Architettura preferita di Exchange 2019
Con ogni nuova versione di Exchange Server per i clienti locali, aggiorniamo l'architettura preferita e parliamo delle modifiche di cui vorremmo che i clienti si rendessero conto. Exchange Server 2013 ci ha portato la prima delle architetture preferite nella cronologia di Exchange moderna e poi è stato seguito con un aggiornamento per Exchange Server 2016 fornendo miglioramenti per le modifiche apportate con la versione 2016. Con questo aggiornamento per Exchange Server 2019, si eseguirà un'iterazione sulla pa precedente per sfruttare le nuove tecnologie e i miglioramenti.
L'architettura preferita
La PA è la raccomandazione Exchange Server Engineering Team per le procedure consigliate per l'architettura di distribuzione migliore per Exchange Server 2019 in un ambiente locale.The PA is the Exchange Server Engineering Team's best practice recommendation for what we believe is the best deployment architecture for Exchange Server 2019 in an on-premises environment.
Anche se Exchange 2019 offre un'ampia gamma di scelte architettoniche per le distribuzioni locali, l'architettura illustrata di seguito è la più esaminata. Anche se esistono altre architetture di distribuzione supportate, non sono la procedura consigliata.
Seguendo la PA, i clienti diventano membri di una community di organizzazioni con distribuzioni di Exchange Server simili. Questa strategia consente una condivisione delle conoscenze più semplice e fornisce una risposta più rapida a circostanze impreviste. La nostra organizzazione di supporto è consapevole dell'aspetto di una distribuzione pa Exchange Server e impedisce loro di spendere lunghi cicli di apprendimento e comprensione dell'ambiente altamente personalizzato di un cliente prima di collaborare con loro per una risoluzione dei casi di supporto.
La pa è progettata tenendo presente diversi requisiti aziendali, ad esempio il requisito che l'architettura sia in grado di:
Includere sia la disponibilità elevata all'interno del data center che la resilienza del sito tra i data center
Supportare più copie di ogni database, consentendo l'attivazione rapida
Ridurre il costo dell'infrastruttura di messaggistica
Aumentare la disponibilità ottimizzando i domini di errore e riducendo la complessità
La natura prescrittiva specifica della PA significa che non tutti i clienti saranno in grado di distribuirla parola per parola. Ad esempio, non tutti i clienti hanno più data center. Alcuni clienti possono avere requisiti aziendali o criteri interni diversi a cui devono attenersi, il che richiede un'architettura di distribuzione diversa. Se si rientra in queste categorie e si vuole distribuire Exchange in locale, esistono comunque vantaggi per l'adesione il più possibile alla PA e deviare solo quando i requisiti o i criteri impongono differenze. In alternativa, è sempre possibile considerare Microsoft 365 o Office 365 in cui non è più necessario distribuire o gestire un numero elevato di server.
La pa rimuove la complessità e la ridondanza laddove necessario per indirizzare l'architettura a un modello di ripristino prevedibile: quando si verifica un errore, viene attivata un'altra copia del database interessato.
L'AP copre le quattro aree di interesse seguenti:
Per Exchange Server 2019, non sono state apportate modifiche in tre delle quattro categorie dell'architettura preferita Exchange Server 2016. Le aree della progettazione dello spazio dei nomi, della progettazione del data center e della progettazione del gruppo di disponibilità del database non ricevono modifiche importanti. Siamo stati soddisfatti delle distribuzioni dei clienti che hanno seguito da vicino la PA Exchange Server 2016 e non vediamo la necessità di discostarsi dalle raccomandazioni in tali aree.
I cambiamenti più importanti nel Exchange Server 2019 PA si concentrano sull'area del design del server grazie ad alcune nuove ed entusiasmanti tecnologie.
