Esercitazione: migrazione da SQL Server a SQL Server su macchine virtuali Azure con Servizio Migrazione del database
È possibile usare il Servizio Migrazione del database di Azure Service e l'estensione Migrazione di Azure SQL in Azure Data Studio per migrare i database da un'istanza locale di SQL Server a SQL Server su macchine virtuali Azure (SQL Server 2016 e successivi) con tempo inattivo minimo.
Per i metodi di migrazione del database che potrebbero richiedere una configurazione manuale, vedere Migrazione dell'istanza di SQL Server a SQL Server nelle macchine virtuali di Azure.
In questa esercitazione viene eseguita la migrazione del database AdventureWorks2022 da un'istanza locale di SQL Server a un SQL Server su macchina virtuale Azure con tempo inattivo minimo, usando Azure Data Studio con il Servizio Migrazione del database di Azure.
Questa esercitazione offre opzioni di migrazione offline e online, tra cui un tempo di inattività accettabile durante il processo di migrazione.
In questa esercitazione apprenderai a:
- Come avviare la Migrazione ad Azure SQL usando la procedura guidata di Azure Data Studio.
- Eseguire una valutazione dei database DI SQL Server di origine.
- Raccogliere dati sulle prestazioni dall'origine SQL Server.
- Come ottenere una raccomandazione dello SKU di SQL Server nella macchina virtuale di Azure più adatta per il carico di lavoro.
- Specificare i dettagli dell’SQL Server di origine, del percorso di backup e dell’SQL Server di destinazione nella macchina virtuale di Azure.
- Creare un nuovo Servizio Migrazione del database di Azure e installare il runtime di integrazione self-hosted per accedere al server di origine e ai backup.
- Avviare e monitorare lo stato di avanzamento della migrazione.
- Una volta pronti, eseguire il cutover della migrazione.
Prerequisiti
Prima di iniziare l'esercitazione:
Installare l'estensione di Migrazione Azure SQL dal Marketplace Azure Data Studio.
Assicurarsi che un account Azure sia assegnato a uno dei ruoli predefiniti seguenti:
Contributore per l'istanza di destinazione di SQL Server su macchine virtuali di Azure e per l'account di archiviazione in cui caricare i file di backup del database da una condivisione di rete Server Message Block (SMB)
Ruolo lettore per il gruppo di risorse di Azure che contiene l'istanza di destinazione di SQL Server nelle macchine virtuali di Azure o per l'account di archiviazione di Azure
Ruolo Proprietario o Collaboratore per la sottoscrizione di Azure
In alternativa all'uso di uno di questi ruoli predefiniti, è possibile assegnare ruoli personalizzati.
Importante
Un account Azure è necessario solo quando si configurano i passaggi di migrazione. Non è necessario un account Azure per la valutazione o per visualizzare le raccomandazioni di Azure nella procedura guidata per la migrazione in Azure Data Studio.
Creare un'istanza di destinazione di SQL Server in Macchine virtuali di Azure.
Importante
Se si dispone di una macchina virtuale di Azure esistente, questa deve essere registrata con l'estensione SQL IaaS Agent in modalità di gestione completa.
Assicurarsi che i login utilizzati per connettersi all'istanza SQL Server di origine siano membri del ruolo server sysadmin o abbiano l'autorizzazione
CONTROL SERVER.Fornire una condivisione di rete SMB, una condivisione file dell'account di archiviazione Azure o un contenitore BLOB dell'account di archiviazione Azure che contenga i file di backup del database completo e i successivi file di backup del registro delle transazioni. Il Servizio Migrazione del database usa il percorso di backup durante la migrazione del database.
L'estensione Migrazione SQL di Azure per Azure Data Studio non esegue backup del database e non avvia backup del database per conto dell'utente. Il servizio utilizza invece i file di backup del database esistente per la migrazione.
Se i file di backup del database si trovano in una condivisione di rete SMB, creare un account di archiviazione di Azure sui quali il Servizio Migrazione del database possa caricare i file di backup del database e che possa usare per eseguire la migrazione dei database. Assicurarsi di creare l'account di archiviazione Azure nella stessa area in cui è stata creata l'istanza del Servizio migrazione del database.
