Creazione di un microservizio CRUD semplice basato sui dati
Suggerimento
Questo contenuto è un estratto dell'eBook "Microservizi .NET: Architettura per le applicazioni .NET incluse in contenitori", disponibile in .NET Docs o come PDF scaricabile gratuitamente e da poter leggere offline.

Questa sezione spiega come creare un semplice microservizio che esegue operazioni CRUD (create, read, update, delete), ovvero di creazione, lettura, aggiornamento ed eliminazione, su un'origine dati.
Progettazione di un microservizio CRUD semplice
Dal punto di vista della progettazione, questo tipo di microservizio in contenitori è molto semplice. È probabile che il problema da risolvere sia semplice o che l'implementazione sia solo un modello di verifica.
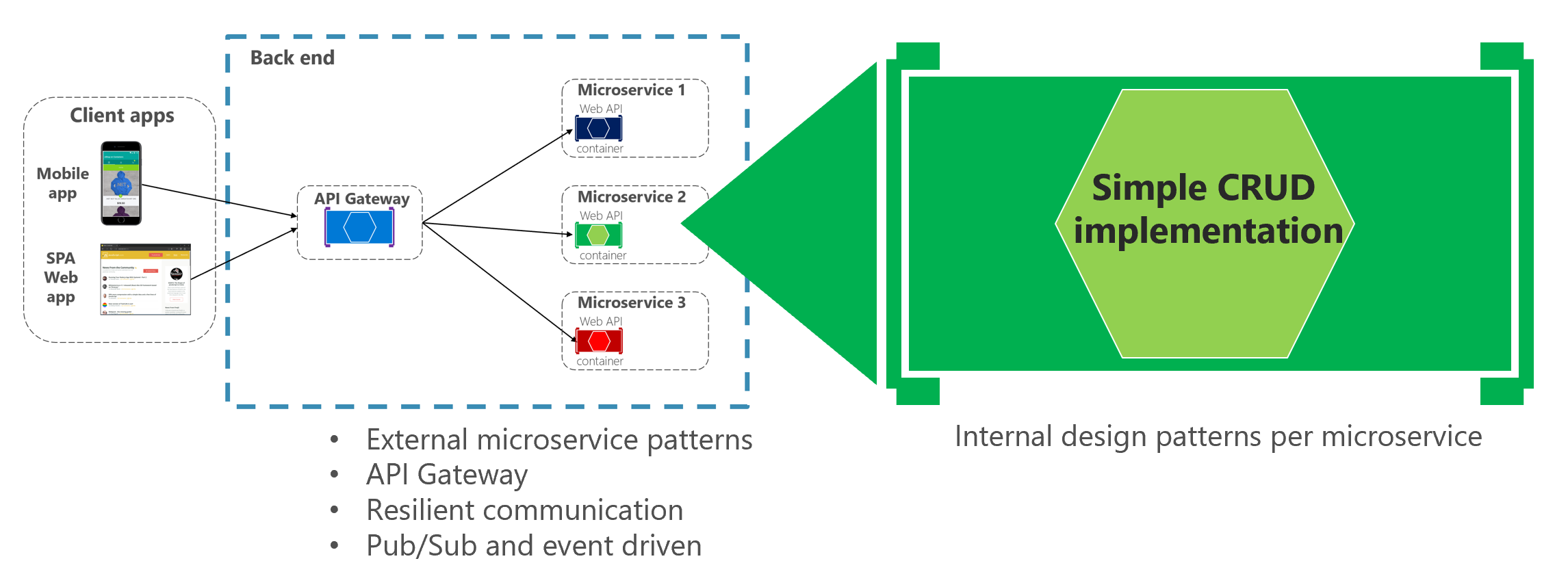
Figura 6-4. Progettazione interna per microservizi CRUD semplici
Un esempio di questo tipo di servizio semplice basato sui dati è il microservizio Catalog dall'applicazione di esempio eShopOnContainers. Questo tipo di servizio implementa tutte le funzionalità in un unico progetto API Web ASP.NET Core che include le classi per il relativo modello di dati, la relativa logica di business e il relativo codice di accesso ai dati. Archivia anche i dati correlati in un database in esecuzione in SQL Server (come un altro contenitore per scopi di sviluppo/test), ma potrebbe essere anche un qualsiasi normale host di SQL Server, come illustrato nella Figura 6-5.
