Documentazione tecnica sul connettore Generic SQL
Questo articolo descrive il connettore Generic SQL ed è applicabile ai prodotti seguenti:
- Microsoft Identity Manager 2016 (MIM2016)
- Microsoft Entra ID
Per MIM2016, il connettore è disponibile come download dall'Area download Microsoft.
Per vedere come funziona questo connettore, vedere l'articolo relativo alle istruzioni dettagliate per il connettore SQL generico .
Nota
Microsoft Entra ID offre ora una soluzione leggera basata su agente per il provisioning degli utenti in un database SQL, senza bisogno di una distribuzione di sincronizzazione MIM. È consigliabile usarlo per il provisioning utenti in uscita. Altre informazioni.
Panoramica del connettore Generic SQL
Il connettore Generic SQL consente di integrare il servizio di sincronizzazione con un sistema di database che offre la connettività ODBC.
A livello generale, le funzionalità seguenti sono supportate dalla versione corrente del connettore:
| Funzionalità | Supporto tecnico |
|---|---|
| Origine dati connessa | Il connettore è supportato con tutti i driver ODBC a 64 bit*. È stato testato con gli elementi seguenti: |
| Scenari | |
| Operazioni | |
| Schema |
Prerequisiti
Prima di usare il connettore, verificare che nel server di sincronizzazione sia disponibile quanto segue:
- Microsoft .NET 4.6.2 Framework o versione successiva
- Driver client ODBC a 64 bit
- Se si usa il connettore per comunicare con Oracle 12c, è necessario Oracle Instant Client 12.2.0.1 o versione successiva con il pacchetto ODBC.
- Se si usa il connettore per comunicare con Oracle 18c-23c, è necessario che Oracle Instant Client 18-23 o versione successiva con il pacchetto ODBC e la variabile di sistema NLS_LANG da impostare per supportare caratteri UTF8, ad esempio NLS_LANG=AMERICAN_AMERICA. AL32UTF8.
- Questo connettore usa istruzioni preparate sql e più istruzioni per transazione. Alcuni sistemi RDBM possono avere problemi nei driver ODBC correlati alla gestione delle transazioni, alle istruzioni SQL preparate sul lato server e a più istruzioni all'interno della stessa transazione. Configurare le opzioni di connessione DSN di conseguenza per assicurarsi che tali istruzioni vengano inviate correttamente al database. Ad esempio, mySQL ODBC Driver versione 8.0.32 richiede opzioni NO_SSPS=1 e MULTI_STATEMENTS=1. Altre opzioni, ad esempio "autocommit" o "commit solo per operazioni riuscite" possono influire sulla modalità di gestione delle esportazioni batch; Per informazioni dettagliate, consultare l'amministratore del database. Per risolvere i problemi durante l'esportazione, impostare le dimensioni del batch di esportazione su 1 e abilitare la registrazione dettagliata del connettore.
La distribuzione di questo connettore può richiedere modifiche alla configurazione del database e modifiche alla configurazione in MIM. Per le distribuzioni che coinvolgono l'integrazione di MIM con un server di database di terze parti in un ambiente di produzione, è consigliabile che i clienti lavorino con il fornitore di database o un partner di distribuzione per assistenza, indicazioni e supporto per questa integrazione.
Autorizzazioni nell'origine dati connessa
Per creare o eseguire una delle operazioni supportate nel connettore Generic SQL, è necessario avere:
- db_datareader
- db_datawriter
Porte e protocolli
Per le porte necessarie per il funzionamento del driver ODBC, vedere la documentazione del fornitore del database.
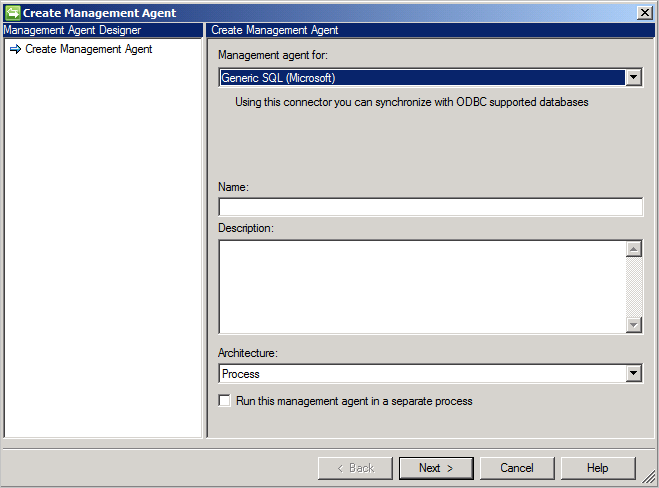
Creare un nuovo connettore
Per creare un connettore Generic SQL, in Synchronization Service selezionare Management Agent e quindi Create. Selezionare il connettore Generic SQL (Microsoft) .
