Linee guida per la progettazione di tabelle distribuite usando il pool SQL dedicato in Azure Synapse Analytics
Questo articolo contiene raccomandazioni per la progettazione di tabelle distribuite con hash e round robin in pool SQL dedicati.
Questo articolo presuppone una certa familiarità con i concetti di distribuzione e spostamento dei dati nel pool SQL dedicato. Per altre informazioni, vedere Architettura di Azure Synapse Analytics.
Che cos'è una tabella distribuita?
Una tabella distribuita viene visualizzata come una singola tabella, ma le righe al suo interno, in realtà, sono archiviate in 60 distribuzioni. Le righe, inoltre, vengono distribuite con un algoritmo hash o round robin.
La distribuzione hash migliora le prestazioni delle query nelle tabelle dei fatti di grandi dimensioni e rappresenta l'argomento principale di questo articolo. La distribuzione round robin consente di aumentare la velocità di caricamento. Queste scelte di progettazione possono contribuire in maniera significativa al miglioramento delle prestazioni delle query e di caricamento.
Un'altra opzione di archiviazione delle tabelle prevede la replica di una tabella di piccole dimensioni in tutti i nodi di calcolo. Per altre informazioni, vedere Linee guida di progettazione per l'uso di tabelle replicate in Azure SQL Data Warehouse. Per scegliere rapidamente tra queste tre opzioni, vedere Tabelle distribuite nell'articolo di panoramica sulle tabelle.
Come parte della progettazione di tabelle, è necessario comprendere quanto più possibile i propri dati e il modo in cui vengono eseguite query sui dati. Ad esempio, considerare queste domande:
- Quali sono le dimensioni della tabella?
- Quanto spesso viene aggiornata la tabella?
- Sono presenti tabelle dei fatti e delle dimensioni in un pool SQL dedicato?
Tabelle con distribuzione hash
Una tabella con distribuzione hash distribuisce le righe della tabella nei vari nodi di calcolo usando una funzione hash deterministica per assegnare ogni riga a una distribuzione.
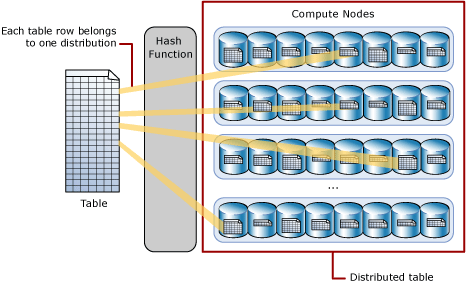
Poiché valori identici eseguono sempre l'hash nella stessa distribuzione, in SQL Analytics sono integrate informazioni sulla posizione delle righe. Nel pool SQL dedicato, queste informazioni vengono usate per ridurre al minimo lo spostamento dei dati durante le query e, di conseguenza, migliorare le prestazioni complessive delle query.
Le tabelle con distribuzione hash sono particolarmente indicate per le tabelle dei fatti di grandi dimensioni in uno schema star. Possono contenere un numero molto elevato di righe e conseguire comunque prestazioni elevate. È necessario considerare anche alcuni aspetti di progettazione per ottenere le prestazioni che il sistema distribuito è in grado di offrire. Uno di questi riguarda la scelta di un o più colonne di distribuzione appropriate, illustrata in questo articolo.
Valutare l'opportunità di usare una tabella con distribuzione hash se:
- La dimensione della tabella su disco è superiore a 2 GB.
- La tabella prevede frequenti operazioni di inserimento, aggiornamento ed eliminazione.
Distribuzione round robin
Una tabella con distribuzione round robin distribuisce le righe della tabella in modo uniforme tra tutte le distribuzioni. L'assegnazione delle righe alle distribuzioni è casuale. A differenza delle tabelle con distribuzione hash, inoltre, non è garantito che valori identici vengano assegnati alla stessa distribuzione.
Di conseguenza, a volte il sistema deve richiamare un'operazione di spostamento dei dati per organizzare meglio i dati e poter risolvere una query. Questo passaggio aggiuntivo può rallentare le query. L'aggiunta di una tabella con distribuzione round robin, ad esempio, richiede una ridistribuzione dei dati, con una conseguente riduzione delle prestazioni.