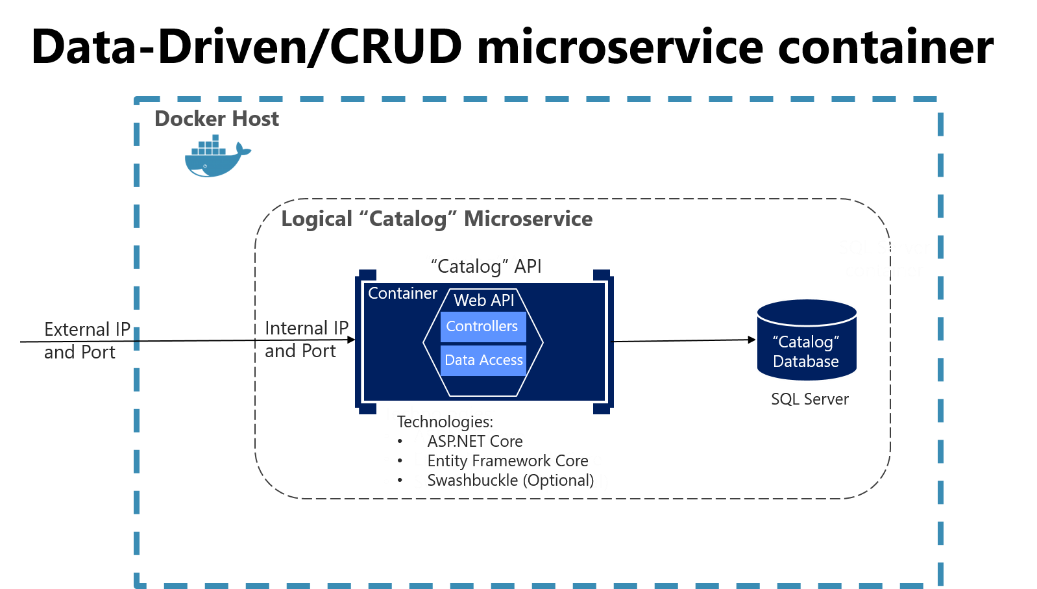
Figura 6-5. Progettazione di un microservizio CRUD/basato sui dati semplice
Il diagramma precedente illustra il microservizio logico Catalog, che include il proprio database Catalog, che può essere incluso o meno nello stesso host Docker. Il fatto che il database sia incluso nello stesso host Docker potrebbe essere ottimale per lo sviluppo, ma non per la produzione. Quando si sviluppa questo tipo di servizio, sono necessari solo ASP.NET Core e una API di accesso ai dati oppure ORM come Entity Framework Core. È anche possibile generare automaticamente metadati Swagger tramite Swashbuckle per fornire una descrizione delle funzionalità offerte del servizio, come spiegato nella sezione successiva.
Si noti che poter eseguire un server di database, come SQL Server, all'interno di un contenitore Docker è ideale per gli ambienti di sviluppo, perché garantisce che tutte le dipendenze siano attive e in esecuzione senza dover eseguire il provisioning di un database nel cloud o in locale. Questo approccio risulta molto utile quando si eseguono test di integrazione. Per ambienti di produzione, però, è consigliabile non eseguire un server di database in un contenitore perché in genere tale approccio non garantisce una disponibilità elevata. Per un ambiente di produzione in Azure, è consigliabile usare Azure SQL DB o una qualsiasi altra tecnologia di database in grado di offrire disponibilità e scalabilità elevate. Per un approccio NoSQL è ad esempio possibile scegliere CosmosDB.
Modificando infine i file di metadati di Dockerfile e di docker-compose.yml, è possibile configurare la modalità di creazione dell'immagine di questo contenitore, ovvero quale immagine di base userà, oltre ad impostazioni di progettazione, come i nomi interni ed esterni e le porte TCP.
Implementazione di un microservizio CRUD semplice con ASP.NET Core
Per implementare un microservizio CRUD semplice con .NET e Visual Studio, è innanzitutto necessario creare un progetto API Web ASP.NET Core semplice (in esecuzione in .NET, in modo che sia eseguibile in un host Docker Linux), come illustrato nella Figura 6-6.
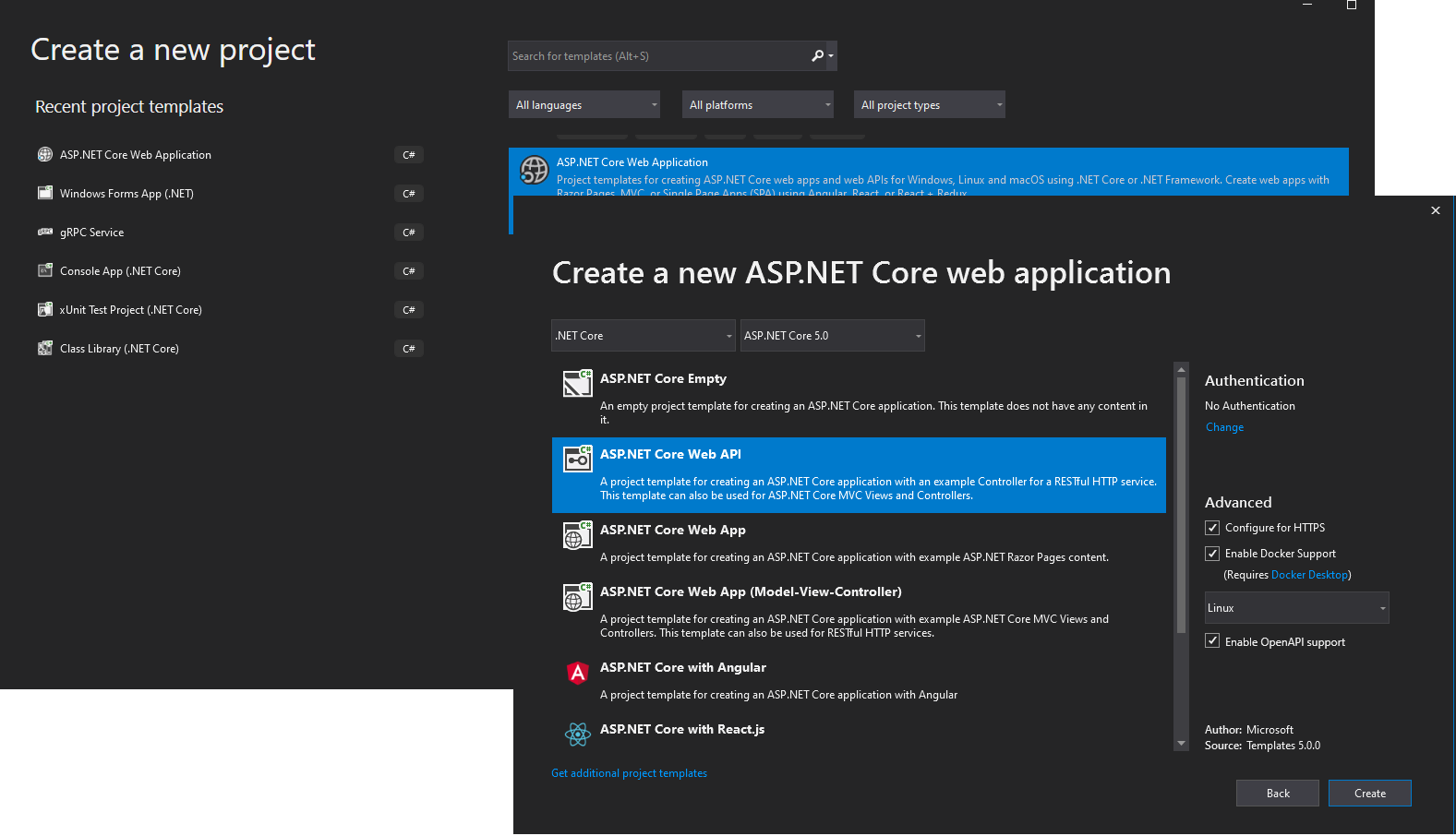
Figura 6-6. Creazione di un progetto API Web ASP.NET Core in Visual Studio 2019
Per creare un progetto API Web ASP.NET Core, selezionare prima un'applicazione Web ASP.NET Core, quindi selezionare il tipo di API. Dopo aver creato il progetto, è possibile implementare i controller MVC, come in qualsiasi altro progetto API Web, usando l'API di Entity Framework o altre API. In un nuovo progetto API Web è possibile notare che l'unica dipendenza presente in tale microservizio è su ASP.NET Core stesso. Internamente, nella dipendenza Microsoft.AspNetCore.All, il progetto include riferimenti a Entity Framework e a molti altri pacchetti NuGet di .NET, come illustrato nella Figura 6-7.
Figura 6-7. Dipendenze in un microservizio API Web CRUD semplice
Il progetto API include riferimenti al pacchetto NuGet Microsoft.AspNetCore.App, che a sua volta include riferimenti a tutti i pacchetti essenziali. Può anche includere altri pacchetti.
Implementazione di servizi API Web CRUD con Entity Framework Core
