Oltre alla migrazione di Teradata, implementare un data warehouse moderno in Microsoft Azure
Questo articolo è la settima parte di una serie in sette parti che fornisce indicazioni su come eseguire la migrazione da Teradata ad Azure Synapse Analytics. Questo articolo è incentrato sulle procedure consigliate per l'implementazione di data warehouse moderni.
Oltre la migrazione del data warehouse ad Azure
Un motivo fondamentale per eseguire la migrazione del data warehouse esistente ad Azure Synapse Analytics consiste nell'usare un database analitico sicuro a livello globale, scalabile, a basso costo, nativo del cloud e con pagamento in base al consumo. Con Azure Synapse è possibile integrare il data warehouse di cui è stata eseguita la migrazione con l'ecosistema analitico di Microsoft Azure completo per sfruttare altre tecnologie Microsoft e modernizzare il data warehouse di cui è stata eseguita la migrazione. Tali tecnologie includono:
Azure Data Lake Storage per operazioni efficaci di inserimento, staging, pulizia e trasformazione dei dati. Data Lake Storage può liberare la capacità del data warehouse occupata da tabelle di staging in rapida crescita.
Azure Data Factory per l'integrazione dei dati IT collaborativa e self-service con connettori a origini dati e dati di streaming cloud e locali.
Common Data Model per condividere dati attendibili coerenti tra più tecnologie, tra cui:
- Azure Synapse
- Azure Synapse Spark
- Azure HDInsight
- Power BI
- Piattaforma per la gestione della customer experience di Adobe
- Azure IoT
- Partner Microsoft ISV
Tecnologie di data science di Microsoft, tra cui:
- Studio di Azure Machine Learning
- Azure Machine Learning
- Spark di Azure Synapse (Spark come servizio)
- Jupyter Notebook
- RStudio
- ML.NET
- .NET per Apache Spark, che consente agli scienziati dei dati di usare i dati di Azure Synapse per eseguire il training di modelli di Machine Learning su larga scala.
Azure HDInsight per elaborare grandi quantità di dati e aggiungere Big Data ai dati di Azure Synapse creando un data warehouse logico tramite PolyBase.
Hub eventi di Azure, Analisi di flusso di Azure e Apache Kafka per integrare i dati di streaming live da Azure Synapse.
La crescita dei Big Data ha portato a una grande richiesta di Machine Learning per abilitare l'uso dei modelli di Machine Learning creati in modo personalizzato e sottoposti a training in Azure Synapse. I modelli di Machine Learning consentono l'esecuzione dell'analisi nel database su larga scala in batch, basata su eventi e su richiesta. La possibilità di sfruttare i vantaggi dell'analisi nel database in Azure Synapse da più strumenti e applicazioni di business intelligence garantisce anche stime e raccomandazioni coerenti.
Inoltre, è possibile integrare Azure Synapse con gli strumenti dei partner Microsoft in Azure per ridurre il time-to-value.
Si esaminerà ora in modo più approfondito come sfruttare le tecnologie nell'ecosistema analitico Microsoft per modernizzare il data warehouse dopo la migrazione ad Azure Synapse.
Staging di offload dei dati ed elaborazione ETL in Data Lake Storage e Data Factory
La trasformazione digitale ha creato una sfida importante per le aziende generando una valanga di nuovi dati per l'acquisizione e l'analisi. Un buon esempio è costituito dai dati delle transazioni creati aprendo sistemi OLTP (elaborazione delle transazioni online) per consentire l'accesso dai dispositivi mobili. Gran parte di questi dati viene conservata nei data warehouse e i sistemi OLTP sono l'origine principale. Poiché ora sono i clienti e non i dipendenti a determinare la velocità delle transazioni, il volume di dati nelle tabelle di staging del data warehouse è in rapida crescita.
Con il rapido afflusso di dati nell'azienda, insieme a nuove origini di dati come Internet delle cose (IoT), le aziende devono trovare un modo per aumentare le prestazioni dell'elaborazione ETL di integrazione dei dati. Un metodo consiste nell'eseguire l'offload di inserimento, pulizia dei dati, trasformazione e integrazione in un data lake ed elaborare i dati su larga scala, come parte di un programma di modernizzazione del data warehouse.
Dopo aver eseguito la migrazione del data warehouse ad Azure Synapse, Microsoft può modernizzare l'elaborazione ETL inserendo ed eseguendo lo staging dei dati in Data Lake Storage. È quindi possibile pulire, trasformare e integrare i dati su larga scala usando Data Factory prima di caricarli in Azure Synapse in parallelo usando PolyBase.
Per le strategie ELT, valutare la possibilità di eseguire l'offload dell'elaborazione ELT in Data Lake Storage per aumentare facilmente le prestazioni man mano che il volume o la frequenza dei dati aumenta.
Microsoft Azure Data Factory
Azure Data Factory è un servizio di integrazione di dati ibridi con pagamento in base all'uso per l'elaborazione ELT ed ETL altamente scalabile. Data Factory offre un'interfaccia utente basata sul Web per compilare pipeline di integrazione dei dati senza codice. Con Data Factory è possibile:
Creare pipeline di integrazione dei dati scalabili senza codice.
Acquisire facilmente i dati su larga scala.
Si paga solo per le risorse usate.
Connettersi a origini dati locali, cloud e basati su SaaS.
Inserire, spostare, pulire, trasformare, integrare e analizzare i dati cloud e locali su larga scala.
Creare, monitorare e gestire facilmente pipeline che estendono gli archivi dati sia in locale che nel cloud.
Abilitare le operazioni di scale-out con pagamento in base al consumo in linea con la crescita dei clienti.