Progettazione dello spazio dei nomi
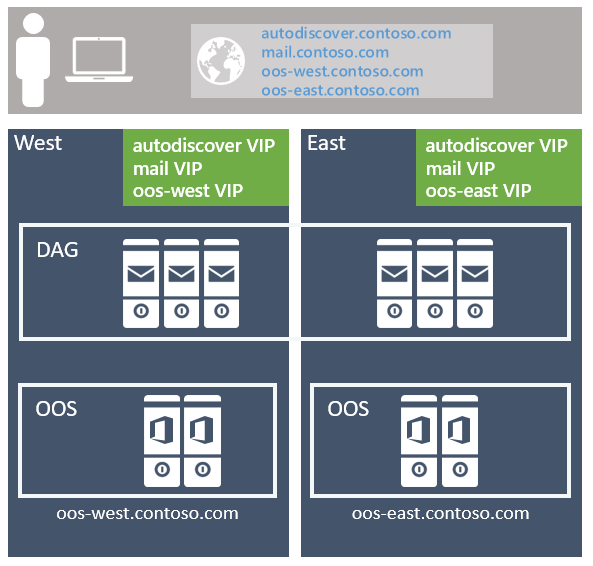
Negli articoli Namespace Planning and Load Balancing Principles (Pianificazione dello spazio dei nomi e principi di bilanciamento del carico per Exchange Server 2016), Ross Smith IV ha descritto le varie opzioni di configurazione disponibili con Exchange 2016 e questi concetti continuano ad essere validi per Exchange Server 2019. Per lo spazio dei nomi, è possibile distribuire uno spazio dei nomi associato (con una preferenza per gli utenti per operare fuori da un data center specifico) o uno spazio dei nomi non associato (in modo che gli utenti si connettono a qualsiasi data center senza preferenze).
L'approccio consigliato consiste nell'usare il modello non associato, distribuendo un singolo spazio dei nomi di Exchange per protocollo client per la coppia di data center resilienti al sito (in cui si presuppone che ogni data center rappresenti il proprio sito di Active Directory, vedere altri dettagli su questo punto di seguito). Ad esempio:
Per il servizio di individuazione automatica: autodiscover.contoso.com
Per i client HTTP: mail.contoso.com
Per i client IMAP: imap.contoso.com
Per i client SMTP: smtp.contoso.com
Ogni spazio dei nomi di Exchange viene sottoposto a bilanciamento del carico tra entrambi i data center in una configurazione di livello 7 che non usa l'affinità di sessione, con il risultato che il 50% del traffico viene sottoposto a proxy tra i data center. Il traffico è ugualmente distribuito tra i data center nella coppia resiliente al sito, tramite DNS round robin, DNS geografico o altre soluzioni simili. Dal nostro punto di vista, la soluzione più semplice è la meno complessa e più facile da gestire, quindi è consigliabile usare DNS round robin.
Per i clienti è importante assicurarsi di assegnare un valore TTL (time to live) basso per qualsiasi record DNS associato all'architettura di Exchange. Se si verifica un'interruzione completa del data center quando si usa dns round robin, è necessario mantenere la possibilità di aggiornare rapidamente i record DNS. È necessario rimuovere gli indirizzi IP dal data center offline in modo che non vengano restituiti per le query DNS. Ad esempio, se i record DNS hanno un valore TTL più lungo di 24 ore, l'aggiornamento corretto delle cache DNS downstream potrebbe richiedere fino a un giorno. Se non si esegue questo passaggio, è possibile che alcuni client non siano in grado di eseguire correttamente la transizione agli indirizzi IP ancora disponibili nel data center rimanente. Non dimenticare di aggiungere nuovamente gli indirizzi IP ai record DNS quando il data center offline precedente viene ripristinato e pronto per ospitare nuovamente i servizi.
L'affinità del data center è necessaria per le farm Office Online Server, quindi viene distribuito uno spazio dei nomi per ogni data center con il servizio di bilanciamento del carico che usa il livello 7 e mantenendo l'affinità di sessione tramite la persistenza basata su cookie.
Se nell'ambiente sono presenti più coppie di data center resilienti al sito, è necessario decidere se si vuole disporre di un singolo spazio dei nomi globale o se si vuole controllare il traffico verso ogni data center specifico usando spazi dei nomi a livello di area. La decisione dipende dalla topologia di rete e dal costo associato all'uso di un modello non associato; Ad esempio, se si dispone di data center situati in America del Nord e Sudafrica, il collegamento di rete tra queste aree potrebbe non solo essere costoso, ma potrebbe anche avere una latenza elevata, che può introdurre problemi operativi e di dolore per gli utenti. In tal caso, è opportuno distribuire un modello associato con uno spazio dei nomi separato per ogni area. Tuttavia, opzioni come DNS geografico offrono la possibilità di distribuire un singolo spazio dei nomi unificato, anche quando si dispone di costosi collegamenti di rete; geo-DNS consente di indirizzare gli utenti al data center più vicino in base all'indirizzo IP del client.