Ciascun backup può essere scritto in un file di backup separato o in più file di backup. Accodare più backup, ad esempio quelli completi e del log delle transazioni, in un singolo supporto di backup non è supportato.
È possibile usare backup compressi per ridurre la probabilità di potenziali problemi associati alla migrazione di backup di grandi dimensioni.
Assicurarsi che l'account di servizio che esegue l'istanza di SQL Server di origine abbia le autorizzazioni di lettura e scrittura sulla condivisione di rete SMB che contiene i file di backup del database.
Se si esegue la migrazione di un database protetto da Transparent Data Encryption (TDE), è necessario eseguire la migrazione del certificato dall'istanza di SQL Server di origine a SQL Server nelle Macchine virtuali di Azure prima di eseguire la migrazione dei dati. Per altre informazioni, vedere Spostare un database protetto da TDE su un altro SQL Server.
Suggerimento
Se il database contiene dati sensibili protetti da Always Encrypted, il processo di migrazione esegue automaticamente la migrazione delle chiavi Always Encrypted all'istanza di destinazione di SQL Server in nelle Macchie virtuali di Azure.
Se i backup del database si trovano in una condivisione file di rete, specificare un computer in cui è possibile installare un runtime di integrazione self-hosted per accedere ed eseguire la migrazione dei backup del database. La procedura guidata per la migrazione fornisce il collegamento di download e le chiavi di autenticazione per scaricare e installare il runtime di integrazione self-hosted.
Durante la preparazione per la migrazione, verificare che nel computer in cui si installa il runtime di integrazione self-hosted siano abilitate le regole del firewall in uscita e i nomi di dominio seguenti:
Nomi di dominio Porta in uscita Descrizione Cloud pubblico: {datafactory}.{region}.datafactory.azure.net
oppure*.frontend.clouddatahub.net
Azure per enti pubblici:{datafactory}.{region}.datafactory.azure.us
Microsoft Azure gestito da 21Vianet:{datafactory}.{region}.datafactory.azure.cn443 Richiesta dal runtime di integrazione self-hosted per connettersi al Servizio Migrazione del database.
Per una data factory appena creata in un cloud pubblico, individuare il nome di dominio completo (FQDN) dalla chiave di runtime di integrazione self-hosted nel formato{datafactory}.{region}.datafactory.azure.net.
Per una data factory esistente, se non viene visualizzato il nome di dominio completo nella chiave di integrazione self-hosted, invece usare*.frontend.clouddatahub.net.download.microsoft.com443 Richiesta dal runtime di integrazione self-hosted per il download degli aggiornamenti. Se l'aggiornamento automatico è stato disabilitato, è possibile evitare di configurare questo dominio. .core.windows.net443 Viene usato dal runtime di integrazione self-hosted che si connette all'account di archiviazione di Azure per caricare i backup del database dalla condivisione di rete Suggerimento
Se i file di backup del database sono già disponibili in un account di archiviazione di Azure, durante il processo di migrazione non è necessario un runtime di integrazione self-hosted.
Se si usa un runtime di integrazione self-hosted, assicurarsi che il computer in cui è installato il runtime possa connettersi all'istanza di SQL Server di origine e alla condivisione file di rete in cui si trovano i file di backup.
Abilitare la porta in uscita 445 per consentire l'accesso alla condivisione dei file di rete. Per altre informazioni, vedere gli Articoli consigliati per il runtime di integrazione self-hosted.
Se è la prima volta che si usa il Servizio Migrazione del database di Azure è necessario assicurarsi che il provider di risorse
Microsoft.DataMigrationsia registrato nella sottoscrizione.
- Offline con Servizio Migrazione del database di Azure
- Online con Servizio Migrazione del database di Azure
Questa esercitazione descrive una migrazione offline da SQL Server a SQL Server nelle Macchine virtuali di Azure.