È possibile usare queste funzionalità senza scrivere codice oppure aggiungere codice personalizzato alle pipeline di Data Factory. Lo screenshot seguente mostra un esempio di pipeline di Data Factory.

Suggerimento
Data Factory consente di creare pipeline di integrazione dei dati scalabili senza codice.
Implementare lo sviluppo di pipeline di Data Factory da diverse posizioni, tra cui:
Portale di Microsoft Azure.
Microsoft Azure PowerShell.
A livello di programmazione da .NET e Python con un SDK multi-lingua.
Modelli di Azure Resource Manager (ARM).
API REST.
Suggerimento
Data Factory può connettersi ai dati locali, cloud e SaaS.
Gli sviluppatori e gli scienziati dei dati che preferiscono scrivere codice possono creare facilmente pipeline di Data Factory in Java, Python e .NET usando gli SDK (Software Development Kit) disponibili per tali linguaggi di programmazione. Le pipeline di Data Factory possono essere pipeline di dati ibridi perché possono connettersi, inserire, pulire, trasformare e analizzare i dati in data center locali, in Microsoft Azure, in altri cloud e nelle offerte SaaS.
Dopo aver sviluppato le pipeline di Data Factory per integrare e analizzare i dati, è possibile distribuire tali pipeline a livello globale e pianificarle per l'esecuzione in batch, richiamarle su richiesta come servizio o eseguirle in tempo reale in base agli eventi. Una pipeline di Data Factory può essere eseguita anche su uno o più motori di esecuzione e monitorare l'esecuzione per garantire le prestazioni e tenere traccia degli errori.
Suggerimento
In Azure Data Factory le pipeline controllano l'integrazione e l'analisi dei dati. Data Factory è un software di integrazione dei dati di livello aziendale destinato a professionisti IT e offre funzionalità di data wrangling per gli utenti aziendali.
Utilizzare casi
Data Factory supporta più casi d'uso, ad esempio:
Preparare, integrare e arricchire i dati dalle origini dati cloud e locali per popolare i data warehouse e i data mart di cui è stata eseguita la migrazione in Microsoft Azure Synapse.
Preparare, integrare e arricchire i dati dalle origini dati cloud e locali per produrre dati di training da usare nello sviluppo di modelli di Machine Learning e nel ripetere il training dei modelli analitici.
Orchestrare la preparazione e l'analisi dei dati per creare pipeline analitiche predittive e prescrittive per l'elaborazione e l'analisi dei dati in batch, ad esempio l'analisi della valutazione. Agire sui risultati dell'analisi o popolare il data warehouse con i risultati.
Preparare, integrare e arricchire i dati per le applicazioni aziendali basate sui dati in esecuzione nel cloud di Azure su archivi di dati operativi, quali Azure Cosmos DB.
Suggerimento
Creare set di dati di training in data science per sviluppare modelli di Machine Learning.
Origini dati
Data Factory consente di usare connettori da origini dati sia cloud che locali. Il software dell'agente, noto come runtime di integrazione self-hosted, accede in modo sicuro alle origini dati locali e supporta il trasferimento dei dati sicuro e scalabile.
Trasformare i dati con Azure Data Factory
All'interno di una pipeline di Data Factory è possibile inserire, pulire, trasformare, integrare e analizzare qualsiasi tipo di dati da queste origini. I dati possono essere strutturati, semistrutturati come JSON o Avro o non strutturati.
Senza scrivere il codice, gli sviluppatori professionisti ETL possono usare i flussi dei dati di mapping di Data Factory per filtrare, dividere, unire diversi tipi, ricercare, trasformare tramite Pivot, trasformare tramite UnPivot, ordinare, creare unioni e aggregare i dati. Data Factory supporta inoltre chiavi surrogate, più opzioni di elaborazione di scrittura, ad esempio inserimento, upsert, aggiornamento, ricreazione e troncamento delle tabelle e diversi tipi di archivi di dati di destinazione noti anche come sink. Gli sviluppatori ETL possono anche creare aggregazioni, incluse le aggregazioni di serie temporali che richiedono l'inserimento di una finestra sulle colonne di dati.
Suggerimento
Gli sviluppatori professionali ETL possono usare flussi di dati per mapping di Data Factory per pulire, trasformare e integrare i dati senza la necessità di scrivere codice.
È possibile eseguire flussi di dati per mapping che trasformano i dati come attività in una pipeline di Data Factory e, se necessario, è possibile includere più flussi di dati per mapping in una singola pipeline. In questo modo, è possibile gestire la complessità suddividendo le attività complesse di trasformazione e integrazione dei dati in flussi di dati per mapping più piccoli che possono essere combinati. È anche possibile aggiungere codice personalizzato quando necessario. Oltre a questa funzionalità, i flussi di dati per mapping di Data Factory includono la possibilità di:
Definire espressioni per pulire e trasformare i dati, calcolare le aggregazioni e arricchire i dati. Ad esempio, queste espressioni possono eseguire la definizione delle funzionalità in un campo di dati per suddividerlo in più campi per creare dati di training durante lo sviluppo di modelli di Machine Learning. È possibile costruire espressioni da un set completo di funzioni che includono funzioni matematiche, temporali, divisione, unione, concatenazione di stringhe, condizioni, corrispondenza dei criteri, sostituzione e molte altre funzioni.
Gestire automaticamente lo spostamento schema in modo che le pipeline di trasformazione dei dati possano evitare di essere interessate dalle modifiche dello schema nelle origini dati. Questa funzionalità è particolarmente importante per lo streaming dei dati IoT, in cui le modifiche dello schema possono verificarsi senza preavviso se i dispositivi vengono aggiornati o quando le letture non vengono eseguite dai dispositivi gateway che raccolgono dati IoT.
