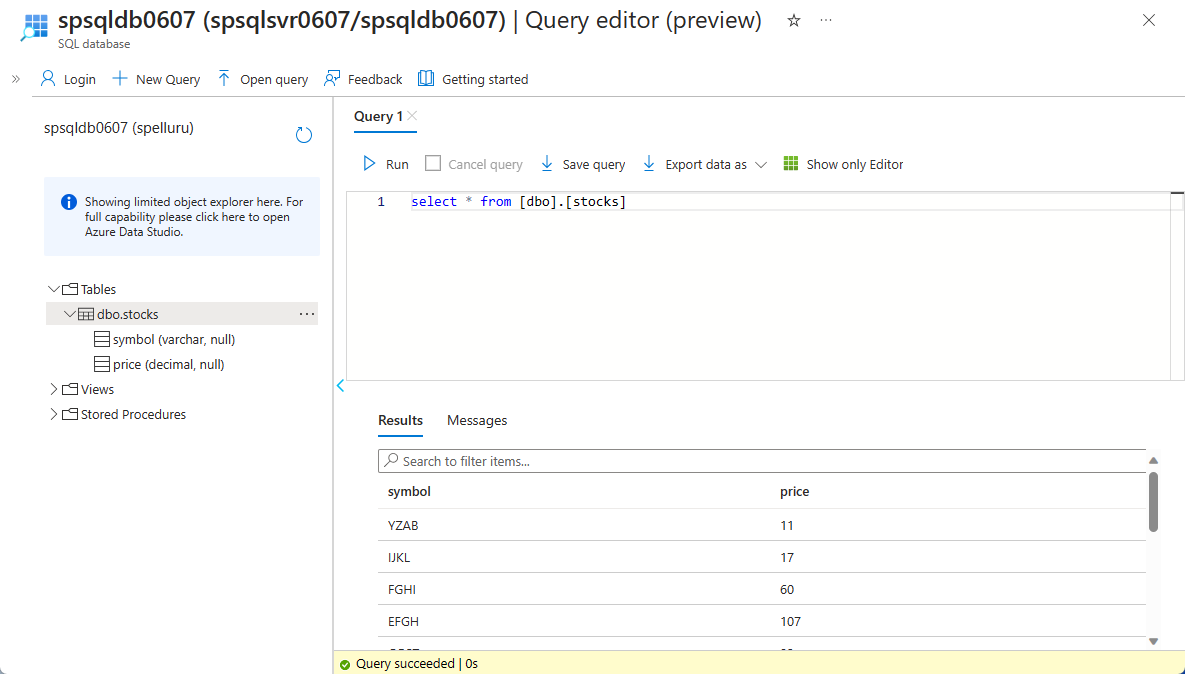
Per testare i passaggi, creare una tabella nel database SQL usando l'editor di query (anteprima).
create table stocks ( symbol varchar(4), price decimal )

Usare l'editor senza codice per creare un processo di Analisi di flusso
In questa sezione viene creato un processo di Analisi di flusso di Azure usando l'editor senza codice. Il processo trasforma lo streaming dei dati da un'istanza di Hub eventi (hub eventi) e archivia i dati dei risultati in un database SQL di Azure.
Nella portale di Azure passare alla pagina Istanza di Hub eventi per l'hub eventi.
Selezionare Funzionalità>Elabora dati nel menu a sinistra e quindi selezionare Avvia nella scheda Trasforma e archivia i dati nel database SQL.
