Creare una lakehouse per Direct Lake
Questo articolo descrive come creare una lakehouse, creare una tabella Delta nella lakehouse e quindi creare un modello semantico di base per la lakehouse in un'area di lavoro di Microsoft Fabric.
Prima di iniziare a creare una lakehouse per Direct Lake, vedere Panoramica di Direct Lake.
Creare una lakehouse
Nell'area di lavoro Di Microsoft Fabric selezionare Nuove>opzioni e quindi in Ingegneria dei dati selezionare il riquadro Lakehouse.
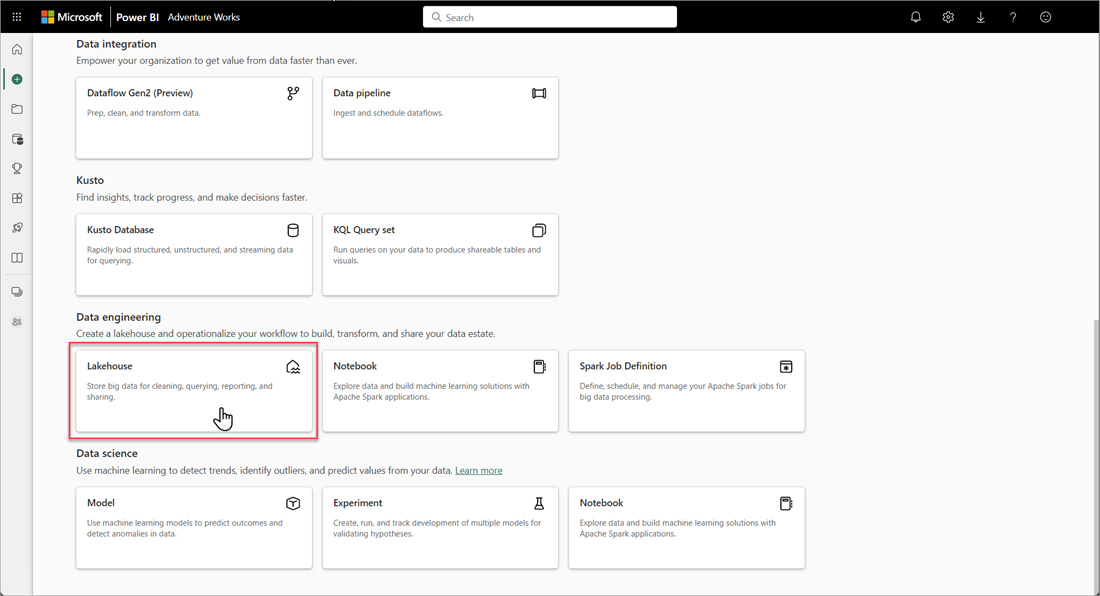
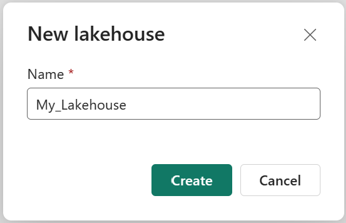
Nella finestra di dialogo Nuovo lakehouse immettere un nome e quindi selezionare Crea. Il nome può contenere solo caratteri alfanumerici e caratteri di sottolineatura.
