Controllo del codice sorgente con Warehouse (anteprima)
Questo articolo illustra il funzionamento di Integrazione Git e delle pipeline di distribuzione per i magazzini in Microsoft Fabric. Informazioni su come configurare un collegamento al repository, gestire i magazzini e implementarli in ambienti diversi. Il controllo del codice sorgente per il magazzino di Fabric è attualmente una funzionalità di anteprima.
Per scenari diversi, è possibile usare sia l'integrazione Git sia le Pipeline di distribuzione:
- Usare Git e i progetti di database SQL per gestire modifiche incrementali, collaborazione del team e cronologia di commit in singoli oggetti di database.
- Usare le pipeline di distribuzione per promuovere le modifiche al codice in ambienti di pre-produzione e di produzione diversi.
Integrazione con Git
L'integrazione Git in Microsoft Fabric abilita gli sviluppatori a integrare processi di sviluppo, strumenti e procedure consigliate direttamente nella piattaforma Fabric. Consente agli sviluppatori che sviluppano in Fabric di:
- Eseguire il backup e la versione del lavoro
- Ripristinare le fasi precedenti in base alle esigenze
- Collaborare con altri utenti o lavorare da soli usando i rami Git
- Applicare le capacità degli strumenti di controllo del codice sorgente familiari per gestire gli elementi di Fabric
Per altre informazioni sul processo di integrazione con Git vedere:
- Integrazione Git di Fabric
- Concetti di base nell'integrazione Git
- Attività iniziali con l'integrazione Git (anteprima)
Configurare un collegamento al controllo del codice sorgente
Dalla pagina Impostazioni area di lavoro è possibile configurare facilmente un collegamento al repository per eseguire il commit e la sincronizzazione delle modifiche.
- Per configurare il collegamento, vedere Attività iniziali per l'integrazione Git. Seguire le istruzioni per Connetti a un repository Git in Azure DevOps o GitHub, come operatore Git.
- Una volta connessi, gli elementi, inclusi i magazzini, vengono visualizzati nel pannello Controllo del codice sorgente.
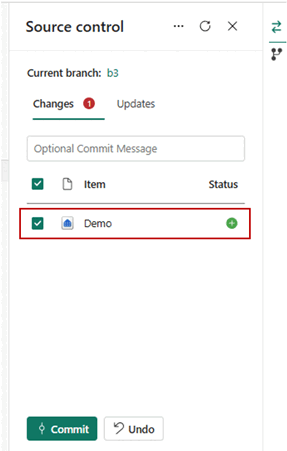
- Dopo aver connesso correttamente le istanze del magazzino al repository Git, viene visualizzata la struttura della cartella di magazzino. È ora possibile eseguire operazioni future, ad esempio la creazione di una richiesta pull.
Progetti di database per un magazzino in Git
L'immagine seguente è un esempio della struttura di file di ogni elemento del magazzino nel repository:

Quando si esegue il commit dell'elemento di magazzino nel repository Git, il magazzino viene convertito in un formato di codice sorgente come progetto di database SQL. Un progetto SQL è una rappresentazione locale degli oggetti SQL che costituiscono lo schema di un database singolo, ad esempio tabelle, stored procedure o funzioni. La struttura di cartelle degli oggetti database è organizzata per Schema/Tipo di oggetto. Ogni oggetto nel magazzino è rappresentato con un file .sql che contiene la propria definizione DDL (Data Definition Language). I dati delle tabelle di magazzino e le funzionalità della sicurezza SQL non sono inclusi nel progetto di database SQL.
Anche le query condivise vengono sottoposte a commit nel repository ed ereditano il nome in cui vengono salvate.
Scaricare il progetto di database SQL di un magazzino in Fabric
Con l'estensione dei progetti di database SQL disponibile all'interno di Azure Data Studio e di Visual Studio Code, è possibile gestire uno schema del magazzino e gestire le modifiche dell'oggetto magazzino come per altri progetti di database SQL.
Per il download di una copia locale dello schema del magazzino, selezionare Scarica progetto di database SQL nel nastro.

Copia locale di un progetto di database contenente la definizione dello schema del magazzino. Il progetto di database può essere usato per:
- Ricreare lo schema del magazzino in un altro magazzino.
- Sviluppare ulteriormente lo schema del magazzino negli strumenti client, ad esempio Azure Data Studio o Visual Studio Code.
Pubblicare un progetto di database SQL in un nuovo magazzino
Per pubblicare lo schema del magazzino in un nuovo magazzino:
- Creare un nuovo magazzino nell'area di lavoro di Fabric.
- Nella pagina di avvio del nuovo magazzino, in Compila un magazzino selezionare Progetto di database SQL.

- Selezionare il file .zip scaricato dal magazzino esistente.
- Lo schema del magazzino viene pubblicato nel nuovo magazzino.

