Analizzare i dati con Azure Machine Learning
Questa esercitazione usa la finestra di progettazione di Azure Machine Learning per creare un modello di Machine Learning predittivo. Il modello si basa sui dati archiviati in Azure Synapse. Lo scenario per l'esercitazione consiste nel prevedere se un cliente può acquistare una bicicletta o meno così Adventure Works, il negozio di biciclette, può creare una campagna di marketing mirata.
Prerequisiti
Per eseguire questa esercitazione, è necessario:
- un pool SQL precaricati con i dati di esempio AdventureWorksDW. Per effettuare il provisioning di questo pool SQL, vedere Creare un pool SQL e scegliere di caricare i dati di esempio. Se si dispone già di un data warehouse, ma non sono presenti dati di esempio, è possibile caricare manualmente i dati di esempio.
- un'area di lavoro di Azure Machine Learning. Seguire questa esercitazione per creare una nuova.
Ottenere i dati
I dati usati sono nella visualizzazione dbo.vTargetMail in AdventureWorksDW. Per usare l'archivio dati in questa esercitazione, i dati vengono prima esportati in Azure Data Lake Storage account come Azure Synapse attualmente non supportano i set di dati. Azure Data Factory può essere usato per esportare i dati dal data warehouse a Azure Data Lake Storage usando l'attività di copia. Usare la query seguente per l'importazione:
SELECT [CustomerKey]
,[GeographyKey]
,[CustomerAlternateKey]
,[MaritalStatus]
,[Gender]
,cast ([YearlyIncome] as int) as SalaryYear
,[TotalChildren]
,[NumberChildrenAtHome]
,[EnglishEducation]
,[EnglishOccupation]
,[HouseOwnerFlag]
,[NumberCarsOwned]
,[CommuteDistance]
,[Region]
,[Age]
,[BikeBuyer]
FROM [dbo].[vTargetMail]
Una volta disponibili i dati in Azure Data Lake Storage, gli archivi dati in Azure Machine Learning vengono usati per connettersi ai servizi di archiviazione di Azure. Seguire questa procedura per creare un archivio dati e un set di dati corrispondente:
Avviare studio di Azure Machine Learning da portale di Azure o accedere all'studio di Azure Machine Learning.
Fare clic su Archivi dati nel riquadro sinistro nella sezione Gestisci e quindi fare clic su Nuovo archivio dati.
Specificare un nome per l'archivio dati, selezionare il tipo "Archiviazione BLOB di Azure", specificare la posizione e le credenziali. quindi scegliere Crea.
Fare quindi clic su Set di dati nel riquadro sinistro nella sezione Asset . Selezionare Crea set di dati con l'opzione Dall'archivio dati.
Specificare il nome del set di dati e selezionare il tipo da tabulare. Fare quindi clic su Avanti per spostarsi avanti.
In Selezionare o creare un archivio dati selezionare l'opzione Archivio dati creato in precedenza. Selezionare l'archivio dati creato in precedenza. Fare clic su Avanti e specificare le impostazioni del percorso e del file. Assicurarsi di specificare l'intestazione di colonna se i file contengono uno.
Infine, fare clic su Crea per creare il set di dati.
Configurare l'esperimento della finestra di progettazione
Seguire quindi i passaggi seguenti per la configurazione della finestra di progettazione:
Fare clic sulla scheda Designer nel riquadro sinistro nella sezione Autore.
Selezionare Componenti predefiniti facili da usare per creare una nuova pipeline.
Nel riquadro delle impostazioni a destra specificare il nome della pipeline.
Selezionare anche un cluster di calcolo di destinazione per l'intero esperimento nelle impostazioni di un cluster con provisioning precedente. Chiudere il riquadro Impostazioni.
