Usare Synapse Studio per monitorare le applicazioni di Apache Spark
Con Azure Synapse Analytics è possibile usare Apache Spark per eseguire notebook, processi e altri tipi di applicazioni nei pool di Apache Spark nell'area di lavoro.
Questo articolo illustra come monitorare le applicazioni Apache Spark, consentendo di tenere sotto controllo lo stato più recente, i problemi e lo stato di avanzamento.
Visualizzare le applicazioni Apache Spark
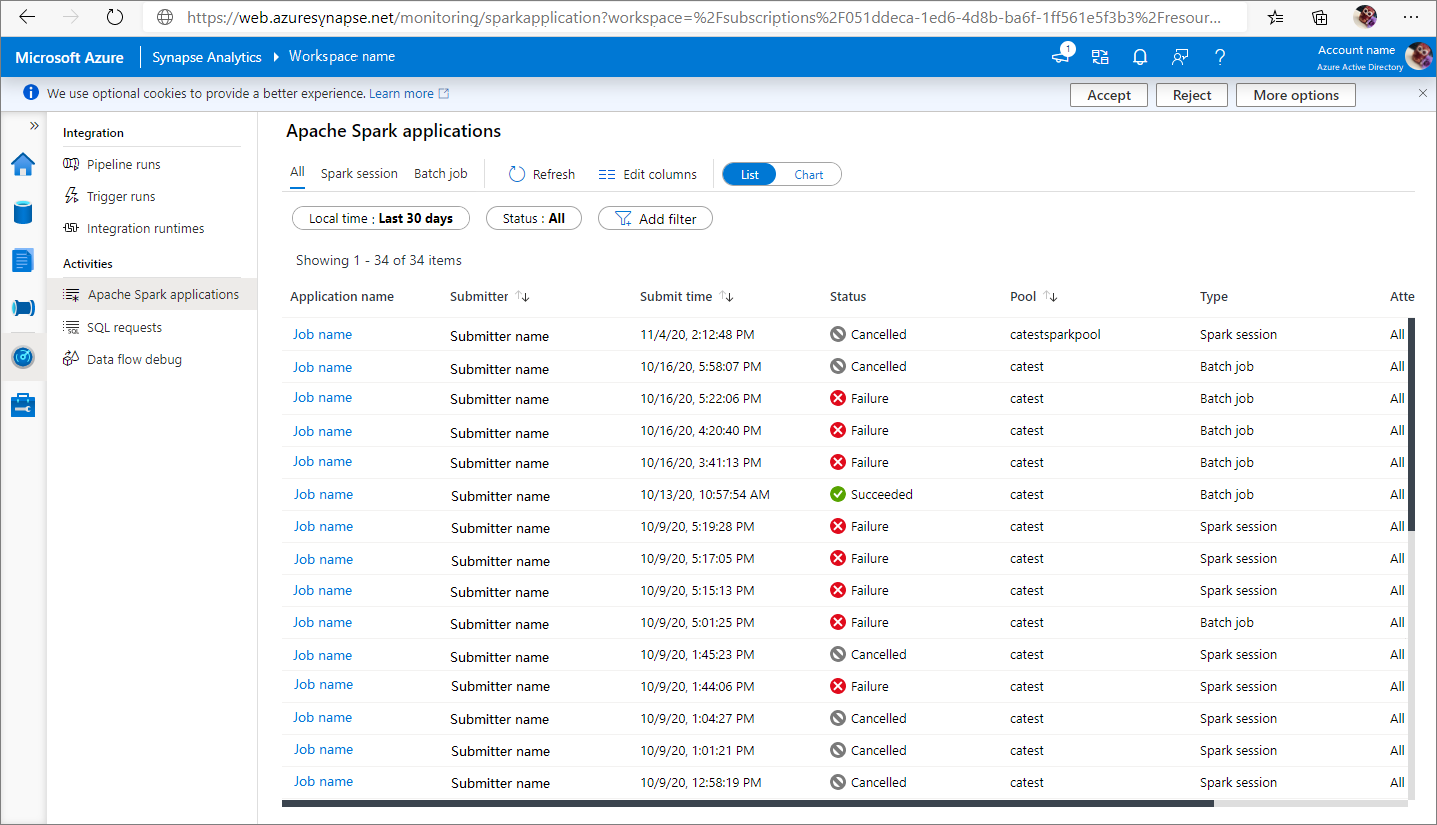
È possibile visualizzare tutte le applicazioni Apache Spark da Monitoraggio ->applicazioni Apache Spark.