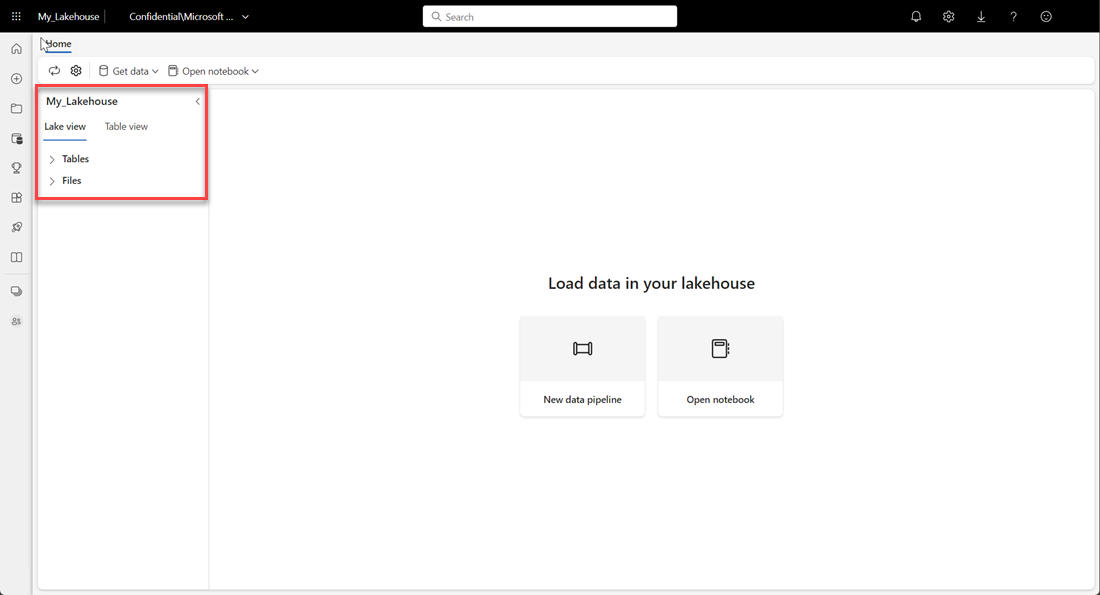
Verificare che il nuovo lakehouse sia stato creato e che venga aperto correttamente.
Creare una tabella Delta nella lakehouse
Dopo aver creato un nuovo lakehouse, è necessario creare almeno una tabella Delta in modo che Direct Lake possa accedere ad alcuni dati. Direct Lake può leggere file in formato parquet, ma per ottenere prestazioni ottimali, è consigliabile comprimere i dati usando il metodo di compressione VORDER. VORDER comprime i dati usando l'algoritmo di compressione nativo del motore power BI. In questo modo il motore può caricare i dati in memoria il più rapidamente possibile.
Sono disponibili più opzioni per caricare i dati in un lakehouse, tra cui pipeline di dati e script. La procedura seguente usa PySpark per aggiungere una tabella Delta a una lakehouse basata su un set di dati aperto di Azure:
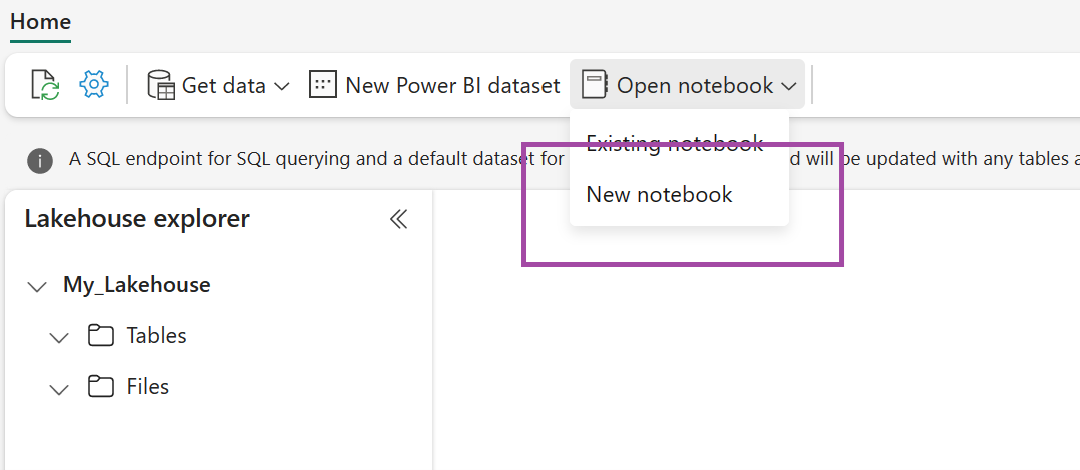
Nel lakehouse appena creato selezionare Apri notebook e quindi selezionare Nuovo notebook.