Valutare l'opportunità di usare la distribuzione round robin per una tabella negli scenari seguenti:
- Quando si inizia come punto di partenza semplice (impostazione predefinita)
- Se non è presente una chiave di join ovvia.
- Se non è presente una colonna candidata ottimale per la distribuzione hash della tabella.
- Se la tabella non condivide una chiave di join comune con altre tabelle.
- Se il join è meno significativo di altri join nella query.
- Quando si tratta di una tabella di staging temporaneo.
L'esercitazione relativa al caricamento dei dati relativi ai taxi di New York illustra un esempio di caricamento dei dati in una tabella di staging con distribuzione round robin.
Scegliere una colonna di distribuzione
Nelle tabelle con distribuzione hash è presente una colonna o un set di distribuzione che rappresenta la chiave hash. Il codice seguente, ad esempio, crea una tabella con distribuzione hash con ProductKey come colonna di distribuzione.
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey])
);
La distribuzione hash può essere applicata a più colonne per una distribuzione più uniforme della tabella di base. La distribuzione a più colonne consente di scegliere fino a otto colonne per la distribuzione. Ciò non solo riduce l'asimmetria dei dati nel tempo, ma migliora anche le prestazioni delle query. Ad esempio:
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey], [OrderDateKey], [CustomerKey] , [PromotionKey])
);
Nota
La distribuzione a più colonne in Azure Synapse Analytics può essere abilitata modificando il livello di compatibilità del database in 50 con questo comando.
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; Per altre informazioni sull'impostazione del livello di compatibilità del database, vedere ALTER DATABASE SCOPED CONFIGURATION. Per altre informazioni sulle distribuzioni a più colonne, vedere CREATE MATERIALIZED VIEW, CREATE TABLE o CREATE TABLE AS SELECT.
È possibile aggiornare i dati archiviati nelle colonne di distribuzione. Gli aggiornamenti apportati ai dati nelle colonne di distribuzione possono tuttavia comportare un'operazione di riproduzione casuale dei dati.
La scelta delle colonne di distribuzione è una decisione di progettazione importante, poiché i valori presenti nelle colonne hash determinano il modo in cui vengono distribuite le righe. La scelta ottimale dipende da vari fattori e, in genere, comporta alcuni compromessi. Dopo aver scelto una colonna o un set di colonne di distribuzione, non è più possibile modificarla. Se non si riescono a scegliere subito le colonne ottimali, è possibile usare CREATE TABLE AS SELECT (CTAS) per ricreare la tabella con la chiave hash di distribuzione desiderata.
Scegliere una colonna di distribuzione in modo che i dati vengano distribuiti in modo uniforme
Per ottenere prestazioni ottimali, tutte le distribuzioni devono avere approssimativamente lo stesso numero di righe. Se una o più distribuzioni hanno un numero sproporzionato di righe, alcune distribuzioni completano la propria porzione di query parallela prima delle altre. La query, quindi, viene completata solo nel momento in cui tutte le distribuzioni hanno terminato l'elaborazione e la velocità di ogni query corrisponde di fatto alla distribuzione più lenta.
- L'asimmetria dei dati significa che i dati non vengono distribuiti in modo uniforme tra le distribuzioni
- L'asimmetria di elaborazione significa che alcune distribuzioni richiedono più tempo di altre per eseguire query parallele. Questa situazione può verificarsi in caso di asimmetria dei dati.
Per bilanciare l'elaborazione parallela, selezionare una colonna o un set di colonne di distribuzione che:
- Contenga molti valori univoci. Una o più colonne di distribuzione possono avere valori duplicati. Tutte le righe con lo stesso valore vengono assegnate alla stessa distribuzione. Poiché sono presenti 60 distribuzioni, alcune distribuzioni possono avere valori univoci 1 di >, mentre altri possono terminare con valori pari a zero.
- Non contenga valori null o ne contenga un numero limitato. Come esempio estremo, se tutti i valori delle colonne di distribuzione sono NULL, tutte le righe vengono assegnate alla stessa distribuzione. L'elaborazione della query, quindi, è assegnata a un'unica distribuzione e non può usufruire dei vantaggi dell'elaborazione in parallelo.
