Opzioni di continuità aziendale e ripristino di emergenza per FSLogix
Nota
Tutti i diagrammi sono esempi basati su Desktop virtuale Azure e sono applicabili ad altre piattaforme desktop virtuali.
Un piano di continuità aziendale e ripristino di emergenza (BCDR) efficace è incentrato sui processi e sulle risorse necessarie per consentire a un'organizzazione di operare in caso di catastrofe o altre interruzioni significative. I profili utente mobili non vengono comunemente descritti come componente aziendale o cruciale di una strategia BCDR . In un ambiente desktop virtuale, un utente non è a conoscenza di avere un profilo mobile. Il profilo viene sottoposto a roaming per offrire agli utenti un'esperienza coerente indipendentemente dalla macchina virtuale. I dati aziendali o cruciali non devono essere archiviati nel profilo di un utente, se possibile. L'uso di OneDrive, SharePoint o altre soluzioni è un mezzo efficace per proteggere i dati durante un evento BCDR , senza basarsi sul roaming dei dati con l'utente come parte del profilo. Questo processo è descritto meglio in un esercizio obiettivo del tempo di ripristino (RTO) e obiettivo del punto di ripristino (RPO), in cui il vantaggio dei costi e l'analisi dei rischi possono essere ponderati in base agli obiettivi aziendali e aziendali.
Opzione 1: Nessun ripristino del profilo
Anche se questa opzione non sembra una progettazione BCDR , è incentrata sulla garanzia che i dati aziendali e cruciali non siano nel profilo dell'utente. Durante un'emergenza, gli utenti creerebbero nuovi profili in una nuova posizione o in un nuovo provider di archiviazione (entrambi possono essere true). Questa opzione è il più conveniente in termini di costo dell'infrastruttura, anche se ha una penalità a causa dell'effetto che potrebbe avere sull'esperienza utente.
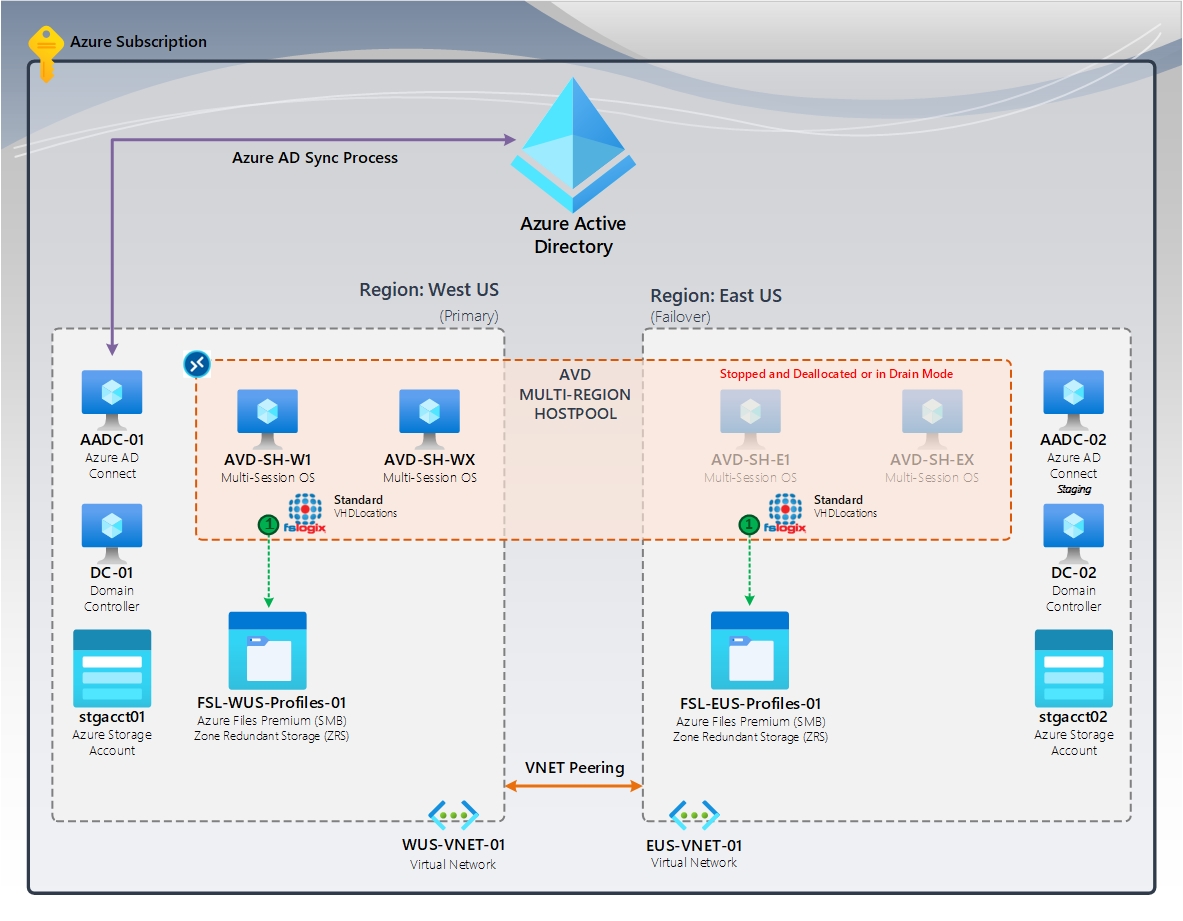
Figura 1: Nessun ripristino del profilo | Contenitori standard FSLogix (VHDLocations)