Aprire la procedura guidata Migrazione ad Azure SQL in Azure Data Studio
Per aprire la procedura guidata Migrazione ad Azure SQL:
In Azure Data Studio, passare a Connessioni. Selezionare e connettersi all'istanza locale di SQL Server. È possibile anche connettersi a SQL Server in una macchina virtuale di Azure.
Fare clic con il pulsante destro del mouse sulla connessione del server e selezionare Gestisci.
Nel menu del server, in Generale selezionare Migrazione Azure SQL.
Nel dashboard di Migrazione Azure SQL, selezionare Migrazione ad Azure SQL per aprire la procedura guidata per la migrazione.

Nella prima pagina della procedura guidata, avviare una nuova sessione o riavviare una sessione salvata in precedenza.

Eseguire una valutazione del database, raccogliere i dati sulle prestazioni e visualizzare i consigli di Azure
Nel passaggio 1: Database per la valutazione nella procedura guidata Migrazione ad Azure SQL, selezionare i database da valutare. Quindi seleziona Avanti.
Nel passaggio 2: Risultati e consigli della valutazione, completare i passaggi seguenti:
In Scegli la destinazione di Azure SQL, selezionare SQL Server su Macchina virtuale di Azure.
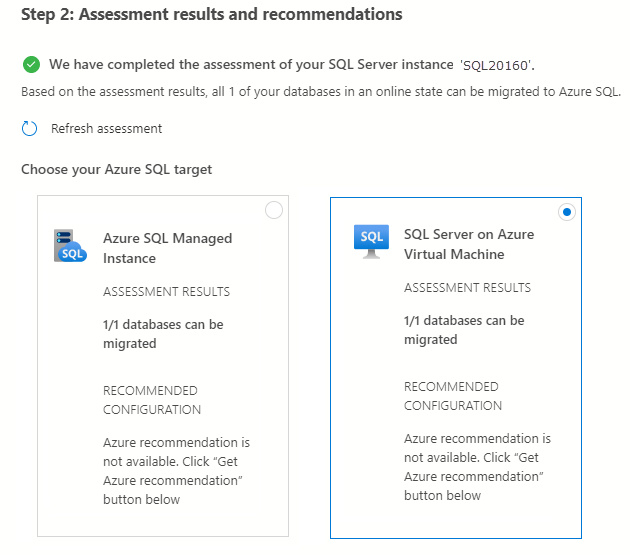
Selezionare Visualizza/Seleziona per visualizzare i risultati della valutazione.
Nei risultati della valutazione, selezionare il database e quindi esaminare il report di valutazione per assicurarsi che non siano stati trovati problemi.
Selezionare Ottieni raccomandazione di Azure per aprire il riquadro raccomandazioni.
Selezionare Raccogli dati sulle prestazioni ora.. Nel computer locale, selezionare una cartella in cui archiviare i log di prestazioni, quindi selezionare Avvia.
Azure Data Studio raccoglie i dati sulle prestazioni fino a quando non si arresta la raccolta dati o si chiude Azure Data Studio.
Dopo 10 minuti, Azure Data Studio indica che è disponibile un consiglio per SQL Server su Macchine virtuali di Azure. Dopo aver generato la prima raccomandazione, è possibile selezionare Riavvia raccolta dati per continuare il processo di raccolta dati e affinare la raccomandazione SKU. La valutazione estesa è particolarmente utile se i modelli di utilizzo variano nel tempo.
Nella destinazione SQL Server nelle Macchine virtuali Azure Macchine virtuali selezionata, scegliere Visualizza dettagli per aprire il report dettagliato sulle raccomandazioni SKU:
In Esamina le raccomandazioni SQL Server delle Macchine virtuali di Azure, esaminare la raccomandazione. Per salvare una copia della raccomandazione, selezionare la casella di controllo Salva report della raccomandazione.
Selezionare Chiudi per chiudere il riquadro della raccomandazione.
Selezionare Avanti per continuare la migrazione del database nella procedura guidata.
Configurare le impostazioni di migrazione
Nel passaggio 3: Destinazione Azure SQL nella procedura guidata Migrazione ad Azure SQL, selezionare l'account Azure, la sottoscrizione Azure, l'area o la posizione di Azure e il gruppo di risorse che contiene l'istanza di SQL Server di destinazione nell'istanza delle Marrchine virtuali di Azure. Quindi seleziona Avanti.