Importare i dati
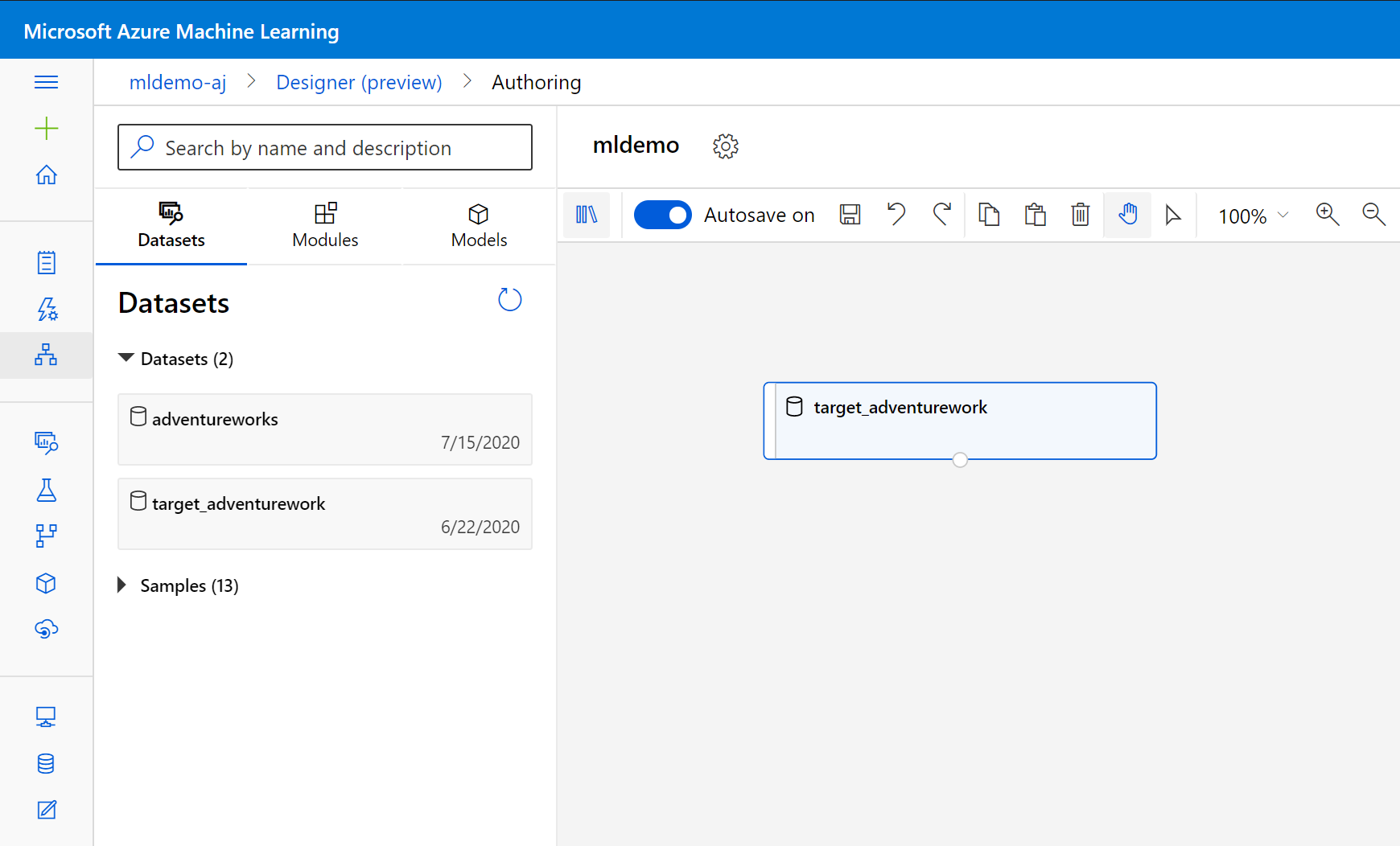
Selezionare la sottotabula Set di dati nel riquadro sinistro sotto la casella di ricerca.
Trascinare il set di dati creato in precedenza nell'area di disegno.
Pulire i dati
Per pulire i dati, eliminare colonne non pertinenti per il modello. Seguire la procedura descritta di seguito:
Selezionare la sottotabula Componenti nel riquadro sinistro.
Trascinare il componente Seleziona colonne nel set di dati inModifica trasformazione < dati nell'area di disegno. Connettere questo componente al componente Set di dati .