Visualizzare le applicazioni Apache Spark completate
Aprire Monitoraggio e quindi selezionare Applicazioni Apache Spark. Per visualizzare i dettagli sulle applicazioni Apache Spark completate, selezionare l'applicazione Apache Spark.

Controllare le attività completate, lo statoe la durata totale.
Aggiornare il processo.
Fare clic su Confronta applicazioni per usare la funzionalità di confronto. Per altre informazioni su questa funzionalità, vedere Confrontare le applicazioni Apache Spark.
Fare clic sul server cronologia Spark per aprire la pagina Server cronologia.
Controllare le informazioni di Riepilogo.
Controllare la diagnostica nella scheda Diagnostica.
Controllare i log. È possibile visualizzare il log completo dei log Livy, Preavvio e Driver log selezionando diverse opzioni nell'elenco a discesa. È anche possibile recuperare direttamente le informazioni di log necessarie eseguendo la ricerca di parole chiave. Fare clic su Scarica log per scaricare le informazioni di log in locale e selezionare la casella di controllo Filtra errori e avvisi per filtrare gli errori e gli avvisi necessari.
È possibile visualizzare una panoramica del processo nel grafico del processo generato. Per impostazione predefinita, il grafico mostra tutti i processi. È possibile filtrare questa visualizzazione in base all'ID processo.
Per impostazione predefinita, la visualizzazione Stato è selezionata. È possibile controllare il flusso di dati selezionando Stato/Letti/Scritti/Durata nell'elenco a discesa Visualizza.
Per riprodurre il processo, fare clic sul pulsante Riproduzione. È possibile fare clic sul pulsante Arresta in qualsiasi momento per arrestarlo.
Usare la barra di scorrimento per ingrandire e ridurre il grafico del processo, è anche possibile selezionare Adatta alla finestra per adattarlo allo schermo.

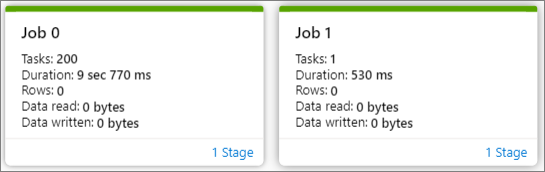
Il nodo del grafico del processo visualizza le informazioni seguenti per ogni fase:
ID processo
Numero attività
Durata
Numero di righe
Dati letti: la somma delle dimensioni di input e delle dimensioni dei dati casuali letti
Dati scritti: la somma delle dimensioni di output e delle dimensioni dei dati casuali scritti
Numero fase
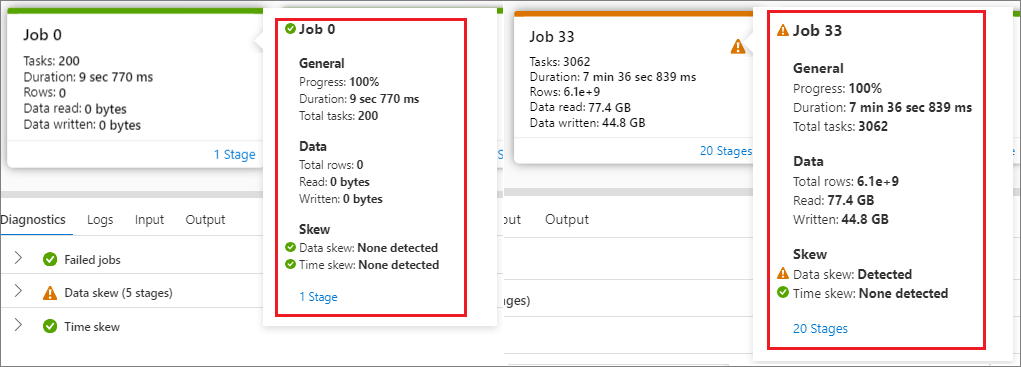
Passare il puntatore del mouse su un processo e i dettagli del processo verranno visualizzati nella descrizione comando:
Icona dello stato del processo: se lo stato del processo ha esito positivo, verrà visualizzato come verde "√"; se il processo rileva un problema, verrà visualizzato un "!" giallo
ID processo
Parte generale:
- Avanzamento
- Durata
- Numero totale di attività
Parte dati:
- Numero totale righe
- Dimensioni di lettura
- Dimensioni di scrittura
Parte asimmetria:
- Asimmetria dei dati
- Sfasamento dell'ora
Numero fase
Fare clic su Numero fase per espandere tutte le fasi contenute nel processo. Fare clic su Comprimi accanto all'ID processo per comprimere tutte le fasi del processo.