Connettività
Il connettore usa un file DSN ODBC per la connettività. Creare il file DSN tramite Origini dati ODBC disponibile nel menu Start in Strumenti di amministrazione. Nello strumento di amministrazione creare un DSN file da passare al connettore.
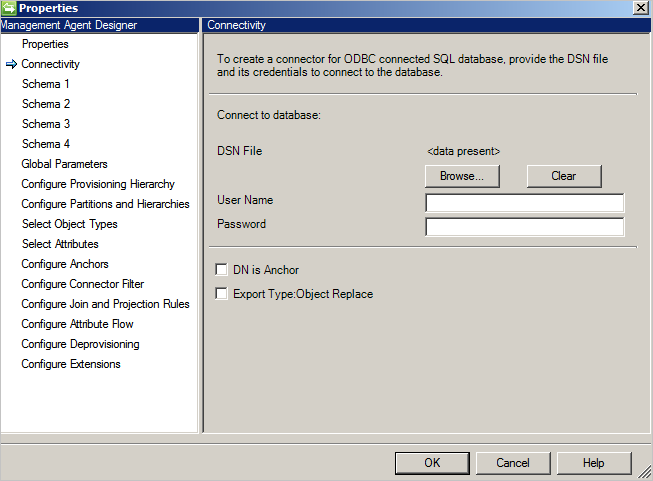
La schermata Connectivity è la prima visualizzata quando si crea un nuovo connettore Generic SQL. Prima di tutto è necessario specificare le informazioni seguenti:
- Percorso del file DSN
- Authentication
- Nome utente
- Password
Il database deve supportare uno di questi metodi di autenticazione:
- Autenticazione di Windows: il database di autenticazione usa le credenziali di Windows per verificare l'utente. Il nome utente e la password specificati vengono usati per l'autenticazione nel database. Questo account deve avere autorizzazioni sul database.
- Autenticazione SQL: il database di autenticazione usa il nome utente e la password definiti nella schermata Connectivity (Connettività) per connettersi al database. Se si archiviano il nome utente e la password nel file DSN, le credenziali fornite nella schermata Connectivity (Connettività) hanno la precedenza.
- database SQL di Azure'autenticazione: per altre informazioni, vedere Connettersi a database SQL tramite l'autenticazione di Microsoft Entra.
DN is Anchor(DN è Anchor): se si seleziona questa opzione, il DN viene usato anche come attributo di ancoraggio. Può essere usato per un'implementazione semplice, ma presenta anche la limitazione seguente:
- Il connettore supporta solo un tipo di oggetto. Di conseguenza gli attributi di riferimento possono fare riferimento solo allo stesso tipo di oggetto.
Export Type: Object Replace(Tipo di esportazione: sostituzione oggetto): durante l'esportazione se solo alcuni attributi sono stati modificati, l'intero oggetto con tutti gli attributi viene esportato e sostituisce l'oggetto esistente.
Schema 1 (rilevare i tipi di oggetto)
In questa pagina si configura il modo in cui il connettore troverà i diversi tipi di oggetto nel database.
Ogni tipo di oggetto viene presentato come una partizione e configurato ulteriormente in Configurare partizioni e gerarchie.
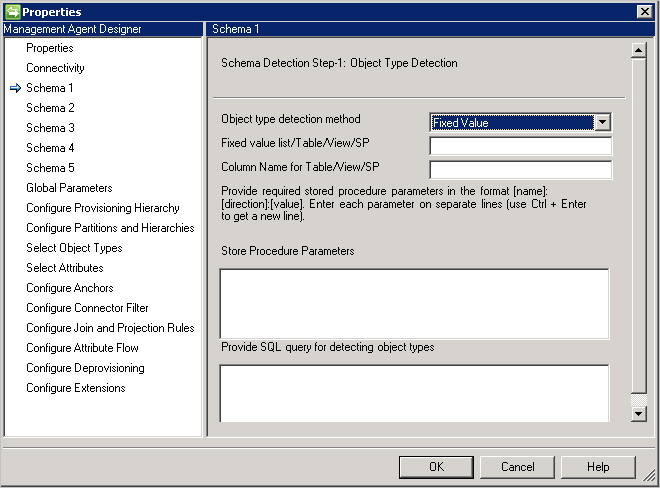
Object Type detection method: il connettore supporta questi metodi di rilevamento del tipo di oggetto.