Copiare e incollare il frammento di codice seguente nella prima cella di codice per consentire a SPARK di accedere al modello aperto, quindi premere MAIUSC + INVIO per eseguire il codice.
# Azure storage access info blob_account_name = "azureopendatastorage" blob_container_name = "holidaydatacontainer" blob_relative_path = "Processed" blob_sas_token = r"" # Allow SPARK to read from Blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set( 'fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token) print('Remote blob path: ' + wasbs_path)Verificare che il codice restituisca correttamente un percorso BLOB remoto.
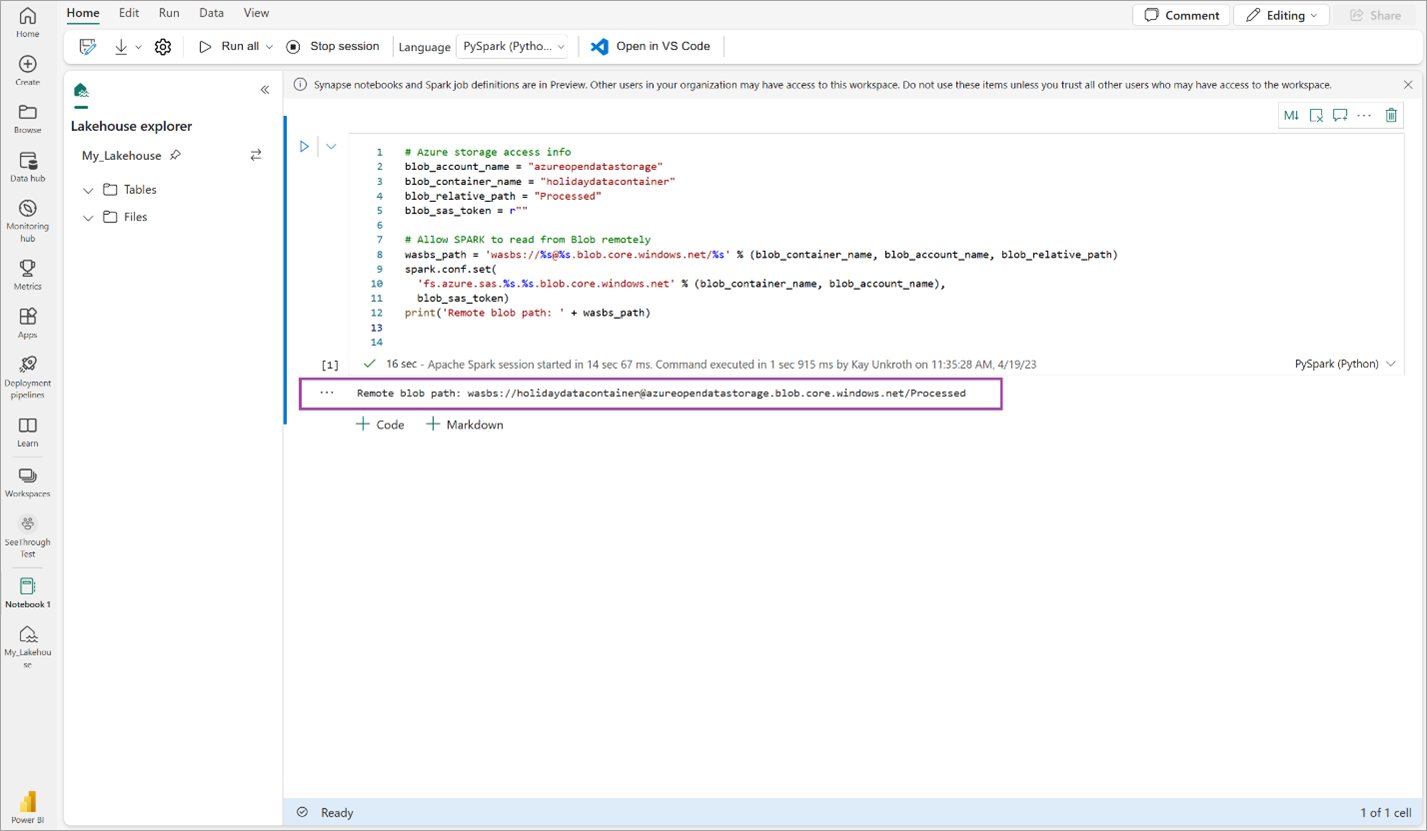
Copiare e incollare il codice seguente nella cella successiva, quindi premere MAIUSC + INVIO.
