Problemi e soluzioni per la gestione dei dati distribuiti
Suggerimento
Questo contenuto è un estratto dell'eBook "Microservizi .NET: Architettura per le applicazioni .NET incluse in contenitori", disponibile in .NET Docs o come PDF scaricabile gratuitamente e da poter leggere offline.

Problema 1: Come definire i limiti di ogni microservizio
La definizione dei limiti dei microservizi è probabilmente il primo problema riscontrato da tutti gli utenti. Ogni microservizio deve infatti essere un componente dell'applicazione pur rimanendo autonomo, con tutti i vantaggi e problemi che questo comporta. Ma come è possibile identificare questi limiti?
In primo luogo è necessario concentrare l'attenzione sui modelli di dominio logici dell'applicazione e sui dati correlati. Provare a individuare isole scollegate di dati e contesti diversi all'interno della stessa applicazione. Ogni contesto potrebbe essere caratterizzato da un linguaggio aziendale diverso, ovvero termini aziendali diversi. I contesti devono quindi essere definiti e gestiti in modo indipendente. I termini e le entità usati in questi contesti diversi potrebbero sembrare simili, ma potrebbe capitare che un concetto aziendale in un contesto venga usato per uno scopo diverso in un altro contesto e abbia anche un nome diverso. È ad esempio possibile che si faccia riferimento al concetto di utente come utente in un contesto di identità o appartenenza, come cliente in un contesto CRM, come acquirente in un contesto di creazione ordini e così via.
Il modo in cui vengono identificati i limiti tra più contesti dell'applicazione con un dominio diverso per ogni contesto coincide con la modalità di identificazione dei limiti per ogni microservizio business e i relativi dati e modelli di dominio correlati. Si prova sempre a ridurre al minimo l'accoppiamento tra tali microservizi. Questa guida approfondisce la struttura di questo modello di dominio e identificazione più avanti, nella sezione Identificazione dei limiti del modello di dominio per ogni microservizio.
Problema 2: Come creare query che recuperano dati da più microservizi
Il secondo problema si pone quando si tratta di implementare query che recuperano dati di più microservizi, evitando comunicazioni frammentate con i microservizi dalle app client remote. Un esempio può essere una singola schermata di un'app per dispositivi mobili che deve visualizzare all'utente le informazioni appartenenti ai microservizi del carrello, del catalogo e dell'identità utente. Un altro esempio è un report complesso che include molte tabelle distribuite in più microservizi. La soluzione giusta dipende dalla complessità delle query. In ogni caso, per migliorare l'efficienza nelle comunicazioni del sistema è necessario elaborare un modello per aggregare le informazioni. Le soluzioni più comuni sono le seguenti.
API Gateway. Per la semplice aggregazione di dati da più microservizi che sono proprietari di database diversi, l'approccio consigliato è un microservizio di aggregazione noto come API Gateway. Bisogna però prestare attenzione implementare questo schema perché può diventare un collo di bottiglia nel sistema e violare il principio di autonomia dei microservizi. Per evitare questi inconvenienti è possibile definire più schemi API Gateway specifici, ognuno incentrato su una sezione verticale o area aziendale del sistema. Lo schema API Gateway è illustrato in dettaglio più avanti, nella sezione API Gateway.
Federazione di GraphQL Una possibilità da considerare se i microservizi usano già GraphQL è la federazione di GraphQL. La federazione consente di definire "sottografi" da altri servizi e di comporli in un "supergrafo" aggregato che funge da schema autonomo.
CQRS con tabelle di query/letture. Un'altra soluzione per aggregare i dati di più microservizi è lo schema Materialized View. In questo approccio si genera in anticipo una tabella di sola lettura con i dati appartenenti a più microservizi, ovvero si preparano i dati denormalizzati prima delle query effettive. Il formato della tabella è adatto alle esigenze dell'app client.
Si immagini, ad esempio, la schermata di un'app per dispositivi mobili. Se è presente un unico database, è possibile raccogliere i dati per tale schermata usando una query SQL che esegue un join complesso che interessa più tabelle. Se, però, sono presenti più database, ognuno dei quali appartiene a un microservizio diverso, non è possibile eseguire query su tali database e creare un join SQL. La query complessa diventa un problema. Per risolverlo è possibile ricorrere a un approccio CQRS, creando una tabella denormalizzata in un database diverso che viene usato solo per le query. La tabella può essere progettata in modo specifico per i dati necessari per la query complessa, con una relazione uno a uno tra i campi necessari per la schermata dell'applicazione e le colonne nella tabella di query. Può anche essere usata per la creazione di report.