Progettazione di coppie di data center resilienti al sito
Per ottenere un'architettura a disponibilità elevata e resiliente al sito, è necessario disporre di due o più data center ben connessi(idealmente, si vuole una bassa latenza di rete round trip, altrimenti la replica e l'esperienza client sono influenzate negativamente). Inoltre, i data center devono essere connessi tramite percorsi di rete ridondanti forniti da gestori operativi diversi.
Anche se è supportante l'estensione di un sito di Active Directory tra più data center, per la PA è consigliabile che ogni data center sia il proprio sito di Active Directory. Esistono due motivi:
La resilienza del sito di trasporto tramite ridondanza Shadow in Exchange Server e Safety Net in Exchange Server può essere ottenuta solo quando il gruppo di disponibilità del database dispone di membri che si trovano in più siti di Active Directory.
Active Directory ha pubblicato indicazioni che specificano che le subnet devono essere posizionate in diversi siti di Active Directory quando la latenza di round trip è maggiore di 10 ms tra le subnet.
Progettazione del server
Nella PA tutti i server sono server fisici e usano l'archiviazione collegata in locale. L'hardware fisico viene distribuito anziché l'hardware virtualizzato per due motivi:
I server vengono ridimensionati in modo da usare l'80% delle risorse durante la modalità di errore peggiore.
La virtualizzazione comporta una leggera riduzione delle prestazioni e l'aggiunta di un ulteriore livello di gestione e complessità, che introduce modalità di ripristino aggiuntive che non aggiungono valore, in particolare perché Exchange Server offre in modo nativo le stesse funzionalità.
Server di materie prime
Le piattaforme server commodity vengono usate nella PA. Le piattaforme di materie prime correnti sono e includono:
2U, server dual socket con un massimo di 48 core del processore fisico (un aumento rispetto ai 24 core in Exchange 2016)
Fino a 256 GB di memoria (un aumento da 192 GB in Exchange 2016)
Un controller della cache di scrittura con batteria
12 o più alloggiamenti di unità all'interno dello chassis del server
La possibilità di combinare l'archiviazione tradizionale del piatto rotante (HDD) e l'archiviazione a stato solido (SSD) all'interno dello stesso chassis.
Teoria della scala
È importante notare che, anche se la capacità di processore e memoria consentita è stata aumentata nel Exchange Server 2019, la raccomandazione Exchange Server PG rimane quella di aumentare le prestazioni anziché aumentare. La scalabilità orizzontale significa che si preferisce distribuire un numero maggiore di server con un numero leggermente inferiore di risorse per server anziché un numero inferiore di server densi usando le risorse massime e popolato con un numero elevato di cassette postali. Individuando un numero ragionevole di cassette postali all'interno di un server, si riduce l'impatto di eventuali interruzioni pianificate o non pianificate e si riduce il rischio di individuare altri colli di bottiglia del sistema.
Un aumento delle risorse di sistema non dovrebbe comportare il presupposto che si noteranno miglioramenti lineari delle prestazioni in Exchange Server 2019 usando le risorse massime consentite durante il confronto con le risorse massime consentite di Exchange 2016. Ogni nuova versione di Exchange include nuovi processi e aggiornamenti che a loro volta rendono difficile confrontare una versione corrente con la versione precedente. Per determinare la progettazione del server, seguire tutte le linee guida per il ridimensionamento fornite da Microsoft.
Archiviazione
Altri alloggiamenti unità possono essere collegati direttamente per server a seconda del numero di cassette postali, delle dimensioni delle cassette postali e della scalabilità delle risorse del server.
Ogni server ospita una singola coppia di dischi RAID1 per il sistema operativo, i file binari di Exchange, i log del protocollo/client e il database di trasporto.
L'archiviazione rimanente è configurata come JBOD (Just a Bunch of Disks). Tenere presente che alcuni controller di archiviazione hardware possono richiedere che ogni disco sia configurato come gruppo RAID0 a disco singolo per l'utilizzo della memorizzazione nella cache di scrittura. Rivolgersi al produttore dell'hardware per verificare la configurazione appropriata per il sistema che garantisce l'uso della cache di scrittura.