# Read Parquet file into a DataFrame. df = spark.read.parquet(wasbs_path) print(df.printSchema())Verificare che il codice restituisca correttamente lo schema del dataframe.
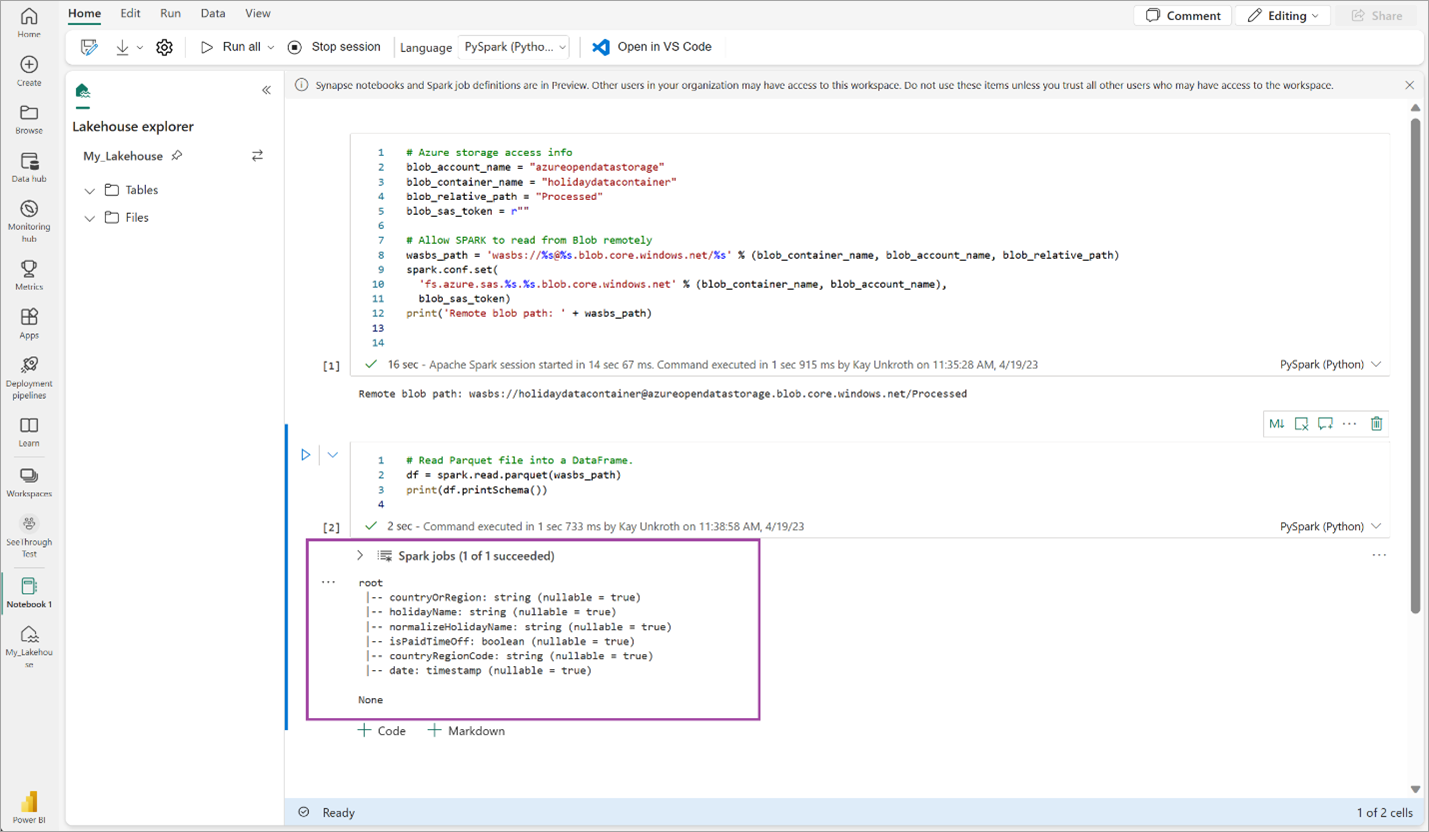
Copiare e incollare le righe seguenti nella cella successiva, quindi premere MAIUSC + INVIO. La prima istruzione abilita il metodo di compressione VORDER e l'istruzione successiva salva il DataFrame come tabella Delta nella lakehouse.