Nel passaggio 4: Modalità di migrazione, selezionare Migrazione offline e quindi selezionare Avanti.
Nota
Nella modalità di migrazione offline, il database SQL Server di origine non deve essere usato per l'attività di scrittura mentre i file di backup del database vengono ripristinati nell'istanza di destinazione di SQL Server in Macchine virtuali di Azure. Il tempo inattivo dell'applicazione persiste dall'inizio al completamento del processo di migrazione.
Nel passaggio 5: Configurazione origine dati, selezionare la posizione dei backup del database. I backup del database possono trovarsi in una condivisione di rete locale o in un contenitore BLOB del servizio di archiviazione di Azure.
Nota
Se i backup del database vengono forniti in una condivisione di rete locale, è necessario configurare un runtime di integrazione self-hosted nel passaggio successivo della procedura guidata. È necessario un runtime di integrazione self-hosted, per accedere ai backup del database di origine, verificare la validità del set di backup e caricare i backup nell'account di archiviazione di Azure.
Se i backup del database si trovano già in un contenitore BLOB del servizio di archiviazione di Azure, non è necessario configurare un runtime di integrazione self-hosted.
Per i backup che si trovano in una condivisione di rete, immettere o selezionare le informazioni seguenti:
Nome Descrizione Credenziali di origine: nome utente Le credenziali (autenticazione di Windows e SQL) per connettersi all'istanza di SQL Server di origine e convalidare i file di backup. Credenziali di origine: password Le credenziali (autenticazione di Windows e SQL) per connettersi all'istanza di SQL Server di origine e convalidare i file di backup. Posizione di condivisione di rete che contiene i backup La posizione di condivisione di rete che contiene i file di backup completi e del log delle transazioni. I file o i file di backup non validi nella condivisione di rete che non appartengono al set di backup valido vengono ignorati automaticamente durante il processo di migrazione. Account utente di Windows con accesso in lettura alla posizione della condivisione di rete Le credenziali di Windows (nome utente) con accesso in lettura alla condivisione di rete per recuperare i file di backup. Password Le credenziali di Windows (password) con accesso in lettura alla condivisione di rete per recuperare i file di backup. Nome del database di destinazione Durante il processo di migrazione, è possibile modificare il nome del database di destinazione. Per i backup archiviati in un contenitore BLOB del servizio di archiviazione di Azure, immettere o selezionare le informazioni seguenti:
Nome Descrizione Nome del database di destinazione Durante il processo di migrazione, è possibile modificare il nome del database di destinazione. Dettagli dell'account di archiviazione Il gruppo di risorse, l'account di archiviazione e il contenitore in cui si trovano i file di backup. Ultimo file di backup Il nome del file dell'ultimo backup del database di cui si sta eseguendo la migrazione. Importante
Se la funzionalità di controllo del loopback è attivata e l’SQL Server di origine e la condivisione di file si trovano sullo stesso computer, l'origine non sarà in grado di accedere alla condivisione di file utilizzando l'FQDN. Per risolvere questo problema, disabilitare la funzionalità di controllo del loopback.