Entity Framework (EF) Core è una versione semplice, estendibile e multipiattaforma della tecnologia di accesso dati Entity Framework più diffusa. EF Core è un mapper relazionale a oggetti che consente agli sviluppatori di .NET di usare un database con gli oggetti .NET.
Il microservizio Catalog usa Entity Framework e il provider SQL Server perché il relativo database è in esecuzione in un contenitore con l'immagine di SQL Server per Linux Docker. Il database può però essere distribuito in qualsiasi istanza di SQL Server, ad esempio Windows locale o Azure SQL DB. L'unico elemento da modificare è la stringa di connessione nel microservizio API Web ASP.NET.
Modello di dati
Con Entity Framework Core, l'accesso ai dati viene eseguito tramite un modello. Un modello è costituito da classi di entità (modello di dominio) e da un contesto derivato (DbContext) che rappresenta una sessione con il database, per eseguire una query e salvare i dati. È possibile generare un modello da un database esistente, scrivere manualmente il codice di un modello in modo che corrisponda al database oppure usare tecniche di migrazione di Entity Framework per creare un database a partire dal modello, usando l'approccio incentrato sul codice (che facilita lo sviluppo del database di pari passo con l'evoluzione del modello nel tempo). Per il microservizio Catalog è stato usato l'ultimo approccio. Nell'esempio di codice seguente è incluso un esempio della classe di entità CatalogItem, che è una semplice classe di entità POCO (Plain Old Class Object).
public class CatalogItem
{
public int Id { get; set; }
public string Name { get; set; }
public string Description { get; set; }
public decimal Price { get; set; }
public string PictureFileName { get; set; }
public string PictureUri { get; set; }
public int CatalogTypeId { get; set; }
public CatalogType CatalogType { get; set; }
public int CatalogBrandId { get; set; }
public CatalogBrand CatalogBrand { get; set; }
public int AvailableStock { get; set; }
public int RestockThreshold { get; set; }
public int MaxStockThreshold { get; set; }
public bool OnReorder { get; set; }
public CatalogItem() { }
// Additional code ...
}
È inoltre necessario una classe DbContext che rappresenta una sessione con il database. Per il microservizio Catalog la classe CatalogContext deriva dalla classe di base di DbContext, come illustrato nell'esempio seguente:
public class CatalogContext : DbContext
{
public CatalogContext(DbContextOptions<CatalogContext> options) : base(options)
{ }
public DbSet<CatalogItem> CatalogItems { get; set; }
public DbSet<CatalogBrand> CatalogBrands { get; set; }
public DbSet<CatalogType> CatalogTypes { get; set; }
// Additional code ...
}
Possono esistere altre implementazioni di DbContext. Ad esempio, nel microservizio Catalog.API di esempio, è presente un secondo elemento DbContext denominato CatalogContextSeed in cui inserisce automaticamente i dati di esempio la prima volta che prova ad accedere al database. Questo metodo è utile anche per i dati di demo e per scenari di test automatizzati.
All'interno di DbContext si usa il metodo OnModelCreating per personalizzare i mapping di entità di oggetto/database e altri punti di estendibilità di Entity Framework.