Eseguire la partizione dei dati per abilitare l'esecuzione delle trasformazioni in parallelo su larga scala.
Esaminare i dati di streaming per visualizzare i metadati di un flusso che si sta trasformando.
Suggerimento
Data Factory supporta la possibilità di rilevare e gestire automaticamente le modifiche dello schema nei dati in ingresso, ad esempio nei dati di streaming.
Lo screenshot seguente mostra un esempio di flusso di dati per mapping di Data Factory.

Gli ingegneri dei dati possono profilare la qualità dei dati e visualizzare i risultati delle singole trasformazioni di dati abilitando la funzionalità di debug durante lo sviluppo.
Suggerimento
Data Factory può anche partizionare i dati per consentire l'esecuzione dell'elaborazione ETL su larga scala.
Se necessario, è possibile estendere la funzionalità di trasformazione e analisi di Data Factory aggiungendo un servizio collegato che contiene il codice in una pipeline. Ad esempio, un notebook del pool di Spark di Azure Synapse potrebbe contenere il codice Python che usa un modello sottoposto a training per assegnare un punteggio ai dati integrati da un flusso di dati per mapping.
È possibile archiviare i dati integrati ed eventuali risultati dell'analisi all'interno di una pipeline di Data Factory in uno o più archivi dati, ad esempio Data Lake Storage, Azure Synapse o tabelle Hive in HDInsight. È anche possibile richiamare altre attività che agiscano sulle informazioni dettagliate generate da una pipeline analitica di Data Factory.
Suggerimento
Le pipeline di Data Factory sono estendibili perché Data Factory consente di scrivere codice personalizzato ed eseguirlo come parte di una pipeline.
Usare Spark per dimensionare l'integrazione dei dati
In fase di esecuzione, Data Factory usa internamente i pool di Spark di Azure Synapse, che sono l'offerta Spark come servizio di Microsoft, per pulire e integrare i dati nel cloud di Azure. È possibile pulire, integrare e analizzare grandi volumi di dati ad alta velocità, ad esempio dati clickstream su larga scala. L'intenzione di Microsoft è anche eseguire pipeline di Data Factory in altre distribuzioni Spark. Oltre all'esecuzione di processi ETL in Spark, Data Factory può richiamare script Pig e query Hive per accedere e trasformare i dati archiviati in HDInsight.
Collegare la preparazione dei dati self-service e l'elaborazione ETL di Data Factory usando flussi di dati per wrangling
Il data wrangling consente agli utenti aziendali, noti anche come integratori di dati dei cittadini e ingegneri dei dati, di usare la piattaforma per individuare visivamente, esplorare e preparare i dati su larga scala senza scrivere codice. Questa funzionalità di Data Factory è facile da usare ed è simile a Microsoft Excel Power Query o ai flussi di dati di Microsoft Power BI, in cui gli utenti aziendali self-service usano un'interfaccia utente in stile foglio di calcolo con trasformazioni a discesa per preparare e integrare i dati. Lo screenshot seguente mostra un esempio di flusso di dati per wrangling di Data Factory.

A differenza di Excel e Power BI, i flussi di dati per wrangling di Data Factory usano Power Query per generare codice M e poi convertirlo in un processo Spark in memoria parallelo massivo per l'esecuzione a livello di cloud. La combinazione di flussi di dati per mapping e flussi di dati per wrangling in Data Factory consente agli sviluppatori professionisti ETL e agli utenti aziendali di collaborare per preparare, integrare e analizzare i dati per uno scopo aziendale comune. Il diagramma precedente dei flussi di dati per mapping di Data Factory mostra come sia i notebook del pool di Data Factory che del pool di Spark di Azure Synapse possono essere combinati nella stessa pipeline di Data Factory. La combinazione flusso di dati per mapping e wrangling in Data Factory consente agli utenti IT e aziendali di saper quale flusso di dati è stato creato da ognuno di essi e supporta il riutilizzo del flusso di dati per ridurre al minimo la reinvenzione e ottimizzare la produttività e la coerenza.
Suggerimento
Data Factory supporta sia i flussi di dati per wrangling che i flussi di dati per mapping, in modo che gli utenti aziendali e gli utenti IT possano integrare i dati in modo collaborativo in una piattaforma comune.
Collegare dati e analisi nelle pipeline analitiche
Oltre a pulire e trasformare i dati, Data Factory può combinare l'integrazione e l'analisi dei dati nella stessa pipeline. È possibile usare Data Factory per creare pipeline di integrazione e pipeline di analisi dei dati; quest'ultima è un'estensione della prima. È possibile rilasciare un modello analitico in una pipeline per creare una pipeline analitica che genera dati puliti e integrati per previsioni o raccomandazioni. È quindi possibile intervenire immediatamente sulle previsioni o sulle raccomandazioni oppure archiviarle nel data warehouse per fornire nuove informazioni dettagliate e raccomandazioni che possono essere visualizzate negli strumenti di business intelligence.
Per assegnare un punteggio in batch ai dati, è possibile sviluppare un modello analitico richiamato come servizio all'interno di una pipeline di Data Factory. È possibile sviluppare modelli analitici senza codice con studio di Azure Machine Learning o con Azure Machine Learning SDK usando i notebook del pool di Spark di Azure Synapse o R in RStudio. Quando si eseguono pipeline di Machine Learning di Spark nei notebook del pool di Spark di Azure Synapse, l'analisi avviene su larga scala.
È possibile archiviare i dati integrati ed eventuali risultati delle pipeline di analisi di Data Factory in uno o più archivi dati, ad esempio Data Lake Storage, Azure Synapse o tabelle Hive in HDInsight. È anche possibile richiamare altre attività che agiscano sulle informazioni dettagliate generate da una pipeline analitica di Data Factory.