- Fixed Value(Valore fisso): specificare l'elenco dei tipi di oggetto con un elenco con valori delimitati da virgole. Ad esempio:
User,Group,Department.
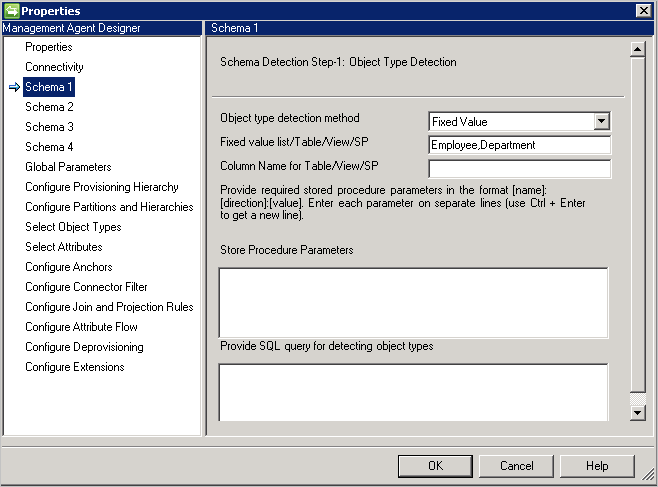
- Table/View/Stored Procedure(Tabella/Vista/Stored procedure): fornire il nome della tabella/vista/stored procedure, quindi il nome della colonna che fornisce l'elenco dei tipi di oggetto. Se si usa una stored procedure, fornire anche i relativi parametri nel formato [Nome]:[Direzione]:[Valore]. Specificare ogni parametro su una riga separata (usare CTRL+INVIO per ottenere una nuova riga).
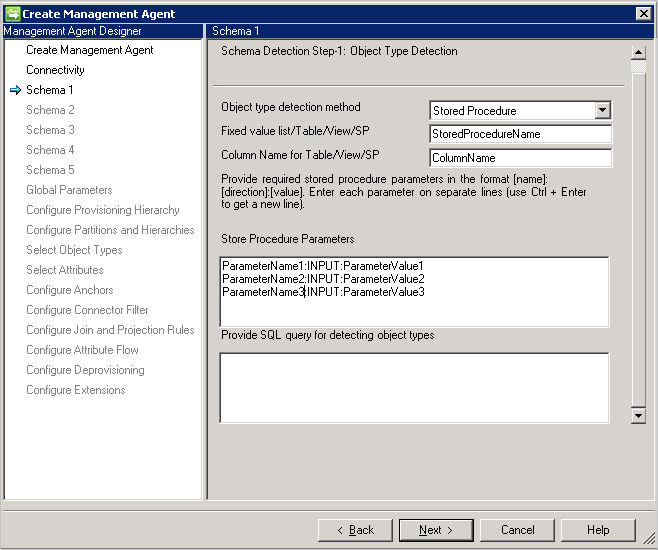
- SQL Query (Query SQL): questa opzione consente di fornire una query SQL che restituisce una singola colonna con i tipi di oggetto, ad esempio
SELECT [Column Name] FROM TABLENAME. La colonna restituita deve essere di tipo stringa (varchar).
Schema 2 (rilevare i tipi di attributo)
In questa pagina si configura in che modo verranno rilevati i nomi e i tipi di attributi. Le opzioni di configurazione sono elencate per ogni tipo di oggetto rilevato nella pagina precedente.