Esecuzione di query sui dati da controller API Web
Per recuperare le istanze di classi di entità dal database si usa in genere LINQ (Language Integrated Query), come illustrato nell'esempio seguente:
[Route("api/v1/[controller]")]
public class CatalogController : ControllerBase
{
private readonly CatalogContext _catalogContext;
private readonly CatalogSettings _settings;
private readonly ICatalogIntegrationEventService _catalogIntegrationEventService;
public CatalogController(
CatalogContext context,
IOptionsSnapshot<CatalogSettings> settings,
ICatalogIntegrationEventService catalogIntegrationEventService)
{
_catalogContext = context ?? throw new ArgumentNullException(nameof(context));
_catalogIntegrationEventService = catalogIntegrationEventService
?? throw new ArgumentNullException(nameof(catalogIntegrationEventService));
_settings = settings.Value;
context.ChangeTracker.QueryTrackingBehavior = QueryTrackingBehavior.NoTracking;
}
// GET api/v1/[controller]/items[?pageSize=3&pageIndex=10]
[HttpGet]
[Route("items")]
[ProducesResponseType(typeof(PaginatedItemsViewModel<CatalogItem>), (int)HttpStatusCode.OK)]
[ProducesResponseType(typeof(IEnumerable<CatalogItem>), (int)HttpStatusCode.OK)]
[ProducesResponseType((int)HttpStatusCode.BadRequest)]
public async Task<IActionResult> ItemsAsync(
[FromQuery]int pageSize = 10,
[FromQuery]int pageIndex = 0,
string ids = null)
{
if (!string.IsNullOrEmpty(ids))
{
var items = await GetItemsByIdsAsync(ids);
if (!items.Any())
{
return BadRequest("ids value invalid. Must be comma-separated list of numbers");
}
return Ok(items);
}
var totalItems = await _catalogContext.CatalogItems
.LongCountAsync();
var itemsOnPage = await _catalogContext.CatalogItems
.OrderBy(c => c.Name)
.Skip(pageSize * pageIndex)
.Take(pageSize)
.ToListAsync();
itemsOnPage = ChangeUriPlaceholder(itemsOnPage);
var model = new PaginatedItemsViewModel<CatalogItem>(
pageIndex, pageSize, totalItems, itemsOnPage);
return Ok(model);
}
//...
}
Salvataggio dei dati
I dati vengano creati, eliminati e modificati nel database tramite le istanze di classi di entità. È possibile aggiungere codice analogo all'esempio hardcoded seguente (dati fittizi, in questo caso) ai controller API Web.
var catalogItem = new CatalogItem() {CatalogTypeId=2, CatalogBrandId=2,
Name="Roslyn T-Shirt", Price = 12};
_context.Catalog.Add(catalogItem);
_context.SaveChanges();
Inserimento delle dipendenze in ASP.NET Core e controller API Web
In ASP.NET Core è possibile usare il modello predefinito di inserimento delle dipendenze. Non è necessario configurare un contenitore IoC (Inversion of Control) di terze parti, anche se è possibile inserire il contenitore IoC preferito nell'infrastruttura ASP.NET Core. In questo caso, è possibile inserire direttamente la classe DBContext richiesta di Entity Framework o altri repository tramite il costruttore del controller.
Nella classe CatalogController menzionata in precedenza, il tipo CatalogContext (che eredita da DbContext) viene inserito insieme agli altri oggetti necessari nel costruttore CatalogController().
Un'importante configurazione da definire nel progetto API Web è la registrazione della classe DbContext nel contenitore IoC del servizio. Tale operazione viene in genere eseguita nel file Program.cs chiamando il metodo builder.Services.AddDbContext<CatalogContext>(), come illustrato nell'esempio semplificato seguente:
// Additional code...
builder.Services.AddDbContext<CatalogContext>(options =>
{
options.UseSqlServer(builder.Configuration["ConnectionString"],
sqlServerOptionsAction: sqlOptions =>
{
sqlOptions.MigrationsAssembly(
typeof(Program).GetTypeInfo().Assembly.GetName().Name);
//Configuring Connection Resiliency:
sqlOptions.
EnableRetryOnFailure(maxRetryCount: 5,
maxRetryDelay: TimeSpan.FromSeconds(30),
errorNumbersToAdd: null);
});
// Changing default behavior when client evaluation occurs to throw.
// Default in EFCore would be to log warning when client evaluation is done.
options.ConfigureWarnings(warnings => warnings.Throw(
RelationalEventId.QueryClientEvaluationWarning));
});
Risorse aggiuntive
Esecuzione di query su dati
https://video2.skills-academy.com/ef/core/querying/indexSalvataggio di dati
https://video2.skills-academy.com/ef/core/saving/index
Stringa di connessione di database e variabili di ambiente usate dai contenitori Docker
È possibile usare le impostazioni di ASP.NET Core e aggiungere una proprietà ConnectionString al file settings.json come illustrato nell'esempio seguente:
{
"ConnectionString": "Server=tcp:127.0.0.1,5433;Initial Catalog=Microsoft.eShopOnContainers.Services.CatalogDb;User Id=sa;Password=[PLACEHOLDER]",
"ExternalCatalogBaseUrl": "http://host.docker.internal:5101",
"Logging": {
"IncludeScopes": false,
"LogLevel": {
"Default": "Debug",
"System": "Information",
"Microsoft": "Information"
}
}
}
Il file settings.json può contenere valori predefiniti per la proprietà ConnectionString o per qualsiasi altra proprietà. Quando si usa Docker, però, tali proprietà verranno però sovrascritte dai valori delle variabili di ambiente specificate nel file docker-compose.override.yml.
