Portare i dati a OneLake con Lakehouse
Questa esercitazione è una guida rapida alla creazione di un lakehouse e un'introduzione ai metodi di base per interagire con esso. Dopo aver completato questa esercitazione, si avrà un lakehouse di cui è stato effettuato il provisioning all'interno di Microsoft Fabric che lavora su OneLake.
Creare un lakehouse
Accedere a Microsoft Fabric.
Passare a Ingegneria dei dati usando l'icona del commutatore del carico di lavoro nell'angolo inferiore sinistro della home page.
Selezionare Aree di lavoro dal menu a sinistra.
Per aprire l'area di lavoro, immettere il nome dell’area di lavoro nella casella di testo di ricerca collocata nella parte superiore e selezionarlo nei risultati della ricerca.
Nell'angolo superiore sinistro della pagina iniziale dell'area di lavoro, selezionare Nuovo e quindi scegliere Lakehouse.
Assegnare al lakehouse un nome e selezionare Crea.
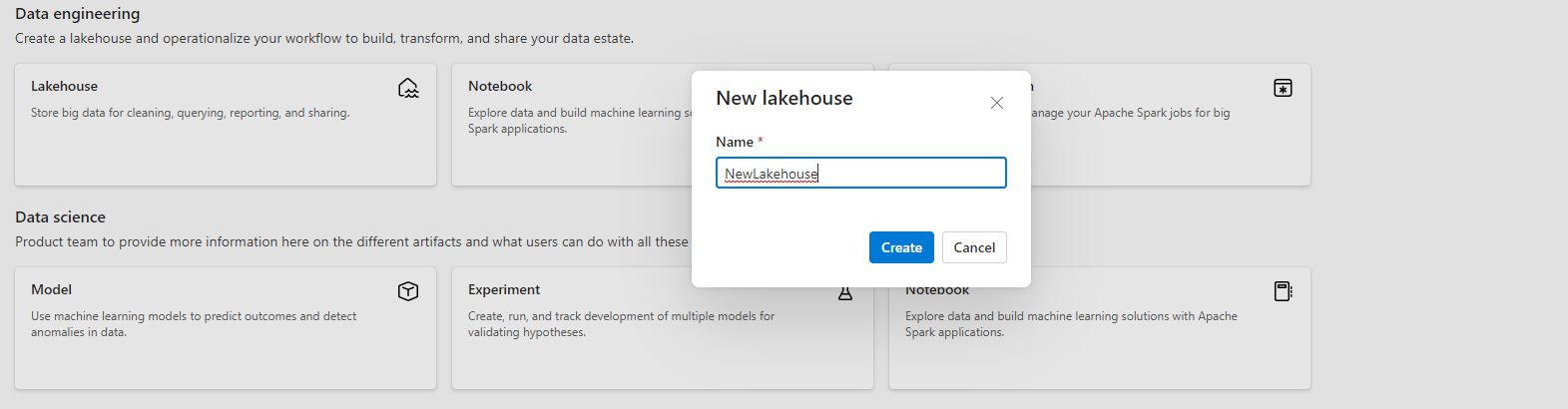
Viene creato un nuovo lakehouse e, se si tratta del primo elemento OneLake, viene eseguito il provisioning di OneLake in background.

A questo punto, si dispone di un lakehouse in esecuzione su OneLake. Aggiungere quindi alcuni dati e iniziare a organizzare il lake.
Caricare i dati in un lakehouse
Nel browser di file a sinistra, selezionare File e quindi Nuova sottocartella. Assegnare un nome alla sottocartella e selezionare Crea.
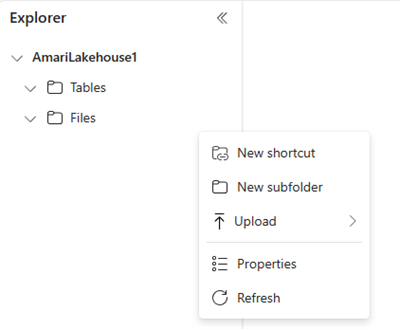
È possibile ripetere questo passaggio per aggiungere altre sottocartelle in base alle esigenze.
Selezionare una cartella e selezionare Carica file dall'elenco.
Scegliere il file desiderato dal computer locale e poi selezionare Carica.
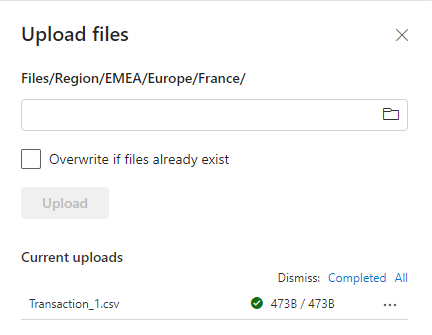
I dati sono stati aggiunti a OneLake. Per aggiungere dati in blocco o pianificare i caricamenti di dati in OneLake, usare il pulsante Recupera dati per creare pipeline. Per altre informazioni sulle opzioni per il recupero dei dati, vedere la Guida alle decisioni di Microsoft Fabric: attività Copy, flusso di dati o Spark.
Selezionare l'icona Altro (...) per il file caricato e selezionare Proprietà dal menu.
La schermata Proprietà mostra i vari dettagli per il file, inclusi l'URL e il percorso Azure Blob File System (ABFS) da usare con i notebook. È possibile copiare ABFS in un notebook di Fabric per eseguire query sui dati usando Apache Spark. Per altre informazioni sui notebook in Fabric, vedere Esplorare i dati in lakehouse con un notebook.
È stato creato il primo lakehouse con i dati archiviati in OneLake.