Questo approccio consente non solo di risolvere il problema originale (come eseguire query e join tra più microservizi), ma anche di migliorare notevolmente le prestazioni rispetto a un join complesso, perché i dati necessari per l'applicazione sono già disponibili nella tabella di query. Naturalmente l'uso di CQRS (Command and Query Responsibility Segregation) con le tabelle di query/letture implica un ulteriore lavoro di sviluppo, oltre alla necessità di includere la coerenza finale. Nonostante questo, è nei requisiti delle prestazioni e della scalabilità elevata degli scenari di collaborazione (o di concorrenza, a seconda del punto di vista) che si deve applicare CQRS con più database.
Dati utilizzati meno di frequente nei database centrali. Un approccio comune nel caso di report e query complesse che potrebbero non richiedere dati in tempo reale consiste nell'esportare i dati utilizzati più di frequente (dati transazionali dei microservizi) come dati utilizzati meno di frequente in database di grandi dimensioni che vengono usati solo per la creazione di report. Il sistema di database centrale può essere un sistema basato su Big Data, come Hadoop, un data warehouse come quello basato su Azure SQL Data Warehouse o persino un singolo database SQL usato solo per i report, se le dimensioni non rappresentano un problema.
Tenere presente che questo database centralizzato verrà usato solo per query e report che non richiedono dati in tempo reale. Gli aggiornamenti e le transazioni originali, da usare come fonte affidabile, devono essere presenti nei dati dei microservizi. Per la sincronizzazione dei dati, si può scegliere di usare la comunicazione basata su eventi (illustrata nelle sezioni successive) o altri strumenti di importazione/esportazione dell'infrastruttura di database. Se si usa la comunicazione basata su eventi, il processo di integrazione sarà simile alla procedura di propagazione dei dati descritto in precedenza per le tabelle di query CQRS.
Se però la progettazione dell'applicazione implica l'aggregazione costante di informazioni di più microservizi per le query complesse, questo potrebbe essere un sintomo di una progettazione non appropriata, dal momento che un microservizio deve essere il più possibile isolato da altri microservizi. Sono esclusi i report e le analisi, che devono sempre usare database centrali con dati utilizzati meno di frequente. Spesso questo problema potrebbe essere un valido motivo per unire i microservizi. È necessario bilanciare l'autonomia dell'evoluzione e la distribuzione di ogni microservizio con dipendenze complesse, coesione e aggregazione dei dati.
Problema 3: Come ottenere la coerenza tra più microservizi
Come affermato in precedenza, i dati di proprietà di ogni microservizio sono privati per il microservizio specifico ed è possibile accedervi solo usando la rispettiva API di microservizio. Di conseguenza uno dei problemi da affrontare è come implementare processi business end-to-end, garantendo al contempo la coerenza tra più microservizi.
Per analizzare il problema, considerare un esempio tratto dall'applicazione di riferimento eShopOnContainers. Il microservizio Catalog contiene le informazioni relative a tutti i prodotti, incluso il relativo prezzo. Il microservizio Basket gestisce i dati temporali relativi alle unità dei prodotti che gli utenti aggiungono al carrello, e questi includono il prezzo degli articoli quando sono stati aggiunti al carrello. Quando viene aggiornato il prezzo di un prodotto nel catalogo, il prezzo deve essere aggiornato anche nei carrelli attivi che contengono tale prodotto. Inoltre il sistema dovrebbe avvisare l'utente che il prezzo di un determinato articolo è cambiato da quando l'utente lo ha aggiunto al carrello.
In un'ipotetica versione monolitica di questa applicazione, quando il prezzo viene modificato nella tabella dei prodotti, il sottosistema del catalogo può semplicemente utilizzare una transazione ACID per aggiornare il prezzo corrente nella tabella Basket.
Tuttavia, in un'applicazione basata su microservizi le tabelle Product e Basket appartengono ai rispettivi microservizi. Nessun microservizio deve includere tabelle/risorse di archiviazione di proprietà di un altro microservizio nelle proprie transazioni e nemmeno nelle query dirette, come illustrato nella figura 4-9.