Usare un database Lake per condividere dati attendibili coerenti
Un obiettivo chiave di qualsiasi configurazione di integrazione dei dati è la possibilità di integrare i dati una sola volta e riutilizzarli ovunque, non solo in un data warehouse. Ad esempio, è possibile usare i dati integrati nel data science. Il riutilizzo evita la reinvenzione e garantisce dati coerenti e comunemente riconosciuti attendibili per tutti.
Common Data Model descrive le entità di dati di base che possono essere condivise e riutilizzate in tutta l'azienda. Per eseguire il riutilizzo, Common Data Model stabilisce un set di nomi di dati e definizioni comuni che descrivono le entità dati logiche. Esempi di nomi di dati comuni includono Cliente, Account, Prodotto, Fornitore, Ordini, Pagamenti e Resi. I professionisti IT e aziendali possono usare il software di integrazione dei dati per creare e archiviare asset di dati comuni per ottimizzarne il riutilizzo e favorire la coerenza ovunque.
Azure Synapse offre modelli di database specifici del settore per aiutare a standardizzare i dati in un Lake. I modelli di database Lake forniscono schemi per aree aziendali predefinite, consentendo il caricamento dei dati in un database lake in modo strutturato. La potenza deriva dall'uso del software di integrazione dei dati per creare asset di dati comuni del database Lake, con conseguente autodescrizione dei dati attendibili che possono essere utilizzati da applicazioni e sistemi analitici. È possibile creare asset di dati comuni in Data Lake Storage usando Data Factory.
Suggerimento
Data Lake Storage è un archivio condiviso che supporta Microsoft Azure Synapse, Azure Machine Learning, Spark di Azure Synapse e HDInsight.
Power BI, Spark di Azure Synapse, Azure Synapse e Azure Machine Learning possono usare asset di dati comuni. Il diagramma seguente illustra come usare un database Lake in Azure Synapse.
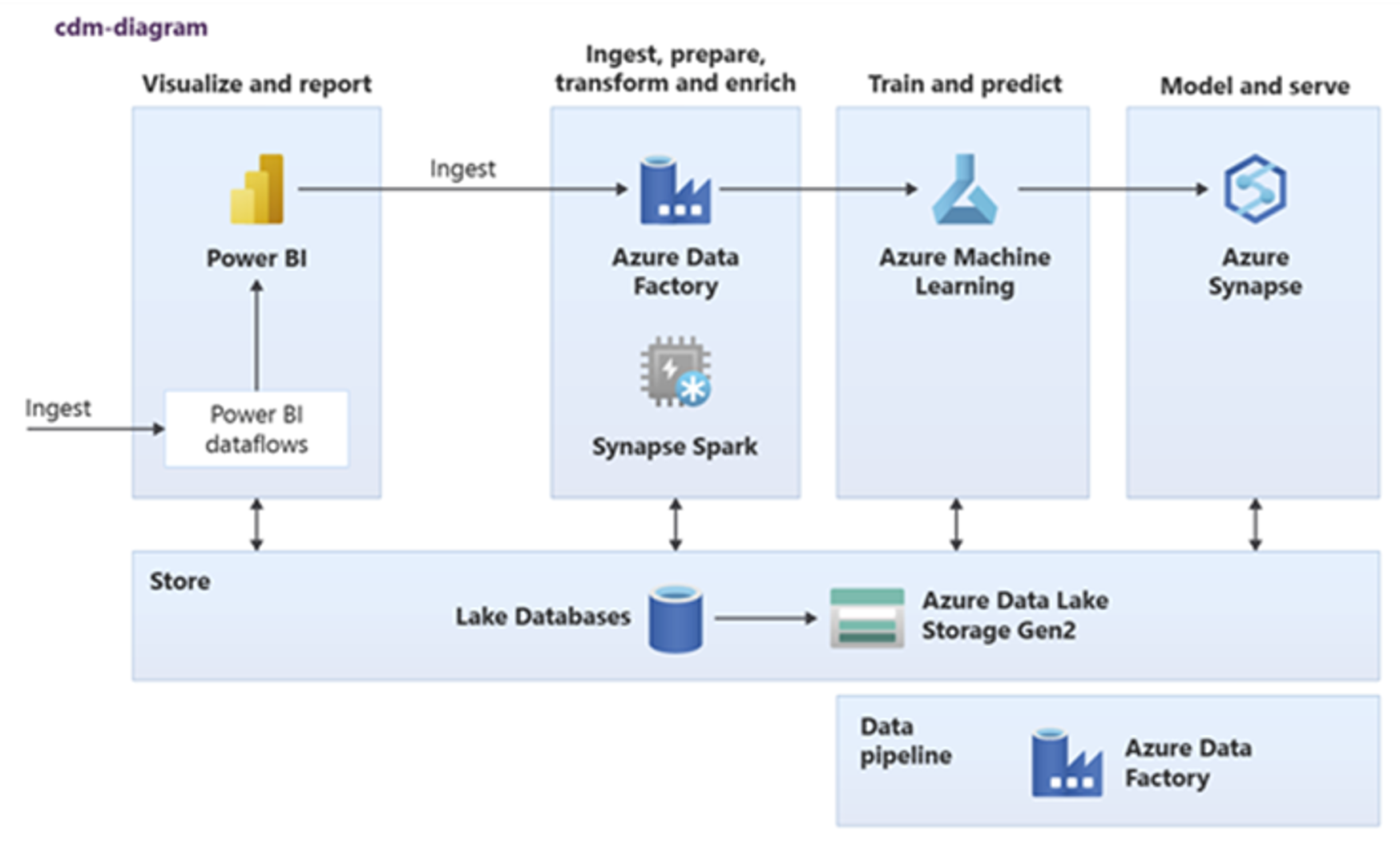
Suggerimento
Integrare i dati per creare entità logiche di database Lake nell'archiviazione condivisa per ottimizzare il riutilizzo degli asset di dati comuni.