Una novità di Exchange Server 2019 PA è la raccomandazione di avere due classi di archiviazione per tutto ciò che non si trova già nella coppia di dischi RAID1 menzionata in precedenza.
Classe di archiviazione tradizionale
Questa classe di archiviazione contiene Exchange Server file di database e Exchange Server file di log delle transazioni. Questi dischi sono dischi SCSI (SAS) collegati serialmente a 7,2 K RPM con capacità elevata. Anche se sono disponibili dischi SATA, si osservano operazioni di I/O migliori e una frequenza di errore annualizzata inferiore usando l'equivalente della firma di accesso condiviso.
Per garantire che la capacità e le operazioni di I/O di ogni disco vengano usate nel modo più efficiente possibile, vengono distribuite fino a quattro copie di database per disco. Il normale layout di copia in fase di esecuzione assicura che non sia presente più di una singola copia del database attiva per disco.
Almeno un disco nel pool di dischi di archiviazione tradizionale è riservato come riserva a caldo. AutoReseed è abilitato e ripristina rapidamente la ridondanza del database dopo un errore del disco attivando la riserva a caldo e avviando i reinvii della copia del database.
Classe di archiviazione con stato solido
Questa classe di archiviazione contiene i nuovi file del database MetaCache (MCDB) di Exchange 2019. Queste unità a stato solido possono presentare fattori di forma diversi, ad esempio, a titolo esemplificabile, le tradizionali unità SAS connesse da 2,5"/3,5" o unità connesse PCIe M.2.
I clienti dovrebbero prevedere di distribuire circa il 5-10% di spazio di archiviazione aggiuntivo come archiviazione a stato solido. Ad esempio, se si prevede che un singolo server contenga 28 TB di file di database delle cassette postali nell'archiviazione tradizionale, è consigliabile usare anche 1,4-2,8 TB di archiviazione con stato solido come risorsa di archiviazione aggiuntiva per lo stesso server.
I dischi tradizionali e a stato solido devono essere distribuiti in un rapporto 3:1, dove possibile. Per ogni tre dischi tradizionali all'interno del server, verrà distribuito un singolo disco a stato solido. Questi dischi a stato solido conterrà gli MCDB per tutti i database all'interno dei tre dischi tradizionali associati. Questa raccomandazione limita il dominio di errore che un errore di unità a stato solido può imporre a un sistema. Quando un SSD ha esito negativo, Exchange 2019 eseguirà il failover di tutte le copie del database usando tale SSD per il database MCDB in un altro nodo dag con risorse MCDB integre per il database interessato. La limitazione del numero di failover del database riduce la possibilità di influire sugli utenti se molti più database condividono un numero minore di unità a stato solido.
Se si verifica un errore di unità con stato solido, il servizio Disponibilità elevata di Exchange tenterà di montare i database interessati in nodi dag diversi in cui esiste ancora un database MCDB integro per ogni database interessato. Se per qualche motivo non esistono MCDB integri per uno dei database interessati, i servizi a disponibilità elevata di Exchange lasceranno in esecuzione la copia del database interessato locale senza i vantaggi in termini di prestazioni del database MCDB.
Ad esempio, se un cliente dovesse distribuire un sistema in grado di contenere 20 unità, potrebbe avere un layout simile al seguente.
2 HDD per il mirroring del sistema operativo, i file binari di Exchange e il database di trasporto
12 HDD per l'archiviazione del database di Exchange
1 HDD come riserva AutoReseed
4 unità SSD per MCDB di Exchange che forniscono tra il 5 e il 10% della capacità di archiviazione cumulativa del database.
Facoltativamente, un cliente può scegliere di aggiungere un SSD di riserva o una seconda unità AutoReseed.
Questa configurazione può essere visualizzata usando il diagramma seguente:
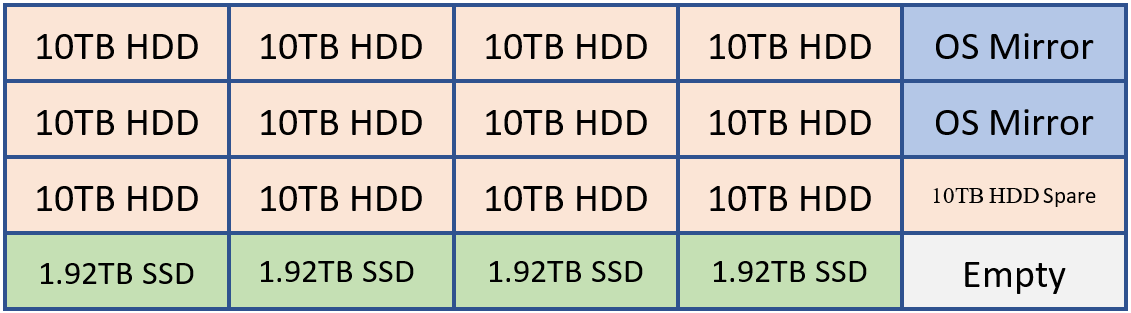
Nell'esempio precedente sono presenti 120 TB di archiviazione del database di Exchange e 7,68 TB di archiviazione MCDB, ovvero circa il 6,4% dello spazio di archiviazione del database tradizionale. Con questa quantità di archiviazione MCBD, siamo perfettamente allineati all'interno delle linee guida del 5-10%. Ognuna delle unità da 10 TB conterrà quattro copie del database e ogni unità MCDB conterrà 12 MCDB.
Impostazioni di archiviazione comuni
Che si tratti di uno stato tradizionale o solido, tutti i dischi che ospitano i dati di Exchange sono formattati con ReFS (con la funzionalità di integrità disabilitata) e il dag è configurato in modo che AutoReseed formatti i dischi con ReFS:
Set-DatabaseAvailabilityGroup -Identity <DAGIdentity> -FileSystem ReFS
BitLocker viene usato per crittografare ogni disco, fornendo in tal modo la crittografia dei dati inattivi e attenuando i problemi relativi al furto di dati o alla sostituzione del disco. Per altre informazioni, vedere Abilitazione di BitLocker nei server Exchange.
Progettazione del gruppo di disponibilità del database
All'interno di ogni coppia di data center resilienti al sito sono disponibili uno o più dag. Non è consigliabile estendere un dag in più di due data center.
Configurazione del gruppo di disponibilità del database
Come per il modello dello spazio dei nomi, ogni dag all'interno della coppia di data center resilienti al sito opera in un modello non associato con copie attive distribuite equamente tra tutti i server del dag. Questo modello:
Garantisce che lo stack completo di servizi di ogni membro del dag (connettività client, pipeline di replica, trasporto e così via) venga convalidato durante le normali operazioni.
Distribuisce il carico tra il maggior numero possibile di server durante uno scenario di errore, aumentando in modo incrementale l'uso delle risorse tra i membri rimanenti all'interno del gruppo di disponibilità del database.
Ogni data center è simmetrico, con un numero uguale di membri dag in ogni data center. Ciò significa che ogni dag ha un numero pari di server e usa un server di controllo per la manutenzione del quorum.
Il gruppo di disponibilità del database è il blocco predefinito fondamentale in Exchange 2019. Per quanto riguarda le dimensioni del dag, un dag con un numero maggiore di nodi membri partecipanti offre più ridondanza e risorse. All'interno della pa, l'obiettivo è distribuire dag con un numero maggiore di nodi membri, in genere a partire da un dag di otto membri e aumentando il numero di server in base alle esigenze. È consigliabile creare nuovi dag solo quando la scalabilità introduce problemi relativi al layout di copia del database esistente.
Progettazione della rete del gruppo di disponibilità del database
La pa usa una singola interfaccia di rete non in team sia per la connettività client che per la replica dei dati. Un'unica interfaccia di rete è necessaria perché in definitiva l'obiettivo è quello di ottenere un modello di recupero standard indipendentemente dall'errore, indipendentemente dal fatto che si verifichi un errore del server o che si verifichi un errore di rete, il risultato è lo stesso: una copia del database viene attivata in un altro server all'interno del gruppo di disponibilità del database. Questa modifica dell'architettura semplifica lo stack di rete e elimina la necessità di eliminare manualmente il cross-talk heartbeat.
Posizionamento del server di controllo di controllo
Il posizionamento del server di controllo del mirroring determina se l'architettura può fornire funzionalità di failover automatico del data center o se richiederà un'attivazione manuale per abilitare il servizio in caso di errore del sito.
Se l'organizzazione ha una terza posizione con un'infrastruttura di rete isolata dagli errori di rete che influiscono sulla coppia di data center resilienti al sito in cui viene distribuito il dag, è consigliabile distribuire il server di controllo del dag in tale terza posizione. Questa configurazione offre al dag la possibilità di eseguire automaticamente il failover dei database nell'altro data center in risposta a un evento di errore a livello di data center, indipendentemente dal data center in cui si verifica l'interruzione.
Se l'organizzazione non ha una terza posizione, provare a posizionare il server di controllo in Azure. in alternativa, posizionare il server di controllo di controllo in uno dei data center all'interno della coppia di data center resilienti al sito. Se sono presenti più dag all'interno della coppia di data center resilienti al sito, posizionare il server di controllo di controllo per tutti i dag nello stesso data center (in genere il data center in cui si trova fisicamente la maggior parte degli utenti). Assicurarsi inoltre che anche Primary Active Manager (PAM) per ogni dag si trovi nello stesso data center.
Exchange Server 2019 e tutte le versioni precedenti non supportano l'uso della funzionalità Cloud Witness introdotta per la prima volta nel cluster di failover Windows Server 2016.
Resilienza dei dati
La resilienza dei dati viene ottenuta distribuendo più copie del database. Nella pa, le copie del database vengono distribuite nella coppia di data center resilienti al sito, assicurando in tal modo che i dati delle cassette postali siano protetti da errori software, hardware e persino del data center.
Ogni database ha quattro copie, con due copie in ogni data center, il che significa che la PA richiede almeno quattro server. Di queste quattro copie, tre di esse sono configurate come a disponibilità elevata. La quarta copia (la copia con il numero di preferenza di attivazione più alto) è configurata come copia di database ritardata. A causa della progettazione del server, ogni copia di un database è isolata dalle altre copie, riducendo così i domini di errore e aumentando la disponibilità complessiva della soluzione, come illustrato in DAG: Beyond the "A".
Lo scopo della copia ritardata del database è fornire un meccanismo di ripristino per il raro evento di danneggiamento logico irreversibile a livello di sistema. Non è destinato al ripristino delle singole cassette postali o al ripristino degli elementi della cassetta postale.
La copia ritardata del database è configurata con replayLagTime di sette giorni. Inoltre, Replay Lag Manager è abilitato anche per fornire il riproduzione dinamica del file di log per le copie ritardate quando la disponibilità è compromessa a causa della perdita di copie non ritardate.
Usando la copia ritardata del database in questo modo, è importante comprendere che la copia ritardata del database non è un backup temporizzato garantito. La copia ritardata del database avrà una soglia di disponibilità, in genere intorno al 90%, a causa dei periodi in cui il disco contenente una copia ritardata viene perso a causa di un errore del disco, la copia ritardata diventa una copia a disponibilità elevata (a causa del play-down automatico) e i periodi in cui la copia ritardata del database ricompila la coda di riproduzione.
Per proteggersi dall'eliminazione accidentale (o dannosa) di elementi, vengono usate tecnologie di recupero o blocco sul posto per un singolo elemento e la finestra Conservazione elementi eliminati è impostata su un valore che soddisfa o supera qualsiasi contratto di servizio di ripristino a livello di elemento definito.
Con tutte queste tecnologie in gioco, i backup tradizionali non sono necessari; di conseguenza, la PA usa Exchange Native Data Protection.
progettazione Office Online Server
Si vuole distribuire almeno una farm di Office Online Server (OOS) con almeno due nodi OOS in ogni data center che ospita i server Exchange 2019. Ogni Office Online Server deve avere almeno 8 core processore, 32 GB di memoria e almeno 40 GB di spazio dedicato per i file di log. I server cassette postali di Exchange 2019 devono essere configurati in modo da basarsi sulla farm OOS locale nel data center per garantire la latenza più bassa possibile e la larghezza di banda massima possibile tra i server per eseguire il rendering del contenuto dei file agli utenti.
Riepilogo
Exchange Server 2019 continua a migliorare gli investimenti introdotti nelle versioni precedenti di Exchange e introduce tecnologie aggiuntive originariamente inventate per l'uso in Microsoft 365 e Office 365.
Allineandosi all'architettura preferita, è possibile sfruttare queste modifiche e offrire la migliore esperienza utente locale possibile. Si continuerà la tradizione di avere una distribuzione di Exchange altamente affidabile, prevedibile e resiliente.