Dal file docker-compose.yml o docker-compose.override.yml è possibile inizializzare le variabili di ambiente in modo che Docker le configuri automaticamente come variabili di ambiente del sistema operativo, come illustrato nel file docker-compose.override.yml seguente. In questo esempio la stringa di connessione e le altre righe vanno a capo, ma dovrebbero rimanere sulla stessa riga nel file dell'utente.
# docker-compose.override.yml
#
catalog-api:
environment:
- ConnectionString=Server=sqldata;Database=Microsoft.eShopOnContainers.Services.CatalogDb;User Id=sa;Password=[PLACEHOLDER]
# Additional environment variables for this service
ports:
- "5101:80"
I file docker-compose.yml a livello di soluzione non sono solo più flessibili dei file di configurazione a livello di progetto o microservizio, ma anche più sicuri se si sostituiscono le variabili di ambiente dichiarate nei file docker-compose con i valori impostati dagli strumenti di distribuzione, ad esempio dalle attività di distribuzione di Azure DevOps Services Docker.
Infine, è possibile ottenere tale valore dal codice usando builder.Configuration\["ConnectionString"\], come illustrato in un esempio di codice precedente.
Per ambienti di produzione, però, è possibile che si voglia esplorare altre modalità di archiviazione dei segreti, ad esempio le stringhe di connessione. Un metodo ottimale per la gestione dei segreti dell'applicazione è l'uso di Azure Key Vault.
Azure Key Vault contribuisce ad archiviare proteggere i segreti e le chiavi di crittografia usati dai servizi e dalle applicazioni cloud dell'utente. Un segreto è un elemento sul quale di desidera avere un controllo restrittivo, ad esempio le chiavi API, le stringhe di connessione, le password e così via. Il controllo restrittivo include tra le altre caratteristiche la registrazione dell'uso, l'impostazione della scadenza e la gestione dell'accesso.
Azure Key Vault consente un livello di controllo dettagliato sull'uso dei segreti dell'applicazione, senza che altri utenti debbano conoscerli. I segreti possono anche essere ruotati per la sicurezza avanzata, senza interrompere lo sviluppo o il funzionamento.
Le applicazioni devono essere registrate in Active Directory per l'organizzazione, in modo che possano usare Key Vault.
Per informazioni dettagliate, vedere la documentazione Concetti di Key Vault.
Implementazione del controllo delle versioni in API Web ASP.NET
In seguito alla modifica dei requisiti di business, è possibile che vengano aggiunte nuove raccolte di risorse, che le relazioni tra le risorse cambino e che la struttura dei dati nelle risorse subisca modifiche. L'aggiornamento di un'API Web in modo che possa gestire i nuovi requisiti è un processo relativamente semplice, ma è necessario considerare gli effetti che tali modifiche avranno sulle applicazioni client che utilizzano l'API Web. Anche se lo sviluppatore che progetta e implementa un'API Web dispone del controllo completo su tale API, non può avere lo stesso livello di controllo sulle applicazioni client che potrebbero essere create da organizzazioni di terze parti operanti in remoto.
Il controllo delle versioni consente a un'API Web di indicare le funzionalità e le risorse che espone. Un'applicazione client può quindi inviare richieste a una versione specifica di una funzione o di una risorsa. Esistono diversi approcci per l'implementazione del controllo delle versioni:
Controllo delle versioni tramite l’URI
Controllo delle versioni tramite la stringa di query
Controllo delle versioni tramite l’intestazione
Il controllo delle versioni della stringa di query e dell'URI sono i più semplici da implementare. Il controllo delle versioni dell'intestazione costituisce un valido approccio, Tuttavia, il controllo delle versioni dell’intestazione non è esplicito e semplice come il controllo delle versioni dell'URI. Dal momento che è il più semplice e il più esplicito, il controllo delle versioni dell'URI è l'approccio usato nell'applicazione di esempio eShopOnContainers.
Con il controllo delle versioni dell'URI, secondo l'implementazione dell'applicazione di esempio eShopOnContainers, ogni volta che si modifica l'API Web o si cambia lo schema delle risorse, per ogni risorsa viene aggiunto un numero di versione all'URI. Gli URI esistenti continueranno a funzionare come prima, restituendo le risorse conformi allo schema che corrisponde alla versione richiesta.
Come illustrato nell'esempio di codice seguente, è possibile impostare la versione usando l'attributo Route nel controller API Web, in modo da renderla esplicita nell'URI (v1 in questo caso).
[Route("api/v1/[controller]")]
public class CatalogController : ControllerBase
{
// Implementation ...
Questo meccanismo di controllo delle versioni è semplice e dipende dal server che inoltra la richiesta all'endpoint appropriato. Per un controllo delle versioni più sofisticato e per il metodo migliore quando si usa REST, tuttavia, è opportuno usare ipermedia e implementare HATEOAS (Hypertext as the Engine of Application State).
