Migrazione dei dati, ETL e caricamento per le migrazioni di Oracle
Questo articolo è la seconda parte di una serie in sette parti che fornisce indicazioni su come eseguire la migrazione da Oracle ad Azure Synapse Analytics. L'obiettivo di questo articolo è illustrare le procedure consigliate per la migrazione ETL e del carico.
Considerazioni sulla migrazione dei dati
Esistono molti fattori da considerare quando si esegue la migrazione di dati, ETL e carichi da un data warehouse Oracle legacy e da data mart ad Azure Synapse.
Decisioni iniziali per la migrazione dei dati da Oracle
Quando si pianifica una migrazione da un ambiente Oracle esistente, prendere in considerazione le domande correlate ai dati seguenti:
È consigliabile eseguire la migrazione delle strutture di tabella inutilizzate?
Qual è l'approccio migliore alla migrazione per ridurre al minimo i rischi e l'impatto per gli utenti?
Quando si esegue la migrazione dei data mart: scegliere l'approccio fisico o virtuale?
Le sezioni successive illustrano questi punti nel contesto di una migrazione da Oracle.
Eseguire la migrazione delle tabelle inutilizzate?
È opportuno eseguire la migrazione solo delle tabelle in uso. Le tabelle non attive possono essere archiviate anziché sottoposte a migrazione, in modo che i dati siano disponibili se necessario in futuro. È consigliabile usare i metadati di sistema e i file di log anziché la documentazione per determinare quali tabelle sono in uso, perché la documentazione può non essere aggiornata.
Le tabelle e i log del catalogo di sistema Oracle contengono informazioni che possono essere usate per determinare quando è stato eseguito l'ultimo accesso a una determinata tabella, informazione che a sua volta può essere usata per decidere se una tabella sia ideale o meno per la migrazione.
Se è stato concesso in licenza il pacchetto Oracle Diagnostic Pack, è possibile accedere alla cronologia della sessione attiva, che è possibile usare per determinare quando è stato eseguito l'ultimo accesso a una tabella.
Suggerimento
Nei sistemi legacy non è insolito che le tabelle diventino ridondanti nel tempo. Non è necessario eseguire la migrazione nella maggior parte dei casi.
Ecco una query di esempio che cerca l'utilizzo di una tabella specifica all'interno di un determinato intervallo di tempo:
SELECT du.username,
s.sql_text,
MAX(ash.sample_time) AS last_access ,
sp.object_owner ,
sp.object_name ,
sp.object_alias as aliased_as ,
sp.object_type ,
COUNT(*) AS access_count
FROM v$active_session_history ash
JOIN v$sql s ON ash.force_matching_signature = s.force_matching_signature
LEFT JOIN v$sql_plan sp ON s.sql_id = sp.sql_id
JOIN DBA_USERS du ON ash.user_id = du.USER_ID
WHERE ash.session_type = 'FOREGROUND'
AND ash.SQL_ID IS NOT NULL
AND sp.object_name IS NOT NULL
AND ash.user_id <> 0
GROUP BY du.username,
s.sql_text,
sp.object_owner,
sp.object_name,
sp.object_alias,
sp.object_type
ORDER BY 3 DESC;
L'esecuzione di questa query può richiedere tempo se sono state eseguite numerose query.
Qual è l'approccio migliore alla migrazione per ridurre al minimo i rischi e l'impatto sugli utenti?
Questa domanda si presenta spesso perché le aziende potrebbero voler ridurre l'impatto delle modifiche sul modello di dati del data warehouse per migliorare l'agilità. Le aziende spesso vedono l'opportunità di modernizzare o trasformare ulteriormente i dati durante una migrazione ETL. Questo approccio comporta un rischio più elevato perché cambia più fattori contemporaneamente, rendendo difficile confrontare i risultati del vecchio sistema rispetto al nuovo. Le modifiche apportate al modello di dati possono influire anche sui processi ETL upstream o downstream in altri sistemi. A causa di questo rischio, è preferibile riprogettare questa scalabilità dopo la migrazione del data warehouse.
Anche se un modello di dati viene intenzionalmente modificato come parte della migrazione complessiva, è consigliabile eseguire la migrazione del modello esistente così com'è ad Azure Synapse, anziché eseguire una nuova progettazione nella nuova piattaforma. Questo approccio riduce al minimo l'effetto sui sistemi di produzione esistenti, sfruttando al contempo le prestazioni e la scalabilità elastica della piattaforma Azure per le attività di ricompilazione una tantum.
