Eventi
Ottieni gratuitamente la certificazione in Microsoft Fabric.
19 nov, 23 - 10 dic, 23
Per un periodo di tempo limitato, il team della community di Microsoft Fabric offre buoni per esami DP-600 gratuiti.
Prepara oraQuesto browser non è più supportato.
Esegui l'aggiornamento a Microsoft Edge per sfruttare i vantaggi di funzionalità più recenti, aggiornamenti della sicurezza e supporto tecnico.
Questo scenario illustra come connettersi a OneLake tramite Azure Databricks. Dopo aver completato questa esercitazione, sarà possibile leggere e scrivere in un lakehouse di Microsoft Fabric dall'area di lavoro di Databricks di Azure.
Prima di connettersi, è necessario disporre di:
Aprire l'area di lavoro di Databricks di Azure e selezionare Crea>Cluster.
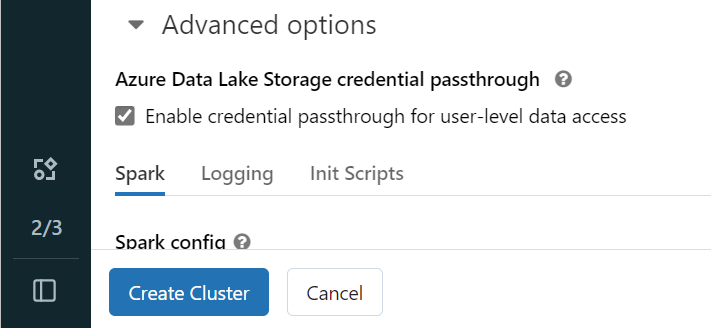
Per eseguire l'autenticazione a OneLake con l'identità di Microsoft Entra, è necessario abilitare il pass-through delle credenziali di Azure Data Lake Storage (ADLS) nel cluster nelle opzioni avanzate.
Nota
È anche possibile connettere Databricks a OneLake usando un'entità servizio. Per altre informazioni sull'autenticazione di Azure Databricks con un'entità servizio, vedere Gestire le entità servizio.
Creare il cluster con i parametri preferiti. Per altre informazioni sulla creazione di cluster di Databricks, vedere Configura cluster – Azure Databricks.
Aprire un notebook e connetterlo al cluster appena creato.
Andare al lakehouse di Fabric e copiare il percorso di Azure Blob Filesystem (ABFS) nel lakehouse. È possibile trovarlo nel riquadro Proprietà.
Nota
Azure Databricks supporta solo il driver Azure Blob Filesystem durante la lettura e la scrittura in ADLS Gen2 e OneLake: abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/.
Salvare il percorso del lakehouse nel notebook di Databricks. Questo lakehouse è dove si scrivono i dati elaborati successivamente:
oneLakePath = 'abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/myLakehouse.lakehouse/Files/'
Caricare dati da un set di dati pubblico di Databricks in un dataframe. È anche possibile leggere un file da un'altra posizione in Fabric o scegliere un file da un altro account ADLS Gen2 già proprietario.
yellowTaxiDF = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/databricks-datasets/nyctaxi/tripdata/yellow/yellow_tripdata_2019-12.csv.gz")
Filtrare, trasformare o preparare i dati. Per questo scenario, è possibile ridurre il set di dati per un caricamento più rapido, unirlo ad altri set di dati o filtrare in base a risultati specifici.
filteredTaxiDF = yellowTaxiDF.where(yellowTaxiDF.fare_amount<4).where(yellowTaxiDF.passenger_count==4)
display(filteredTaxiDF)
Scrivere il dataframe filtrato nel lakehouse di Fabric usando il percorso di OneLake.
filteredTaxiDF.write.format("csv").option("header", "true").mode("overwrite").csv(oneLakePath)
Verificare che i dati siano stati scritti correttamente leggendo il file appena caricato.
lakehouseRead = spark.read.format('csv').option("header", "true").load(oneLakePath)
display(lakehouseRead.limit(10))
Congratulazioni. È ora possibile leggere e scrivere dati in Fabric usando Azure Databricks.
Eventi
Ottieni gratuitamente la certificazione in Microsoft Fabric.
19 nov, 23 - 10 dic, 23
Per un periodo di tempo limitato, il team della community di Microsoft Fabric offre buoni per esami DP-600 gratuiti.
Prepara ora