Procedure consigliate per l'unificazione dei dati
Quando imposti delle regole per unificare i tuoi dati in un profilo cliente, tieni in considerazione queste best practice:
Trova il tempo necessario per unificare e completare l'abbinamento. Cercare di catturare ogni possibile corrispondenza porta a molte regole e l'unificazione richiede molto tempo.
Aggiungi regole progressivamente e monitora i risultati. Rimuovi le regole che non migliorano il risultato della partita.
Deduplicare ogni tabella in modo che ogni cliente sia rappresentato in una singola riga.
Utilizzare la normalizzazione per standardizzare le variazioni nel modo in cui sono stati inseriti i dati, ad esempio Via vs. St vs. St. vs. st.
Utilizza la corrispondenza fuzzy strategicamente per correggere errori di battitura e refusi come bob@contoso.com e bob@contoso.cm. Le corrispondenze fuzzy richiedono più tempo per essere eseguite rispetto alle corrispondenze esatte. Verificare sempre se il tempo extra dedicato al fuzzy matching vale la pena di aumentare il tasso di corrispondenza.
Restringi l'ambito delle corrispondenze con corrispondenza esatta. Assicurarsi che ogni regola con condizioni fuzzy abbia almeno una condizione di corrispondenza esatta.
Non abbinare colonne che contengono dati ripetuti in modo frequente. Assicuratevi che le colonne con corrispondenze parziali non abbiano valori ripetuti frequentemente, come il valore predefinito di un modulo "Nome".
Prestazioni di unificazione
Ogni regola richiede tempo per essere applicata. Modelli quali il confronto di ogni tabella con tutte le altre tabelle o il tentativo di catturare ogni possibile corrispondenza di record possono comportare lunghi tempi di elaborazione dell'unificazione. Restituisce inoltre poche, se non addirittura nessuna, corrispondenze in un piano che confronta ogni tabella con una tabella di base.
L'approccio migliore è iniziare con un set di regole di base che sai essere necessario, come il confronto di ogni tabella con la tabella principale. La tabella primaria dovrebbe essere quella con i dati più completi e accurati. Questa tabella dovrebbe essere ordinata in alto nell'unificazione delle regole di corrispondenza passaggio.
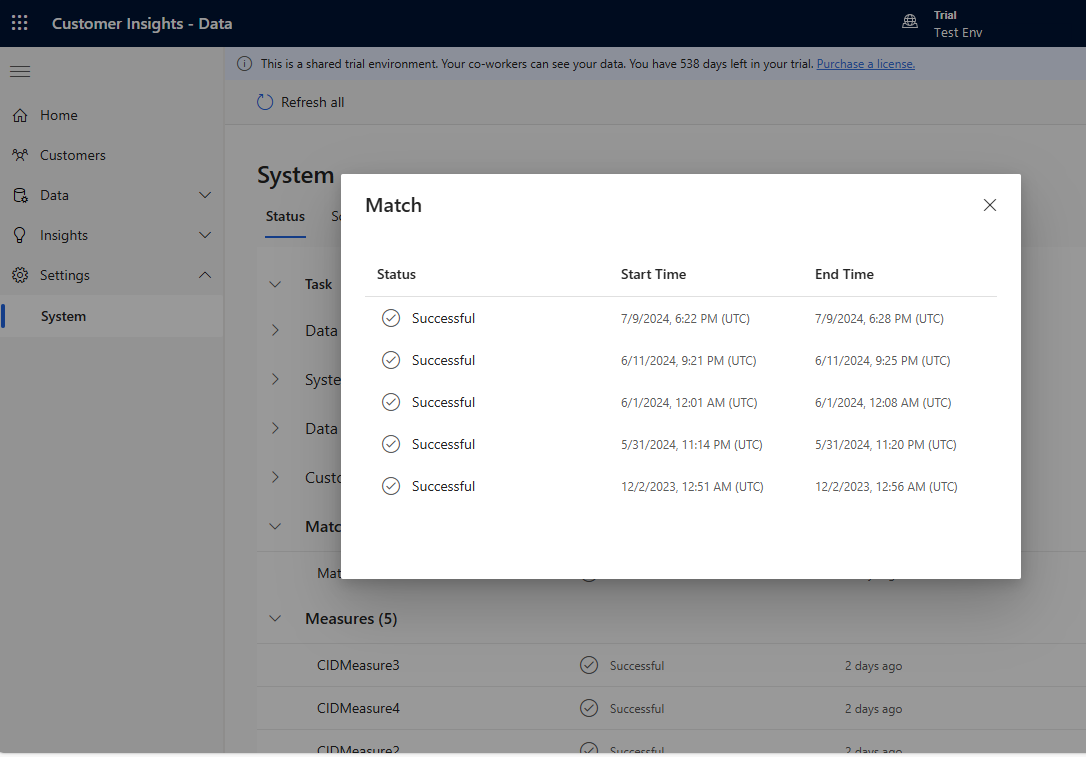
Aggiungi progressivamente diverse regole e osserva quanto tempo impiegano le modifiche per essere applicate e se i risultati migliorano. Vai su Impostazioni>Sistema>Stato e Seleziona Corrispondenza per vedere quanto tempo è stato impiegato per la deduplicazione e la corrispondenza per ogni esecuzione di unificazione.