Nel diagramma è un pool di host in più aree usando Desktop virtuale Azure. Sia le aree primarie che di failover hanno una condivisione File di Azure dedicata usando l'archiviazione con ridondanza della zona (ZRS) che offre disponibilità elevata all'interno dell'area. L'area di failover dispone di host sessione, che vengono arrestati o deallocati. In un'emergenza, l'area di failover diventa l'area primaria e gli utenti accederanno a tali host sessione e creeranno nuovi profili nella condivisione File di Azure in tale area.
Opzione 2: Cache cloud (primaria/failover)
- Revisione: Panoramica di Cloud Cache
- Esempio: Advanced + Disaster Recovery (primario/failover)
Una progettazione di failover è una strategia comune per garantire la disponibilità e l'affidabilità dell'infrastruttura in caso di emergenza o di un errore. Cloud Cache consente di usare FSLogix usando questo tipo di progettazione del failover. Con Cloud Cache è possibile configurare i dispositivi in modo da usare due (2) provider di archiviazione che archiviano i dati del profilo in posizioni diverse. Cache cloud sincronizza i dati del profilo con ognuno dei due provider di archiviazione in modo asincrono, in modo da avere sempre la versione più recente dei dati. Alcuni dispositivi si trovano nella posizione primaria e gli altri dispositivi si trovano nella posizione di failover. Cloud Cache assegna la priorità al primo provider di archiviazione (più vicino al dispositivo) e usa l'altro provider di archiviazione come backup. Ad esempio, se il dispositivo primario si trova negli Stati Uniti occidentali e il dispositivo di failover si trova negli Stati Uniti orientali, è possibile configurare La cache cloud come indicato di seguito:
- Il dispositivo primario usa un provider di archiviazione negli Stati Uniti occidentali come prima opzione e un provider di archiviazione negli Stati Uniti orientali come seconda opzione.
- Il dispositivo di failover usa un provider di archiviazione negli Stati Uniti orientali come prima opzione e un provider di archiviazione negli Stati Uniti occidentali come seconda opzione.
- Se il dispositivo primario o il provider di archiviazione più vicino non riesce, è possibile passare al dispositivo di failover o al provider di archiviazione di backup e continuare il lavoro senza perdere i dati del profilo.