Suggerimento
Eseguire inizialmente la migrazione del modello esistente così com'è, anche se è prevista una modifica al modello di dati in futuro.
Migrazione dei data mart: scegliere l'approccio fisico o virtuale?
Negli ambienti di data warehouse Oracle legacy, è prassi comune creare molti data mart strutturati per offrire prestazioni ottimali per query e report self-service ad hoc per una determinata funzione di reparto o business all'interno di un'organizzazione. Un data mart è in genere costituito da un subset del data warehouse che contiene versioni aggregate dei dati in un modulo che consente agli utenti di eseguire facilmente query sui dati con tempi di risposta rapidi. Gli utenti possono usare strumenti di query semplici come Microsoft Power BI, che supportano le interazioni degli utenti aziendali con i data mart. Il formato dei dati in un data mart è in genere un modello di dati dimensionale. Un uso dei data mart consiste nell'esporre i dati in un formato fruibile, anche se il modello di dati del warehouse sottostante è di tipo diverso, ad esempio un insieme di credenziali dei dati.
È possibile usare data mart separati per singole business unit all'interno di un'organizzazione per implementare solidi regimi di sicurezza dei dati. Limitare l'accesso degli utenti a data mart specifici pertinenti ed eliminare, offuscare o rendere anonimi i dati sensibili.
Se questi data mart vengono implementati come tabelle fisiche, richiederanno risorse di archiviazione aggiuntive e ulteriore elaborazione per la compilazione e l'aggiornamento regolari. Inoltre, i dati nel mart saranno aggiornati solo come ultima operazione di aggiornamento e quindi potrebbero non essere adatti per i dashboard di dati altamente volatili.
Suggerimento
La virtualizzazione dei data mart può far risparmiare sulle risorse di archiviazione ed elaborazione.
Con l'avvento di architetture MPP più economiche, ad esempio Azure Synapse, e le relative caratteristiche di prestazioni intrinseche, è possibile fornire funzionalità di data mart senza creare un'istanza del mart come set di tabelle fisiche. Un metodo consiste nel virtualizzare efficacemente i data mart tramite viste SQL nel data warehouse principale. Un altro modo consiste nel virtualizzare i data mart tramite un livello di virtualizzazione usando funzionalità come le viste in Azure o prodotti di virtualizzazione di terze parti. Questo approccio semplifica o elimina la necessità di un'elaborazione aggiuntiva di archiviazione e aggregazione e riduce il numero complessivo di oggetti di database di cui eseguire la migrazione.
Questo approccio offre un altro potenziale vantaggio. Implementando la logica di aggregazione e join all'interno di un livello di virtualizzazione e presentando strumenti di creazione di report esterni tramite una vista virtualizzata, l'elaborazione necessaria per creare queste viste viene inserita nel data warehouse. Il data warehouse è in genere la posizione migliore per eseguire join, aggregazioni e altre operazioni correlate su volumi di dati di grandi dimensioni.
I driver principali per l'implementazione di un data mart virtuale in un data mart fisico sono:
Più agilità: un data mart virtuale è più facile da modificare rispetto alle tabelle fisiche e ai processi ETL associati.
Costo totale di proprietà inferiore: un'implementazione virtualizzata richiede meno archivi dati e copie di dati.
Eliminazione dei processi ETL di cui eseguire la migrazione e architettura data warehouse semplificata in un ambiente virtualizzato.
Prestazioni: anche se i data mart fisici sono storicamente più efficienti, i prodotti di virtualizzazione ora implementano tecniche di memorizzazione nella cache intelligenti per attenuare questa differenza.
Suggerimento
Le prestazioni e la scalabilità di Azure Synapse consentono una virtualizzazione senza sacrificare le prestazioni.
Migrazione dei dati da Oracle
Informazioni sui dati
Come parte della pianificazione della migrazione, è necessario comprendere in dettaglio il volume di dati di cui eseguire la migrazione, in quanto ciò può influire sulle decisioni relative all'approccio alla migrazione. Usare i metadati di sistema per determinare lo spazio fisico occupato dai dati non elaborati all'interno delle tabelle di cui eseguire la migrazione. In questo contesto, per dati non elaborati si indica la quantità di spazio usata dalle righe di dati all'interno di una tabella, esclusi i sovraccarichi, ad esempio indici e compressione. Le tabelle dei fatti più grandi comprendono in genere più del 95% dei dati.