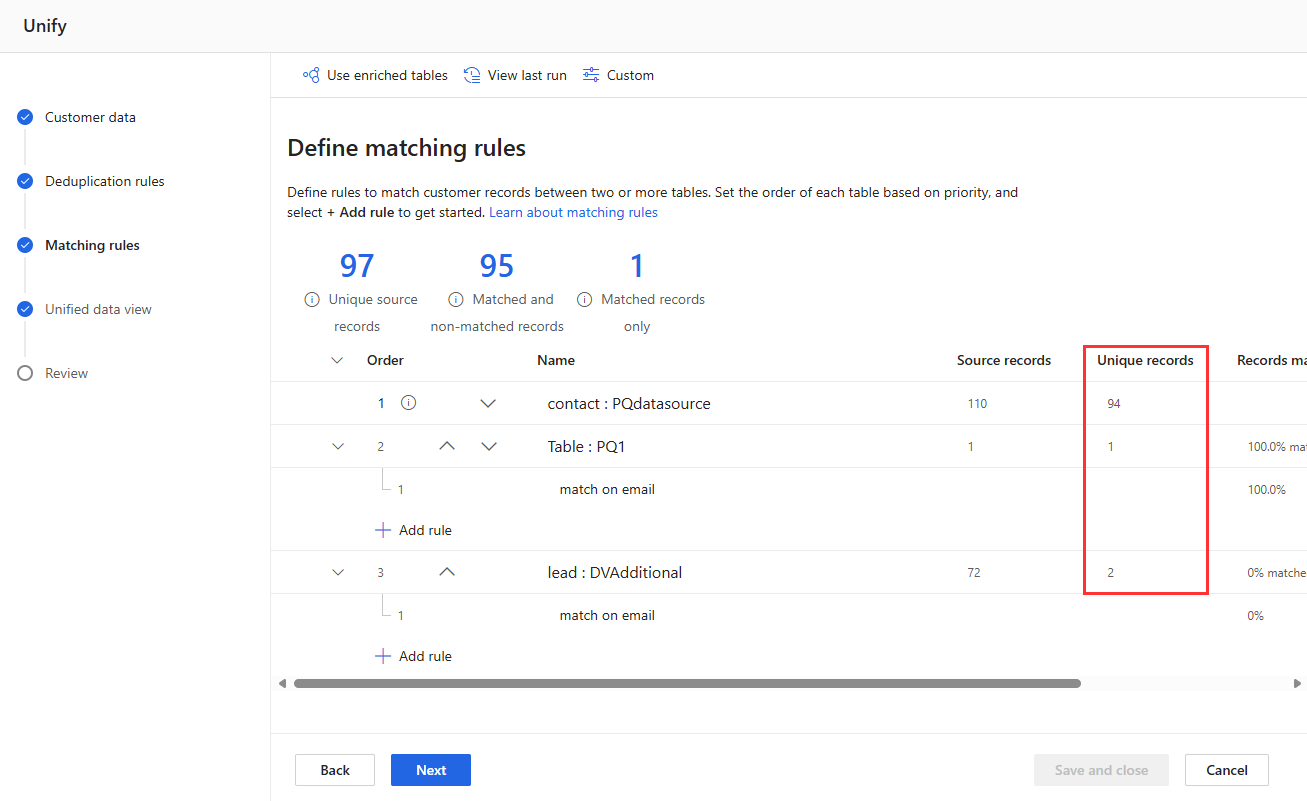
Visualizza le statistiche delle regole nelle pagine Regole di deduplicazione e Regole di corrispondenza per vedere se il numero di Record univoci cambia. Se una nuova regola corrisponde ad alcuni record e il conteggio univoco dei record non cambia, una regola precedente identifica tali corrispondenze.
Deduplicazione
Utilizzare regole di deduplicazione per rimuovere i record dei clienti duplicati all'interno di una tabella, in modo che una singola riga in ogni tabella rappresenti ciascun cliente. Una buona regola identifica un cliente unico.