L'estensione di migrazione Azure SQL per Azure Data Studio non richiede più configurazioni specifiche nelle impostazioni di rete dell'account di archiviazione di Azure per eseguire la migrazione dei database di SQL Server ad Azure. Tuttavia, a seconda della posizione di backup del database e delle impostazioni di rete dell'account di archiviazione desiderato, sono necessari alcuni passaggi per assicurarsi che le risorse possano accedere all'account di archiviazione di Azure. Vedere la tabella seguente per i vari scenari di migrazione e configurazioni di rete:
Scenario Condivisione di rete SMB Contenitore dell'account di archiviazione Azure Abilitato da tutte le reti Nessun passaggio aggiuntivo Nessun passaggio aggiuntivo Abilitata da reti virtuali e indirizzi IP selezionati Vedere 1a Vedere 2a Abilitata da reti virtuali e indirizzi IP selezionati + endpoint privato Vedere 1b Vedere 2b
1a - Configurazione della rete dell'archiviazione BLOB di Azure
Se il runtime di integrazione self-hosted (SHIR) è installato in una VM di Azure, vedere la sezione 1b - Configurazione della rete di archiviazione BLOB di Azure. Se il runtime di integrazione self-hosted (SHIR) è installato sulla rete locale, è necessario aggiungere l'indirizzo IP del client del computer ospitante nell'account di archiviazione di Azure in questo modo:

Per applicare questa configurazione specifica, collegarsi al portale di Azure dal computer SHIR, aprire la configurazione dell'account di archiviazione Azure, selezionare Networking, quindi selezionare la casella di controllo Aggiungi l'indirizzo IP del client. Selezionare Salva per salvare la modifica in modo permanente. Per i passaggi rimanenti, vedere la sezione 2a - Configurazione della rete dell'archiviazione BLOB di Azure (endpoint privato).
1b - Configurazione della rete dell'archiviazione BLOB di Azure
Se il servizio SHIR è ospitato in una VM di Azure, è necessario aggiungere la rete virtuale della VM all'account di archiviazione di Azure, poiché la VM ha un indirizzo IP non pubblico che non può essere aggiunto alla sezione Intervallo di indirizzi IP.

Per applicare questa configurazione specifica, individuare l'account di archiviazione di Azure, nel pannello Archiviazione dati, selezionare Networking e quindi selezionare la casella di controllo Aggiungi rete virtuale esistente. SI apre un nuovo pannello, selezionare la sottoscrizione, la rete virtuale e la subnet della VM di Azure che ospita il runtime di integrazione. Queste informazioni sono disponibili nella pagina Panoramica della macchina virtuale di Azure. La subnet potrebbe indicare che l'endpoint del servizio è necessario in tal caso, selezionare Abilita. Quando è tutto pronto, salvare gli aggiornamenti. Per i passaggi rimanenti necessari, vedere la sezione 2a - Configurazione della rete dell'archiviazione BLOB di Azure (endpoint privato).
2a - Configurazione della rete dell'archiviazione BLOB di Azure (endpoint privato)
Se i backup vengono inseriti direttamente in un contenitore di archiviazione di Azure, tutti i passaggi precedenti non sono necessari, poiché non esiste un runtime di integrazione che comunica con l'account di archiviazione di Azure. Tuttavia, è comunque necessario assicurarsi che l'istanza di SQL Server di destinazione possa comunicare con l'account di archiviazione di Azure per ripristinare i backup dal contenitore. Per applicare questa configurazione specifica, seguire le istruzioni nella sezione 1b - Configurazione della rete di archiviazione BLOB di Azure, specificare la rete virtuale dell'istanza SQL di destinazione quando si compila il popup "Aggiungi rete virtuale esistente".
2b - Configurazione della rete dell'archiviazione BLOB di Azure (endpoint privato)
Se è stato configurato un endpoint privato nell'account di archiviazione di Azure, seguire i passaggi descritti nella sezione 2a - Configurazione della rete di archiviazione BLOB di Azure (endpoint privato). È tuttavia necessario selezionare la subnet dell'endpoint privato, oltre alla subnet di SQL Server di destinazione. Assicurarsi che l'endpoint privato sia ospitato nella stessa rete virtuale dell'istanza di SQL Server di destinazione. In caso contrario, creare un altro endpoint privato usando il processo nella sezione della configurazione dell’account di archiviazione di Azure.