# Save as delta table spark.conf.set("spark.sql.parquet.vorder.enabled", "true") df.write.format("delta").saveAsTable("holidays")Verificare che tutti i processi SPARK siano stati completati correttamente. Espandere l'elenco dei processi SPARK per visualizzare altri dettagli.
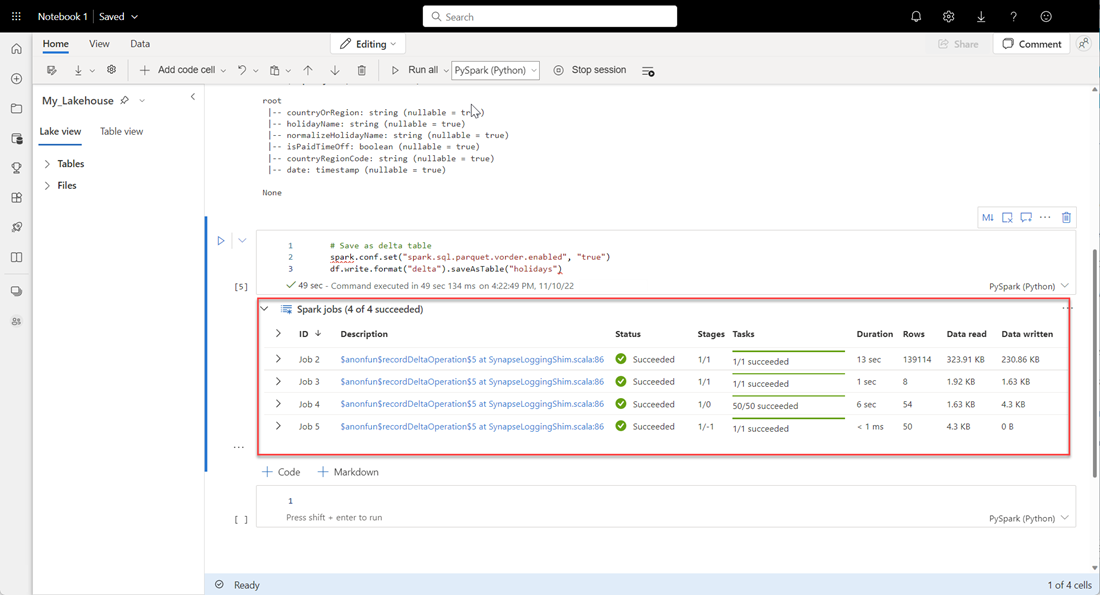
Per verificare che una tabella sia stata creata correttamente, nell'area superiore sinistra accanto a Tabelle selezionare i puntini di sospensione (...), quindi selezionare Aggiorna e quindi espandere il nodo Tabelle .
