Ottenere dati di Archiviazione di Azure
Questo articolo illustra come ottenere dati dall'archiviazione di Azure (contenitore ADLS Gen2, contenitore BLOB o singoli BLOB) in una tabella nuova o esistente.
Prerequisiti
- Un'area di lavoro con una capacità abilitata per Microsoft Fabric
- Un database KQL con autorizzazioni di modifica
- Un account di archiviazione
Origine
Nella barra multifunzione inferiore del database KQL selezionare Ottenere dati.
Nella finestra Ottieni dati è selezionata la scheda Origine.
Selezionare l'origine dati dall'elenco disponibile. In questo esempio sati inserendo dati da Azure storage.


Configurare
Selezionare una tabella di destinazione. Per inserire dati in una nuova tabella, selezionare + Nuova tabella e immettere un nome tabella.
Nota
I nomi delle tabelle possono avere un massimo di 1.024 caratteri, inclusi spazi, caratteri alfanumerici, trattini e trattini bassi. I caratteri speciali non sono supportati.
Per aggiungere l'origine dati, incollare la stringa di connessione di archiviazione nel campo URI e quindi selezionare +. La tabella seguente elenca i metodi di autenticazione supportati e le autorizzazioni necessarie per l'inserimento di dati da Archiviazione di Azure.
Authentication method Singoli processi Contenitore BLOB Azure Data Lake Storage Gen2 Token (SAS) di accesso condiviso Lettura e scrittura Lettura e Lista Lettura e Lista Chiave di accesso dell'account di archiviazione Nota
- È possibile aggiungere fino a 10 singoli BLOB oppure inserire fino a 5000 BLOB da un singolo contenitore. Non si possono utilizzare entrambe le opzioni contemporaneamente.
- Ogni BLOB può essere un massimo di 1 GB non compresso.
Se è stato incollata una stringa di connessione per un contenitore BLOB o Azure Data Lake Storage Gen2, è possibile aggiungere i filtri facoltativi seguenti:

Impostazione Descrizione campo Gestisci filtri file (facoltativo) Percorso cartella Filtra i dati per inserire file con un percorso di cartella specifico. Estensione di file Filtra i dati per inserire file solo con un'estensione di file specifica.
Selezionare Avanti

Controllare
La scheda Ispezione si apre con un'anteprima dei dati.
Selezionare Fine per completare il processo di inserimento.

Facoltativamente:
- Selezionare Command viewer per visualizzare e copiare i comandi automatici generati dagli input.
- Usare il menù a discesa File di definizione dello schema per modificare il file da cui viene dedotto lo schema.
- Modificare il formato dei dati dedotti automaticamente selezionando il formato desiderato dal menu a tendina. Per maggiori informazioni, vedere Formati di dati supportati dall'Intelligence in tempo reale.
- Modifica colonne.
- Esplorare le Opzioni avanzate in base al tipo di dati.
Modifica colonne
Nota
- Per i formati tabulari (CSV, TSV, PSV), non è possibile eseguire il mapping di una colonna due volte. Per eseguire il mapping a una colonna esistente, eliminare prima quella nuova.
- Non è possibile modificare un tipo di colonna esistente. Se si tenta di eseguire il mapping su una colonna con un formato diverso, è possibile che appaiano colonne vuote.
Le modifiche che è possibile apportare in una tabella dipendono dai parametri seguenti:
- Il tipo di tabella è nuovo o esistente
- Il tipo di mapping è nuovo o esistente
| Tipo di tabella | Tipo di mapping | Modifiche disponibili |
|---|---|---|
| Nuova tabella | Nuovo mapping | Rinominare la colonna, modificare il tipo di dati, modificare l'origine dati, eseguire la Trasformazione del mapping, aggiungere una colonna, eliminare una colonna |
| Tabella esistente | Nuovo mapping | Aggiungi colonna (per cui è poi possibile cambiare il tipo di dati, rinominare e aggiornare) |
| Tabella esistente | Mapping esistente | Nessuno |

Trasformazioni del mapping
Alcuni mapping del formato dati (Parquet, JSON e Avro) supportano semplici trasformazioni in fase di inserimento. Per applicare le trasformazioni del mapping, creare o aggiornare una colonna nella finestra Modifica colonne.
Le trasformazioni del mapping possono essere eseguite su una colonna di tipo string o date/time, con l'origine che ha un tipo di dati int o long. Le trasformazioni del mapping supportate sono:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Opzioni avanzate in base al tipo di dati
Tabulare (CSV, TSV, PSV):
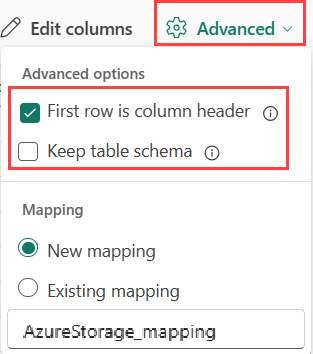
Se si inseriscono formati tabulari in una tabella esistente, è possibile selezionare Avanzate>Mantieni lo schema di tabella. I dati tabulari non comprendono necessariamente i nomi di colonna usati per eseguire il mapping dei dati di origine sulle colonne esistenti. Quando questa opzione è selezionata, il mapping viene eseguito in base all'ordine e lo schema della tabella rimane invariato. Se questa opzione è deselezionata, vengono create nuove colonne per i dati in ingresso, indipendentemente dalla struttura dei dati.
Per usare la prima riga come nomi di colonna, selezionare Avanzate>Prima riga è intestazione di colonna.
JSON:
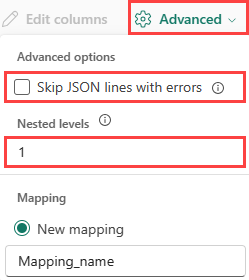
Per determinare la divisione delle colonne dei dati JSON, selezionare Avanzate>Livelli annidati, da 1 a 100.
Se si seleziona Avanzate>Ignora le righe JSON con errori, i dati vengono inseriti in formato JSON. Se si lascia deselezionata questa casella di controllo, i dati vengono inseriti in formato multijson.
Riepilogo
Nella finestra Preparazione dei dati, tutti e tre i passaggi sono contrassegnati con segni di spunta verdi quando l'inserimento dati si conclude con successo. È possibile selezionare una scheda per eseguire query, eliminare i dati inseriti o visualizzare una dashboard con il riepilogo dell'inserimento.

Contenuto correlato
- Per gestire il database, vedere Gestire i dati
- Per creare, archiviare ed esportare query, vedere Dati query in un set di query KQL