Creare l'istanza del Servizio Migrazione del database
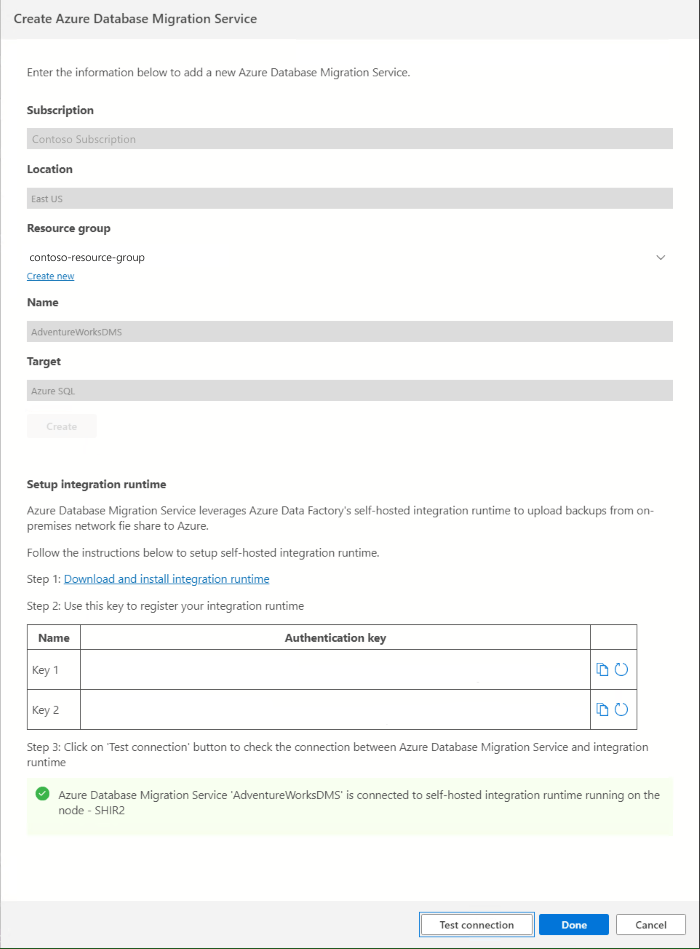
Nel passaggio 6: Servizio Migrazione del database di Azure nella procedura guidata Migrazione a SQL di Azure, creare una nuova istanza di Servizio Migrazione del database di Azure o riutilizzare un'istanza esistente creata in precedenza.
Nota
Se in precedenza è stata creata un'istanza di Servizio Migrazione del database usando il portale di Azure, non è possibile riutilizzare l'istanza nella procedura guidata di migrazione in Azure Data Studio. È possibile riutilizzare un'istanza solo se è stata creata usando Azure Data Studio.
Usare un'istanza esistente del Servizio Migrazione del database
Per usare un'istanza esistente di Servizio Migrazione del database:
In Gruppo di risorse, selezionare il gruppo di risorse che contiene un'istanza esistente di Servizio Migrazione del database.
In Servizio Migrazione del database di Azure selezionare un'istanza esistente del Servizio Migrazione del database nel gruppo di risorse selezionato.
Selezionare Avanti.
Creare una nuova istanza del Servizio Migrazione del database
Per crere una nuova istanza del Servizio Migrazione del database:
In Gruppo di risorse, creare un nuovo gruppo di risorse che possa contenere una nuova istanza di Servizio Migrazione del database.
In Servizio Migrazione del database di Azure, selezionare Crea.
In Crea Servizio Migrazione del database di Azure immettere un nome per l'istanza di Servizio Migrazione del database e quindi selezionare Crea.
In Configura runtime di integrazione, completare i passaggi seguenti:
Selezionare il collegamento Scarica e installa runtime di integrazione per aprire il collegamento di download in un Web browser. Scaricare il runtime di integrazione e quindi installarlo in un computer che soddisfi i prerequisiti per connettersi all'istanza di SQL Server di origine.
Al termine dell'installazione, viene aperto automaticamente il Microsoft Integration Runtime Configuration Manager per avviare il processo di registrazione.
Nella tabella Chiave di autenticazione, copiare una delle chiavi di autenticazione fornite nella procedura guidata e incollarla in Azure Data Studio. Se la chiave di autenticazione è valida, viene visualizzata un'icona di spunta verde nel runtime di integrazione Configuration Manager. Un segno di spunta verde indica che è possibile procedere alla Registrazione.
Dopo aver registrato il runtime di integrazione self-hosted, chiudere Microsoft Integration Runtime Configuration Manager.