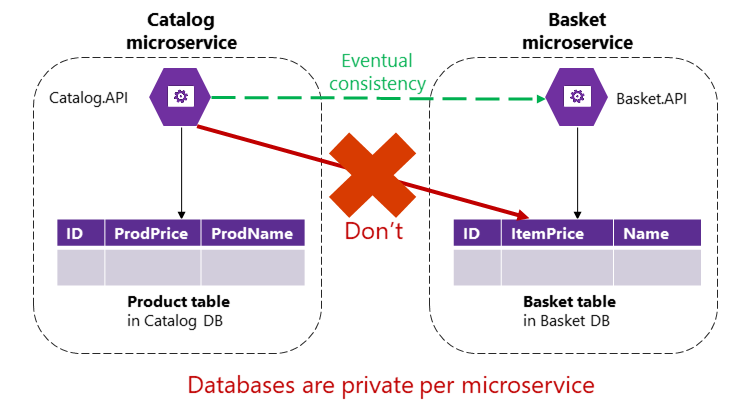
Figura 4-9. Un microservizio non può accedere direttamente a una tabella in un altro microservizio
Il microservizio Catalog non deve aggiornare direttamente la tabella Basket, perché la tabella Basket è di proprietà del microservizio Basket. Per eseguire un aggiornamento nel microservizio Basket, il microservizio Catalog deve usare la coerenza finale, probabilmente basandosi su comunicazioni asincrone come gli eventi di integrazione (comunicazione basata su messaggi ed eventi). Ecco come l'applicazione di riferimento eShopOnContainers implementa questo tipo di coerenza tra i diversi microservizi.
Come dichiarato nel teorema CAP, è necessario scegliere tra disponibilità e coerenza assoluta ACID. La maggior parte degli scenari basati su microservizio richiede disponibilità e scalabilità elevata anziché la coerenza assoluta. Le applicazioni mission-critical devono rimanere attive e in esecuzione e gli sviluppatori possono aggirare la coerenza assoluta usando tecniche per operare con la coerenza finale o debole. Si tratta dell'approccio adottato per la maggior parte delle architetture basate su microservizi.
Le transazioni di commit in due fasi o di tipo ACID non sono solo contrarie ai principi dei microservizi: la maggior parte dei database NoSQL, come Azure Cosmos DB, MongoDB e così via, non supporta le transazioni di commit in due fasi, tipiche degli scenari di database distribuiti. È tuttavia essenziale garantire la coerenza dei dati tra servizi e database. Questo problema è anche associato a quello della propagazione di modifiche tra più microservizi quando determinati dati devono essere ridondanti, ad esempio quando il nome o la descrizione del prodotto deve essere presente sia nel microservizio Catalog che nel microservizio Basket.
Una valida soluzione per questo problema consiste nell'usare la coerenza finale tra microservizi articolati tramite la comunicazione basata su eventi e un sistema di pubblicazione e sottoscrizione. Questi argomenti sono trattati nella sezione Comunicazione asincrona basata su eventi più avanti in questa guida.
Problema 4: Come progettare la comunicazione tra i limiti dei microservizi
La comunicazione tra i limiti dei microservizi costituisce un vero e proprio problema. In questo contesto la comunicazione non fa riferimento a quale protocollo usare (HTTP e REST, AMQP, messaggistica e così via), ma indica lo stile di comunicazione da usare e soprattutto come definire l'accoppiamento tra i microservizi. Quando si verifica un errore, l'impatto di tale errore sul sistema varia in modo significativo a seconda del livello di accoppiamento.
In un sistema distribuito, ad esempio un'applicazione basata su microservizi, che implica l'uso di un numero elevato di artefatti e la presenza di servizi distribuiti in numerosi server o host, è inevitabile che si verifichino errori nei componenti. Possono verificarsi errori parziali e persino interruzioni di maggiore entità, pertanto è necessario progettare i microservizi e la comunicazione tra di essi tenendo conto dei rischi comuni in questo tipo di sistema distribuito.