Fare clic su Visualizza dettagli in un grafico di fase, quindi verranno visualizzati i dettagli di una fase.


Monitorare lo stato dell'applicazione Apache Spark
Aprire Monitoraggio e quindi selezionare Applicazioni Apache Spark. Per visualizzare i dettagli sulle applicazioni Apache Spark in esecuzione, selezionare l'applicazione Apache Spark inviata. Se l'applicazione di Apache Spark è ancora in esecuzione, è possibile monitorare lo stato di avanzamento.

Controllare le attività completate, lo statoe la durata totale.
Annullare l'applicazione Apache Spark.
Aggiornare il processo.
Fare clic sul pulsante Interfaccia utente Spark per passare alla pagina Processo Spark.
Per Grafico processi, Riepilogo, Diagnostica, Log. È possibile visualizzare una panoramica del processo nel grafico del processo generato. Vedere i passaggi da 5 a 15 di Visualizzazione delle applicazioni Apache Spark completate.

Visualizzare le applicazioni Apache Spark annullate
Aprire Monitoraggio e quindi selezionare Applicazioni Apache Spark. Per visualizzare i dettagli sulle applicazioni Apache Spark annullate, selezionare l'applicazione Apache Spark.

Controllare le attività completate, lo statoe la durata totale.
Aggiornare il processo.
Fare clic su Confronta applicazioni per usare la funzionalità di confronto. Per altre informazioni su questa funzionalità, vedere Confrontare le applicazioni Apache Spark.
Aprire il collegamento al server cronologia Apache facendo clic su Server cronologia Spark.
Visualizzare il grafico. È possibile visualizzare una panoramica del processo nel grafico del processo generato. Vedere i passaggi da 5 a 15 di Visualizzazione delle applicazioni Apache Spark completate.

Debug dell'applicazione Apache Spark non riuscita
Aprire Monitoraggio e quindi selezionare Applicazioni Apache Spark. Per visualizzare i dettagli sulle applicazioni Apache Spark non riuscite, selezionare l'applicazione Apache Spark.

Controllare le attività completate, lo statoe la durata totale.
Aggiornare il processo.
Fare clic su Confronta applicazioni per usare la funzionalità di confronto. Per altre informazioni su questa funzionalità, vedere Confrontare le applicazioni Apache Spark.
Aprire il collegamento al server cronologia Apache facendo clic su Server cronologia Spark.
Visualizzare il grafico. È possibile visualizzare una panoramica del processo nel grafico del processo generato. Vedere i passaggi da 5 a 15 di Visualizzazione delle applicazioni Apache Spark completate.

Visualizzare i dati di input/output
Selezionare un'applicazione Apache Spark e fare clic sulla scheda dati di input/output per visualizzare le date dell'input e dell'output per l'applicazione Apache Spark. Questa funzione consente di eseguire il debug del processo Spark. E l'origine dati supporta tre metodi di archiviazione: gen1, gen2 e BLOB.
Scheda dei dati di input
Fare clic sul pulsante Copia input per incollare il file di input nel file locale.
Fare clic sul pulsante Esporta in CSV per esportare il file di input in formato CSV.
È possibile cercare i file in base alle parole chiave di input nella casella di ricerca (le parole chiave includono il nome del file, il formato di lettura e il percorso).
È possibile ordinare i file di input facendo clic su Nome, Formato di lettura e percorso.
Usare il mouse per passare il puntatore su un file di input, verrà visualizzata l'icona del pulsante Scarica/Copia percorso/Altro.