Questa query fornirà le dimensioni totali del database in Oracle:
SELECT
( SELECT SUM(bytes)/1024/1024/1024 data_size
FROM sys.dba_data_files ) +
( SELECT NVL(sum(bytes),0)/1024/1024/1024 temp_size
FROM sys.dba_temp_files ) +
( SELECT SUM(bytes)/1024/1024/1024 redo_size
FROM sys.v_$log ) +
( SELECT SUM(BLOCK_SIZE*FILE_SIZE_BLKS)/1024/1024/1024 controlfile_size
FROM v$controlfile ) "Size in GB"
FROM dual
Le dimensioni del database sono uguali alle dimensioni di (data files + temp files + online/offline redo log files + control files). Le dimensioni complessive del database includono lo spazio usato e lo spazio disponibile.
La query di esempio seguente fornisce una suddivisione dello spazio su disco usato dai dati e dagli indici della tabella:
SELECT
owner, "Type", table_name "Name", TRUNC(sum(bytes)/1024/1024) Meg
FROM
( SELECT segment_name table_name, owner, bytes, 'Table' as "Type"
FROM dba_segments
WHERE segment_type in ('TABLE','TABLE PARTITION','TABLE SUBPARTITION' )
UNION ALL
SELECT i.table_name, i.owner, s.bytes, 'Index' as "Type"
FROM dba_indexes i, dba_segments s
WHERE s.segment_name = i.index_name
AND s.owner = i.owner
AND s.segment_type in ('INDEX','INDEX PARTITION','INDEX SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.segment_name
AND s.owner = l.owner
AND s.segment_type IN ('LOBSEGMENT','LOB PARTITION','LOB SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB Index' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.index_name
AND s.owner = l.owner
AND s.segment_type = 'LOBINDEX')
WHERE owner in UPPER('&owner')
GROUP BY table_name, owner, "Type"
HAVING SUM(bytes)/1024/1024 > 10 /* Ignore really small tables */
ORDER BY SUM(bytes) desc;
Inoltre, il team di migrazione del database Microsoft fornisce molte risorse, tra cui gli Artefatti dello script dell'inventario Oracle. Lo strumento Artefatti script dell'inventario Oracle include una query PL/SQL che accede alle tabelle di sistema Oracle e fornisce un conteggio degli oggetti per tipo di schema, tipo di oggetto e stato. Lo strumento fornisce anche una stima approssimativa dei "dati non elaborati" in ogni schema e il dimensionamento delle tabelle in ogni schema, con i risultati archiviati in formato CSV. Un foglio di calcolo del calcolatore incluso accetta il file CSV come input e fornisce dati di dimensionamento.
Per qualsiasi tabella, è possibile stimare accuratamente il volume di dati di cui è necessario eseguire la migrazione estraendo un campione rappresentativo dei dati, ad esempio un milione di righe, in un file di dati flat ASCII non compresso e delimitato. Usare quindi le dimensioni del file per ottenere una dimensione media dei dati non elaborati per riga. Moltiplicare infine tale dimensione media per il numero totale di righe nella tabella completa per assegnare una dimensione dei dati non elaborata per la tabella. Usare le dimensioni dei dati non elaborate nella pianificazione.
Usare query SQL per trovare i tipi di dati
Eseguendo una query sulla vista DBA_TAB_COLUMNS del dizionario dei dati statico di Oracle, è possibile determinare quali tipi di dati sono in uso in uno schema e se è necessario modificare uno di questi tipi di dati. Usare le query SQL per trovare le colonne in qualsiasi schema Oracle con tipi di dati che non eseguono il mapping direttamente ai tipi di dati in Azure Synapse. Analogamente, è possibile usare le query per contare il numero di occorrenze di ogni tipo di dati Oracle che non esegue il mapping diretto ad Azure Synapse. Usando i risultati di queste query in combinazione con la tabella di confronto dei tipi di dati, è possibile determinare quali tipi di dati devono essere modificati in un ambiente Azure Synapse.
