Esercitazione: Analizzare il sentiment dei commenti dei siti Web in un'applicazione Web usando ML.NET Model Builder
Scopri come analizzare il sentimento dai commenti in tempo reale all'interno di un'applicazione web.
Questa esercitazione illustra come creare un'applicazione Razor Pages di ASP.NET Core che classifica il sentiment dai commenti del sito Web in tempo reale.
In questa esercitazione si apprenderà come:
- Creare un'applicazione ASP.NET Core Razor Pages
- Preparare e comprendere i dati
- Scegliere uno scenario
- Carica i dati
- Addestrare il modello
- Valutare il modello
- Usare il modello per le stime
Il codice sorgente per questa esercitazione è disponibile nel repository dotnet/machinelearning-samples.
Prerequisiti
Per un elenco dei prerequisiti e delle istruzioni di installazione, vedere la guida all'installazione di Model Builder.
Creare un'applicazione Razor Pages
Creare un'applicazione ASP.NET Core Razor Pages .
- In Visual Studio apri la finestra di dialogo Crea un nuovo progetto.
- Nella finestra di dialogo "Crea un nuovo progetto" selezionare il modello di progetto
ASP.NET Core Web App. - Nella casella di testo Nome, digitare "SentimentRazor" e selezionare Avanti.
- Nella finestra di dialogo Informazioni aggiuntive lasciare invariate tutte le impostazioni predefinite e selezionare Crea.
Preparare e comprendere i dati
Scarica il dataset "Wikipedia Detox" . Quando si apre la pagina Web, fare clic con il pulsante destro del mouse sulla pagina, selezionare Salva con nome e salvare il file in qualsiasi punto del computer.
Ogni riga nel set di dati wikipedia-detox-250-line-data.tsv rappresenta una recensione diversa lasciata da un utente su Wikipedia. La prima colonna rappresenta il sentiment del testo (0 è non tossico, 1 è tossico) e la seconda colonna rappresenta il commento lasciato dall'utente. Le colonne sono separate da tabulazioni. I dati sono simili ai seguenti:
| Sentimento | Testo del Sentimento |
|---|---|
| 1 | ==RUDE== Amico, sei scortese, carica di nuovo quella foto di Carl, altrimenti. |
| 1 | == OK! == STA PER VANDALIZZARE QUELLI SELVATICI WIKI THEN!! |
| 0 | Spero che questo aiuti. |
Creare un file di configurazione di Model Builder
Quando si aggiunge per la prima volta un modello di Machine Learning alla soluzione, verrà richiesto di creare un file mbconfig. Il file mbconfig tiene traccia di tutto ciò che si esegue in Generatore modelli per consentire di riaprire la sessione.
- In Esplora soluzioni , fare clic con il pulsante destro del mouse sul progetto SentimentRazor e selezionare Aggiungi>modello di apprendimento automatico.
- Nella finestra di dialogo, inserire il nome del progetto Generatore modelli SentimentAnalysis.mbconfige selezionare Aggiungi.
Scegliere uno scenario

Per eseguire il training del modello, è necessario selezionare dall'elenco degli scenari di Machine Learning disponibili forniti da Model Builder.
Per questo esempio, l'attività è classificazione del testo. Nello scenario , passaggio, dell'estensione Generatore modelli, selezionare lo scenario classificazione del testo.
Selezionare un ambiente
Model Builder può addestrare su ambienti diversi a seconda dello scenario selezionato.
Selezionare Locale (GPU) come ambiente e fare clic sul pulsante passaggio successivo.
Nota
Questo scenario usa tecniche di Deep Learning che funzionano meglio negli ambienti GPU. Se non si ha una GPU, scegliere l'ambiente locale (CPU), ma tenere presente che il tempo previsto per l'addestramento sarà notevolmente più lungo. Per altre informazioni sull'uso di GPU con Model Builder, vedere la guida GPU in Generatore modelli.
Carica i dati
Model Builder accetta dati da due origini, un database di SQL Server o un file locale in formato csv o tsv.
- Nella fase dei dati dello strumento Generatore modelli, selezionare File dalle opzioni dell'origine dati.
- Selezionare il pulsante accanto alla casella di testo Selezionare un file e usare Esplora file per esplorare e selezionare il file wikipedia-detox-250-line-data.tsv.
- Scegliere Sentiment dalla Colonna per prevedere (etichetta) dall'elenco a discesa.
- Scegliere SentimentText dall'elenco a discesa della colonna di testo .
- Selezionare il pulsante Passaggio successivo per procedere al passaggio successivo in Model Builder.