In questo semplice esempio, i record 1, 2 e 3 Condividi sono un indirizzo email o un numero di telefono e rappresentano la stessa persona.
| ID | Name | il numero | Indirizzo e-mail |
|---|---|---|---|
| 1 | Persona 1 | (425) 555-1111 | AAA@A.com |
| 2 | Persona 1 | (425) 555-1111 | BBB@B.com |
| 3 | Persona 1 | (425) 555-2222 | BBB@B.com |
| 4 | Persona 2 | (206) 555-9999 | Person2@contoso.com |
Non dobbiamo abbinare solo il nome perché così facendo si abbinerebbero persone diverse con lo stesso nome.
Crea la regola 1 utilizzando Nome e Telefono, che corrisponde ai record 1 e 2.
Crea la regola 2 utilizzando Nome ed Email, che corrisponde ai record 2 e 3.
La combinazione della Regola 1 e della Regola 2 crea un singolo gruppo di corrispondenza perché condividono il record 2.
Puoi decidere il numero di regole e condizioni che identificano in modo univoco i tuoi clienti. Le regole esatte dipendono dai dati disponibili da abbinare, dalla qualità dei dati e da quanto esaustivo si desidera che sia il processo di deduplicazione.
Record vincenti e alternativi
Una volta eseguite le regole e identificati i record duplicati, il processo di deduplicazione seleziona una "riga vincente". Le righe non vincenti sono chiamate "righe alternative". Le righe alternative vengono utilizzate nell'unificazione delle regole di corrispondenza passaggio per abbinare i record di altre tabelle alla riga vincente. Le righe vengono abbinate ai dati nelle righe alternative oltre alla riga vincente.
Dopo aver aggiunto una regola a una tabella, puoi configurare quale riga impostare come Seleziona come riga vincente tramite le Preferenze di unione. Le preferenze di unione vengono impostate per tabella. Indipendentemente dal criterio di unione selezionato, in caso di parità per una riga vincente, la prima riga nell'ordine dei dati viene utilizzata come criterio di spareggio.
Normalizzazione
Utilizzare la normalizzazione per standardizzare i dati e ottenere una corrispondenza migliore. La normalizzazione funziona bene su grandi insiemi di dati.
I dati normalizzati vengono utilizzati solo a scopo di confronto per abbinare i record del cliente in modo più efficace. Non modifica i dati nell'output finale del profilo cliente unificato.
| Normalizzazione | Esempi |
|---|---|
| Numeri | Converte molti simboli Unicode che rappresentano numeri in numeri semplici. Esempi: ❽ e Ⅷ sono entrambi normalizzati al numero 8. Nota: i simboli devono essere codificati in formato punto Unicode. |
| Simboli | Rimuove simboli e caratteri speciali. Esempi: !?"#$%&'( )+,.-/:;<=>@^~{}`[ ] |
| Testo in minuscolo | Converte i caratteri maiuscoli in minuscoli. Esempio: "THIS Is aN EXamplE" viene convertito in "this is an example" |
| Tipo - Telefono | Converte i telefoni in vari formati in cifre e tiene conto delle variazioni nel modo in cui vengono presentati i codici paese e le estensioni. Esempio: +01 425.555.1212 = 1 (425) 555-1212 |
| Tipo - Nome | Converte oltre 500 varianti e titoli di nomi comuni. Esempi: "debby" -> "deborah" "prof" e "professore" -> "Prof." |
| Tipo - Indirizzo | Converte le parti comuni degli indirizzi Esempi: "strada" -> "st" e "nordovest" -> "no" |
| Tipo - Organizzazione | Rimuove circa 50 "parole inutili" nei nomi delle aziende, come "co", "corp", "corporation" e "ltd". |
| Unicode in ASCII | Unicode in ASCII: converte i caratteri Unicode nella lettera equivalente ASCII Esempio: i caratteri "à,' 'á,' 'â,' 'À,' 'Á,' 'Â,' 'Ã,' 'Ä,' 'Ⓐ," e "A" vengono tutti convertiti in "a." |
| Spazio vuoto | Rimuove tutti gli spazi vuoti |
| Mapping alias | Consente di caricare un elenco personalizzato di coppie di stringhe che può quindi essere utilizzato per indicare stringhe che devono sempre essere considerate una corrispondenza esatta. Utilizza il mapping degli alias quando disponi di esempi di dati specifici che ritieni debbano corrispondere e che non corrispondono, utilizzando uno degli altri modelli di normalizzazione. Esempio: Scott e Scooter, oppure MSFT e Microsoft. |
| Ignora personalizzato | Consente di caricare un elenco personalizzato di stringhe che può quindi essere utilizzato per indicare che non devono mai essere abbinate. Il bypass personalizzato è utile quando si hanno dati con valori comuni che dovrebbero essere ignorati, come un numero di telefono fittizio o un indirizzo email fittizio. Esempio: non abbinare mai il telefono 555-1212, o test@contoso.com |
Corrispondenza esatta
Utilizzare la precisione per determinare quanto Chiudi due stringhe devono essere considerate corrispondenti. L'impostazione di precisione predefinita richiede una corrispondenza esatta. Qualsiasi altro valore consente la corrispondenza fuzzy per quella condizione.