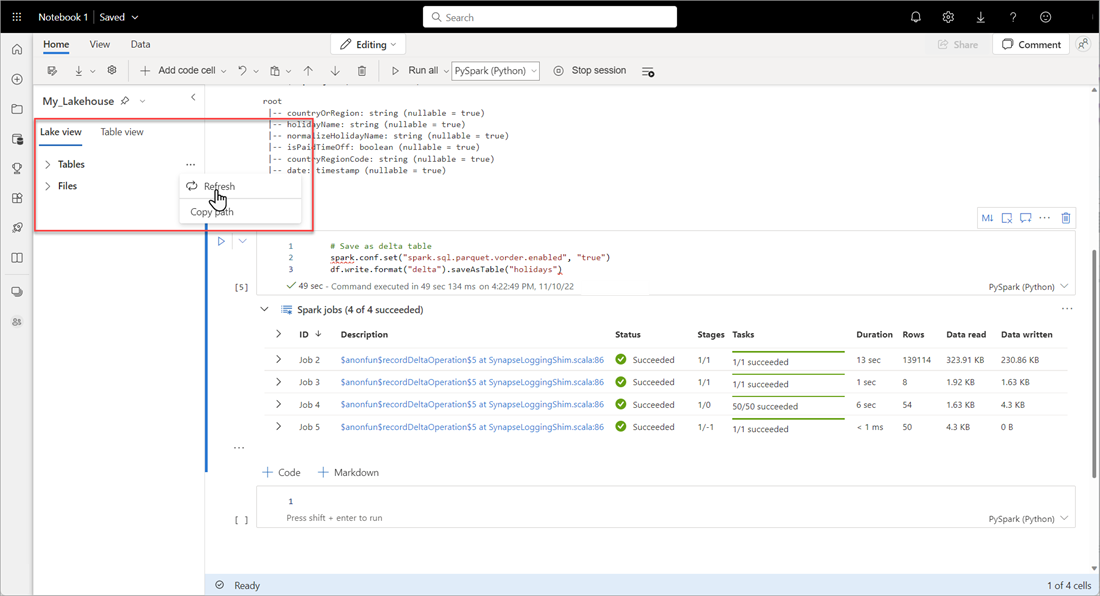
Usando lo stesso metodo precedente o altri metodi supportati, aggiungere altre tabelle Delta per i dati da analizzare.
Creare un modello Direct Lake di base per il lakehouse
Nel lakehouse selezionare Nuovo modello semantico e quindi nella finestra di dialogo selezionare le tabelle da includere.