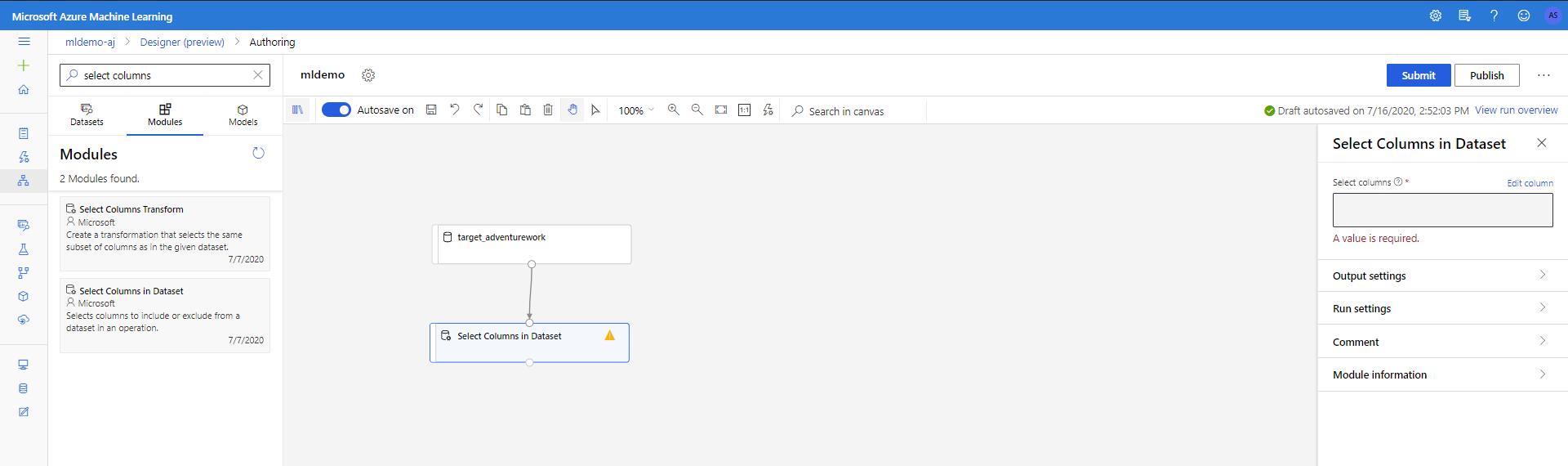
Fare clic sul componente per aprire il riquadro delle proprietà. Fare clic su Modifica colonna per specificare le colonne da eliminare.
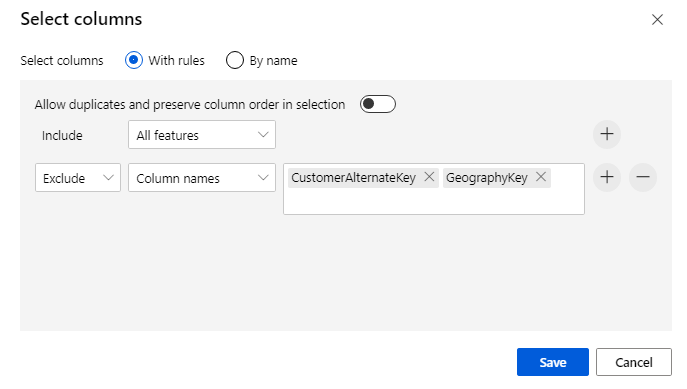
Escludere due colonne: CustomerAlternateKey e GeographyKey. Fare clic su Save (Salva).

Creare il modello
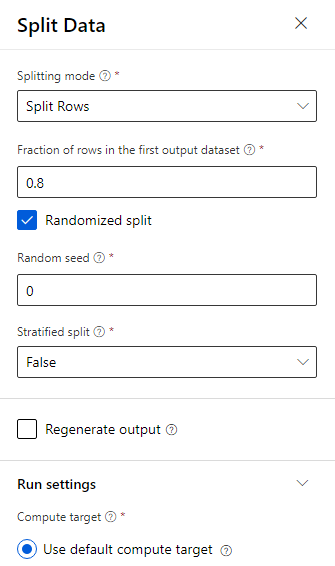
I dati sono suddivisi al 80-20: 80% per eseguire il training di un modello di Machine Learning e il 20% per testare il modello. Gli algoritmi "Two-Class" vengono usati in questo problema di classificazione binaria.