Pipeline di distribuzione
Inoltre è possibile usare le pipeline di distribuzione per implementare il codice di magazzino in ambienti diversi, ad esempio sviluppo, test e produzione. Le pipeline di distribuzione non espongono un progetto di database.
Usare i passaggi seguenti per completare la distribuzione del magazzino usando la pipeline di distribuzione.
- Creare una nuova pipeline di distribuzione o aprire una pipeline di distribuzione esistente. Per altre informazioni, vedere Attività iniziali con le pipeline di distribuzione.
- Assegnare le aree di lavoro a fasi diverse in base agli obiettivi di distribuzione.
- Selezionare, visualizzare e confrontare gli elementi, inclusi i magazzini tra fasi diverse, come illustrato nell'esempio seguente.
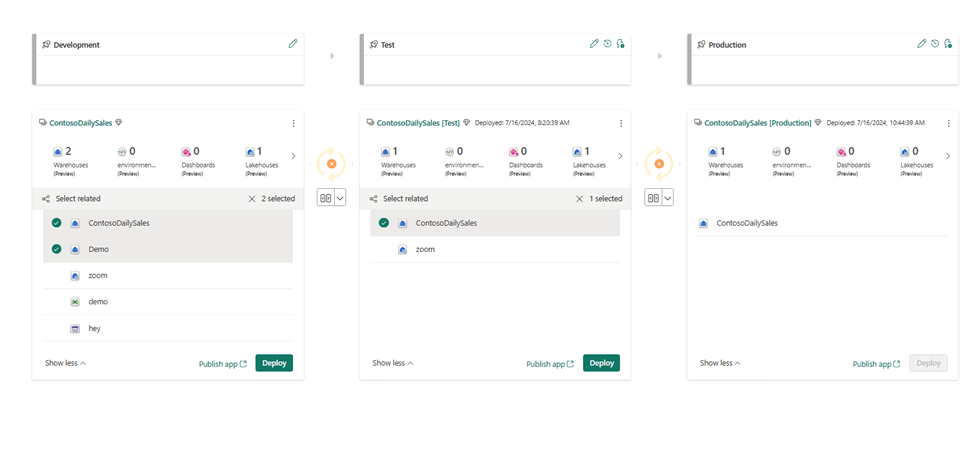
- Selezionare Implementare per implementare i magazzini nelle fasi Sviluppo, Test e Produzione.

Per altre informazioni sul processo delle pipeline di distribuzione in Fabric, vedere Informazioni generali sulle pipeline di distribuzione di Fabric.
Limitazioni nel controllo del codice sorgente
- Le funzionalità della sicurezza SQL devono essere esportate/migrate usando un approccio basato su script. È consigliabile usare uno script post-distribuzione in un progetto di database SQL, che è possibile configurare aprendo il progetto con l'estensione progetti di database SQL disponibile in Azure Data Studio.
Limiti dell'integrazione Git
- Attualmente, se si usa
ALTER TABLEper aggiungere un vincolo o una colonna nel progetto di database, la tabella verrà esclusa e ricreata durante l'implementazione, con conseguente perdita di dati. Prendere in considerazione la soluzione alternativa seguente per mantenere la definizione e i dati della tabella:- Creare una nuova copia della tabella nel magazzino usando
CREATE TABLEeINSERT,CREATE TABLE AS SELECTo Clonare la tabella. - Modificare la nuova definizione di tabella con nuovi vincoli o colonne, in base alle esigenze, usando
ALTER TABLE. - Eliminare la tabella precedente.
- Rinominare la nuova tabella con il nome della tabella precedente usando sp_rename.
- Modificare la definizione della tabella precedente nel progetto di database SQL nello stesso identico modo. Il progetto di database SQL del magazzino nel controllo del codice sorgente e il magazzino live ora dovrebbero corrispondere.
- Creare una nuova copia della tabella nel magazzino usando
- Attualmente, non creare un flusso di dati Gen2 con meta di output nel magazzino. Il commit e l'aggiornamento da Git verrebbero bloccati da un nuovo elemento denominato
DataflowsStagingWarehouse, visualizzato nel repository. - L'endpoint di analisi SQL non è supportato per l'integrazione Git.
Limiti per le pipeline di distribuzione
- Attualmente, se si usa
ALTER TABLEper aggiungere un vincolo o una colonna nel progetto di database, la tabella verrà esclusa e ricreata durante l'implementazione, con conseguente perdita di dati. - Attualmente, non creare un flusso di dati Gen2 con meta di output nel magazzino. La distribuzione verrebbe bloccata da un nuovo elemento denominato
DataflowsStagingWarehousevisualizzato nella pipeline di distribuzione. - L'endpoint di analisi SQL non è supportato nelle pipeline di distribuzione.