Un approccio comune consiste nell'implementare microservizi basati su HTTP (REST), in virtù della loro semplicità. Un approccio basato su HTTP è certamente accettabile. In questo caso il problema è correlato alla modalità di utilizzo. Se si usano richieste e risposte HTTP solo per interagire con i microservizi da applicazioni client o da schemi API Gateway, non ci sono problemi. Se però si creano lunghe catene di chiamate HTTP sincrone tra i microservizi, che comunicano tra i relativi limiti, come se i microservizi fossero oggetti di un'applicazione monolitica, si verificheranno certamente problemi nell'applicazione.
Si supponga che l'applicazione client effettui una chiamata API HTTP a un singolo microservizio, ad esempio il microservizio Ordering. Se il microservizio Ordering chiama a sua volta altri microservizi tramite HTTP nello stesso ciclo di richiesta/risposta, si sta di fatto creando una catena di chiamate HTTP, cosa che potrebbe inizialmente risultare sensata. Ci sono però alcuni aspetti importanti da considerare quando si intraprende questo percorso:
Blocchi e prestazioni ridotte. Data la natura sincrona di HTTP, la richiesta originale non riceve una risposta fino al termine di tutte le chiamate HTTP interne. Si supponga che il numero di queste chiamate aumenti in modo significativo e allo stesso tempo che una delle chiamate HTTP intermedie a un microservizio venga bloccata. Questa situazione influisce non solo sulle prestazioni, ma anche in modo esponenziale sulla scalabilità globale perché aumenta il numero di richieste HTTP aggiuntive.
Accoppiamento di microservizi con HTTP. I microservizi aziendali non devono essere abbinati ad altri microservizi dello stesso tipo. In teoria i microservizi non devono "essere a conoscenza" dell'esistenza di altri microservizi. Se l'applicazione si basa sull'accoppiamento di microservizi come illustrato nell'esempio, sarà quasi impossibile ottenere l'autonomia per singolo microservizio.
Errori in un qualsiasi microservizio. Se è stata implementata una catena di microservizi collegata tramite chiamate HTTP, in caso di errore di uno dei microservizi (situazione che si verifica inevitabilmente), si verificheranno errori nell'intera catena di microservizi. Un sistema basato su microservizi deve essere progettato in modo da continuare a funzionare nel miglior modo possibile in caso di errori parziali. Anche se si implementa la logica client che usa tentativi con meccanismi di interruttore o backoff esponenziale, più complesse sono le catene di chiamate HTTP, più difficile sarà implementare una strategia di gestione degli errori basata su HTTP.
Di fatto, se per comunicare i microservizi interni creano catene di richieste HTTP come descritto, potrebbe sembrare che l'applicazione sia monolitica, ma basata su HTTP tra processi anziché su meccanismi di comunicazione all'interno di processi.
Per imporre l'autonomia dei microservizi e ottenere una migliore resilienza, è necessario ridurre al minimo l'uso di catene di comunicazione richiesta/risposta tra microservizi. È consigliabile usare solo l'interazione asincrona per la comunicazione tra microservizi, sia tramite comunicazione asincrona basata su messaggi ed eventi che tramite il polling HTTP (asincrono), indipendentemente dal ciclo originale di richiesta/risposta HTTP.
Per altre informazioni sull'uso della comunicazione asincrona, vedere le sezioni L'integrazione di microservizi asincroni impone l'autonomia del microservizio e Comunicazione asincrona basata su messaggi più avanti in questa guida.
Risorse aggiuntive
Teorema CAP
https://en.wikipedia.org/wiki/CAP_theoremCoerenza finale
https://en.wikipedia.org/wiki/Eventual_consistencyNozioni di base sulla coerenza dei dati
https://video2.skills-academy.com/previous-versions/msp-n-p/dn589800(v=pandp.10)Martin Fowler. CQRS (Command and Query Responsibility Segregation)
https://martinfowler.com/bliki/CQRS.htmlVista materializzata
https://video2.skills-academy.com/azure/architecture/patterns/materialized-viewCharles Row. ACID vs. BASE: The Shifting pH of Database Transaction Processing
https://www.dataversity.net/acid-vs-base-the-shifting-ph-of-database-transaction-processing/Transazione di compensazione
https://video2.skills-academy.com/azure/architecture/patterns/compensating-transactionUdi Dahan. Service Oriented Composition (Composizione orientata ai servizi)
https://udidahan.com/2014/07/30/service-oriented-composition-with-video/