Integrazione con le tecnologie di data science Microsoft in Azure
Un altro obiettivo chiave per la modernizzazione di un data warehouse consiste nel produrre informazioni dettagliate per un vantaggio competitivo. È possibile produrre informazioni dettagliate integrando il data warehouse di cui è stata eseguita la migrazione con le tecnologie di data science Microsoft e di terze parti in Azure. Le sezioni seguenti descrivono le tecnologie di apprendimento automatico e data science offerte da Microsoft per vedere come possono essere usate con Azure Synapse in un ambiente di data warehouse moderno.
Tecnologie Microsoft per il data science in Azure
Microsoft offre una gamma di tecnologie che supportano l'analisi avanzata. Con queste tecnologie, è possibile creare modelli analitici predittivi usando l'apprendimento automatico o analizzare dati non strutturati usando il Deep Learning. Tali tecnologie includono:
Studio di Azure Machine Learning
Azure Machine Learning
Notebook del pool di Spark di Azure Synapse
ML.NET (API, interfaccia della riga di comando o ML.NET Model Builder per Visual Studio)
.NET per Apache Spark
Gli scienziati dei dati possono usare RStudio (R) e Jupyter Notebook (Python) per sviluppare modelli analitici oppure possono usare framework come Keras o TensorFlow.
Suggerimento
Sviluppare modelli di Machine Learning usando un approccio senza codice o con codice ridotto oppure usando linguaggi di programmazione come Python, R e .NET.
Studio di Azure Machine Learning
Studio di Azure Machine Learning è un servizio cloud completamente gestito che consente di creare, distribuire e condividere l'analisi predittiva usando un'interfaccia utente basata sul Web con trascinamento della selezione. Lo screenshot seguente mostra l'interfaccia utente di studio di Azure Machine Learning.

Azure Machine Learning
Azure Machine Learning offre un SDK e servizi per Python che supportano la preparazione rapida dei dati oltre al training e alla distribuzione di modelli di Machine Learning. È possibile usare Azure Machine Learning nei notebook di Azure usando Jupyter Notebook, con framework open source, ad esempio PyTorch, TensorFlow, scikit-learn o Spark MLlib, la libreria di Machine Learning per Spark.
Suggerimento
Azure Machine Learning offre un SDK per lo sviluppo di modelli di Machine Learning usando diversi framework open source.
È anche possibile usare Azure Machine Learning per creare pipeline di Machine Learning che gestiscono il flusso di lavoro end-to-end, eseguono il ridimensionamento a livello di programmazione nel cloud e distribuiscono modelli sia nel cloud che nei dispositivi perimetrali. Azure Machine Learning contiene aree di lavoro, ovvero spazi logici che è possibile creare manualmente o a livello di programmazione nel portale di Azure. Queste aree di lavoro mantengono destinazioni di calcolo, esperimenti, archivi dati, modelli di Machine Learning con training, immagini Docker e servizi distribuiti in un'unica posizione per consentire ai team di collaborare. È possibile usare Azure Machine Learning in Visual Studio con l'estensione di Visual Studio per l'intelligenza artificiale.
Suggerimento
Organizzare e gestire archivi dati correlati, esperimenti, modelli con training, immagini Docker e servizi distribuiti nelle aree di lavoro.
Notebook del pool di Spark di Azure Synapse
Un notebook del pool di Spark di Azure Synapse Analytics è un servizio Apache Spark ottimizzato per Azure. Con il notebook del pool di Spark di Azure Synapse:
Gli scienziati dei dati possono creare ed eseguire processi di preparazione dei dati scalabili usando Data Factory.
Gli scienziati dei dati possono creare ed eseguire modelli di Machine Learning su larga scala usando notebook scritti in linguaggi come Scala, R, Python, Java e SQL per visualizzare i risultati.
Suggerimento
Spark di Azure Synapse è un'offerta Spark come servizio dinamicamente scalabile di Microsoft, Spark offre un'esecuzione scalabile di preparazione dei dati, sviluppo di modelli ed esecuzione di modelli distribuiti.
I processi in esecuzione nei notebook del pool di Spark di Azure Synapse possono recuperare, elaborare e analizzare i dati su larga scala da Archiviazione BLOB di Azure, Data Lake Storage, Azure Synapse, HDInsight e servizi di dati di streaming come Apache Kafka.
Suggerimento
Spark di Azure Synapse può accedere ai dati in un'ampia gamma di archivi dati dell'ecosistema analitico Microsoft in Azure.
I notebook del pool di Spark di Azure Synapse supportano la scalabilità automatica e la terminazione automatica per ridurre il costo totale di proprietà (TCO). Gli scienziati dei dati possono usare il framework open source MLflow per gestire il ciclo di vita di Machine Learning.
ML.NET
ML.NET è un framework di Machine Learning open source multipiattaforma per Windows, Linux, macOS. Microsoft ha creato ML.NET in modo che gli sviluppatori .NET possano usare strumenti esistenti, ad esempio ML.NET Model Builder per Visual Studio, per sviluppare modelli di Machine Learning personalizzati e integrarli nelle applicazioni .NET.
Suggerimento
Microsoft ha esteso la sua funzionalità di Machine Learning agli sviluppatori .NET.
.NET per Apache Spark
.NET per Apache Spark estende il supporto di Spark oltre a R, Scala, Python e Java a .NET e mira a rendere Spark accessibile agli sviluppatori .NET in tutte le API di Spark. Anche se .NET per Apache Spark è attualmente disponibile solo in Apache Spark in HDInsight, Microsoft intende rendere .NET per Apache Spark disponibile nei notebook del pool di Spark di Azure Synapse.
Usare Azure Synapse Analytics con il data warehouse
Per combinare i modelli di Machine Learning con Azure Synapse, è possibile:
Usare i modelli di Machine Learning in batch o in tempo reale sui dati di streaming per produrre nuove informazioni dettagliate e aggiungere tali informazioni dettagliate a ciò che si conosce già in Azure Synapse.
Usare i dati in Azure Synapse per sviluppare ed eseguire il training di nuovi modelli predittivi per la distribuzione in altre posizioni, ad esempio in altre applicazioni.
Distribuire i modelli di Machine Learning, inclusi i modelli sottoposti a training in altre applicazioni, in Azure Synapse per analizzare i dati nel data warehouse e promuovere un nuovo valore aziendale.
Suggerimento
Eseguire il training, testare, valutare ed eseguire i modelli di Machine Learning su larga scala nei notebook del pool di Spark di Azure Synapse usando i dati in Azure Synapse.
Gli scienziati dei dati possono usare notebook RStudio, Jupyter Notebook e il pool di Spark di Azure Synapse insieme ad Azure Machine Learning per sviluppare modelli di Machine Learning eseguiti su larga scala nei notebook del pool di Spark di Azure Synapse usando i dati in Azure Synapse. Ad esempio, gli scienziati dei dati potrebbero creare un modello non supervisionato per segmentare i clienti e promuovere campagne di marketing diverse. Usare l'apprendimento automatico supervisionato per eseguire il training di un modello per prevedere un risultato specifico, ad esempio per stimare la propensione di un cliente alla varianza o per consigliare l'offerta migliore successiva affinché un cliente provi ad aumentare il valore. Il diagramma seguente illustra come usare Azure Synapse per Azure Machine Learning.
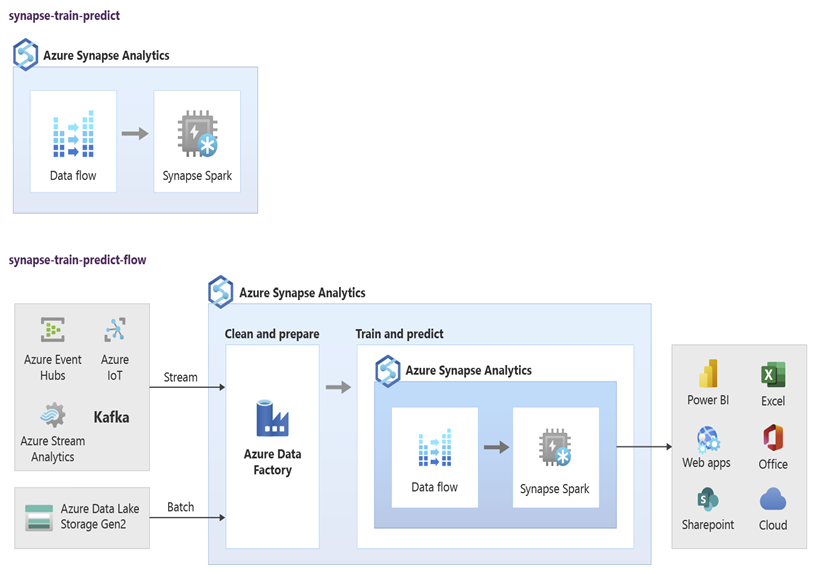
In un altro scenario, è possibile inserire dati di social network o dati dei siti Web di riesame in Data Lake Storage, quindi preparare e analizzare i dati su larga scala in un notebook del pool di Spark di Azure Synapse usando l'elaborazione del linguaggio naturale per assegnare punteggi alla valutazione dei clienti sui prodotti o sul marchio. È quindi possibile aggiungere tali punteggi al data warehouse. Usando l'analisi dei Big Data per comprendere l'effetto della valutazione negativa sulle vendite dei prodotti, si aggiunge a ciò che si conosce già nel data warehouse.
Suggerimento
Produrre nuove informazioni dettagliate usando Machine Learning in Azure in batch o in tempo reale e aggiungere ciò che si conosce nel data warehouse.
Integrare i dati di streaming live in Azure Synapse Analytics
Quando si analizzano i dati in un data warehouse moderno, è necessario essere in grado di analizzare i dati di streaming in tempo reale e aggiungerli ai dati cronologici nel data warehouse. Un esempio è la combinazione di dati IoT con dati di prodotto o asset.
Suggerimento
Integrare il data warehouse con i dati in streaming da dispositivi IoT o clickstream.
Dopo aver eseguito la migrazione del data warehouse ad Azure Synapse, è possibile introdurre l'integrazione dei dati in streaming live come parte di un esercizio di modernizzazione del data warehouse sfruttando le funzionalità aggiuntive in Azure Synapse. A tale scopo, inserire i dati di streaming tramite Hub eventi, altre tecnologie come Apache Kafka o potenzialmente lo strumento ETL esistente se supporta le origini dati di streaming. Archiviare i dati in Data Lake Storage. Creare quindi una tabella esterna in Azure Synapse usando PolyBase e puntare i dati trasmessi in Data Lake Storage a questa in modo che il data warehouse contenga ora nuove tabelle che forniscono l'accesso ai dati di streaming in tempo reale. Eseguire una query sulla tabella esterna come se i dati si trovassero nel data warehouse usando T-SQL standard da qualsiasi strumento di business intelligence che abbia accesso ad Azure Synapse. È anche possibile unire i dati di streaming ad altre tabelle con dati cronologici per creare visualizzazioni che uniscono dati di streaming live a dati cronologici per semplificare l'accesso ai dati da parte degli utenti aziendali.