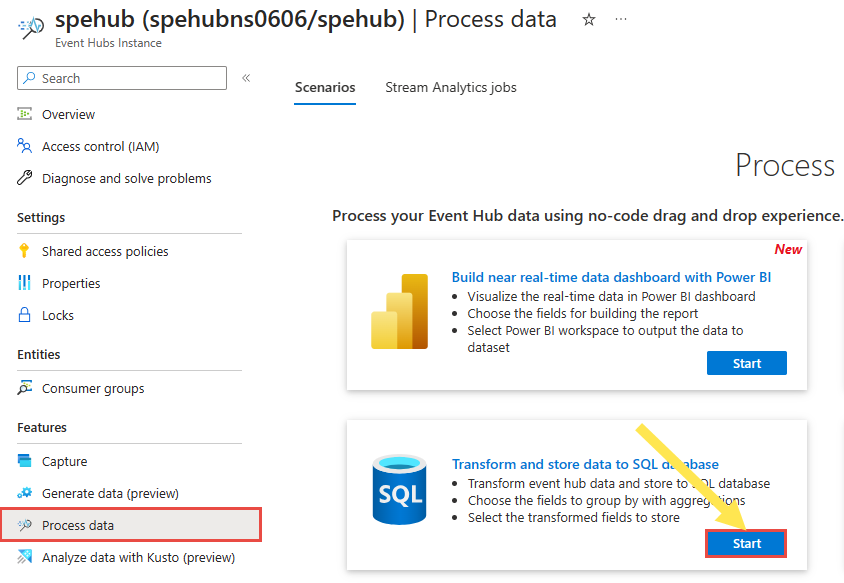
Immettere un nome per il processo di Analisi di flusso e quindi selezionare Crea. Viene visualizzato il diagramma dei processi di Analisi di flusso con la finestra di Hub eventi a destra.
Nella finestra Hub eventi esaminare Le impostazioni di serializzazione e modalità di autenticazione e selezionare Connetti.
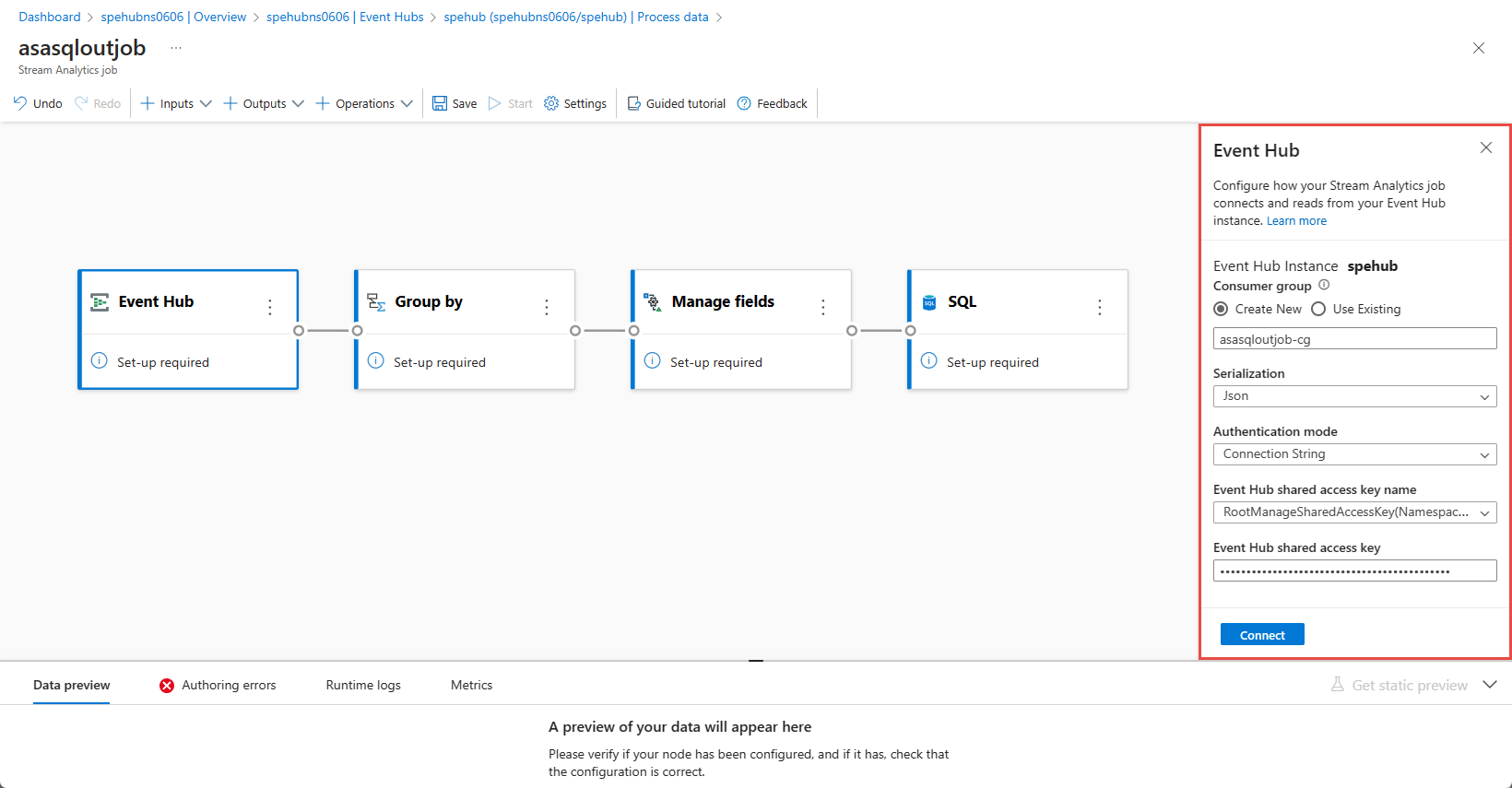
Quando la connessione viene stabilita correttamente e si dispone di dati nell'istanza di Hub eventi, vengono visualizzati due elementi:
