Risolvere i problemi delle connessioni di input
Questo articolo descrive i problemi comuni relativi alle connessioni di input di Analisi di flusso di Azure e come correggere i problemi. Molti passaggi per la risoluzione dei problemi richiedono l'abilitazione dei log delle risorse per il processo di Analisi di flusso. Se i log delle risorse non sono abilitati, vedere Risolvere i problemi di Analisi di flusso di Azure usando i log delle risorse.
Eventi di input non ricevuti dal processo
Testare la connettività di input e output. Verificare la connettività agli input e output con il pulsante Verifica connessione per ogni input e output.
Esaminare i dati di input.
Usare il pulsante Dati di esempio per ogni input. Scaricare i dati di esempio dell'input.
Esaminare i dati di esempio per comprendere lo schema e i tipi di dati.
Monitorare le metriche di Hub eventi per verificare che vengano inviati gli eventi. Se Hub eventi riceve i messaggi, le metriche per i messaggi devono essere maggiori di zero.
Verificare di aver selezionato un intervallo di tempo nell'anteprima input. Scegliere Seleziona intervallo di tempo e quindi immettere una durata di esempio prima di testare la query.
Importante
Per i processi ASA non inseriti in rete, non fare affidamento sull'indirizzo IP di origine delle connessioni provenienti da ASA in alcun modo. Possono essere indirizzi IP pubblici o privati a seconda delle operazioni dell'infrastruttura del servizio che si verificano di tanto in tanto.
Eventi di input in formato non valido determinano errori di deserializzazione
Quando il flusso di input del processo di Analisi di flusso di Azure contiene messaggi in formato non valido, si verificano problemi di deserializzazione. Un messaggio in formato non valido può essere causato, ad esempio, da una parentesi mancante in un oggetto JSON o da un formato di timestamp errato nel campo dell'ora.
Quando un processo di Analisi di flusso di Azure riceve un messaggio in formato non valido da un input, elimina il messaggio e visualizza un messaggio di avviso. Viene visualizzato un simbolo di avviso nel riquadro Input del processo di Analisi di flusso di Azure. Il simbolo di avviso seguente rimane finché il processo è in esecuzione:
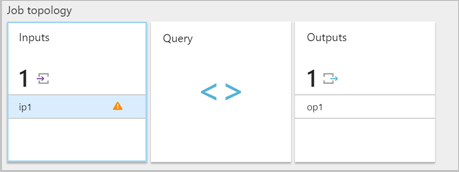
Abilitare i log delle risorse per visualizzare i dettagli dell'errore e il messaggio (payload) che ha generato l'errore. Gli errori di deserializzazione possono verificarsi per diversi motivi. Per altre informazioni relative a errori di deserializzazione specifici, vedere Errori dei dati di input. Se i log delle risorse non sono abilitati, nel portale di Azure verrà visualizzata una breve notifica.
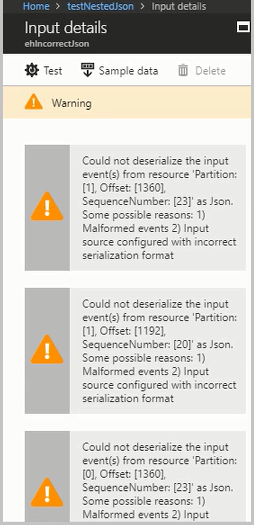
Se il payload del messaggio è superiore a 32 kB o è in formato binario, eseguire il codice CheckMalformedEvents.cs disponibile nel repository degli esempi di GitHub. Questo codice legge l'ID della partizione, l'offset e stampa i dati presenti nell'offset.
Altri motivi comuni che causano errori di deserializzazione di input sono:
- Colonna Integer con un valore maggiore di 9223372036854775807.
- Stringhe anziché matrice di oggetti o oggetti separati da righe. Esempio valido: [{'a':1}]. Esempio non valido: "'a' :1"..
- L'uso di Hub eventi acquisisce BLOB in formato Avro come input nel processo.
- Avere due colonne in un singolo evento di input che differiscono solo nel caso. Esempio: column1 e COLUMN1.
Modifiche al numero di partizioni
È possibile modificare il numero di partizioni di Hub eventi. Il processo di Analisi di flusso deve essere arrestato e avviato di nuovo se il numero di partizioni dell'hub eventi viene modificato.