Risorse aggiuntive
Controllo delle versioni dell'API ASP.NET \ https://github.com/dotnet/aspnet-api-versioning
Scott Hanselman. ASP.NET Core RESTful Web API versioning made easy (Controllo facilitato delle versioni delle API Web ASP.NET Core RESTful)
https://www.hanselman.com/blog/ASPNETCoreRESTfulWebAPIVersioningMadeEasy.aspxVersioning a RESTful web API (Controllo delle versioni delle API Web RESTful)
https://video2.skills-academy.com/azure/architecture/best-practices/api-design#versioning-a-restful-web-apiRoy Fielding. Versioning, Hypermedia, and REST (Controllo delle versioni, ipermedia e REST)
https://www.infoq.com/articles/roy-fielding-on-versioning
Generazione dei metadati delle descrizioni Swagger dall'API Web ASP.NET Core
Swagger è un framework open source di uso comune basato su un vasto ecosistema di strumenti che consentono di progettare, creare, documentare e utilizzare API RESTful. Si sta affermando come lo standard per il dominio dei metadati delle descrizioni di API. È opportuno includere i metadati delle descrizioni Swagger con qualsiasi tipo di microservizio, sia quelli basati sui dati che quelli più avanzati basati su dominio, come descritto nella sezione seguente.
L'elemento centrale di Swagger è la specifica Swagger, costituita dai metadati delle descrizioni di API salvati in un file JSON o YAML. La specifica crea il contratto RESTful per l'API, che elenca in dettaglio tutte le risorse e le operazioni sia nel formato leggibile che in quello macchina, per agevolare lo sviluppo, l'individuazione e l'integrazione.
La specifica è la base della specifica OpenAPI (OAS) ed è sviluppata in una community aperta, trasparente e collaborativa allo scopo di standardizzare le modalità di definizione delle interfacce RESTful.
La specifica definisce la struttura in base alla quale è possibile individuare un servizio e riconoscerne le funzionalità. Per altre informazioni, tra cui un editor Web ed esempi di specifiche Swagger rese disponibili da società quali Spotify, Uber, Slack e Microsoft, visitare il sito di Swagger (https://swagger.io).
Perché usare Swagger?
I motivi principali per generare i metadati di Swagger per le API sono i seguenti.
Consentire ad altri prodotti di utilizzare e integrare automaticamente le API. Decine di prodotti e strumenti in commercio, oltre a numerosi framework e librerie supportano Swagger. Microsoft offre prodotti e strumenti di alto livello in grado di utilizzare automaticamente API basate su Swagger, tra cui:
AutoRest. È possibile generare automaticamente le classi client .NET per chiamare Swagger. Questo strumento può essere usato dall'interfaccia della riga di comando ed è inoltre integrato in Visual Studio in modo da poterlo usare più facilmente tramite l'interfaccia utente grafica.
Microsoft Flow. È possibile usare e integrare automaticamente l'API in un flusso di lavoro Microsoft Flow di alto livello senza che siano necessarie competenze di programmazione.
Microsoft PowerApps. È possibile utilizzare automaticamente l'API da app per dispositivi mobili PowerApps create con PowerApps Studio senza che siano necessarie competenze di programmazione.
App per la logica del servizio app di Azure. È possibile usare e integrare automaticamente l'API in un'app per la logica del servizio app di Azure senza che siano necessarie competenze di programmazione.
Consente di generare automaticamente la documentazione dell'API. Quando si creano API RESTful su vasta scala, ad esempio applicazioni complesse basate su microservizi, è necessario gestire molti endpoint con modelli di dati diversi usati nei payload di richiesta e risposta. Poter disporre della documentazione adeguata e di un solido strumento Esplora API, come avviene con Swagger, è di fondamentale importanza per l'applicazione delle API e per fare in modo che vengano adottate dagli sviluppatori.
Microsoft Flow, PowerApps e le app per la logica di Azure usano proprio i metadati di Swagger per sapere come usare le API e connettersi ad esse.
Sono disponibili diverse opzioni per automatizzare la generazione di metadati di Swagger per le applicazioni API REST di ASP.NET Core, sotto forma di pagine della Guida dell'API funzionale basate su swagger-ui.
La più diffusa è probabilmente Swashbuckle, che è usata attualmente in eShopOnContainers e verrà illustrata in maggior dettaglio in questa guida. È anche possibile usare NSwag, che genera client API Typescript e C# e controller C# da una specifica Swagger o OpenAPI e anche tramite scansione del file DLL contenente i controller, mediante NSwagStudio.
Come automatizzare la generazione di metadati di Swagger per le API con il pacchetto NuGet Swashbuckle
La generazione manuale di metadati di Swagger, in un file JSON o YAML, può essere un lavoro noioso. È però possibile automatizzare l'individuazione delle API per i servizi delle API Web ASP.NET usando il pacchetto NuGet Swashbuckle per generare dinamicamente i metadati di Swagger per le API.
Swashbuckle genera automaticamente i metadati di Swagger per i progetti di API Web ASP.NET. Supporta i progetti API Web ASP.NET Core e l'API Web ASP.NET tradizionale, oltre a qualsiasi altra versione, ad esempio i microservizi delle app per le API di Azure, per le app per dispositivi mobili di Azure e Azure Service Fabric basati su ASP.NET. Supporta anche API Web semplici distribuite nei contenitori, come nel caso dell'applicazione di riferimento.
Swashbuckle combina Esplora API e Swagger o swagger-ui per offrire un'esperienza di individuazione e documentazione completa per i consumer di API. Oltre al motore di generazione dei metadati di Swagger, Swashbuckle contiene anche una versione incorporata di swagger-ui, che verrà eseguito automaticamente una volta installato Swashbuckle.
Questo significa che è possibile offrire a corredo dell'API con una comoda interfaccia utente di individuazione per consentire agli sviluppatori di usare l'API. Tale interfaccia richiede una piccola quantità di codice e manutenzione perché è generata automaticamente, consentendo all'utente di concentrare l'attenzione sulla creazione dell'API. Il risultato per Esplora API è simile a quello illustrato nella Figura 6-8.