Per trovare le colonne con tipi di dati che non eseguono il mapping ai tipi di dati in Azure Synapse, eseguire la query seguente dopo aver sostituito <owner_name> con il proprietario dello schema pertinente:
SELECT owner, table_name, column_name, data_type
FROM dba_tab_columns
WHERE owner in ('<owner_name>')
AND data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
ORDER BY 1,2,3;
Per contare il numero di tipi di dati non mappabili, usare la query seguente:
SELECT data_type, count(*)
FROM dba_tab_columns
WHERE data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
GROUP BY data_type
ORDER BY data_type;
Microsoft offre SQL Server Migration Assistant (SSMA) per Oracle per automatizzare la migrazione dei data warehouse da ambienti Oracle legacy, incluso il mapping dei tipi di dati. È anche possibile usare Servizi Migrazione del database di Azure per pianificare ed eseguire una migrazione da ambienti come Oracle. I fornitori di terze parti offrono anche strumenti e servizi per automatizzare la migrazione. Se uno strumento ETL di terze parti è già in uso nell'ambiente Oracle, è possibile usarlo per implementare le trasformazioni dei dati necessarie. La sezione successiva illustra la migrazione dei processi ETL esistenti.
Considerazioni sulla migrazione ETL
Decisioni iniziali sulla migrazione ETL di Oracle
Per l'elaborazione ETL/ELT, i data warehouse Oracle legacy usano spesso script personalizzati, strumenti di terze parti ETL o una combinazione di approcci che si sono evoluti nel tempo. Quando si pianifica una migrazione ad Azure Synapse, determinare il modo migliore per implementare l'elaborazione ETL/ELT necessaria nel nuovo ambiente riducendo anche al minimo i costi e i rischi.
Suggerimento
Pianificare l'approccio alla migrazione ETL in anticipo e sfruttare le funzionalità di Azure, se appropriato.
Il diagramma di flusso seguente riepiloga un approccio:
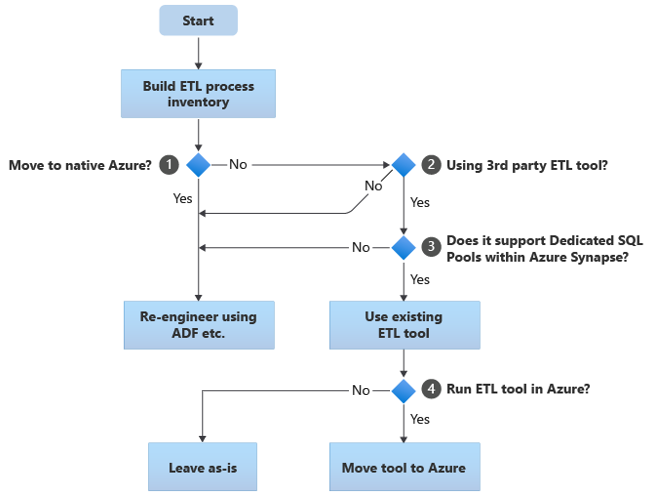
Come mostrato nel diagramma di flusso, il passaggio iniziale consiste sempre nel creare un inventario dei processi ETL/ELT di cui è necessario eseguire la migrazione. Con le funzionalità predefinite di Azure standard, alcuni processi esistenti potrebbero non dover essere spostati. Ai fini della pianificazione, è importante comprendere la scala della migrazione. Considerare quindi le domande nell'albero delle decisioni del diagramma di flusso:
Eseguire il passaggio ad Azure nativo? La risposta dipende dal fatto che si stia eseguendo la migrazione a un ambiente completamente nativo di Azure. In questo caso, è consigliabile riconfigurare l'elaborazione ETL usando Pipeline e attività in Azure Data Factory o Pipeline di Azure Synapse Pipelines.
Usare uno strumento ETL di terze parti? Se non si passa a un ambiente completamente nativo di Azure, verificare se è già in uso uno strumento ETL di terze parti. Nell'ambiente Oracle è possibile che alcune o tutte le elaborazioni ETL vengano eseguite da script personalizzati usando utilità specifiche di Oracle, ad esempio Oracle SQL Developer, Oracle SQL*Loader o Oracle Data Pump. In questo caso, l'approccio consiste nel riprogettare l'uso di Azure Data Factory.