Addestrare il modello
L'attività di machine learning usata per addestrare il modello di analisi del sentiment in questo tutorial è la classificazione del testo. Durante il processo di formazione del modello, Model Builder addestra un modello di classificazione del testo per il set di dati usando l'architettura di rete neurale NAS-BERT.
Selezionare Avvia allenamento.
Al termine del training, i risultati del processo di training vengono visualizzati nella sezione Risultati training della schermata Train. Oltre a fornire risultati di training, vengono creati tre file code-behind all'interno del file SentimentAnalysis.mbconfig.
-
SentimentAnalysis.consumption.cs: questo file contiene gli schemi
ModelInputeModelOutputnonché la funzionePredictgenerata per l'utilizzo del modello. - SentimentAnalysis.training.cs: questo file contiene la pipeline di addestramento (trasformazioni di dati, trainer, iperparametri del trainer) scelta da Model Builder per addestrare il modello. È possibile usare questa pipeline per riaddestrare il modello.
- * SentimentAnalysis.zip: file ZIP serializzato che rappresenta il modello di ML.NET sottoposto a training.
-
SentimentAnalysis.consumption.cs: questo file contiene gli schemi
Selezionare il pulsante Passaggio successivo per passare al passaggio successivo.
Valutare il modello
Il risultato del passaggio di training sarà un modello con prestazioni ottimali. Nel passaggio di valutazione dello strumento Generatore modelli la sezione di output conterrà il formatore usato dal modello con prestazioni migliori nelle metriche di valutazione.
Se non si è soddisfatti delle metriche di valutazione, alcuni modi semplici per provare a migliorare le prestazioni del modello sono l'uso di più dati.
In caso contrario, selezionare il pulsante passaggio successivo per passare al passaggio Utilizzo in Generatore modelli.
Aggiungere modelli per progetti di consumo (opzionale)
Nel passaggio Consumo , Model Builder fornisce modelli di progetti che è possibile impiegare per utilizzare il modello. Questo passaggio è facoltativo ed è possibile scegliere il metodo più adatto alle proprie esigenze per l'uso del modello.
- Applicazione console
- Web API
Aggiungere il codice per eseguire stime
Configurare il pool PredictionEngine
Per fare una singola previsione, devi creare un PredictionEngine<TSrc,TDst>.
PredictionEngine<TSrc,TDst> non è sicuro per l'uso con i thread. È anche necessario creare un'istanza di tale istanza ovunque sia necessaria all'interno dell'applicazione. Man mano che l'applicazione cresce, questo processo può diventare non gestibile. Per migliorare le prestazioni e la thread safety, usare una combinazione di inserimento delle dipendenze e del servizio PredictionEnginePool, che crea un ObjectPool<T> di oggetti PredictionEngine<TSrc,TDst> da usare in tutta l'applicazione.
Installa il pacchetto NuGet Microsoft.Extensions.ML.
- In Esplora soluzioni fare clic con il pulsante destro del mouse sul progetto e selezionare Gestisci pacchetti NuGet.
- Scegliere "nuget.org" come origine del pacchetto.
- Selezionare la scheda Sfoglia e cercare Microsoft.Extensions.ML.
- Selezionare il pacchetto nell'elenco e selezionare Installa.
- Selezionare il pulsante OK nella finestra di dialogo Anteprima modifiche
- Selezionare il pulsante Accetto nella finestra di dialogo Accettazione della Licenza se si accettano le condizioni di licenza per i pacchetti elencati.
Aprire il file Program.cs nel progetto di SentimentRazor.
Aggiungere le seguenti direttive
usingper fare riferimento al pacchetto NuGet Microsoft.Extensions.ML e al progetto SentimentRazorML.Model:using Microsoft.Extensions.ML; using static SentimentRazor.SentimentAnalysis;Configura il PredictionEnginePool<TData,TPrediction> per l'applicazione nel file Program.cs:
builder.Services.AddPredictionEnginePool<ModelInput, ModelOutput>() .FromFile("SentimentAnalysis.zip");
Creare un gestore di analisi del sentiment
Le stime verranno eseguite all'interno della pagina principale dell'applicazione. Pertanto, è necessario aggiungere un metodo che accetta l'input dell'utente e usa il PredictionEnginePool<TData,TPrediction> per restituire una stima.
Aprire il file Index.cshtml.cs che si trova nella directory Pagine e aggiungere le seguenti direttive
using.using Microsoft.Extensions.ML; using static SentimentRazor.SentimentAnalysis;Per usare il PredictionEnginePool<TData,TPrediction> configurato nel file Program.cs, è necessario inserirlo nel costruttore del modello in cui si vuole usarlo.