Trascinare il componente Split Data nell'area di disegno.
Nel riquadro delle proprietà immettere 0.8 per Frazione di righe nel primo set di dati di output.
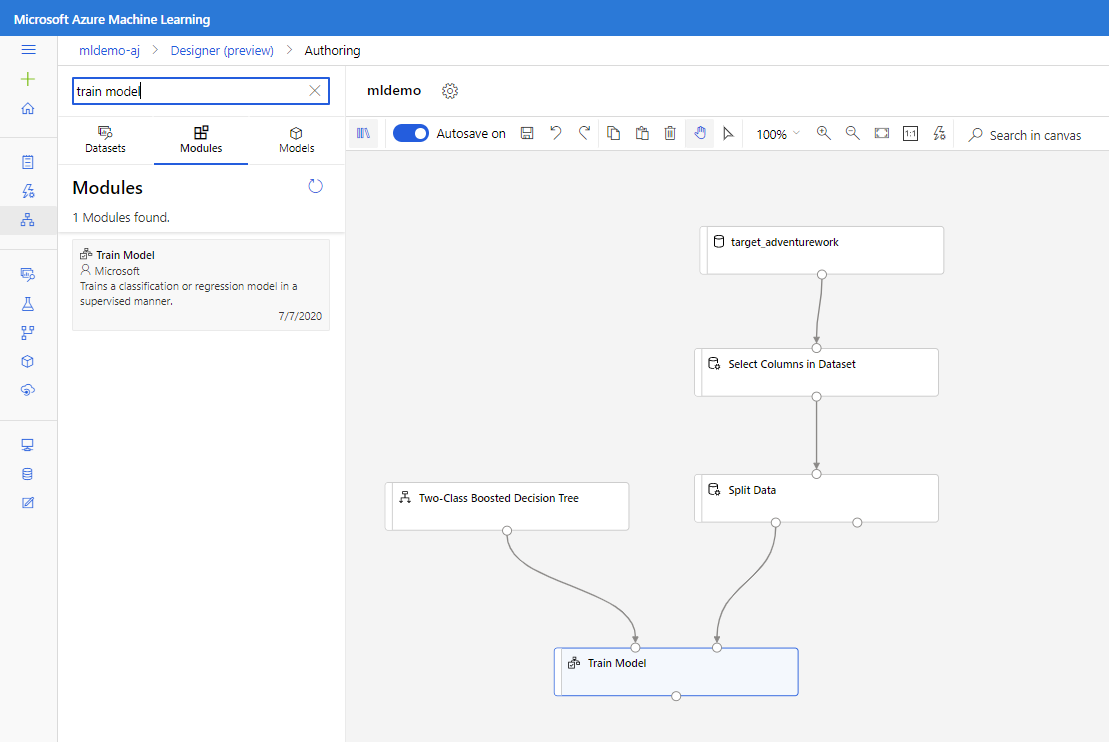
Trascinare il componente Albero delle decisioni incrementato a due classi nell'area di disegno.
Trascinare il componente Train Model nell'area di disegno. Specificare gli input connettendolo ai componenti dell'albero delle decisioni a due classi (algoritmo ML) e Split Data (dati per eseguire il training dell'algoritmo).