La terza parte supporta pool SQL dedicati all'interno di Azure Synapse? Valutare se è stato fatto un grande investimento nelle competenze nello strumento ETL di terze parti o se i flussi di lavoro e le pianificazioni esistenti usano tale strumento. In tal caso, determinare se lo strumento può supportare in modo efficiente Azure Synapse come ambiente di destinazione. Idealmente, lo strumento includerà connettori "nativi" che possono usare le funzionalità di Azure come PolyBase o COPY INTO, per il caricamento dei dati più efficiente. Ma anche senza connettori nativi, in genere è possibile chiamare processi esterni, ad esempio PolyBase o
COPY INTO, e passare parametri applicabili. In questo caso, usare le competenze e i flussi di lavoro esistenti, con Azure Synapse come nuovo ambiente di destinazione.Se si usa Oracle Data Integrator (ODI) per l'elaborazione ELT, sono necessari moduli di conoscenza ODI per Azure Synapse. Se questi moduli non sono disponibili per l'utente nell'organizzazione, ma si dispone di ODI, è possibile usare ODI per generare file flat. Questi file flat possono quindi essere spostati in Azure e inseriti in Azure Data Lake Storage per il caricamento in Azure Synapse.
Eseguire gli strumenti ETL in Azure? Se si decide di mantenere uno strumento ETL di terze parti esistente, è possibile eseguire tale strumento all'interno dell'ambiente Azure (anziché in un server ETL locale esistente) e permettere la gestione dell'orchestrazione complessiva dei flussi di lavoro esistenti da parte di Azure Data Factory. Quindi, decidere se lasciare lo strumento esistente in esecuzione così com'è oppure spostarlo nell'ambiente di Azure per ottenere vantaggi di costo, prestazioni e scalabilità.
Suggerimento
Prendere in considerazione l'esecuzione di strumenti ETL in Azure per sfruttare i vantaggi di prestazioni, scalabilità e costi.
Riconfigurare gli script specifici di Oracle esistenti
Se alcune o tutte le elaborazioni ETL/ELT del warehouse Oracle esistenti vengono gestite da script personalizzati che usano utilità specifiche di Oracle, ad esempio Oracle SQL*Plus, Oracle SQL Developer, Oracle SQL*Loader o Oracle Data Pump, è necessario codificare questi script per l'ambiente Azure Synapse. Analogamente, se i processi ETL sono stati implementati usando stored procedure in Oracle, è necessario ricodificarli.
Alcuni elementi del processo ETL sono facili da sottoporre a migrazione, ad esempio tramite semplice caricamento di dati in blocco in una tabella di gestione temporanea da un file esterno. Può anche essere possibile automatizzare tali parti del processo, ad esempio usando Azure Synapse COPY INTO o PolyBase anziché SQL*Loader. Altre parti del processo che contengono stored procedure e/o SQL complesso arbitrario richiederanno più tempo per la riprogettazione.
Suggerimento
L'inventario delle attività ETL di cui eseguire la migrazione deve includere script e stored procedure.
Un modo per testare Oracle SQL per la compatibilità con Azure Synapse consiste nell'acquisire alcune istruzioni SQL rappresentative da un join di Oracle v$active_session_history e v$sql per ottenere sql_text, quindi anteporre tali query a EXPLAIN. Supponendo che in Azure Synapse sia stato eseguito un modello di dati di tipo like-for-like, eseguire tali istruzioni EXPLAIN in Azure Synapse. Qualsiasi SQL incompatibile restituirà un errore. È possibile usare queste informazioni per determinare la scalabilità dell'attività di ricodifica.
Suggerimento
Usare EXPLAIN per trovare incompatibilità SQL.
Nel peggiore dei casi, potrebbe essere necessario eseguire la registrazione manuale. Esistono tuttavia prodotti e servizi disponibili da partner Microsoft per facilitare la riprogettazione del codice specifico di Oracle.
Suggerimento
I partner offrono prodotti e competenze utili per riprogettazione del codice specifico di Oracle.
Usare strumenti ETL di terze parti esistenti
In molti casi il sistema di data warehouse legacy esistente sarà già popolato e gestito da un prodotto ETL di terze parti. Vedere Partner di integrazione dei dati di Azure Synapse Analytics per un elenco dei partner di integrazione dei dati di Microsoft correnti per Azure Synapse.
La community Oracle usa spesso diversi prodotti ETL più diffusi. I paragrafi seguenti illustrano gli strumenti ETL più diffusi per i warehouse Oracle. È possibile eseguire tutti questi prodotti all'interno di una macchina virtuale in Azure e usarli per leggere e scrivere file e database di Azure.
Suggerimento
Sfruttare gli investimenti negli strumenti di terze parti esistenti per ridurre i costi e i rischi.