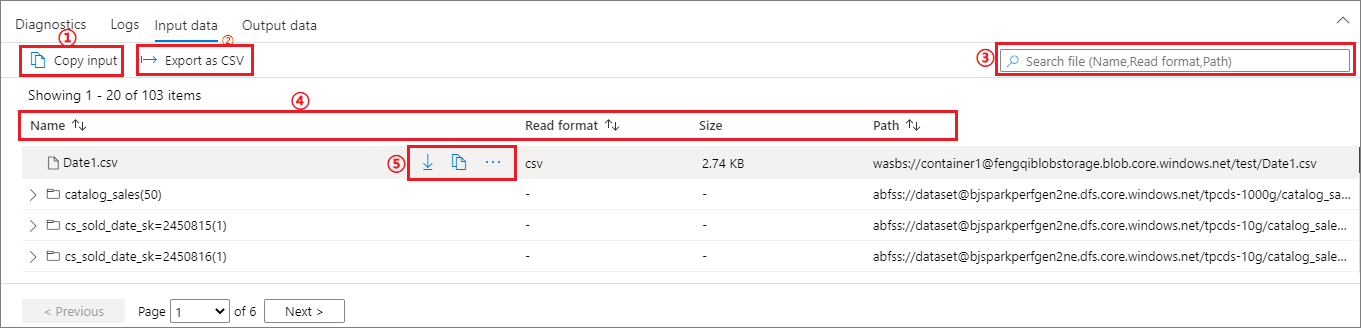
Fare clic sul pulsante Altro. Copia percorso/Mostra in esplora risorse/Proprietà verrà visualizzato nel menu di scelta rapida.
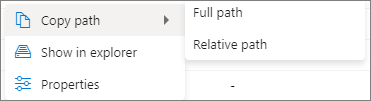
Copia percorso: può copiare il percorso completo e il percorso relativo.
Mostra in Esplora risorse: può passare all'account di archiviazione collegato (collegato ai dati >).
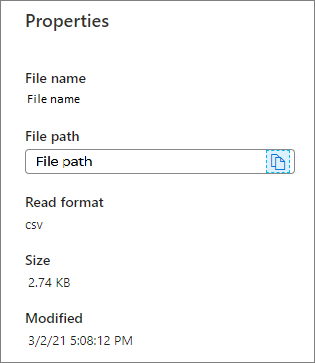
Proprietà: mostra le proprietà di base del file (Nome file/Percorso file/Formato di lettura/Dimensioni/Modifica).
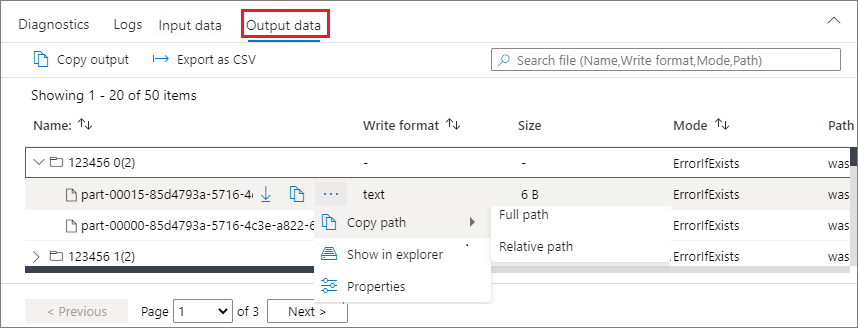
Scheda dei dati di output
Visualizza le stesse funzionalità della scheda di input.
Confrontare le applicazioni Apache Spark
Esistono due modi per confrontare le applicazioni. È possibile confrontare scegliendo Confronta applicazione oppure facendo clic sul pulsante Confronta nel notebook per visualizzarlo nel notebook.
Confrontare in base all'applicazione
Fare clic sul pulsante Confronta applicazioni e scegliere un'applicazione per confrontare le prestazioni. È possibile vedere la differenza tra le due applicazioni.

