Guida introduttiva: Creare un pool di Apache Spark serverless con Synapse Studio
Azure Synapse Analytics offre vari motori di analisi che consentono di inserire, trasformare, modellare, analizzare e gestire i dati. Un pool di Apache Spark offre funzionalità di calcolo open source per i Big Data. Dopo aver creato un pool di Apache Spark nell'area di lavoro di Synapse, i dati possono essere caricati, modellati, elaborati e serviti per ottenere informazioni dettagliate.
Questa guida introduttiva descrive i passaggi per creare un pool di Apache Spark in un'area di lavoro di Synapse tramite Synapse Studio.
Importante
La fatturazione delle istanze di Spark viene calcolata con ripartizione proporzionale al minuto, indipendentemente dal fatto che siano in uso o meno. Assicurarsi di arrestare l'istanza di Spark dopo averla usata oppure impostare un timeout breve. Per altre informazioni, vedere la sezione Pulire le risorse di questo articolo.
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
- È necessaria una sottoscrizione di Azure. Se necessario, creare un account Azure gratuito
- Si userà l'area di lavoro di Synapse.
Accedere al portale di Azure
Accedere al portale di Azure
Accedere all'area di lavoro di Synapse
Passare all'area di lavoro di Synapse in cui verrà creato il pool di Apache Spark digitando il nome del servizio (o direttamente il nome della risorsa) nella barra di ricerca.
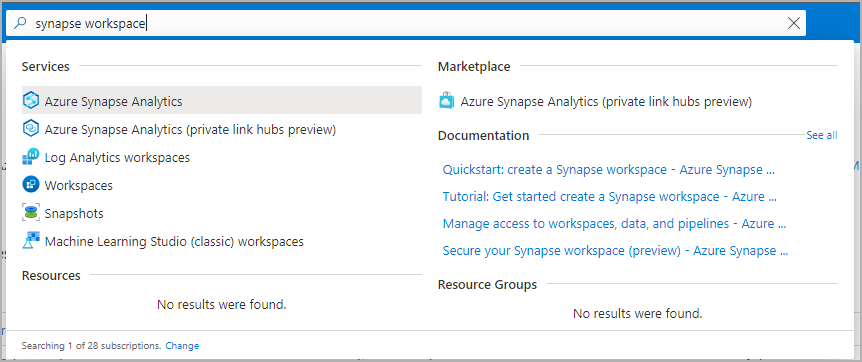
Dall'elenco delle aree di lavoro, digitare il nome (o parte del nome) dell'area di lavoro da aprire. Per questo esempio viene usata un'area di lavoro denominata contosoanalytics.


Avviare Synapse Studio
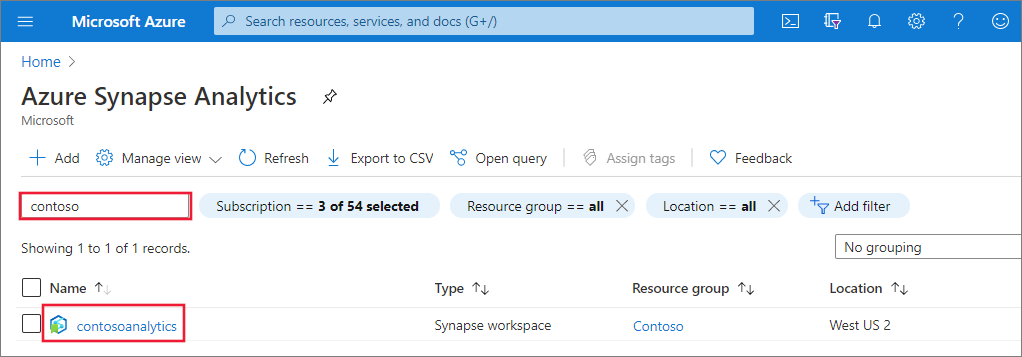
Nella pagina di panoramica dell'area di lavoro selezionare l'URL Web dell'area di lavoro per aprire Synapse Studio.

Creare il pool di Apache Spark in Synapse Studio
Importante
Il runtime di Azure Synapse per Apache Spark 2.4 è stato deprecato e ufficialmente non è supportato a partire da settembre 2023. Dato che Spark 3.1 e Spark 3.2 sono annunciati anche end-of support, si consiglia ai clienti di eseguire la migrazione a Spark 3.3.
Nella home page di Synapse Studio passare all'hub di gestione nel riquadro di navigazione a sinistra selezionando l'icona Gestisci.
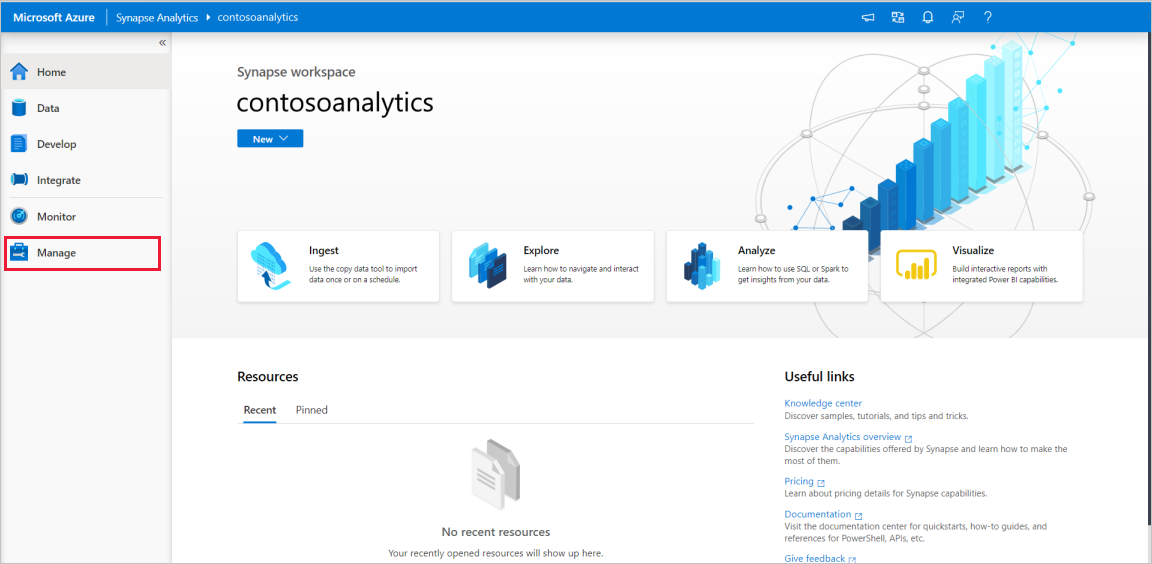
Nell'hub di gestione passare alla sezione Pool di Apache Spark per visualizzare l'elenco corrente dei pool di Apache Spark disponibili nell'area di lavoro.