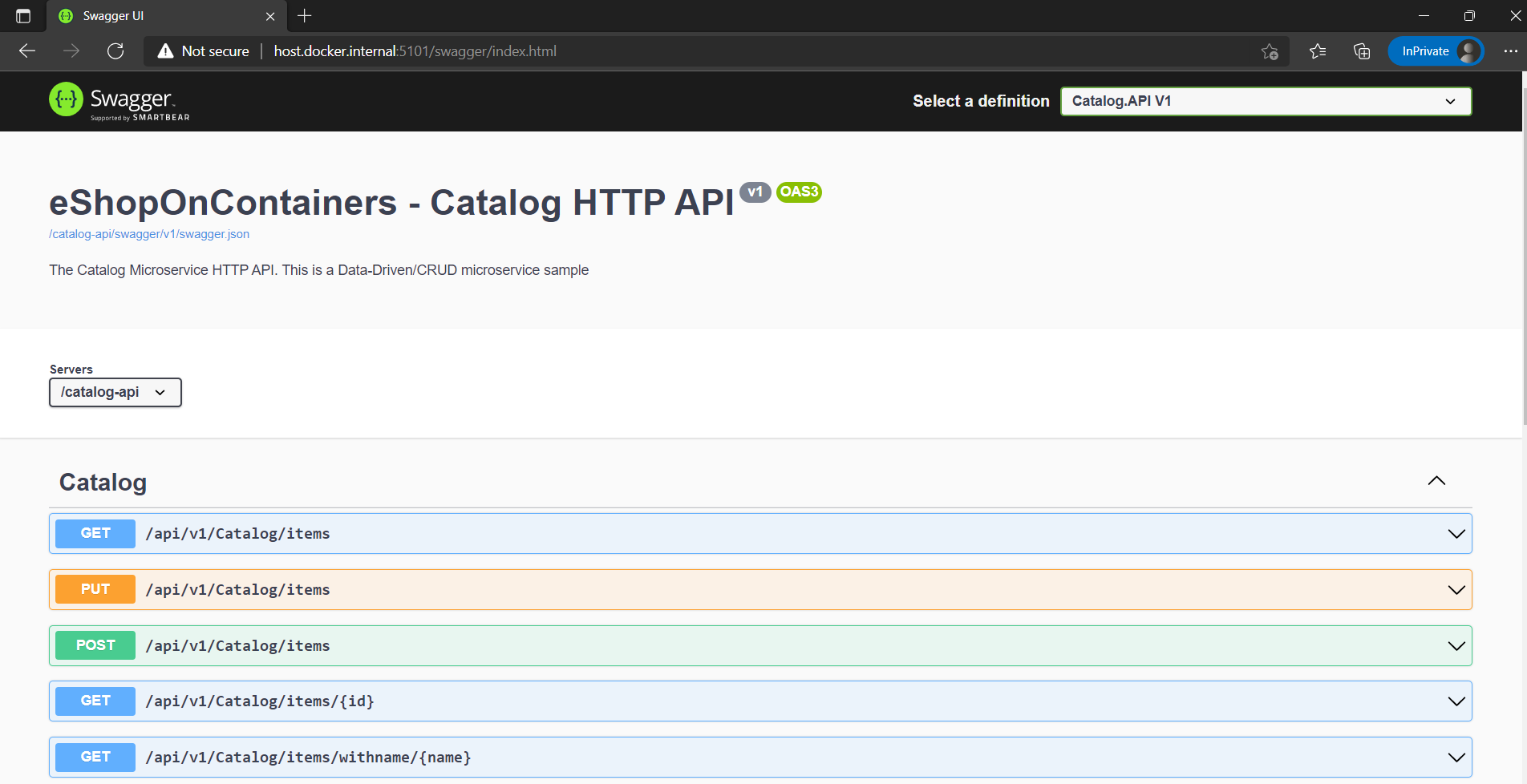
Figura 6-8. Interfaccia Esplora API Swashbuckle basato su metadati di Swagger: microservizio Catalog di eShopOnContainers
L'API dell'interfaccia utente di Swagger generata da Swashbuckle include tutte le azioni pubblicate. Ma l'interfaccia Esplora API non è l'aspetto più interessante in questo caso. Dopo aver creato un'API Web in grado di descrivere se stessa nei metadati di Swagger, è possibile usare facilmente l'API da strumenti basati su Swagger, inclusi i generatori di codice di classe proxy client che possono essere destinati a più piattaforme. Come già accennato, ad esempio, AutoRest genera automaticamente classi client .NET. Ma sono disponibili anche strumenti aggiuntivi, come swagger codegen, che consente di generare automaticamente il codice di librerie client API, stub server e documentazione.
Attualmente Swashbuckle è costituito da cinque pacchetti NuGet interni sotto il metapacchetto di alto livello Swashbuckle.AspNetCore per le applicazioni ASP.NET Core.
Dopo aver installato questi pacchetti NuGet nel progetto API Web, è necessario configurare Swagger nella classe Program.cs, come illustrato nel codice semplificato seguente:
// Add framework services.
builder.Services.AddSwaggerGen(options =>
{
options.DescribeAllEnumsAsStrings();
options.SwaggerDoc("v1", new OpenApiInfo
{
Title = "eShopOnContainers - Catalog HTTP API",
Version = "v1",
Description = "The Catalog Microservice HTTP API. This is a Data-Driven/CRUD microservice sample"
});
});
// Other startup code...
app.UseSwagger();
if (app.Environment.IsDevelopment())
{
app.UseSwaggerUI(c =>
{
c.SwaggerEndpoint("/swagger/v1/swagger.json", "My API V1");
});
}
Al termine, è possibile avviare l'applicazione e sfogliare gli endpoint dell'interfaccia utente e JSON di Swagger seguenti usando URL simili a questi:
http://<your-root-url>/swagger/v1/swagger.json
http://<your-root-url>/swagger/
In precedenza è stata illustrata l'interfaccia utente generata creata da Swashbuckle per un URL come http://<your-root-url>/swagger. Nella Figura 6-9 è anche possibile vedere come eseguire il test di un qualsiasi metodo di API.
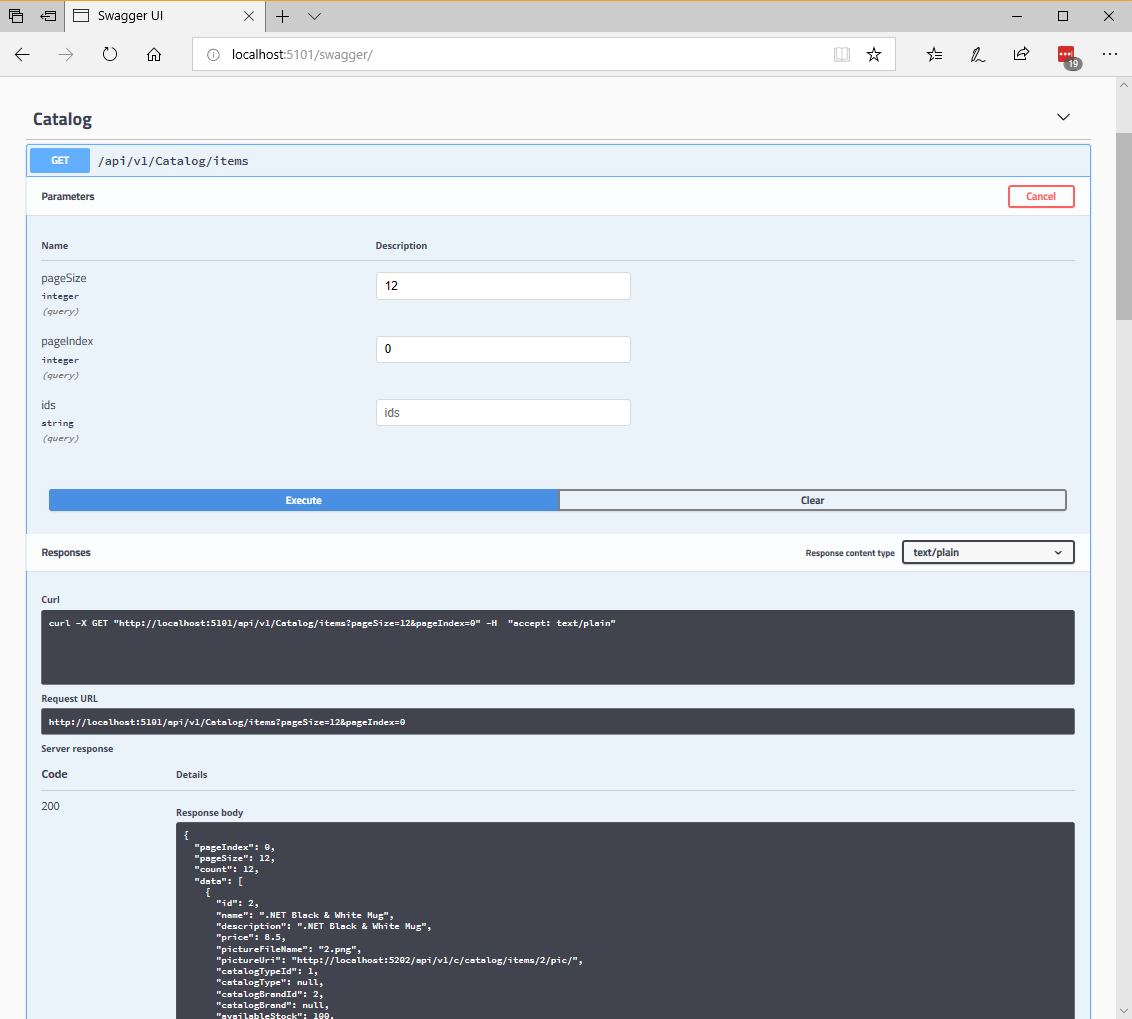
Figura 6-9. Test del metodo API Catalog/Items nell'interfaccia utente di Swashbuckle
I dettagli dell'API interfaccia utente di Swagger visualizzano un esempio della risposta e possono essere usati per eseguire l'API reale, molto utile per l'individuazione degli sviluppatori. Per visualizzare i metadati JSON di Swagger generati dal microservizio eShopOnContainers (ovvero quello che gli strumenti usano nel livello sottostante) effettuare una richiesta http://<your-root-url>/swagger/v1/swagger.json usando Visual Studio Code: estensione client REST.
Risorse aggiuntive
Pagine della Guida dell'API Web ASP.NET con Swagger
https://video2.skills-academy.com/aspnet/core/tutorials/web-api-help-pages-using-swaggerIntroduzione a Swashbuckle e ad ASP.NET Core
https://video2.skills-academy.com/aspnet/core/tutorials/getting-started-with-swashbuckleIntroduzione a NSwag e ad ASP.NET Core
https://video2.skills-academy.com/aspnet/core/tutorials/getting-started-with-nswag