Suggerimento
Inserire dati di streaming in Data Lake Storage da Hub eventi o Apache Kafka e accedere ai dati da Azure Synapse usando le tabelle esterne di PolyBase.
Nel diagramma seguente un data warehouse in tempo reale in Azure Synapse è integrato con i dati di streaming in Data Lake Storage.
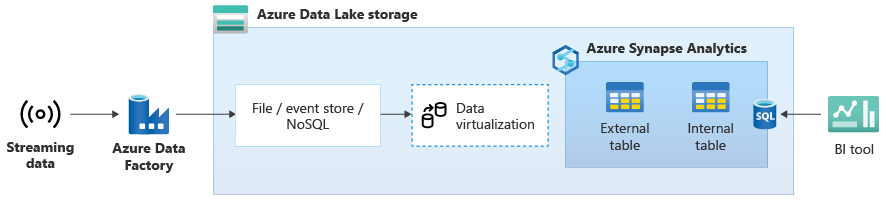
Creare un data warehouse logico con PolyBase
Con PolyBase è possibile creare un data warehouse logico per semplificare l'accesso degli utenti a più archivi dati analitici. Molte aziende hanno adottato negli ultimi anni archivi dati analitici "ottimizzati per il carico di lavoro" oltre ai data warehouse. Le piattaforme analitiche in Azure includono:
Data Lake Storage con il notebook del pool di Spark di Azure Synapse (Spark come servizio) per l'analisi dei Big Data.
HDInsight (Hadoop come servizio), anche per l'analisi dei Big Data.
Database a grafo NoSQL per l'analisi dei grafi, operazione che può essere eseguita in Azure Cosmos DB.
Hub eventi e Analisi di flusso, per l'analisi in tempo reale dei dati in movimento.
Potresti esistere equivalenti non Microsoft di queste piattaforme o un sistema di gestione dei dati master (MDM) a cui è necessario accedere per dati attendibili coerenti su clienti, fornitori, prodotti, asset e altro ancora.
Suggerimento
PolyBase semplifica l'accesso a più archivi dati analitici sottostanti in Azure per semplificare l'accesso da parte degli utenti aziendali.
Queste piattaforme analitiche sono emerse a causa dell'esplosione di nuove origini dati all'interno e all'esterno dell'azienda e della richiesta da parte degli utenti aziendali di acquisire e analizzare i nuovi dati. Le nuove origini dati includono:
Dati generati dal computer, ad esempio dati del sensore IoT e dati clickstream.
Dati generati dall'uomo, ad esempio dati di social network, dati di siti Web di revisione, posta elettronica in ingresso dei clienti, immagini e video.
Altri dati esterni, ad esempio dati aperti della pubblica amministrazione e dati relativi al meteo.
Questi nuovi dati vanno oltre i dati delle transazioni strutturati e le origini dati principali che in genere alimentano i data warehouse e spesso includono:
- Dati semistrutturati come JSON, XML o Avro.
- Dati non strutturati come testo, voce, immagini o video, che sono più complessi da elaborare e analizzare.
- Dati di volume elevato, dati ad alta velocità o entrambi.
Di conseguenza, sono emersi nuovi tipi di analisi più complessi, ad esempio l'elaborazione del linguaggio naturale, l'analisi dei grafi, il Deep Learning, l'analisi di streaming o l'analisi complessa di grandi volumi di dati strutturati. Questi tipi di analisi in genere non avvengono in un data warehouse, quindi non sorprende vedere piattaforme analitiche diverse per diversi tipi di carichi di lavoro analitici, come illustrato nel diagramma seguente.
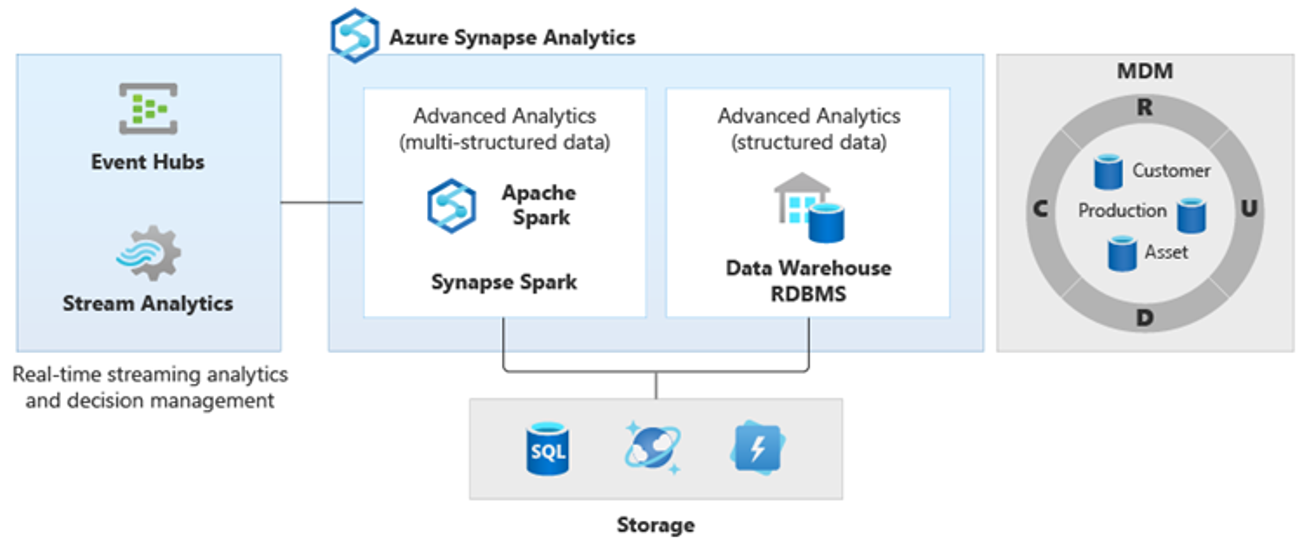
Suggerimento
La possibilità di creare dati in più archivi dati analitici è simile a quanto avviene in un unico sistema e la possibilità di aggiungerli ad Azure Synapse è nota come architettura logica del data warehouse.