Quando il numero di partizioni dell'hub eventi viene modificato quando il processo è in esecuzione, vengono visualizzati gli errori seguenti. Microsoft.Streaming.Diagnostics.Exceptions.InputPartitioningChangedException
Il processo supera il numero massimo di ricevitori di Hub eventi
Una procedura consigliata per l'utilizzo di Hub eventi consiste nell'usare più gruppi di consumer per la scalabilità del processo. Il numero di lettori del processo di Analisi di flusso di Azure per uno specifico input influisce sul numero dei lettori di un singolo gruppo di consumer. Il numero esatto di ricevitori si basa sui dettagli di implementazione interna per la logica della topologia con scale-out e non viene esposto esternamente. Il numero di lettori può cambiare al momento di avvio del processo o durante gli aggiornamenti del processo.
Quando la quantità di ricevitori supera il numero massimo, vengono visualizzati i messaggi di errore seguenti. Il messaggio di errore include un elenco di connessioni esistenti effettuate a Hub eventi in un gruppo di consumer. Il tag AzureStreamAnalytics indica che le connessioni provengono dal servizio di streaming di Azure.
The streaming job failed: Stream Analytics job has validation errors: Job will exceed the maximum amount of Event Hubs Receivers.
The following information may be helpful in identifying the connected receivers: Exceeded the maximum number of allowed receivers per partition in a consumer group which is 5. List of connected receivers –
AzureStreamAnalytics_c4b65e4a-f572-4cfc-b4e2-cf237f43c6f0_1,
AzureStreamAnalytics_c4b65e4a-f572-4cfc-b4e2-cf237f43c6f0_1,
AzureStreamAnalytics_c4b65e4a-f572-4cfc-b4e2-cf237f43c6f0_1,
AzureStreamAnalytics_c4b65e4a-f572-4cfc-b4e2-cf237f43c6f0_1,
AzureStreamAnalytics_c4b65e4a-f572-4cfc-b4e2-cf237f43c6f0_1.
Nota
Quando il numero di lettori cambia durante un aggiornamento del processo, vengono scritti avvisi temporanei nei log di controllo. I processi di Analisi di flusso vengono ripristinati automaticamente da questi problemi temporanei.
Aggiungere un gruppo di consumer negli hub eventi
Per aggiungere un nuovo gruppo di consumer all'istanza dell'hub eventi, seguire questa procedura:
Accedere al portale di Azure.
Individuare il proprio hub eventi.
Selezionare Hub eventi nell'intestazione Entità.
Selezionare l'hub eventi in base al nome.
Nella pagina Istanza di Hub eventi selezionare Gruppi di consumer nell'intestazione Entità. Viene elencato un gruppo di consumer denominato $Default.
Selezionare + Gruppo di consumer per aggiungere un nuovo gruppo di consumer.
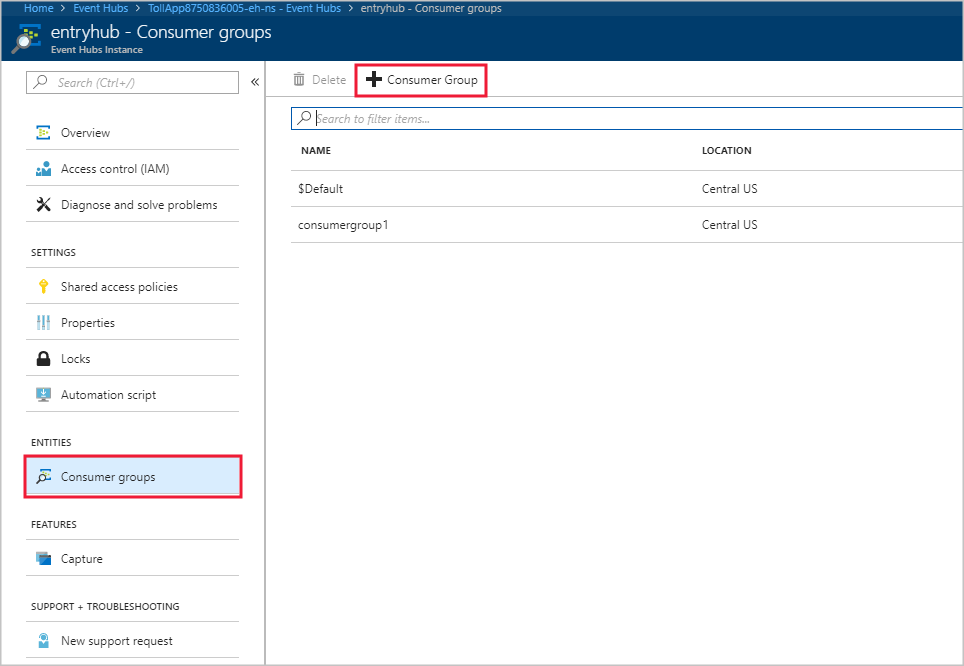
Quando l'utente ha creato l'input in Analisi di flusso affinché puntasse all'hub eventi, ha specificato il gruppo di consumer. $Default viene usato quando non è stato specificato alcun gruppo di consumer. Dopo aver creato un nuovo gruppo di consumer, modificare l'input dell'hub eventi nel processo di Analisi di flusso e specificare il nome del nuovo gruppo di consumer.