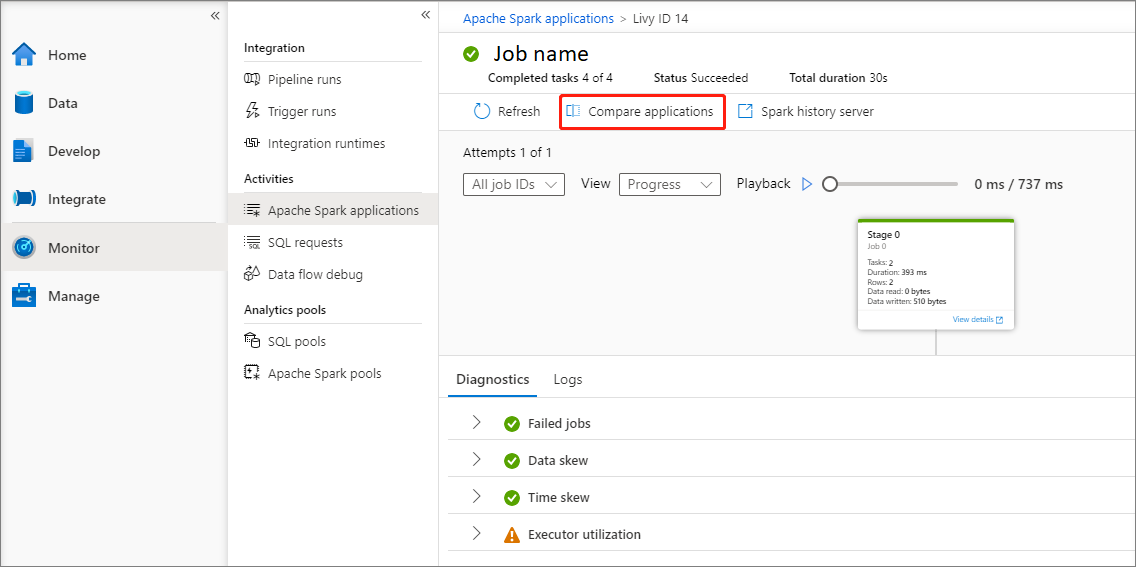
Usare il mouse per passare il puntatore del mouse su un'applicazione e quindi viene visualizzata l'icona Confronta applicazioni.
Fare clic sull'icona Confronta applicazioni e verrà visualizzata la pagina Confronta applicazioni.
Fare clic sul pulsante Scegli applicazione per aprire la pagina Scegli applicazione di confronto.
Quando si sceglie l'applicazione di confronto, è necessario immettere l'URL dell'applicazione o scegliere dall'elenco ricorrente. Fare quindi clic sul pulsante OK.
Il risultato del confronto verrà visualizzato nella pagina delle applicazioni di confronto.
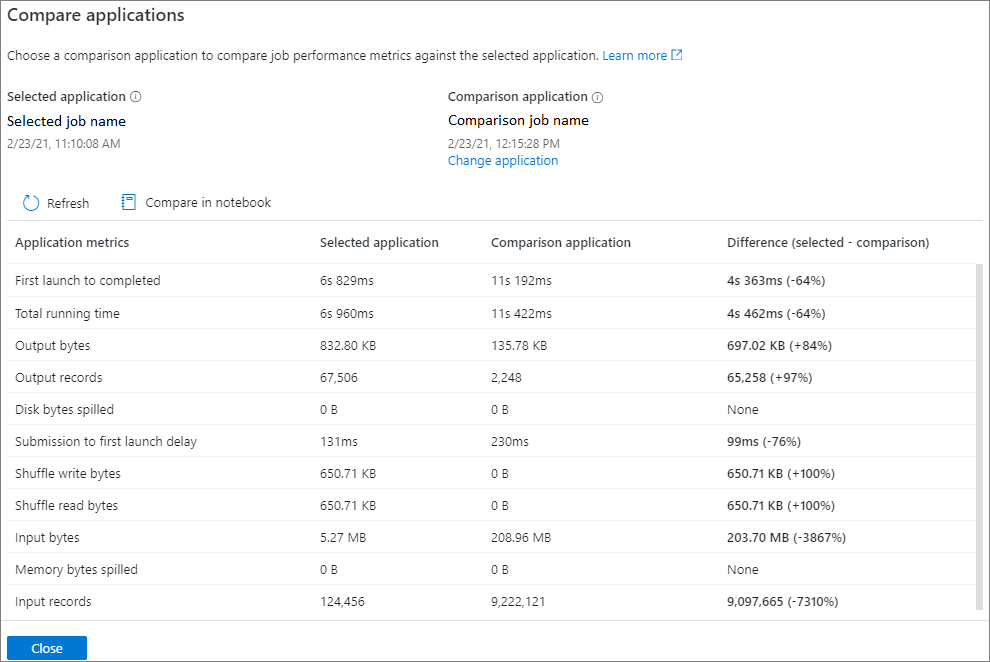
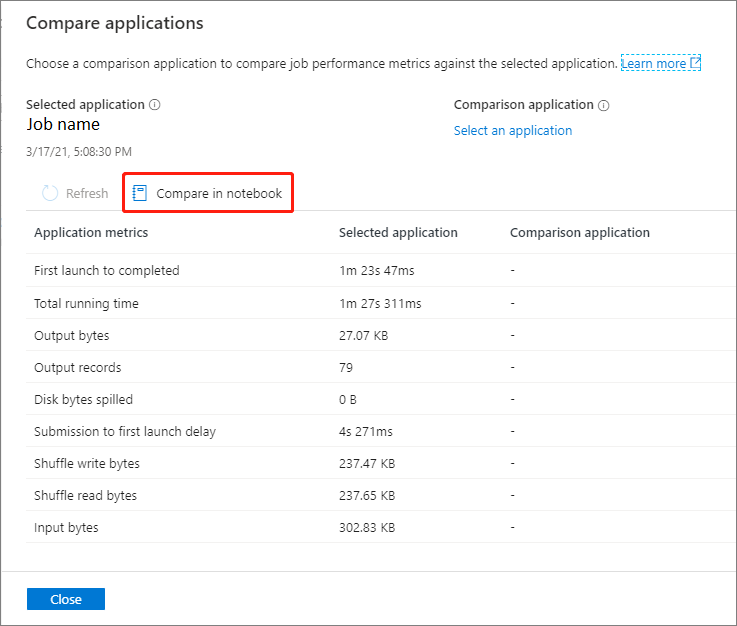
Confrontare nel notebook
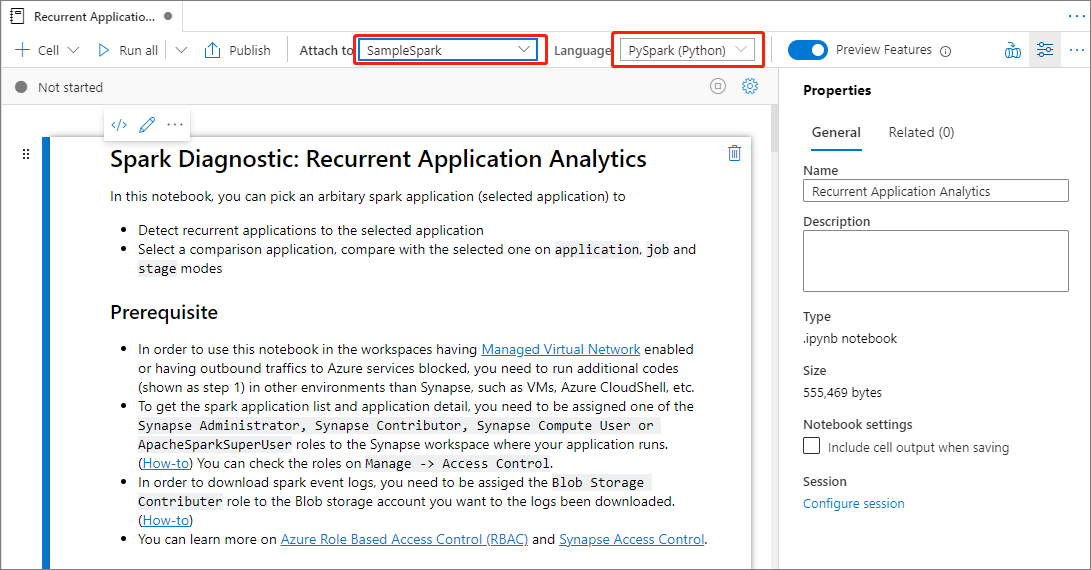
Fare clic sul pulsante Confronta in Notebook nella pagina Confronta applicazioni per aprire il notebook. Il nome predefinito del file con estensione ipynb è Analisi applicazioni ricorrente.
Nel file Notebook: Analisi applicazioni ricorrente è possibile eseguirlo direttamente dopo aver impostato il pool di Spark e il linguaggio.
Passaggi successivi
Per altre informazioni sul monitoraggio delle esecuzioni della pipeline, vedere l'articolo Monitorare le esecuzioni della pipeline usando Synapse Studio.