- Non è una colonna data. Tutti i dati relativi alla stessa data vengono inseriti nella stessa distribuzione o raggruppano i record per data. In questo modo, se più utenti filtrano in base alla stessa data (ad esempio la data odierna), l'intero lavoro di elaborazione viene eseguito solo da 1 delle 60 distribuzioni.
Scegliere una colonna di distribuzione che riduca al minimo lo spostamento dei dati
Per ottenere il risultato corretto, è possibile che le query spostino i dati da un nodo di calcolo a un altro. Lo spostamento dei dati si verifica in genere quando le query hanno join e aggregazioni in tabelle distribuite. Scegliere una colonna o un set di colonne di distribuzione che contribuisca a ridurre lo spostamento dei dati è una delle strategie più importanti per ottimizzare le prestazioni del pool SQL dedicato.
Per ridurre al minimo lo spostamento dei dati, selezionare una colonna o un set di colonne di distribuzione che:
- Viene usata in clausole
JOIN,GROUP BY,DISTINCT,OVEReHAVING. Se due tabelle dei fatti di grandi dimensioni hanno join frequenti, le prestazioni delle query migliorano se si distribuiscono entrambe le tabelle in una delle colonne di join. Se una tabella non viene usata in operazioni di join, valutare l'opportunità di distribuire la tabella in una colonna o set di colonne che si trova spesso nella clausolaGROUP BY. - Non viene usata in clausole
WHERE. Quando la clausolaWHEREdi una query e le colonne di distribuzione della tabella si trovano nella stessa colonna, la query potrebbe riscontrare un'asimmetria dei dati elevata, con conseguente riduzione del carico di elaborazione in poche distribuzioni. Ciò influisce sulle prestazioni delle query: idealmente molte distribuzioni condividono il carico di elaborazione. - Non è una colonna dati. Le clausole
WHEREfiltrano spesso per data. Quando si verifica questa situazione, l'intera elaborazione può essere eseguita solo su alcune distribuzioni che influiscono sulle prestazioni delle query. Idealmente, molte distribuzioni condividono il carico di elaborazione.
Dopo aver progettato una tabella con distribuzione round robin, è necessario caricare i dati nella tabella. Per informazioni sul caricamento, vedere l'articolo di panoramica sul caricamento.
Come stabilire se una distribuzione è appropriata
Dopo aver caricato i dati in una tabella con distribuzione hash, verificare che le righe siano state distribuite in modo uniforme tra le 60 distribuzioni. Una variazione fino al 10% del numero di righe assegnate a ogni distribuzione non influisce in modo significativo sulle prestazioni.
Considerare i modi seguenti per valutare le colonne di distribuzione.
Determinare se la tabella presenta un'asimmetria dei dati
Per controllare se è presente un'asimmetria dei dati, è possibile usare DBCC PDW_SHOWSPACEUSED. Il codice SQL seguente restituisce il numero di righe di tabella archiviate in ognuna delle 60 distribuzioni. Per ottenere prestazioni bilanciate, le righe nella tabella distribuita devono essere suddivise in modo uniforme tra tutte le distribuzioni.
-- Find data skew for a distributed table
DBCC PDW_SHOWSPACEUSED('dbo.FactInternetSales');
Per identificare quali tabelle presentano un'asimmetria dei dati superiore al 10%:
- Creare la visualizzazione
dbo.vTableSizesillustrata nell'articolo di panoramica delle tabelle. - Eseguire la query riportata di seguito:
select *
from dbo.vTableSizes
where two_part_name in
(
select two_part_name
from dbo.vTableSizes
where row_count > 0
group by two_part_name
having (max(row_count * 1.000) - min(row_count * 1.000))/max(row_count * 1.000) >= .10
)
order by two_part_name, row_count;
Verificare lo spostamento dei dati nei piani di query
Se il set di colonne di distribuzione è appropriato, i join e le aggregazioni presentano uno spostamento minimo dei dati. Questo aspetto influisce sul modo in cui devono essere scritti i join. Per ottenere uno spostamento minimo dei dati per un join in due tabelle con distribuzione hash, una delle colonne di join deve essere in una o più colonne di distribuzione. Se due tabelle con distribuzione hash creano un join in una colonna di distribuzione dello stesso tipo di dati, il join non richiede lo spostamento dei dati. I join possono usare colonne aggiuntive senza richiedere uno spostamento dei dati.