Selezionare + Nuovo per visualizzare la procedura guidata per la creazione del nuovo pool di Apache Spark.
Immettere i dettagli seguenti nella scheda Informazioni di base:
Impostazione Valore suggerito Descrizione Nome del pool di Apache Spark Un nome di pool valido, ad esempio contososparkSi tratta del nome che avrà il pool di Apache Spark. Dimensioni nodo Piccole (4 vCPU/32 GB) Per questa guida di avvio rapido, impostare questa opzione sulle dimensioni minime per ridurre i costi Autoscale Disabled In questa guida introduttiva la scalabilità automatica non è necessaria. Numero di nodi 8 Usare dimensioni ridotte per limitare i costi per questa guida introduttiva Allocare dinamicamente executor Disabled Questa impostazione esegue il mapping alla proprietà di allocazione dinamica nella configurazione di Spark per l'allocazione degli executor dell'applicazione Spark. In questa guida introduttiva non è necessaria la scalabilità automatica. 
Importante
Esistono limitazioni specifiche per i nomi che possono essere usati dai pool di Apache Spark. I nomi possono contenere solo lettere o numeri, devono essere costituiti da un massimo di 15 caratteri, devono iniziare con una lettera, non possono contenere parole riservate e devono essere univoci nell'area di lavoro.
Nella scheda successiva impostazioni aggiuntive lasciare tutte le impostazioni predefinite.
Selezionare Tag. Prendere in considerazione l'uso dei tag di Azure. Ad esempio, il tag "Owner" o "CreatedBy" per identificare chi ha creato la risorsa e il tag "Environment" per identificare se questa risorsa si trova in Production, Development e così via. Per altre informazioni, vedere Sviluppare la strategia di denominazione e assegnazione di tag per le risorse di Azure. Quando si è pronti, selezionare Rivedi e crea.
Nella scheda Rivedi e crea verificare che i dettagli siano corretti in base a quanto specificato in precedenza, quindi selezionare Crea.

Il pool di Apache Spark avvierà il processo di provisioning.
Al termine del provisioning, il nuovo pool di Apache Spark verrà visualizzato nell'elenco.






Eliminare le risorse del pool di Apache Spark tramite Synapse Studio
I passaggi seguenti eliminano il pool di Apache Spark dall'area di lavoro usando Synapse Studio.
Avviso
L'eliminazione di un pool SQL determina la rimozione del motore di analisi dall'area di lavoro. Non sarà più possibile connettersi al pool di Spark e tutti i notebook, le query e le pipeline che lo usano non funzioneranno più.
Per eliminare il pool di Apache Spark, seguire questa procedura:
Passare al pool di Apache Spark nell'hub di gestione in Synapse Studio.
Selezionare i puntini di sospensione accanto al pool di Apache da eliminare (in questo caso contosospark) per visualizzare i comandi per il pool di Apache Spark.
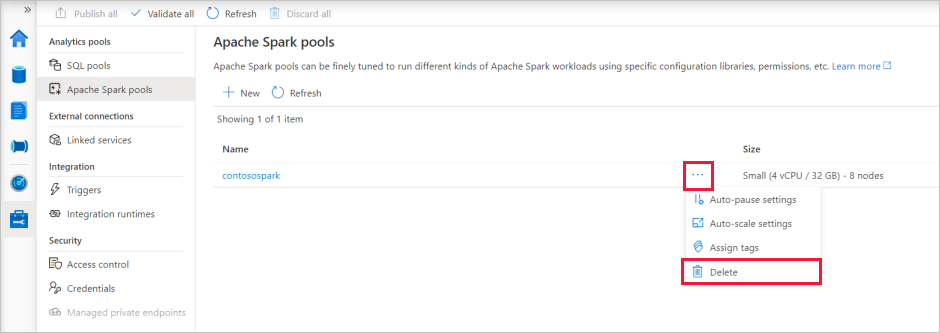
Selezionare Elimina.
Confermare l'eliminazione e premere il pulsante Elimina.
Quando il processo viene completato, il pool di Apache Spark non sarà più elencato nelle risorse dell'area di lavoro.