Nota
Per altre informazioni sul runtime di integrazione self-hosted, vedere Creare e configurare il runtime di integrazione self-hosted.
In Crea Servizio Migrazione del database di Azure in Azure Data Studio selezionare Connessione di test per verificare che l'istanza di Servizio Migrazione del database appena creata sia connessa al runtime di integrazione self-hosted appena registrato.
Tornare alla procedura guidata per la migrazione in Azure Data Studio.
Avviare la migrazione del database
Nel passaggio 7: Riepilogo della procedura guidata Migrazione ad Azure SQL, esaminare la configurazione creata e quindi selezionare Avvia migrazione per avviare la migrazione del database.
Monitorare la migrazione del database
In Azure Data Studio, nel menu del server in Generale, selezionare Migrazione Azure SQL per passare al dashboard per le migrazioni Azure SQL.
In Stato migrazione del database è possibile tenere traccia delle migrazioni in corso, completate e non riuscite (se presenti) oppure visualizzare tutte le migrazioni di database.
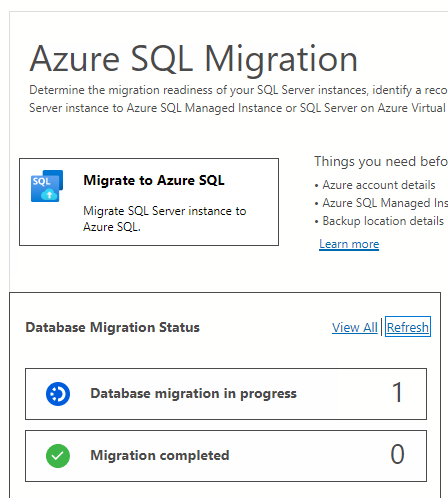
Selezionare Migrazioni di database in corso per visualizzare le migrazioni attive.
Per ottenere altre informazioni su una migrazione specifica, selezionare il nome del database.
Nel riquadro dei dettagli della migrazione vengono visualizzati i file di backup e il relativo stato:
Stato Descrizione Arrivata Il file di backup è arrivato nella posizione di backup di origine ed è stato convalidato. Caricamento Il runtime di integrazione carica il file di backup in Archiviazione di Azure. Caricato Il file di backup è stato caricato in Archiviazione di Azure. Ripristino Il servizio sta ripristinando il file di backup in SQL Server nelle Macchine virtuali di Azure. Ripristinato Il file di backup è stato ripristinato correttamente in SQL Server nelle Macchine virtuali di Azure. Annullata Il processo di migrazione è stato annullato. Ignorato Il file di backup è stato ignorato perché non appartiene a una catena di backup del database valida.
Dopo il ripristino di tutti i backup del database nell'istanza di SQL Server nelle Macchine virtuali di Azure, viene avviato un cutover di migrazione automatica dal Servizio Migrazione del database per assicurarsi che il database migrato sia pronto per l'uso. Lo stato della migrazione passa da In corso a Completata.

Limiti
-Se si esegue la migrazione di un database singolo, i backup del database devono essere collocati in una struttura di file flat all'interno di una cartella di database (compresa la cartella radice del contenitore) e le cartelle non potranno essere annidate, poiché non sono supportate.
-Se si esegue la migrazione di più database usando lo stesso contenitore Archiviazione BLOB di Azure, è necessario inserire i file di backup per database diversi in cartelle separate all'interno del contenitore.
-La sovrascrittura dei database esistenti tramite il Servizio Migrazione del database nell'SQL Server di destinazione su Macchina virtuale di Azure non è supportata.
-La configurazione della disponibilità elevata e del ripristino di emergenza nella destinazione in modo che corrisponda alla topologia di origine non è supportata dal Servizio Migrazione del database.
Gli oggetti server seguenti non sono supportati:
- SQL Server Agent - processi
- Credenziali
- Pacchetti SSIS
- Controllo server
-Non è possibile usare un runtime di integrazione self-hosted esistente creato da Azure Data Factory per le migrazioni di database con Servizio Migrazione del database. Inizialmente, il runtime di integrazione self-hosted deve essere creato usando l'estensione di migrazione Azure SQL in Azure Data Studio e può essere riutilizzato per altre migrazioni di database.
-Le VM con SQL Server 2008 e versioni successive come versioni di destinazione non sono supportate durante la migrazione a SQL Server in Macchine virtuali di Azure.
-Se si usa una macchina virtuale con SQL Server 2012 o SQL Server 2014, è necessario archiviare i file di backup del database di origine in un contenitore BLOB del servizio di archiviazione di Azure, anziché usare l'opzione condivisione di rete. Archiviare i file di backup come BLOB di pagine, poiché i BLOB in blocchi sono supportati solo in SQL 2016 e versioni successive.
-È necessario assicurarsi che l'estensione dell'agente IaaS di SQL nella macchina virtuale di Azure di destinazione sia in modalità completa anziché in modalità leggera.
-Migrazione alla macchina virtuale di Azure SQL tramite Servizio Migrazione del database usa internamente l'agente IaaS di SQL. L'estensione dell'agente IaaS di SQL supporta solo la gestione dell'istanza del server predefinita o di un'istanza denominata singola.
-È possibile eseguire la migrazione di un massimo di 100 database alla stessa macchina virtuale di SQL Server di Azure della destinazione usando una o più migrazioni contemporaneamente. Inoltre, al termine di una o più migrazioni con 100 database, attendere almeno 30 minuti prima di avviare una nuova migrazione alla stessa macchina virtuale di SQL Server di Azure come destinazione. Inoltre, ogni operazione di migrazione (avvio della migrazione, cutover) per ciascun database richiede alcuni minuti in sequenza. Ad esempio, per eseguire la migrazione di 100 database, potrebbero essere necessari circa 200 (2 x 100) minuti per creare le code di migrazione e circa 100 (1 x 100) minuti per eseguire il cutover di tutti i 100 database (esclusi i tempi di backup e ripristino). Pertanto, la migrazione diventa più lenta man mano che aumenta il numero di database. È consigliabile pianificare una finestra di migrazione più lunga in anticipo in base a test di migrazione rigorosi o eseguire il partizionamento di un numero elevato di database in batch durante la migrazione a una VM di Azure di SQL Server.
-Oltre a configurare networking/firewall dell'account di archiviazione di Azure per consentire alla VM di accedere ai file di backup. È anche necessario configurare il networking/il firewall di SQL Server nella VM di Azure per consentire la connessione in uscita all'account di archiviazione.
-È necessario mantenere l'SQL Server di destinazione ATTIVO sulla VM di Azure mentre è in corso la migrazione SQL. Inoltre, quando si crea una nuova migrazione, deve essere eseguito esegue il failover o annullare la migrazione.
Gli eventuali messaggi di errore
Accesso non riuscito per l'utente 'NT Service\SQLIaaSExtensionQuery
Errore: Login failed for user 'NT Service\SQLIaaSExtensionQuery
Motivo: l'istanza di SQL Server è in modalità utente singolo. Un possibile motivo è che l’SQL Server di destinazione nella VM di Azure sia in modalità di aggiornamento.
Soluzione: attendere che l’SQL Server di destinazione nella VM di Azure sia uscito dalla modalità di aggiornamento e avviare di nuovo la migrazione.
Impossibile creare il processo di ripristino
Errore: Ext_RestoreSettingsError, message: Failed to create restore job.;Cannot create file 'F:\data\XXX.mdf' because it already exists.
Soluzione: connettersi a SQL Server di destinazione nella VM di Azure ed eliminare il file XXX.mdf. Quindi, avviare nuovamente la migrazione.
Contenuto correlato
- Eseguire la migrazione di un database SQL Server a SQL Server su una macchina virtuale
- Cos'è SQL Server in macchine virtuali di Windows Azure?
- Connettersi a una macchina virtuale di SQL Server in Azure
- Problemi noti, limitazioni e passaggi per la risoluzione dei problemi
- Eseguire la migrazione di un database a SQL Server su macchine virtuali di Azure utilizzando il comando T-SQL RESTORE