Per evitare lo spostamento dei dati durante un join:
- È necessario eseguire la distribuzione hash delle tabelle coinvolte nel join in una delle colonne che fanno parte del join.
- I tipi di dati delle colonne di join nelle due tabelle devono corrispondere.
- Le colonne devono essere unite con un operatore Uguale.
- Il tipo di join non può essere
CROSS JOIN.
Per vedere se nelle query si verifica uno spostamento dei dati, è possibile controllare il piano di query.
Risolvere un problema relativo a una colonna di distribuzione
Non è necessario risolvere tutti i casi di asimmetria dei dati. La distribuzione è essenzialmente l'individuazione del giusto equilibrio fra la minimizzazione dell'asimmetria dei dati e la minimizzazione dello spostamento dei dati. Non è sempre possibile ridurre al minimo entrambi i valori. In alcuni casi, il vantaggio di uno spostamento dei dati minimo può essere quello di compensare l'impatto negativo dell'asimmetria dei dati.
Per decidere se sia necessario risolvere la differenza dati di una tabella, è necessario conoscere nel modo più completo possibile i volumi di dati e le query del carico di lavoro. È possibile seguire la procedura descritta nell'articolo Monitoraggio delle query per monitorare l'effetto dell'asimmetria sulle prestazioni delle query. In particolare, è possibile scoprire quanto tempo richiede il completamento di query di grandi dimensioni in singole distribuzioni.
Non essendo possibile modificare la colonna di distribuzione in una tabella esistente, il modo più comune per risolvere l'asimmetria dei dati consiste nel ricreare la tabella con colonne di distribuzione diverse.
Ricreare la tabella con un nuovo set di colonne di distribuzione
Questo esempio usa CREATE TABLE AS SELECT per ricreare una tabella con colonne di distribuzione hash diverse.
Usare prima CREATE TABLE AS SELECT (CTAS) la nuova tabella con la nuova chiave. Quindi, ricreare le statistiche e infine scambiare le tabelle ridenominandole.
CREATE TABLE [dbo].[FactInternetSales_CustomerKey]
WITH ( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([CustomerKey])
, PARTITION ( [OrderDateKey] RANGE RIGHT FOR VALUES ( 20000101, 20010101, 20020101, 20030101
, 20040101, 20050101, 20060101, 20070101
, 20080101, 20090101, 20100101, 20110101
, 20120101, 20130101, 20140101, 20150101
, 20160101, 20170101, 20180101, 20190101
, 20200101, 20210101, 20220101, 20230101
, 20240101, 20250101, 20260101, 20270101
, 20280101, 20290101
)
)
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
OPTION (LABEL = 'CTAS : FactInternetSales_CustomerKey')
;
--Create statistics on new table
CREATE STATISTICS [ProductKey] ON [FactInternetSales_CustomerKey] ([ProductKey]);
CREATE STATISTICS [OrderDateKey] ON [FactInternetSales_CustomerKey] ([OrderDateKey]);
CREATE STATISTICS [CustomerKey] ON [FactInternetSales_CustomerKey] ([CustomerKey]);
CREATE STATISTICS [PromotionKey] ON [FactInternetSales_CustomerKey] ([PromotionKey]);
CREATE STATISTICS [SalesOrderNumber] ON [FactInternetSales_CustomerKey] ([SalesOrderNumber]);
CREATE STATISTICS [OrderQuantity] ON [FactInternetSales_CustomerKey] ([OrderQuantity]);
CREATE STATISTICS [UnitPrice] ON [FactInternetSales_CustomerKey] ([UnitPrice]);
CREATE STATISTICS [SalesAmount] ON [FactInternetSales_CustomerKey] ([SalesAmount]);
--Rename the tables
RENAME OBJECT [dbo].[FactInternetSales] TO [FactInternetSales_ProductKey];
RENAME OBJECT [dbo].[FactInternetSales_CustomerKey] TO [FactInternetSales];
Contenuto correlato
Per creare una tabella distribuita, usare una di queste istruzioni: