Impostazioni di configurazione del calcolo Spark negli ambienti di Infrastruttura
Microsoft Fabric Ingegneria dei dati e le esperienze di data science operano su una piattaforma di calcolo Spark completamente gestita. Questa piattaforma è progettata per offrire velocità ed efficienza ineguagliabili. Include pool di avvio e pool personalizzati.
Un ambiente Fabric contiene una raccolta di configurazioni, incluse le proprietà di calcolo Spark che consentono agli utenti di configurare la sessione Spark dopo che sono collegati a notebook e processi Spark. Con un ambiente è disponibile un modo flessibile per personalizzare le configurazioni di calcolo per l'esecuzione dei processi Spark. In un ambiente, la sezione calcolo consente di configurare le proprietà a livello di sessione Spark per personalizzare la memoria e i core degli executor in base ai requisiti del carico di lavoro.
Gli amministratori dell'area di lavoro possono abilitare o disabilitare le personalizzazioni di calcolo con l'opzione Personalizza configurazioni di calcolo per gli elementi nella scheda Pool della sezione Ingegneria dei dati/Science nella schermata Impostazioni area di lavoro.
Gli amministratori dell'area di lavoro possono delegare i membri e i collaboratori per modificare le configurazioni di calcolo a livello di sessione predefinite nell'ambiente fabric abilitando questa impostazione.
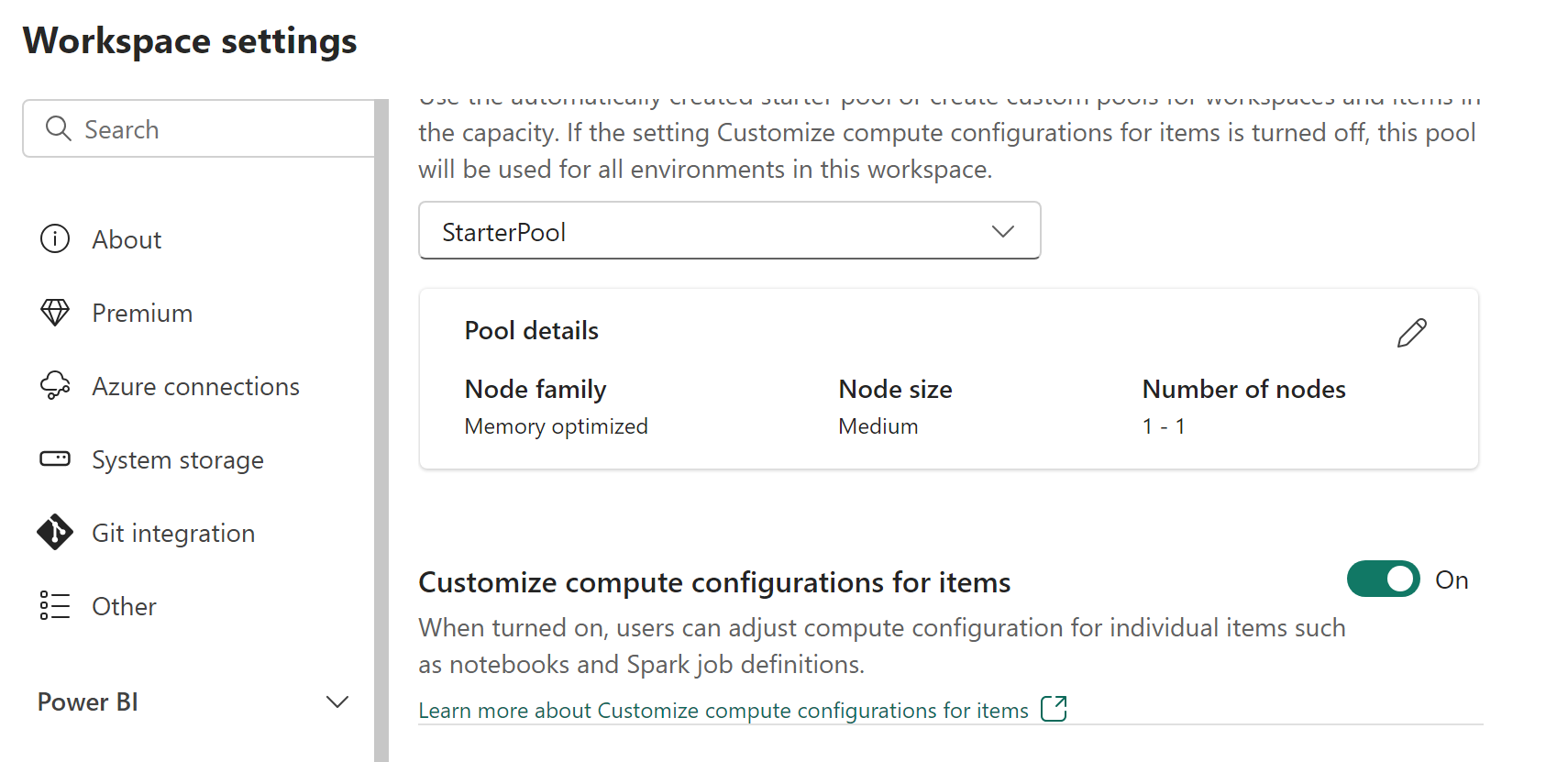
Se l'amministratore dell'area di lavoro disabilita questa opzione nelle impostazioni dell'area di lavoro, la sezione di calcolo dell'ambiente è disabilitata e le configurazioni di calcolo predefinite del pool per l'area di lavoro vengono usate per l'esecuzione di processi Spark.
Personalizzazione delle proprietà di calcolo a livello di sessione in un ambiente
Gli utenti possono selezionare un pool per l'ambiente dall'elenco dei pool disponibili nell'area di lavoro Infrastruttura. L'amministratore dell'area di lavoro infrastruttura crea il pool di avvio predefinito e i pool personalizzati.
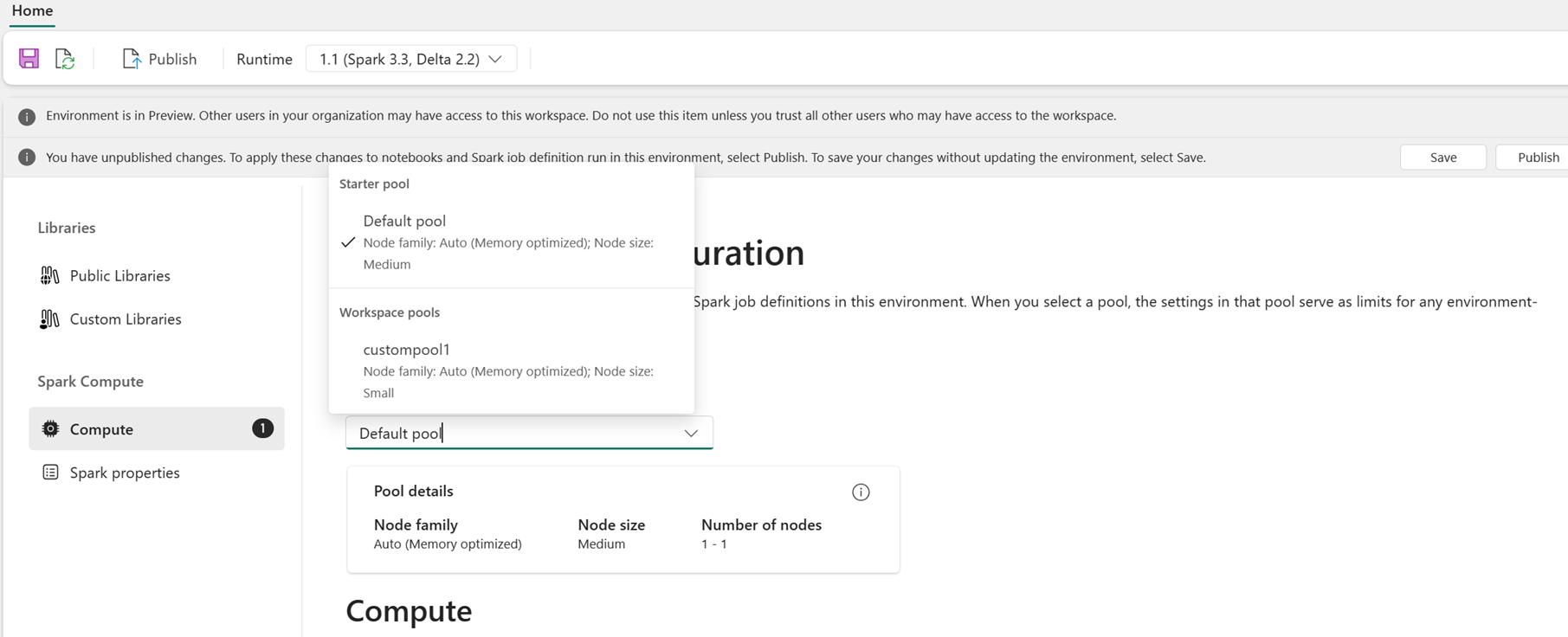
Dopo aver selezionato un pool nella sezione Calcolo , è possibile ottimizzare i core e la memoria per gli executor entro i limiti delle dimensioni e dei limiti del pool selezionato.
Ad esempio: si seleziona un pool personalizzato con dimensioni del nodo di grandi dimensioni, ovvero 16 vCore Spark, come pool di ambienti. È quindi possibile scegliere il core driver/executor in modo che sia 4, 8 o 16, in base ai requisiti a livello di processo. Per la memoria allocata a driver ed executor, è possibile scegliere 28 g, 56 g o 112 g, che sono tutti entro i limiti di un limite di memoria di nodi di grandi dimensioni.
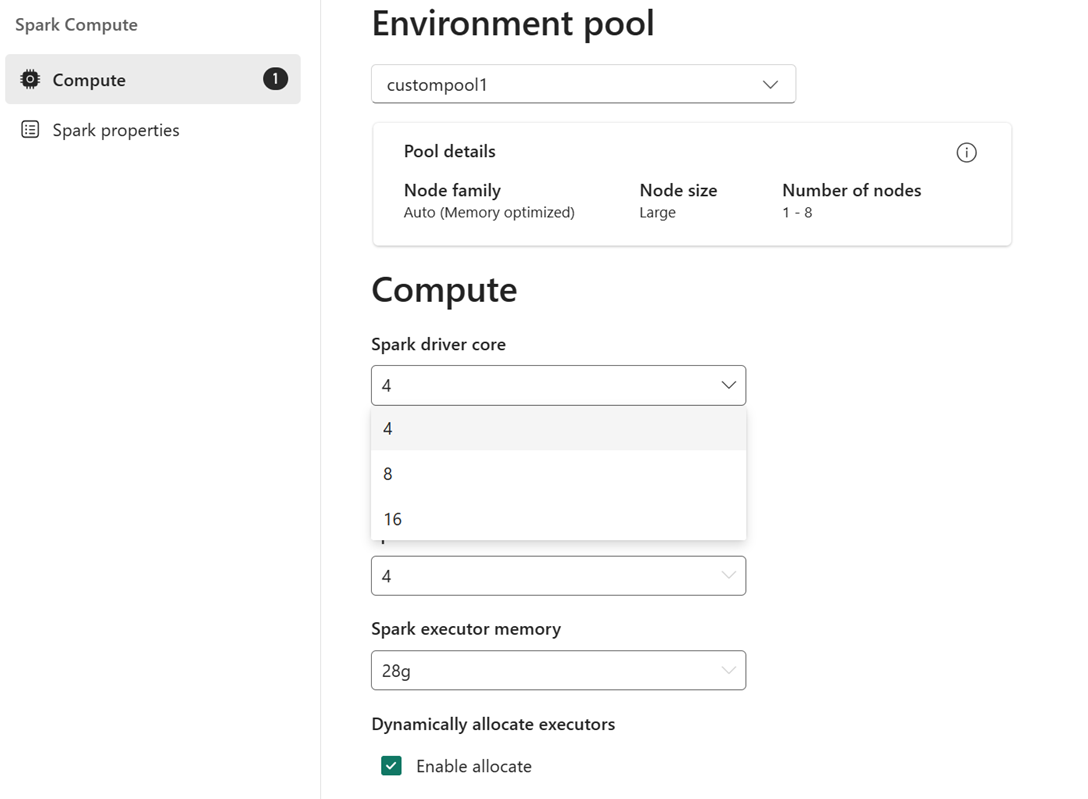
Per altre informazioni sulle dimensioni di calcolo spark e sulle relative opzioni di memoria o core, vedere Informazioni sul calcolo Spark in Microsoft Fabric.