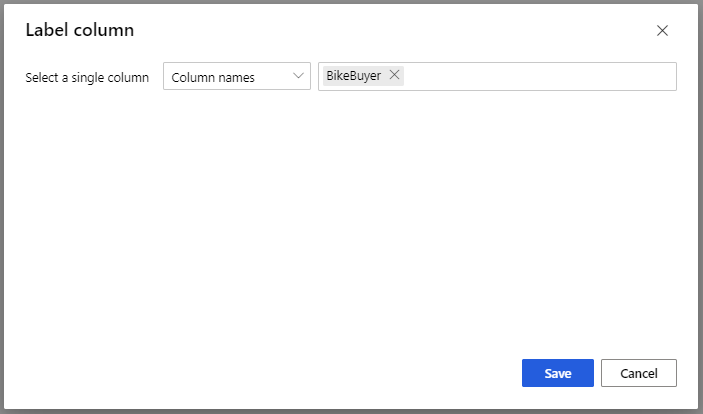
Per Eseguire il training del modello, nell'opzione Colonna Etichetta nel riquadro Proprietà selezionare Modifica colonna. Selezionare la colonna BikeBuyer come colonna per stimare e selezionare Salva.
Assegnare un punteggio al modello
Testare ora come il modello esegue sui dati di test. Due algoritmi diversi verranno confrontati per vedere quali sono le prestazioni migliori. Seguire la procedura descritta di seguito:
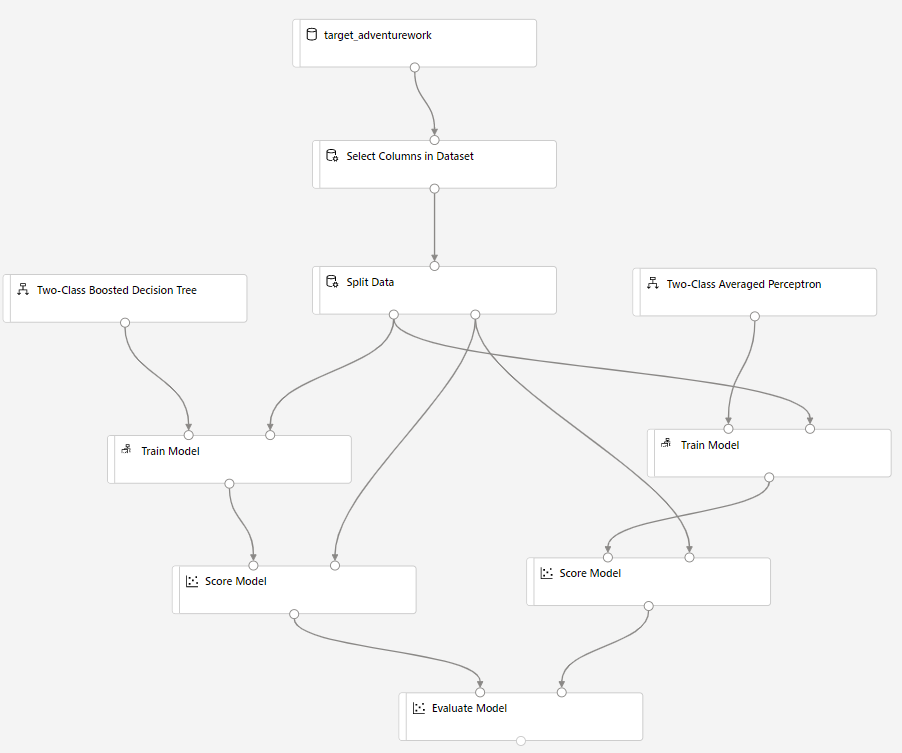
Trascinare il componente Score Model nell'area di disegno e connetterlo ai componenti Train Model e Split Data .
Trascinare la bayron a due classi Media perceptron nell'area di disegno dell'esperimento. Verrà confrontato il modo in cui questo algoritmo viene eseguito rispetto all'albero delle decisioni Two-Class incrementato.
Copiare e incollare i componenti Train Model e Score Model nell'area di disegno.
Trascinare il componente Valuta modello nell'area di disegno per confrontare i due algoritmi.
Fare clic su Invia per configurare l'esecuzione della pipeline.
Al termine dell'esecuzione, fare clic con il pulsante destro del mouse sul componente Valuta modello e scegliere Visualizza risultati valutazione.
