Esercitazione: Accesso ai dati di Azure Synapse ADLS Gen2 in Azure Machine Learning
In questa esercitazione verrà illustrato il processo di accesso ai dati archiviati in Azure Synapse Azure Data Lake Storage Gen2 (ADLS Gen2) da Azure Machine Learning (Azure Machine Learning). Questa funzionalità è particolarmente utile quando si intende semplificare il flusso di lavoro di Machine Learning sfruttando strumenti come Machine Learning automatizzato, rilevamento integrato di modelli e esperimenti o hardware specializzato come GPU disponibili in Azure Machine Learning.
Per accedere ai dati di ADLS Gen2 in Azure Machine Learning, verrà creato un archivio dati di Azure Machine Learning che punta all'account di archiviazione azure Synapse ADLS Gen2.
Prerequisiti
- Un'area di lavoro di Azure Synapse Analytics. Assicurarsi di avere un account di archiviazione di Azure Data Lake Storage Gen2 configurato come risorsa archiviazione predefinita. Assicurarsi di avere il ruolo di Collaboratore ai dati del BLOB di archiviazione per il file system di Data Lake Storage Gen2 usato.
- Un'area di lavoro di Azure Machine Learning.
Installare le librerie
Prima di tutto, verrà installato il azure-ai-ml pacchetto.
%pip install azure-ai-ml
Creare un archivio dati
Azure Machine Learning offre una funzionalità nota come archivio dati, che funge da riferimento all'account di archiviazione di Azure esistente. Verrà creato un archivio dati che fa riferimento all'account di archiviazione azure Synapse ADLS Gen2.
In questo esempio si creerà un archivio dati collegato all'archiviazione di Azure Synapse ADLS Gen2. Dopo aver inizializzato un MLClient oggetto, è possibile fornire i dettagli di connessione all'account ADLS Gen2. Infine, è possibile eseguire il codice per creare o aggiornare l'archivio dati.
from azure.ai.ml.entities import AzureDataLakeGen2Datastore
from azure.ai.ml import MLClient
ml_client = MLClient.from_config()
# Provide the connection details to your Azure Synapse ADLSg2 storage account
store = AzureDataLakeGen2Datastore(
name="",
description="",
account_name="",
filesystem=""
)
ml_client.create_or_update(store)
Per altre informazioni sulla creazione e la gestione di archivi dati di Azure Machine Learning, vedere questa esercitazione negli archivi dati di Azure Machine Learning.
Montare l'account di archiviazione di ADLS Gen2
Dopo aver configurato l'archivio dati, è possibile accedere a questi dati creando un montaggio nell'account ADLSg2. In Azure Machine Learning, la creazione di un montaggio nell'account ADLS Gen2 comporta la creazione di un collegamento diretto tra l'area di lavoro e l'account di archiviazione, consentendo l'accesso facile ai dati archiviati all'interno. Essenzialmente, un montaggio funge da percorso che consente ad Azure Machine Learning di interagire con i file e le cartelle nell'account ADLS Gen2 come se fossero parte del file system locale all'interno dell'area di lavoro.
Dopo aver montato l'account di archiviazione, è possibile leggere, scrivere e modificare facilmente i dati archiviati in ADLS Gen2 usando operazioni di file system familiari direttamente nell'ambiente di Azure Machine Learning, semplificando la pre-elaborazione dei dati, il training del modello e le attività di sperimentazione.
A questo scopo, è necessario:
Avviare il motore di calcolo.
Selezionare Azioni dati e quindi selezionare Monta.
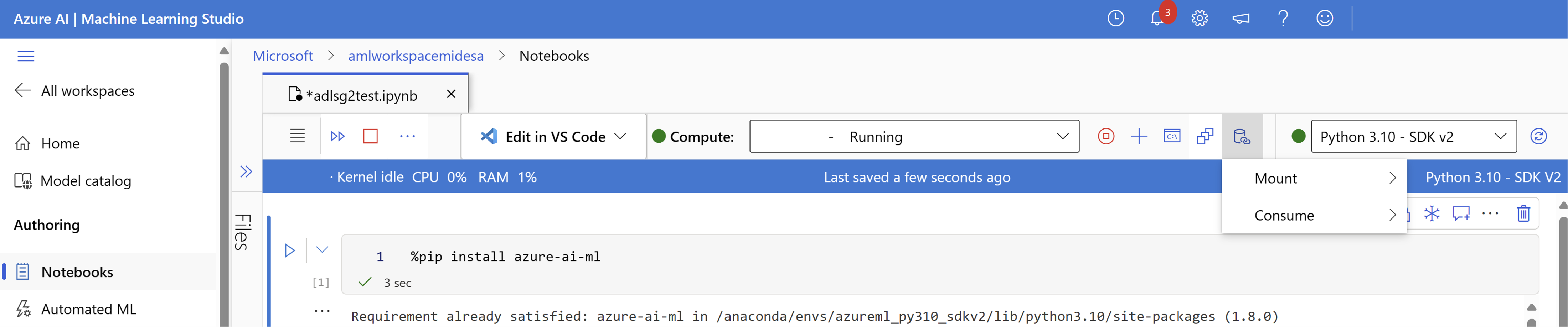
Da qui dovrebbe essere visualizzato e selezionare il nome dell'account di archiviazione ADLSg2. La creazione del montaggio potrebbe richiedere alcuni istanti.
Quando il montaggio è pronto, è possibile selezionare Azioni dati e quindi Utilizzare. In Dati è quindi possibile selezionare il montaggio da cui si desidera utilizzare i dati.
È ora possibile usare le librerie preferite per leggere direttamente i dati dall'account azure Data Lake Storage montato.
Leggere i dati dall'account di archiviazione
import os
# List the files in the mounted path
print(os.listdir("/home/azureuser/cloudfiles/data/datastore/{name of mount}"))
# Get the path of your file and load the data using your preferred libraries
import pandas as pd
df = pd.read_csv("/home/azureuser/cloudfiles/data/datastore/{name of mount}/{file name}")
print(df.head(5))