Aggiungere una variabile per fare riferimento al PredictionEnginePool<TData,TPrediction> all'interno della classe
IndexModelall'interno del file Pages/Index.cshtml.cs.private readonly PredictionEnginePool<ModelInput, ModelOutput> _predictionEnginePool;Modificare il costruttore nella classe
IndexModele iniettare il servizio PredictionEnginePool<TData,TPrediction> al suo interno.public IndexModel(ILogger<IndexModel> logger, PredictionEnginePool<ModelInput, ModelOutput> predictionEnginePool) { _logger = logger; _predictionEnginePool = predictionEnginePool; }Creare un gestore di metodi che usa il
PredictionEnginePoolper eseguire stime dall'input dell'utente ricevuto dalla pagina Web.Sotto il metodo
OnGetcreare un nuovo metodo denominatoOnGetAnalyzeSentimentpublic IActionResult OnGetAnalyzeSentiment([FromQuery] string text) { }All'interno del metodo
OnGetAnalyzeSentiment, restituisci sentiment neutrale se l'input dell'utente è vuoto o nullo.if (String.IsNullOrEmpty(text)) return Content("Neutral");Dato un input valido, creare una nuova istanza di
ModelInput.var input = new ModelInput { SentimentText = text };Usare il PredictionEnginePool<TData,TPrediction> per prevedere il sentiment.
var prediction = _predictionEnginePool.Predict(input);Converti il valore previsto
boolin tossico o non tossico usando il codice seguente.var sentiment = Convert.ToBoolean(prediction.PredictedLabel) ? "Toxic" : "Not Toxic";Infine, restituisci il sentimento alla pagina Web.
return Content(sentiment);
Configurare la pagina Web
I risultati restituiti dal OnGetAnalyzeSentiment verranno visualizzati dinamicamente nella pagina Web Index.
Aprire il file Index.cshtml nella directory Pages e sostituirne il contenuto con il codice seguente:
@page @model IndexModel @{ ViewData["Title"] = "Home page"; } <div class="text-center"> <h2>Live Sentiment</h2> <p><textarea id="Message" cols="45" placeholder="Type any text like a short review"></textarea></p> <div class="sentiment"> <h4>Your sentiment is...</h4> <p>😡 😐 😍</p> <div class="marker"> <div id="markerPosition" style="left: 45%;"> <div>▲</div> <label id="markerValue">Neutral</label> </div> </div> </div> </div>Successivamente, aggiungere codice di stile CSS alla fine della pagina site.css nella directory wwwroot\css.
/* Style for sentiment display */ .sentiment { background-color: #eee; position: relative; display: inline-block; padding: 1rem; padding-bottom: 0; border-radius: 1rem; } .sentiment h4 { font-size: 16px; text-align: center; margin: 0; padding: 0; } .sentiment p { font-size: 50px; } .sentiment .marker { position: relative; left: 22px; width: calc(100% - 68px); } .sentiment .marker > div { transition: 0.3s ease-in-out; position: absolute; margin-left: -30px; text-align: center; } .sentiment .marker > div > div { font-size: 50px; line-height: 20px; color: green; } .sentiment .marker > div label { font-size: 30px; color: gray; }Successivamente, aggiungere il codice per inviare input dalla pagina Web al gestore
OnGetAnalyzeSentiment.Nel file site.js che si trova nella directory wwwroot\js creare una funzione denominata
getSentimentper effettuare una richiesta HTTP GET con l'input dell'utente al gestoreOnGetAnalyzeSentiment.function getSentiment(userInput) { return fetch(`Index?handler=AnalyzeSentiment&text=${userInput}`) .then((response) => { return response.text(); }) }Di seguito, aggiungere un'altra funzione denominata
updateMarkerper aggiornare dinamicamente la posizione del marcatore nella pagina Web in base alla previsione del sentiment.function updateMarker(markerPosition, sentiment) { $("#markerPosition").attr("style", `left:${markerPosition}%`); $("#markerValue").text(sentiment); }Creare una funzione del gestore eventi denominata
updateSentimentper ottenere l'input dall'utente, inviarla alla funzioneOnGetAnalyzeSentimentusando la funzionegetSentimente aggiornare l'indicatore con la funzioneupdateMarker.function updateSentiment() { var userInput = $("#Message").val(); getSentiment(userInput) .then((sentiment) => { switch (sentiment) { case "Not Toxic": updateMarker(100.0, sentiment); break; case "Toxic": updateMarker(0.0, sentiment); break; default: updateMarker(45.0, "Neutral"); } }); }Infine, registrare il gestore eventi e associarlo all'elemento
textareacon l'attributoid=Message.$("#Message").on('change input paste', updateSentiment)
Eseguire l'applicazione
Ora che l'applicazione è configurata, eseguire l'applicazione, che dovrebbe essere avviata nel browser.
Quando l'applicazione viene avviata, immettere Questo modello non dispone di dati sufficienti. nell'area di testo. Il sentiment stimato visualizzato deve essere tossico.
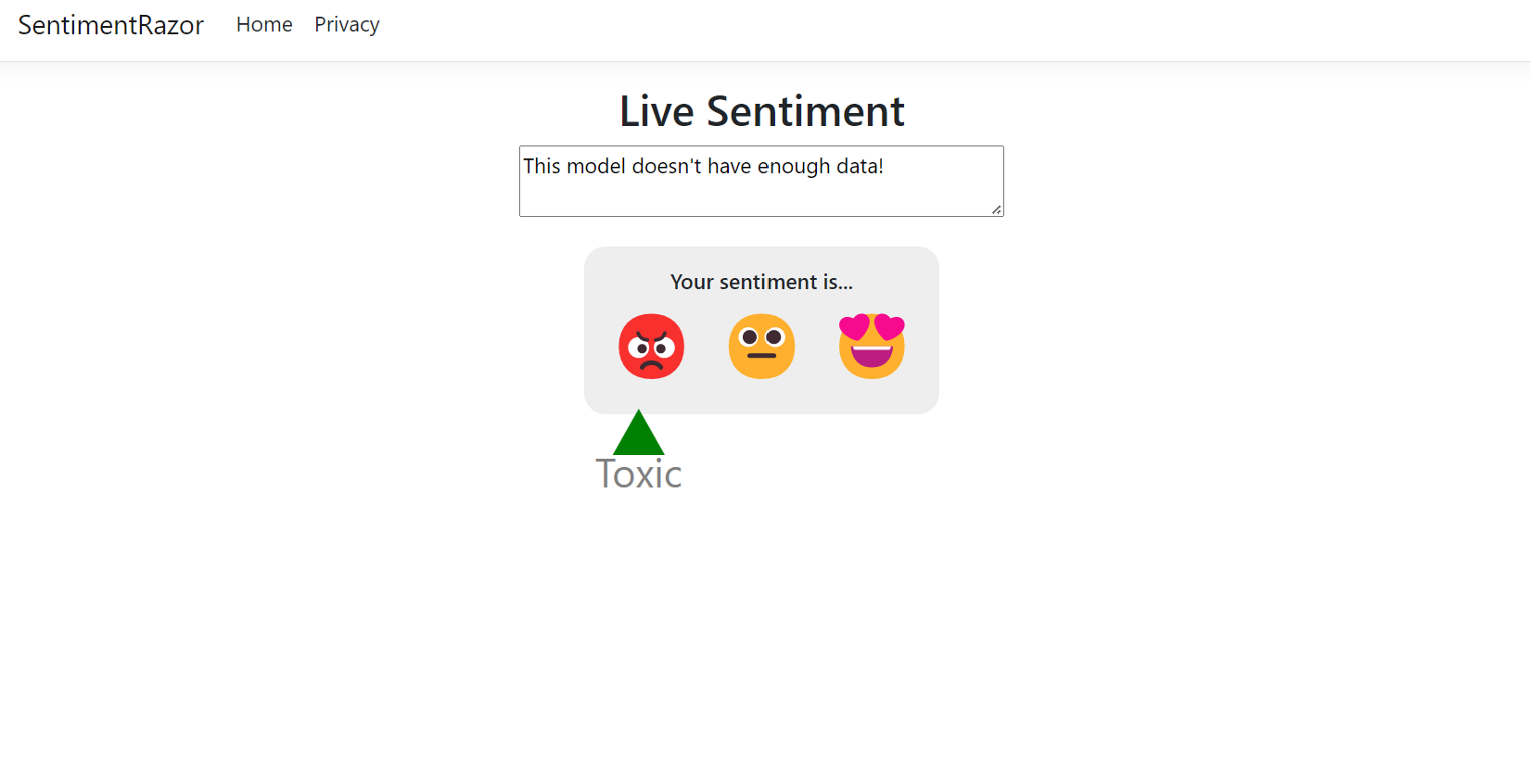
Nota
PredictionEnginePool<TData,TPrediction> crea più istanze di PredictionEngine<TSrc,TDst>. A causa delle dimensioni del modello, la prima volta che viene usata per eseguire una stima, possono essere necessari alcuni secondi. Le stime successive devono essere istantanee.
Passaggi successivi
In questa esercitazione si è appreso come:
- Creare un'applicazione ASP.NET Core Razor Pages
- Preparare e comprendere i dati
- Scegliere uno scenario
- Carica i dati
- Addestrare il modello
- Valutare il modello
- Usare il modello per le stime
Risorse aggiuntive
Per altre informazioni sugli argomenti menzionati in questa esercitazione, visitare le risorse seguenti: