Eventi
Ottieni gratuitamente la certificazione in Microsoft Fabric.
19 nov, 23 - 10 dic, 23
Per un periodo di tempo limitato, il team della community di Microsoft Fabric offre buoni per esami DP-600 gratuiti.
Prepara oraQuesto browser non è più supportato.
Esegui l'aggiornamento a Microsoft Edge per sfruttare i vantaggi di funzionalità più recenti, aggiornamenti della sicurezza e supporto tecnico.
L'area di lavoro di Azure Synapse Analytics consente di creare due tipi di database in un data lake Spark:
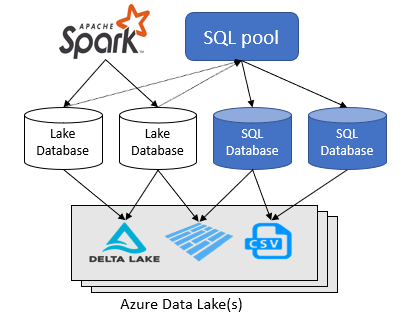
Questo articolo è incentrato sui database lake in un pool SQL serverless in Azure Synapse Analytics.
Azure Synapse Analytics consente di creare database e tabelle lake usando Spark o progettazione database e quindi analizzare i dati nei database lake usando il pool SQL serverless. I database lake e le tabelle (con supporto parquet o CSV) creati nei pool di Apache Spark, nei modellidi database o in Dataverse sono automaticamente disponibili per l'esecuzione di query con il motore del pool SQL serverless. I database e le tabelle lake modificati saranno disponibili nel pool SQL serverless dopo un certo periodo di tempo. Si verifica un ritardo fino a quando non vengono visualizzate le modifiche apportate in Spark o Database progettato in serverless.
Per gestire i database Lake creati da Spark, è possibile usare pool di Apache Spark o Progettazione database. Ad esempio, creare o eliminare un database Lake tramite un processo del pool di Spark. Non è possibile creare un database Lake o gli oggetti nei database lake usando il pool SQL serverless.
Il database Spark default è disponibile nel contesto del pool SQL serverless come database lake denominato default.
Nota
Non è possibile creare un lake e un database SQL nel pool SQL serverless con lo stesso nome.
Le tabelle nei database Lake non possono essere modificate da un pool SQL serverless. Usare Progettazione database o pool di Apache Spark per modificare un database Lake. Il pool SQL serverless consente di apportare le modifiche seguenti in un database Lake usando i comandi Transact-SQL:
I database e le tabelle lake sono protetti a due livelli:
L'accesso ai file di database Lake viene controllato usando le autorizzazioni lake a livello di archiviazione. Solo gli utenti di Microsoft Entra possono usare tabelle nei database lake e possono accedere ai dati nel lake usando le proprie identità.
È possibile concedere l'accesso ai dati sottostanti usati per le tabelle esterne a un'entità di sicurezza, ad esempio un utente, un'applicazione Microsoft Entra con un'entità di sicurezza di servizio assegnata o un gruppo di sicurezza. Per l'accesso ai dati, concedere entrambe le autorizzazioni seguenti:
read (R) per i file, ad esempio i file di dati sottostanti della tabella.execute (X) per la cartella in cui sono archiviati i file e in ogni cartella padre fino alla radice. Per altre informazioni su queste autorizzazioni, vedere la pagina Elenchi di controllo di accesso (ACL).Ad esempio, in https://<storage-name>.dfs.core.windows.net/<fs>/synapse/workspaces/<synapse_ws>/warehouse/mytestdb.db/myparquettable/, le entità di sicurezza hanno bisogno di:
execute (X) per tutte le cartelle a partire da <fs> fino a myparquettable.read (R) per myparquettable e file all'interno di tale cartella, per poter leggere una tabella in un database (sincronizzata o originale).Se un'entità di sicurezza deve poter creare o eliminare oggetti in un database, sono necessarie ulteriori autorizzazioni write (W) sulle cartelle e i file nella cartella warehouse. La modifica di oggetti in un database non è possibile dal pool SQL serverless, solo dai pool di Spark o dalla Progettazione database.
L'area di lavoro di Azure Synapse fornisce un endpoint T-SQL che consente di eseguire query sul database lake usando il pool SQL serverless. Oltre all'accesso ai dati, l'interfaccia SQL consente di controllare chi può accedere alle tabelle. È necessario consentire a un utente di accedere ai database lake condivisi usando il pool SQL serverless. Esistono due tipi di utenti che possono accedere ai database lake:
Altre informazioni sull'impostazione del controllo di accesso nei database condivisi sono disponibili qui.
I database Lake consentono la creazione di oggetti T-SQL personalizzati, ad esempio schemi, procedure, viste e funzioni inline con valori di tabella (iTVFs). Per creare oggetti SQL personalizzati, è NECESSARIO creare uno schema in cui inserire gli oggetti. Gli oggetti SQL personalizzati non possono essere inseriti nello schema dbo perché sono riservati per le tabelle lake definite in Spark, Progettazione database o Dataverse.
Importante
È necessario creare uno schema SQL personalizzato in cui inserire gli oggetti SQL. Gli oggetti SQL personalizzati non possono essere inseriti nello schema dbo. Lo schema dbo è riservato per le tabelle lake create originariamente in Spark o in Progettazione database.
In questo esempio viene aggiunto un utente di Microsoft Entra nel database lake che può leggere i dati tramite tabelle condivise. Gli utenti vengono aggiunti nel database lake tramite il pool SQL serverless. Assegnare quindi l'utente al ruolo db_datareader in modo da poter leggere i dati.
CREATE USER [customuser@contoso.com] FROM EXTERNAL PROVIDER;
GO
ALTER ROLE db_datareader
ADD MEMBER [customuser@contoso.com];
Un account di accesso con autorizzazioni GRANT CONNECT ANY DATABASE e GRANT SELECT ALL USER SECURABLES è in grado di leggere tutte le tabelle usando il pool SQL serverless, ma non è in grado di creare database SQL o modificare gli oggetti in essi contenuti.
CREATE LOGIN [wsdatareader@contoso.com] FROM EXTERNAL PROVIDER
GRANT CONNECT ANY DATABASE TO [wsdatareader@contoso.com]
GRANT SELECT ALL USER SECURABLES TO [wsdatareader@contoso.com]
Questo script consente di creare utenti senza privilegi di amministratore che possono leggere qualsiasi tabella nei database Lake.
Creare prima di tutto un nuovo database Spark denominato mytestdb usando un cluster Spark che è già stato creato nell'area di lavoro. A questo scopo è possibile usare, ad esempio, un notebook C# Spark con l'istruzione .NET per Spark seguente:
spark.sql("CREATE DATABASE mytestlakedb")
Dopo una breve attesa, il database lake viene visualizzato nel pool SQL serverless. Ad esempio, eseguire l'istruzione seguente dal pool SQL serverless.
SELECT * FROM sys.databases;
Verificare che mytestlakedb sia incluso nei risultati.
Nell'esempio seguente viene illustrato come creare una vista personalizzata, una routine e una funzione inline con valori di tabella (iTVF) nello schema reports:
CREATE SCHEMA reports
GO
CREATE OR ALTER VIEW reports.GreenReport
AS SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
GO
CREATE OR ALTER PROCEDURE reports.GreenReportSummary
AS BEGIN
SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
END
GO
CREATE OR ALTER FUNCTION reports.GreenDataReportMonthly(@year int)
RETURNS TABLE
RETURN ( SELECT puYear = @year, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
WHERE puYear = @year
GROUP BY puMonth )
GO
Eventi
Ottieni gratuitamente la certificazione in Microsoft Fabric.
19 nov, 23 - 10 dic, 23
Per un periodo di tempo limitato, il team della community di Microsoft Fabric offre buoni per esami DP-600 gratuiti.
Prepara ora