Tuttavia, esistono alcuni svantaggi dell'uso di una progettazione di failover con Cache cloud. Prima di tutto, è necessario pagare in più per archiviare i dati del profilo in due (2) posizioni. In secondo luogo, è necessario avviare manualmente il processo di failover, che potrebbe richiedere l'approvazione degli stakeholder aziendali. In terzo luogo, è possibile riscontrare una latenza o un'incoerenza nei dati del profilo a causa della sincronizzazione asincrona con i due provider di archiviazione.
Suggerimento
- Prima di consentire agli utenti di eseguire il failback ai profili nella posizione primaria, assicurarsi che tutti gli utenti abbiano eseguito correttamente la disconnessa dal percorso di failover per assicurarsi che la posizione primaria disponga di una replica aggiornata dei dati del profilo dell'utente.
- La cache cloud è un sistema a elevato utilizzo di I/O e può causare facilmente colli di bottiglia di rete e/o di archiviazione nel percorso ripristinato.
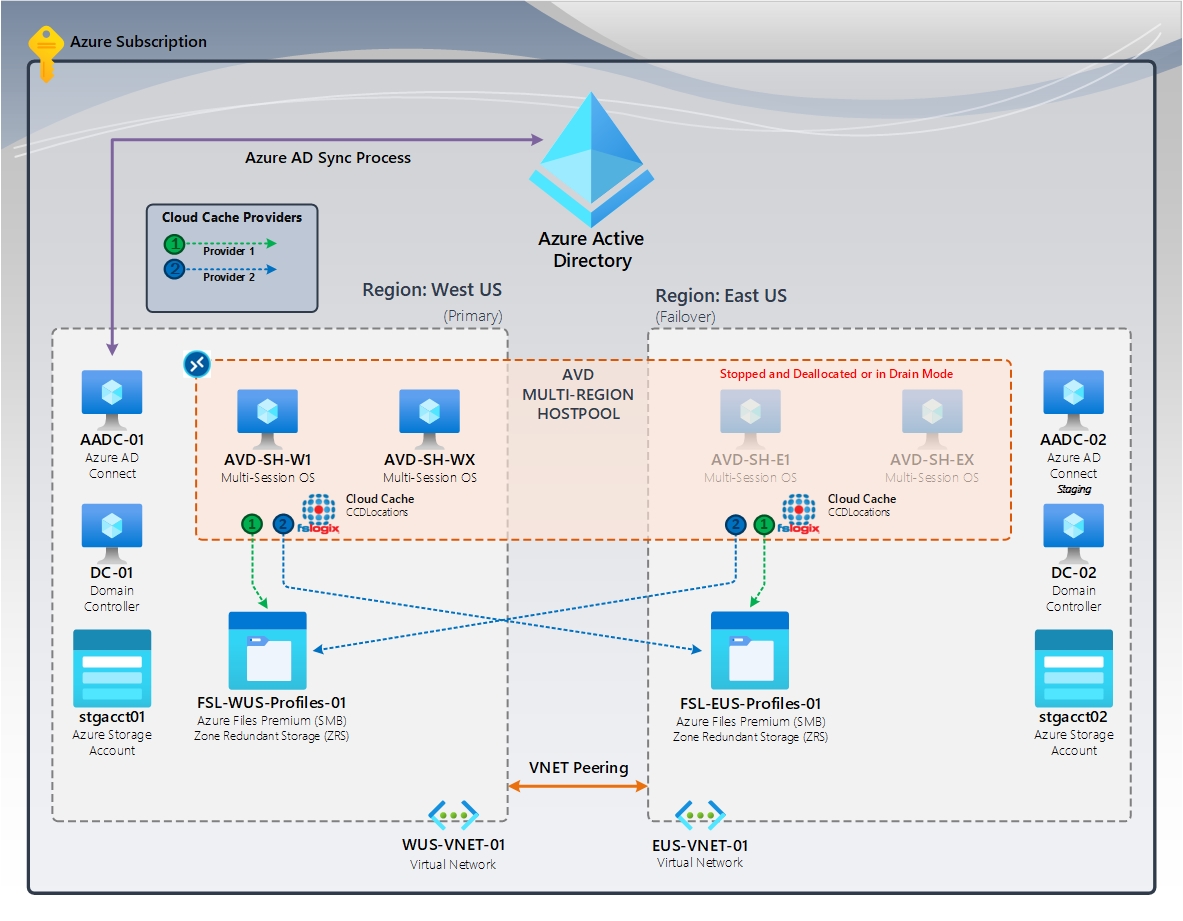
Figura 2: Cache cloud (primaria/failover) | FSLogix Cloud Cache (CCDLocations)
Nel diagramma è disponibile un pool di host in più aree che usa Desktop virtuale Azure. Entrambe le aree primarie e di failover fanno parte di questa configurazione. Ognuno di essi ha una condivisione di File di Azure dedicata usando l'archiviazione con ridondanza della zona (ZRS), garantendo la disponibilità elevata all'interno dell'area. L'area di failover contiene host sessione, che vengono arrestati o deallocati. In caso di emergenza, l'area di failover diventa l'area primaria. Gli utenti accederanno a questi host sessione e caricheranno il profilo replicato dall'area di failover.
Tuttavia, è essenziale considerare quanto segue:
- Gli eventi bcdr (continuità aziendale e ripristino di emergenza) sono raramente normale. A seconda delle circostanze, è possibile che i dati del profilo utente non siano intatti.
- Gli utenti che accedono agli host sessione nell'area di failover potrebbero riscontrare perdite di dati o, in casi peggiori, danneggiamento del contenitore.
Data questa situazione, è fondamentale usare piattaforme di archiviazione come OneDrive o SharePoint per i dati critici. Queste piattaforme offrono ridondanza e protezione aggiuntive contro la perdita di dati. Tenere presente che la pianificazione del ripristino di emergenza è essenziale e avere la giusta strategia di archiviazione può attenuare i rischi e garantire la continuità aziendale.
Opzione 3: Cache cloud (attiva/attiva)
- Revisione: Panoramica di Cloud Cache
- Esempio: Advanced + Disaster Recovery (primario/failover)
Quando si parla di infrastruttura, è comune usare progettazioni attive/attive, che possono essere applicate anche a una soluzione profilo FSLogix. Con questa opzione, Cache cloud è configurata con due provider di archiviazione aggiornati in modo asincrono per riflettere tutte le modifiche apportate alla cache locale. Il provider di archiviazione più vicino alla posizione attiva viene elencato per primo, mentre il provider più lontano è elencato secondo. Nell'altra posizione, l'ordine viene invertito. Questa opzione comporta costi aggiuntivi per l'archiviazione dei dati del provider in due posizioni e richiede una decisione manuale da parte degli stakeholder aziendali prima di avviare un failover.
Suggerimento
- Quando l'area non riuscita è operativa, potrebbe essere necessario tempo significativo per la replica completa dei dati del profilo.
- La cache cloud è un sistema a elevato utilizzo di I/O e può causare facilmente colli di bottiglia di rete e/o di archiviazione nel percorso ripristinato.