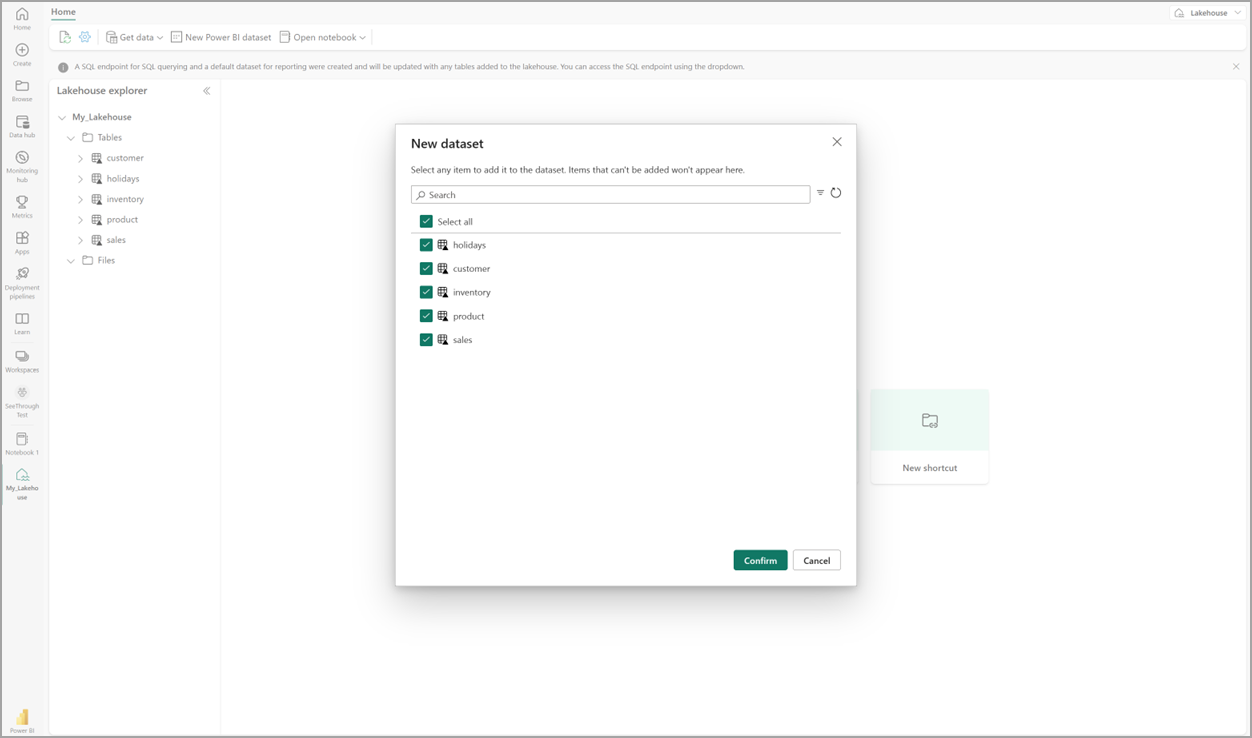
Selezionare Conferma per generare il modello Direct Lake. Il modello viene salvato automaticamente nell'area di lavoro in base al nome del lakehouse e quindi apre il modello.
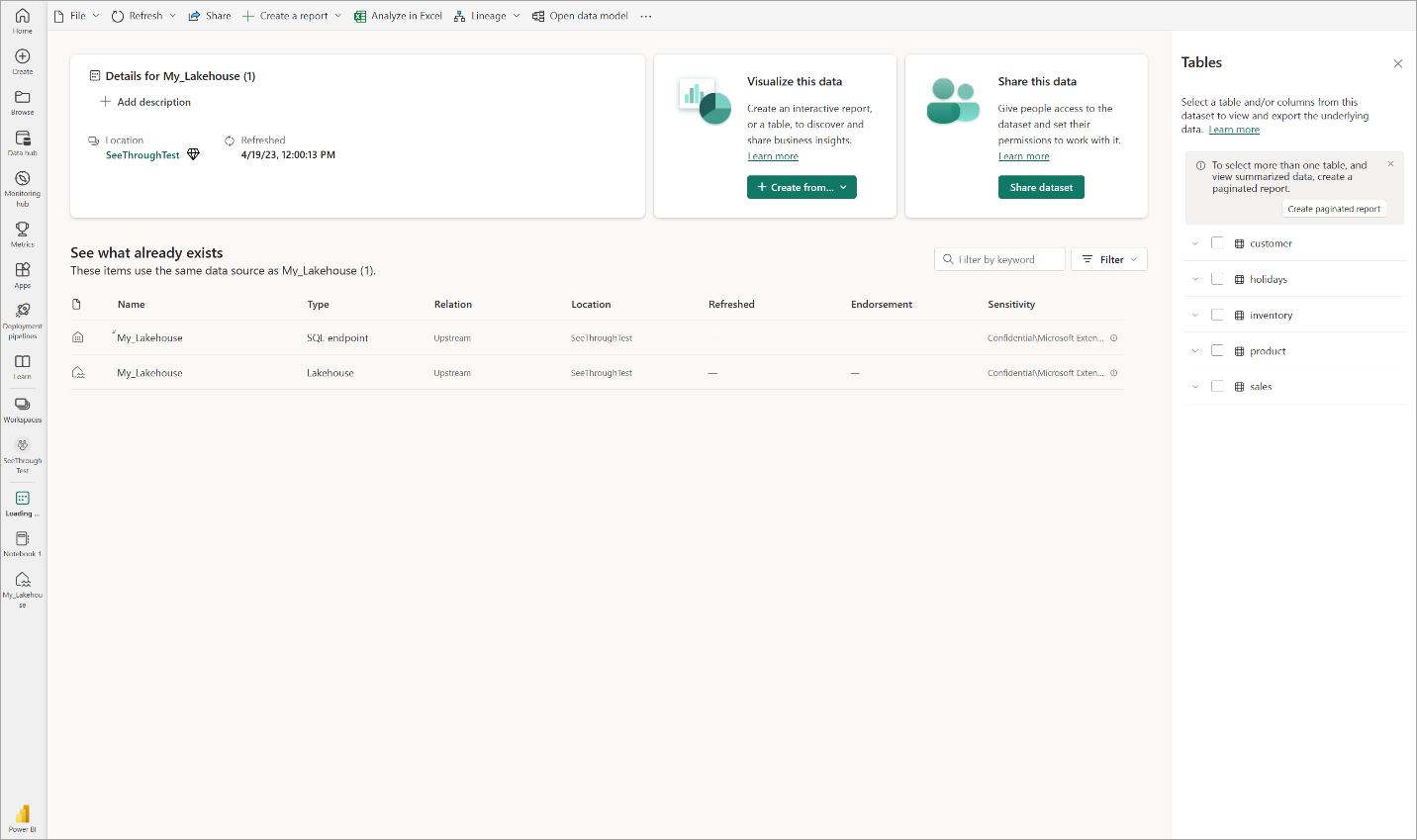
Selezionare Apri modello di dati per aprire l'esperienza di