Caricamento dei dati da Oracle
Scelte disponibili durante il caricamento dei dati da Oracle
Quando si prepara la migrazione dei dati da un data warehouse Oracle, decidere in che modo i dati verranno spostati fisicamente dall'ambiente locale esistente in Azure Synapse nel cloud e quali strumenti verranno usati per eseguire il trasferimento e il caricamento. Considerare le domande seguenti, illustrate nelle sezioni seguenti.
I dati verranno estratti nei file o spostati direttamente tramite una connessione di rete?
Il processo verrà orchestrato dal sistema di origine o dall'ambiente di destinazione di Azure?
Quali strumenti verranno usati per automatizzare e gestire il processo di migrazione?
Trasferire dati tramite file o connessioni di rete?
Dopo aver creato le tabelle di database di cui eseguire la migrazione in Azure Synapse, è possibile spostare i dati che popolano tali tabelle dal sistema Oracle legacy e nel nuovo ambiente. Esistono due approcci di base:
Estrazione di gile: estrarre i dati dalle tabelle Oracle a file delimitati flat, in genere in formato CSV. È possibile estrarre i dati della tabella in diversi modi:
- Usare strumenti Oracle standard, ad esempio SQL*Plus, SQL Developer e SQLcl.
- Usare Oracle Data Integrator (ODI) per generare file flat.
- Usare il connettore Oracle in Data Factory per scaricare le tabelle Oracle in parallelo per abilitare il caricamento dei dati in base alle partizioni.
- Usare uno strumento ETL di terze parti.
Per esempi di come estrarre i dati della tabella Oracle, vedere l'articolo appendice.
Questo approccio richiede spazio per spostare i file di dati estratti. Lo spazio potrebbe essere locale per il database di origine Oracle (se è disponibile spazio di archiviazione sufficiente) o remoto in Archiviazione BLOB di Azure. Le prestazioni migliori si ottengono quando un file viene scritto in locale, in quanto si evita il sovraccarico di rete.
Per ridurre al minimo i requisiti di archiviazione e trasferimento di rete, comprimere i file di dati estratti usando un'utilità come gzip.
Dopo l'estrazione, spostare i file flat in Archiviazione BLOB di Azure. Microsoft offre varie opzioni per spostare grandi volumi di dati, tra cui:
- AzCopy per lo spostamento di file in rete in Archiviazione di Azure.
- Azure ExpressRoute per lo spostamento di dati in blocco tramite una connessione di rete privata.
- Azure Data Box per lo spostamento di file in un dispositivo di archiviazione fisico fornito a un data center di Azure per il caricamento.
Per altre informazioni, vedere Trasferire dati da e verso Azure.
Estrazione diretta e caricamento tra reti: l'ambiente di Azure di destinazione invia una richiesta di estrazione dei dati, in genere tramite un comando SQL, al sistema Oracle legacy per estrarre i dati. I risultati vengono inviati in rete e caricati direttamente in Azure Synapse, senza dover trasferire i dati in file intermedi. Il fattore di limitazione in questo scenario è in genere la larghezza di banda della connessione di rete tra il database Oracle e l'ambiente Azure. Per volumi di dati eccezionalmente grandi, questo approccio potrebbe non essere pratico.
Suggerimento
Comprendere i volumi di dati di cui eseguire la migrazione e la larghezza di banda di rete disponibile, perché questi fattori influenzeranno la decisione dell'approccio alla migrazione.
Esiste anche un approccio ibrido che usa entrambi i metodi. Ad esempio, è possibile usare l'approccio di estrazione diretta dalla rete per tabelle di dimensioni più piccole e per campioni delle tabelle dei fatti più grandi per fornire rapidamente un ambiente di test in Azure Synapse. Per le tabelle dei fatti cronologici di volumi di grandi dimensioni, è possibile usare l'approccio di estrazione e trasferimento dei file usando Azure Data Box.
Orchestrare da Oracle o Azure?
L'approccio consigliato quando si passa ad Azure Synapse consiste nell'orchestrare l'estrazione e il caricamento dei dati dall'ambiente di Azure usando SSMA o Data Factory. Usare le utilità associate, ad esempio PolyBase o COPY INTO, per il caricamento dei dati più efficiente. Questo approccio trae vantaggio dalle funzionalità predefinite di Azure e riduce il lavoro richiesto per creare pipeline di caricamento dei dati riutilizzabili. È possibile usare pipeline di caricamento dei dati basate sui metadati per automatizzare il processo di migrazione.