Campi presenti nei dati di input. È possibile scegliere Aggiungi campo oppure selezionare il simbolo a tre punti accanto a un campo per rimuovere, rinominare o modificarne il tipo.
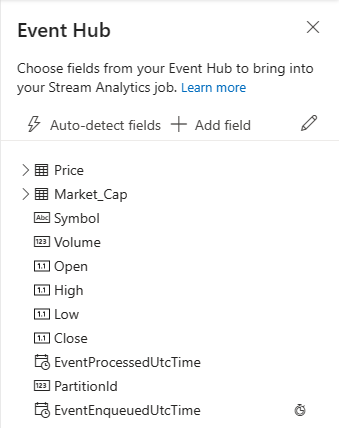
Esempio live di dati in ingresso nella tabella Anteprima dati nella vista diagramma. Viene aggiornato automaticamente periodicamente. È possibile selezionare Sospendi anteprima streaming per visualizzare una visualizzazione statica dei dati di input di esempio.

Selezionare il riquadro Raggruppa per per aggregare i dati. Nel pannello Raggruppa per configurazione è possibile specificare il campo da raggruppare insieme all'intervallo di tempo.
Nell'esempio seguente viene usata la media del prezzo e del simbolo.
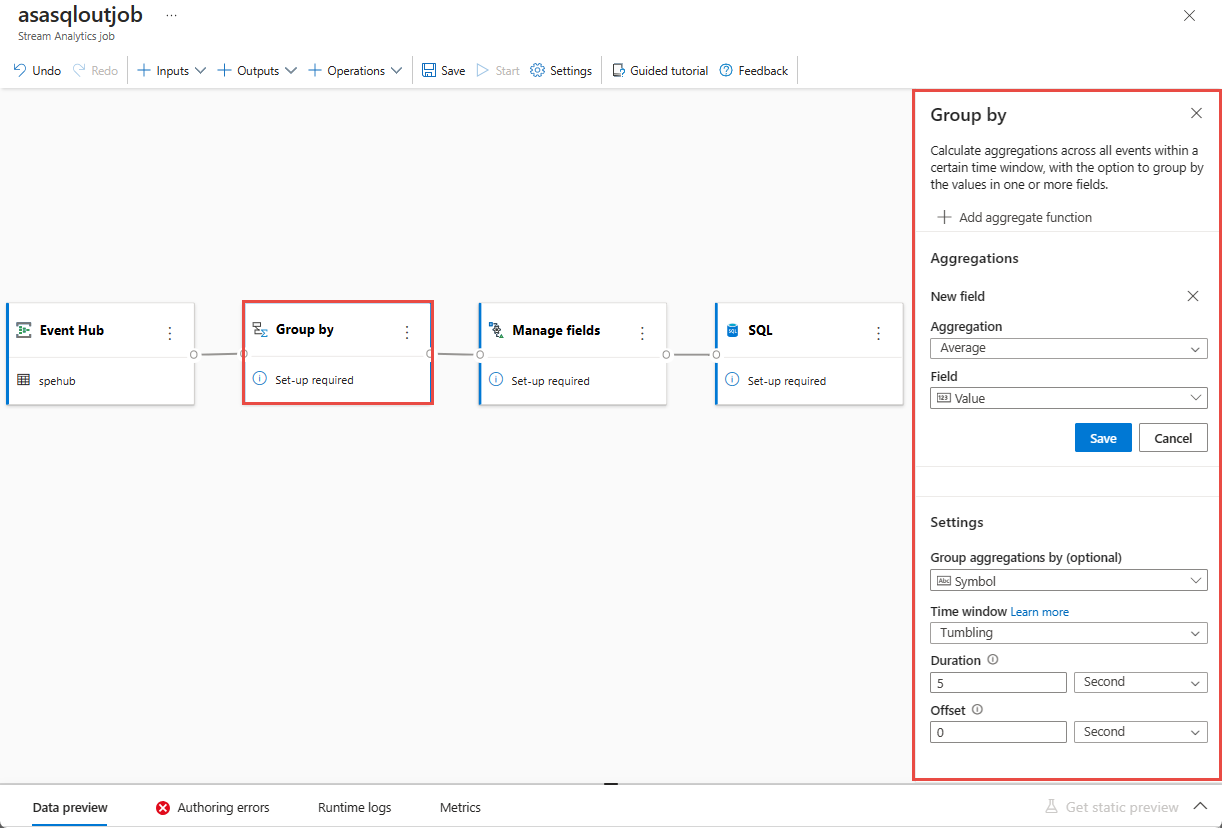
È possibile convalidare i risultati del passaggio nella sezione Anteprima dati.

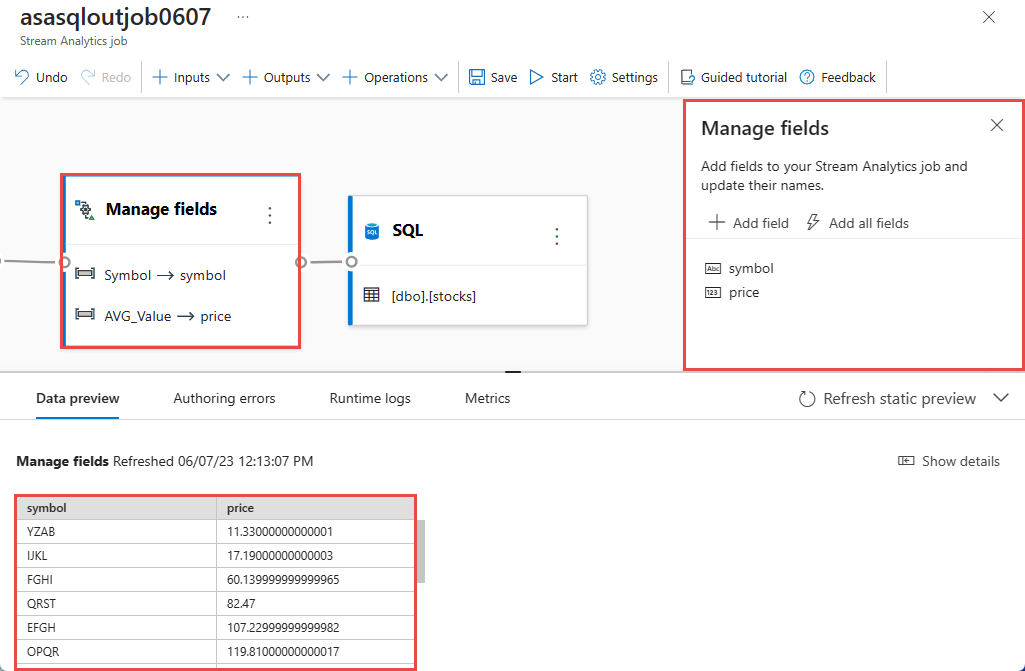
Selezionare il riquadro Gestisci campi . Nel pannello Di configurazione Gestisci campi scegliere i campi da restituire selezionando Aggiungi campo ->Schema importato -> campo.
Per aggiungere tutti i campi, selezionare Aggiungi tutti i campi. Durante l'aggiunta di un campo, è possibile specificare un nome diverso per l'output. Ad esempio,
AVG_Valueviene convertito inValue. Dopo aver salvato le selezioni, i dati vengono visualizzati nel riquadro Anteprima dati.Nell'esempio seguente vengono selezionati Simbolo e AVG_Value . Il simbolo viene mappato al simbolo e AVG_Value viene mappato al prezzo.
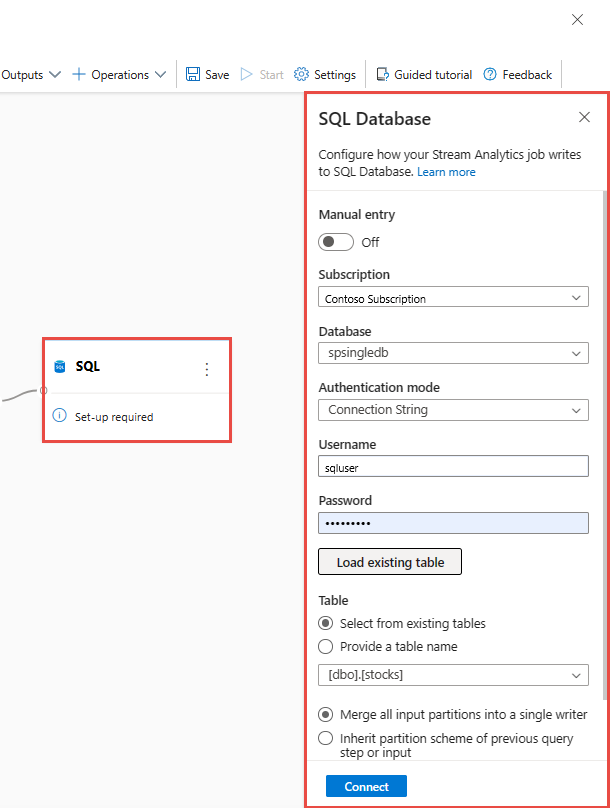
Selezionare il riquadro SQL . Nel pannello di configurazione database SQL compilare i parametri necessari e connettersi. Selezionare Carica tabella esistente per selezionare automaticamente la tabella. Nell'esempio
[dbo].[stocks]seguente viene selezionata l'opzione . Selezionare Connect (Connetti).Nota
Lo schema della tabella che si sceglie di scrivere deve corrispondere esattamente al numero di campi e ai relativi tipi generati dall'anteprima dei dati.
Nel riquadro Anteprima dati viene visualizzata l'anteprima dei dati inserita nel database SQL.

Selezionare Salva e quindi avviare il processo di Analisi di flusso.

Per avviare il processo, specificare:
Numero di unità di streaming (UNITÀ di streaming) con cui viene eseguito il processo. Le unità di streaming rappresentano la quantità di calcolo e memoria allocata al processo. È consigliabile iniziare con tre e quindi regolare in base alle esigenze.
Gestione degli errori dei dati di output: consente di specificare il comportamento desiderato quando l'output di un processo nella destinazione non riesce a causa di errori di dati. Per impostazione predefinita, il processo ritenta fino a quando l'operazione di scrittura non riesce. È anche possibile scegliere di eliminare tali eventi di output.

Dopo aver selezionato Avvia, il processo viene avviato entro due minuti. Il pannello delle metriche viene visualizzato nel riquadro inferiore aperto. L'aggiornamento del pannello richiede tempo. Selezionare Aggiorna nell'angolo superiore destro del pannello per aggiornare il grafico. Passare al passaggio successivo in una scheda o una finestra separata del Web browser.
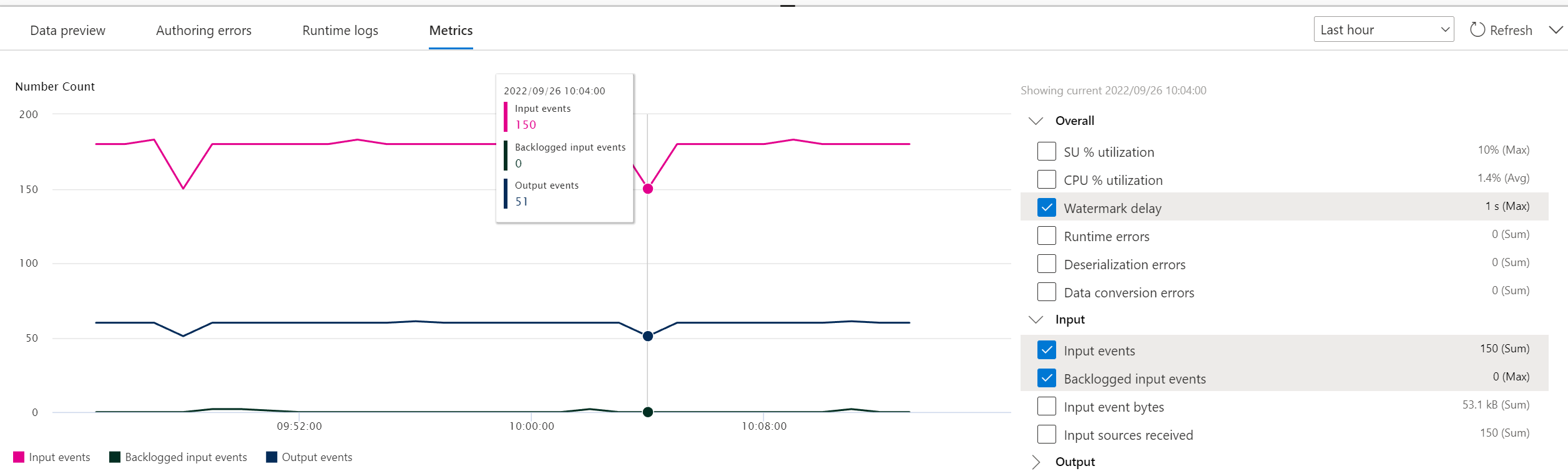
È anche possibile visualizzare il processo nella sezione Elabora dati nella scheda Processi di Analisi di flusso. Selezionare Apri metriche per monitorarlo o arrestarlo e riavviarlo in base alle esigenze.

Passare all'hub eventi nel portale in una finestra o scheda separata del browser e inviare di nuovo i dati delle scorte di esempio (come nei prerequisiti). Nella pagina Istanza di Hub eventi selezionare Genera dati (anteprima) nel menu a sinistra, selezionare Dati titoli per Set di dati e quindi selezionare Invia per inviare alcuni dati di esempio all'hub eventi. L'aggiornamento del pannello Metriche richiede alcuni minuti.
Verranno visualizzati i record inseriti nel database SQL di Azure.















Considerazioni sull'uso della funzionalità di replica geografica di Hub eventi
Hub eventi di Azure recentemente lanciato il Funzionalità replica geografica in anteprima pubblica. Questa funzionalità è diversa dalla funzionalità ripristino di emergenza geografico di Hub eventi di Azure.
Quando il tipo di failover è Forzato e la coerenza della replica è asincrona, il processo di Analisi di flusso non garantisce esattamente una volta l'output in un output Hub eventi di Azure.
Analisi di flusso di Azure, come producer con un output di un hub eventi, potrebbe osservare un ritardo limite nel processo durante la durata del failover e durante la limitazione da parte di Hub eventi nel caso in cui il ritardo di replica tra primario e secondario raggiunga il ritardo massimo configurato.
Analisi di flusso di Azure, come consumer con Hub eventi come input, potrebbe osservare un ritardo limite nel processo durante la durata del failover e potrebbe ignorare i dati o trovare dati duplicati al termine del failover.
A causa di queste avvertenze, è consigliabile riavviare il processo di Analisi di flusso con l'ora di inizio appropriata subito dopo il completamento del failover di Hub eventi. Inoltre, poiché la funzionalità di replica geografica di Hub eventi è in anteprima pubblica, non è consigliabile usare questo modello per i processi di Analisi di flusso di produzione a questo punto. Il comportamento corrente di Analisi di flusso migliorerà prima che la funzionalità di replica geografica di Hub eventi sia disponibile a livello generale e possa essere usata nei processi di produzione di Analisi di flusso.
Passaggi successivi
Altre informazioni su Analisi di flusso di Azure e su come monitorare il processo creato.