Poiché queste piattaforme producono nuove informazioni dettagliate, è normale vedere un requisito per combinare le nuove informazioni dettagliate con ciò che si conosce già in Azure Synapse, che è ciò che PolyBase rende possibile.
Usando la virtualizzazione dei dati di PolyBase all'interno di Azure Synapse, è possibile implementare un data warehouse logico in cui i dati in Azure Synapse vengono aggiunti ai dati in altri archivi dati analitici di Azure e locali, ad esempio HDInsight, Azure Cosmos DB o flusso di dati in streaming in Data Lake Storage da Analisi di flusso o Hub eventi. Questo approccio riduce la complessità per gli utenti, che accedono a tabelle esterne in Azure Synapse e non devono sapere che i dati a cui accedono vengono archiviati in più sistemi analitici sottostanti. Il diagramma seguente mostra una struttura complessa del data warehouse a cui si accede tramite metodi di interfaccia utente relativamente più semplici ma comunque potenti.
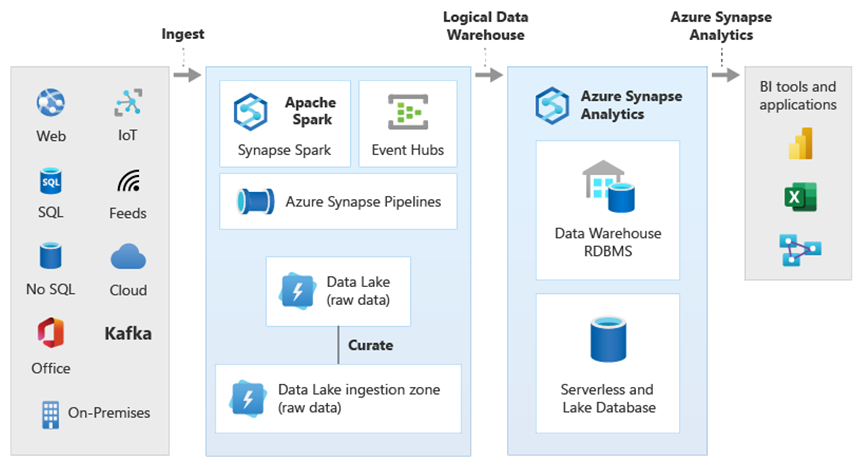
Il diagramma mostra come è possibile combinare altre tecnologie nell'ecosistema analitico Microsoft con la funzionalità dell'architettura del data warehouse logico in Azure Synapse. Ad esempio, è possibile inserire dati in Data Lake Storage e curare i dati usando Data Factory per creare prodotti dati attendibili che rappresentano le entità dati logiche del database Lake di Microsoft. Questi dati attendibili e comunemente riconosciuti possono quindi essere usati e riutilizzati in ambienti analitici diversi, ad esempio Azure Synapse, notebook del pool di Spark di Azure Synapse o Azure Cosmos DB. Tutte le informazioni dettagliate prodotte in questi ambienti sono accessibili tramite un livello di virtualizzazione dei dati del data warehouse logico reso possibile da PolyBase.
Suggerimento
Un'architettura del data warehouse logico semplifica l'accesso degli utenti aziendali ai dati e aggiunge nuovo valore a ciò che si conosce già nel data warehouse.
Conclusioni
Dopo aver eseguito la migrazione del data warehouse ad Azure Synapse, è possibile sfruttare altre tecnologie nell'ecosistema analitico Microsoft. In questo modo, non solo si modernizza il data warehouse, ma si apportano informazioni dettagliate prodotte in altri archivi dati analitici di Azure in un'architettura analitica integrata.
È possibile ampliare l'elaborazione ETL per inserire dati di qualsiasi tipo in Data Lake Storage e quindi preparare e integrare i dati su larga scala usando Data Factory per produrre asset di dati attendibili e comunemente riconosciuti. Tali asset possono essere utilizzati dal data warehouse e sono accessibili per gli scienziati dei dati e altre applicazioni. È possibile creare pipeline analitiche orientate in tempo reale e batch e creare modelli di Machine Learning da eseguire in batch, in tempo reale sui dati di streaming e su richiesta come servizio.
È possibile usare PolyBase o COPY INTO per andare oltre il data warehouse e semplificare l'accesso alle informazioni dettagliate da più piattaforme analitiche sottostanti in Azure. A tale scopo, è possibile creare visualizzazioni olistiche e integrate in un data warehouse logico che supportino l'accesso a streaming, Big Data e informazioni dettagliate del data warehouse tradizionali da applicazioni e strumenti di business intelligence.
Eseguendo la migrazione del data warehouse ad Azure Synapse, è possibile sfruttare l'ecosistema analitico Microsoft avanzato in esecuzione in Azure per promuovere un nuovo valore nell'azienda.
Passaggi successivi
Per informazioni sulla migrazione a un pool SQL dedicato, vedere Eseguire la migrazione di un data warehouse a un pool SQL dedicato in Azure Synapse Analytics.