Il numero di lettori per partizione supera il limite impostato in Hub eventi di Azure
Se la sintassi delle query di streaming fa riferimento più volte alla stessa risorsa hub eventi di input, il motore di processi può usare più lettori per ogni query dello stesso gruppo di consumer. Quando ci sono troppi riferimenti allo stesso gruppo di consumer, il processo può superare il limite di cinque e generare un errore. In questo caso è possibile creare altre suddivisioni usando più input in più gruppi di consumer servendosi della soluzione descritta nella sezione seguente.
Gli scenari in cui il numero di lettori per ogni partizione supera il limite di cinque hub eventi comprendono i seguenti:
Più istruzioni SELECT: se si usano più istruzioni SELECT che fanno riferimento allo stesso input dell'hub eventi, ogni istruzione SELECT fa sì che venga creato un nuovo ricevitore.
UNION: quando si usa UNION, è possibile avere più input che si riferiscono allo stesso hub eventi e gruppo di consumer.
SELF JOIN: quando si usa un'operazione SELF JOIN è possibile fare riferimento allo stesso hub eventi più volte.
Le procedure consigliate seguenti possono aiutare a mitigare gli scenari in cui il numero di lettori per ogni partizione supera il limite di cinque hub eventi.
Suddividere la query in più passaggi usando una clausola WITH
La clausola WITH specifica un set di risultati con nome temporaneo a cui è possibile fare riferimento mediante una clausola FROM nella query. La clausola WITH viene definita nell'ambito di esecuzione di una singola istruzione SELECT.
Ad esempio, invece di questa query:
SELECT foo
INTO output1
FROM inputEventHub
SELECT bar
INTO output2
FROM inputEventHub
…
Usare questa query:
WITH data AS (
SELECT * FROM inputEventHub
)
SELECT foo
INTO output1
FROM data
SELECT bar
INTO output2
FROM data
…
Assicurarsi che gli input siano associati a gruppi di consumer diversi
Per le query in cui tre o più input sono connessi allo stesso gruppo di consumer di hub eventi, creare gruppi di consumer separati. Ciò richiede la creazione di input di Analisi di flusso aggiuntivi.
Creare input separati con gruppi di consumer diversi
È possibile creare input separati con gruppi di consumer diversi per lo stesso hub eventi. La query UNION seguente è un esempio in cui InputOne e InputTwo fanno riferimento alla stessa origine di Hub eventi. Qualsiasi query può avere input separati con gruppi di consumer diversi. La query UNION è solo un esempio.
WITH
DataOne AS
(
SELECT * FROM InputOne
),
DataTwo AS
(
SELECT * FROM InputTwo
),
SELECT foo FROM DataOne
UNION
SELECT foo FROM DataTwo
I lettori per partizione superano hub IoT limite
I processi di Analisi di flusso usano l'endpoint compatibile con Hub eventi predefinito di hub IoT per connettersi e leggere gli eventi da hub IoT. Se la lettura per partizione supera i limiti di hub IoT, è possibile usare le soluzioni per Hub eventi per risolverlo. È possibile creare un gruppo di consumer per l'endpoint predefinito tramite hub IoT sessione dell'endpoint del portale o tramite hub IoT SDK.
Come ottenere assistenza
Per maggiore supporto, provare la Pagina delle domande di Domande e risposte Microsoft per Analisi di flusso di Azure.
Passaggi successivi
- Introduzione ad Analisi dei flussi di Azure
- Introduzione all'uso di Analisi dei flussi di Azure
- Ridimensionare i processi di Analisi dei flussi di Azure
- Informazioni di riferimento sul linguaggio di query di Analisi di flusso di Azure
- Informazioni di riferimento sulle API REST di gestione di Analisi di flusso di Azure