La precisione può essere impostata su bassa (corrispondenza del 30%), media (corrispondenza del 60%) e alta (corrispondenza dell'80%). Oppure puoi personalizzare e impostare la precisione con incrementi dell'1%.
Condizioni di corrispondenza esatta
Le condizioni di corrispondenza esatta vengono eseguite prima per ottenere un set di valori Più piccolo per le corrispondenze fuzzy. Per essere efficaci, le condizioni di corrispondenza esatta dovrebbero avere un ragionevole grado di unicità. Ad esempio, se tutti i tuoi clienti vivono nello stesso Paese/regione, avere una corrispondenza esatta per quel Paese/regione non aiuterebbe a restringere l'ambito.
Colonne come i campi nome completo, e-mail, telefono o indirizzo hanno un buon livello di univocità e sono ottime colonne da utilizzare come corrispondenza esatta.
Assicurati che la colonna utilizzata per una condizione di corrispondenza esatta non contenga valori ripetuti frequentemente, come il valore predefinito "Nome" acquisito da un modulo. Le informazioni sui clienti possono profilare le colonne di dati per fornire informazioni sui principali valori ricorrenti. È possibile abilitare la profilazione dei dati sulle connessioni di Azure Data Lake (utilizzando il formato Common Data Model o Delta) e Synapse. Il profilo dati viene eseguito al successivo aggiornamento di origine dati. Per maggiori informazioni, vai a Profilazione dei dati.
Corrispondenza fuzzy
Utilizza la corrispondenza fuzzy per trovare le stringhe che sono Chiudi ma che non sono esatte a causa di errori di battitura o altre piccole variazioni. Utilizza il fuzzy matching in modo strategico, poiché è più lento del matching esatto. Assicurarsi che ci sia almeno una condizione di corrispondenza esatta in ogni regola che abbia condizioni fuzzy.
Il fuzzy matching non è pensato per catturare varianti di nomi come Suzzie e Suzanne. Queste varianti vengono catturate meglio con il modello di normalizzazione Tipo: Nome o con il personalizzato corrispondenza Alias in cui i clienti possono inserire l'elenco delle varianti di nome che desiderano considerare come corrispondenze.
Puoi aggiungere condizioni a una regola, ad esempio la corrispondenza di Nome e Telefono. Le condizioni all'interno di una determinata regola sono condizioni "AND". Affinché le righe corrispondano, ogni condizione deve corrispondere. Le regole separate sono le condizioni "OR". Se la Regola 1 non corrisponde alle righe, le righe vengono confrontate con la Regola 2.
Nota
Solo le colonne con tipo di dati stringa possono utilizzare la corrispondenza fuzzy. Per le colonne con altri tipi di dati, come integer, double o datetime, il campo precision è di sola lettura e impostato sulla corrispondenza esatta.
Calcoli di corrispondenza fuzzy
Le corrispondenze fuzzy vengono determinate calcolando il punteggio della distanza di modifica tra due stringhe. Se il punteggio raggiunge o supera la soglia di precisione, le stringhe vengono considerate corrispondenti.
La distanza di modifica è il numero di modifiche necessarie per trasformare una stringa in un'altra, aggiungendo, eliminando o cambiando un carattere.
Ad esempio, le stringhe "Jacqueline" e "Jaclyne" hanno una distanza di modifica pari a cinque quando rimuoviamo i caratteri q, u, e, i ed e e inseriamo il carattere y.
Per calcolare il punteggio della distanza di modifica, utilizzare questa formula: (Lunghezza base della stringa – Distanza di modifica) / Lunghezza base della stringa.
| Stringa base | Stringa di confronto | Punteggio |
|---|---|---|
| Jacqueline | Jaclyne | (10-4)/10=,6 |
| fred@contoso.com | fred@contso.cm | (14-2)/14 = 0,857 |
| franklin | frank | (8-3) / 8 = 0,625 |