modellazione Web in cui è possibile aggiungere relazioni tra tabelle e misure DAX.
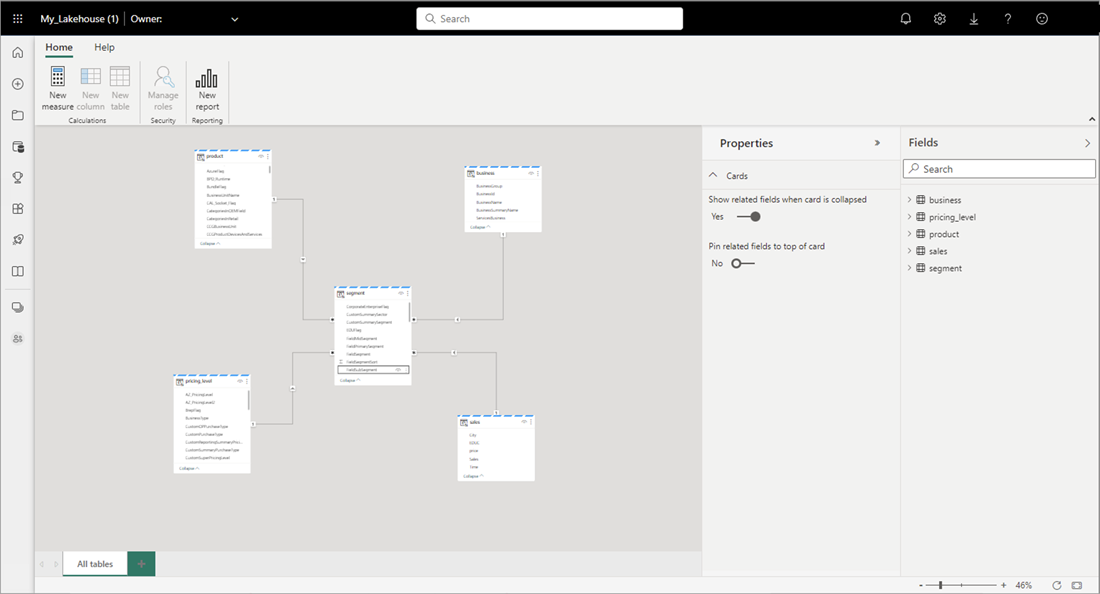
Al termine dell'aggiunta di relazioni e misure DAX, è possibile creare report, creare un modello composito ed eseguire query sul modello tramite endpoint XMLA nello stesso modo di qualsiasi altro modello.