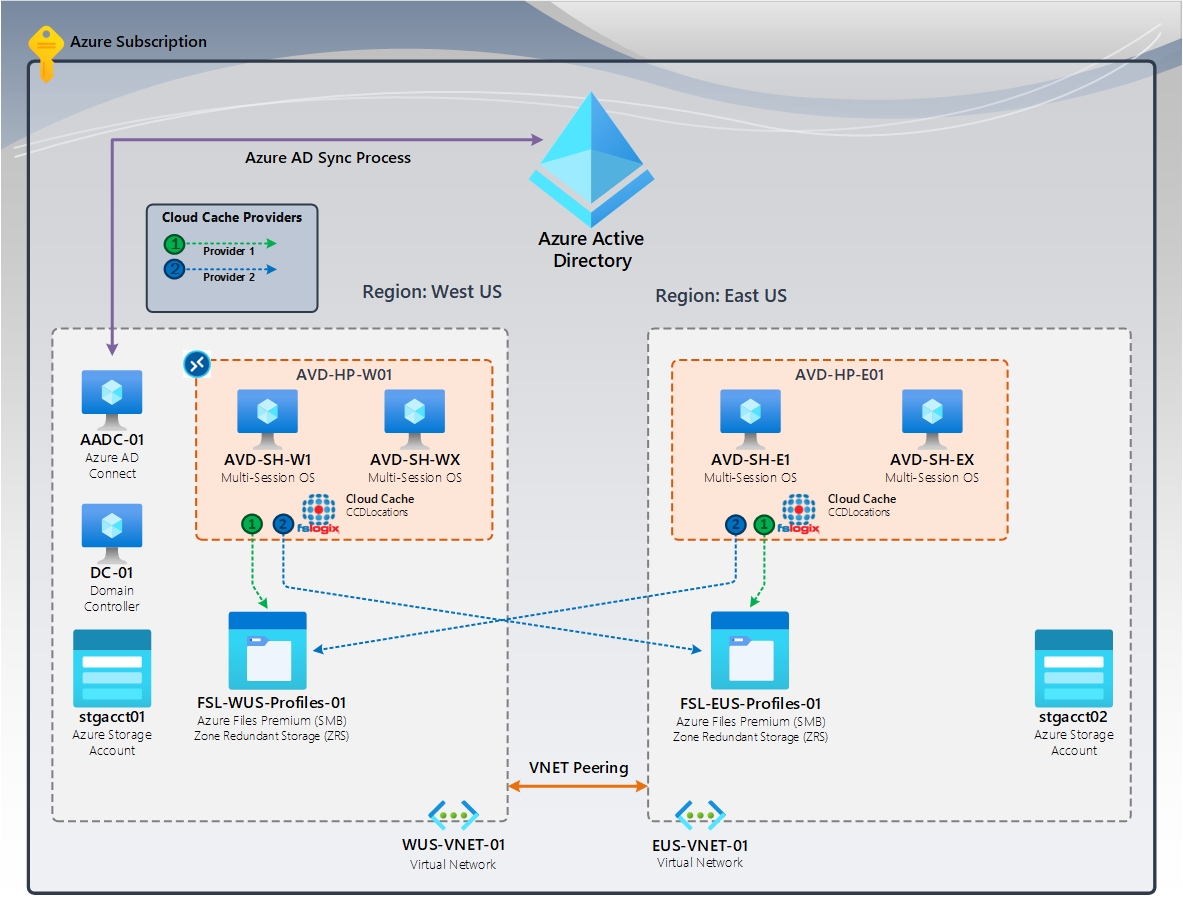
Figura 3: Cache cloud (attiva/attiva) | FSLogix Cloud Cache (CCDLocations)
Nel diagramma sono due (2) pool di host AVD e host di sessione che risiedono in aree di Azure specifiche. Gli utenti assegnati all'area Stati Uniti occidentali accedono a tali macchine virtuali. Gli utenti nell'area Stati Uniti orientali accedono solo a tali macchine virtuali. Durante un'emergenza, l'area sopravvissuta deve avere capacità sufficiente per supportare tutti gli utenti. Inoltre, gli utenti dell'area non riuscita devono avere accesso concesso alle macchine virtuali nell'area sopravvissuta.
Gli eventi BCDR non sono mai normali e, a seconda delle circostanze dell'evento, non è garantito che i dati del profilo utente siano intatti. Gli utenti che accedono agli host sessione nell'area sopravvissuta potrebbero riscontrare perdite di dati o un danneggiamento del contenitore peggiore. Questa situazione amplifica la necessità di usare piattaforme di archiviazione come OneDrive o SharePoint per i dati utente critici.