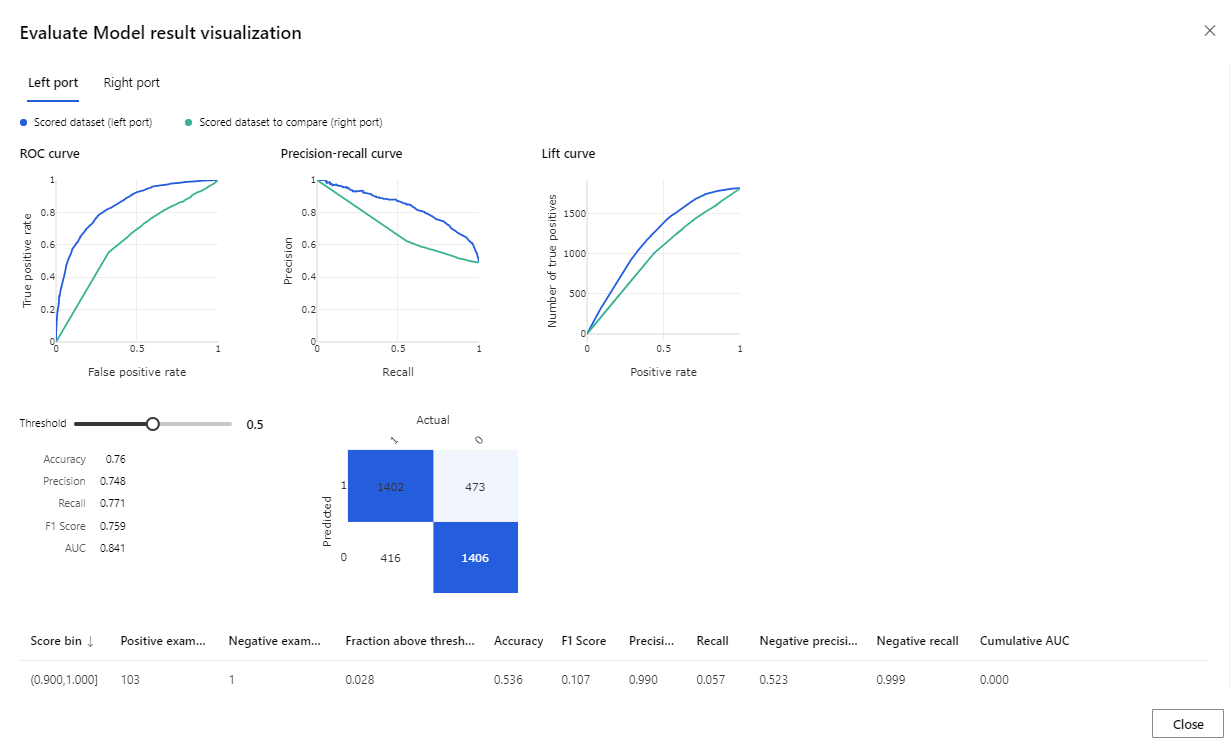

La metrica fornita include curva ROC, diagramma di precisione/recupero e curva lift. Esaminare queste metriche per verificare che il primo modello sia stato eseguito meglio del secondo. Per esaminare il primo modello previsto, fare clic con il pulsante destro del mouse sul componente Score Model e scegliere Visualizza set di dati con punteggio per visualizzare i risultati stimati.
Verranno visualizzate due altre colonne aggiunte al set di dati di test.
- Scored Probabilities: la probabilità che un cliente sia un acquirente di biciclette.
- Scored Labels: la classificazione eseguita dal modello – acquirente di biciclette (1) o non acquirente (0). La soglia di probabilità per le etichette è impostata su 50% e può essere modificata.
Confrontare la colonna BikeBuyer (effettiva) con le etichette segnate (stima), per vedere come è stato eseguito il modello. È quindi possibile usare questo modello per effettuare stime per i nuovi clienti. È possibile pubblicare questo modello come servizio Web o scrivere i risultati in Azure Synapse.
Passaggi successivi
Per altre informazioni su Azure Machine Learning, vedere Introduzione a Machine Learning in Azure.
Informazioni sul punteggio predefinito nel data warehouse, qui.