L'approccio consigliato riduce al minimo anche il raggiungimento delle prestazioni nell'ambiente Oracle esistente durante il processo di caricamento dei dati, perché il processo di gestione e caricamento viene eseguito in Azure.
Strumenti di migrazione dei dati esistenti
La trasformazione e lo spostamento dei dati sono una funzione di base di tutti i prodotti ETL. Se uno strumento di migrazione dei dati è già in uso nell'ambiente Oracle esistente e supporta Azure Synapse come ambiente di destinazione, è consigliabile usare tale strumento per semplificare la migrazione dei dati.
Anche se non è disponibile uno strumento ETL esistente, i partner di integrazione dei dati di Azure Synapse Analytics offrono strumenti ETL per semplificare l'attività di migrazione dei dati.
Infine, se si prevede di usare uno strumento ETL, prendere in considerazione l'esecuzione di tale strumento all'interno dell'ambiente Azure per sfruttare le prestazioni, la scalabilità e i costi del cloud di Azure. Questo approccio libera anche le risorse nel data center Oracle.
Riepilogo
Per riepilogare, i suggerimenti per la migrazione dei dati e dei processi ETL associati da Oracle ad Azure Synapse sono:
Pianificare in anticipo per garantire un esercizio di migrazione riuscito.
Creare un inventario dettagliato dei dati e dei processi di cui eseguire la migrazione il prima possibile.
Usare i metadati di sistema e i file di log per ottenere una comprensione accurata dei dati e dell'utilizzo dei processi. Non basarsi sulla documentazione perché potrebbe non essere aggiornata.
Comprendere i volumi di dati di cui eseguire la migrazione e la larghezza di banda di rete tra il data center locale e gli ambienti cloud di Azure.
Prendere in considerazione l'uso di un'istanza Oracle in una macchina virtuale di Azure come procedura di offload della migrazione dall'ambiente Oracle legacy.
Usare le funzionalità di Azure "predefinite" standard per ridurre al minimo il carico di lavoro di migrazione.
Identificare e comprendere gli strumenti più efficienti per l'estrazione e il caricamento dei dati in ambienti Oracle e Azure. Usare gli strumenti appropriati in ogni fase del processo.
Usare le funzionalità di Azure, ad esempio Azure Data Factory, per orchestrare e automatizzare il processo di migrazione riducendo al minimo l'impatto sul sistema Oracle.
Appendice: esempi di tecniche per estrarre i dati Oracle
È possibile usare diverse tecniche per estrarre i dati Oracle durante la migrazione da Oracle ad Azure Synapse. Le sezioni successive illustrano come estrarre i dati Oracle usando Oracle SQL Developer e il connettore Oracle in Data Factory.
Usare Oracle SQL Developer per l'estrazione dei dati
È possibile usare l'interfaccia utente di Oracle SQL Developer per esportare i dati della tabella in molti formati, tra cui CSV, come illustrato nello screenshot seguente:

Altre opzioni di esportazione includono JSON e XML. È possibile usare l'interfaccia utente per aggiungere un set di nomi di tabella a un "carrello", quindi applicare l'esportazione all'intero set nel carrello:

È anche possibile usare Oracle SQL Developer Command Line (SQLcl) per esportare i dati Oracle. Questa opzione supporta l'automazione tramite uno script della shell.
Per le tabelle relativamente piccole, questa tecnica può risultare utile se si verificano problemi durante l'estrazione dei dati tramite una connessione diretta.
Usare il connettore Oracle in Azure Data Factory per la copia parallela
È possibile usare il connettore Oracle in Data Factory per scaricare tabelle Oracle di grandi dimensioni in parallelo. Il connettore Oracle fornisce il partizionamento dei dati predefinito per copiare dati da Oracle in parallelo. È possibile trovare le opzioni di partizionamento dei dati nella tabella Origine dell'attività di copia.

Per informazioni su come configurare il connettore Oracle per la copia parallela, vedere Copia parallela da Oracle.
Per altre informazioni sulle prestazioni e la scalabilità dell'attività di copia di Azure Data Factory, vedere Guida alle prestazioni e alla scalabilità dell'attività Copy.
Passaggi successivi
Per informazioni sulle operazioni di accesso alla sicurezza, vedere l'articolo successivo di questa serie: Sicurezza, accesso e operazioni per le migrazioni Oracle.