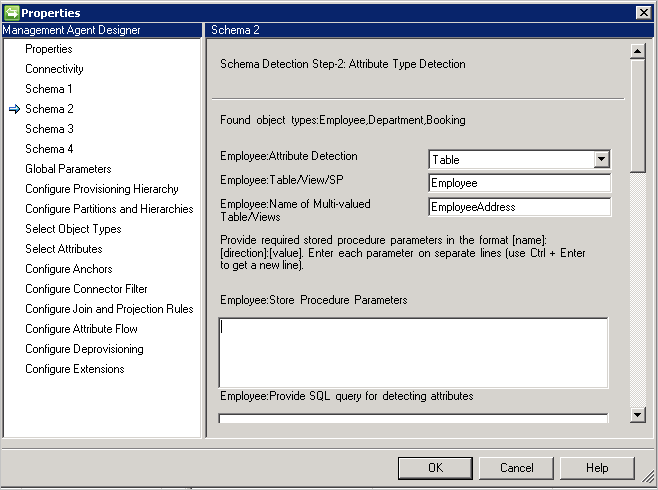
Attribute Type detection method: il connettore supporta questi metodi di rilevamento del tipo di attributo con ogni tipo di oggetto rilevato nella schermata di Schema 1.
- Table/View/Stored Procedure(Tabella/Vista/Stored procedure): specificare il nome della tabella/vista/stored procedure da usare per trovare i nomi di attributo. Se si usa una stored procedure, fornire anche i relativi parametri nel formato [Nome]:[Direzione]:[Valore]. Specificare ogni parametro su una riga separata (usare CTRL+INVIO per ottenere una nuova riga). Per rilevare i nomi degli attributi in un attributo multivalore, fornire un elenco di tabelle o viste separate da virgole. Gli scenari multivalore non sono supportati quando le tabelle padre e figlio hanno gli stessi nomi di colonna.
- SQL query (Query SQL): questa opzione consente di fornire una query SQL che restituisce una singola colonna con i nomi degli attributi, ad esempio
SELECT [Column Name] FROM TABLENAME. La colonna restituita deve essere di tipo stringa (varchar).
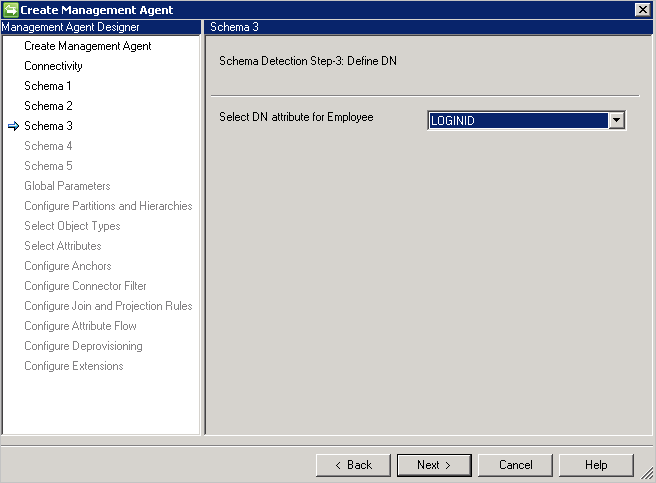
Schema 3 (definire ancoraggio e DN)
Questa pagina consente di configurare l'attributo di ancoraggio e DN per ogni tipo di oggetto rilevato. È possibile selezionare più attributi per rendere univoco l'ancoraggio.
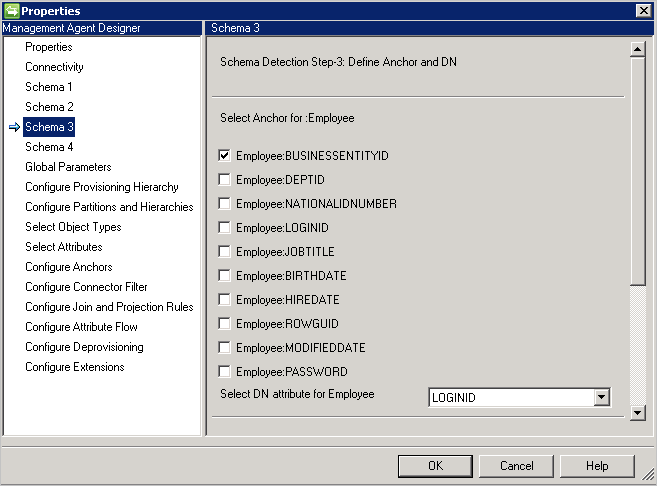
Non sono elencati gli attributi multivalore e booleani.
Lo stesso attributo non può essere usato per DN e ancoraggio, a meno che nella pagina Connectivity non sia selezionata l'opzione DN is Anchor .
Se DN is Anchor è selezionata nella pagina Connectivity, questa pagina richiede solo l'attributo DN. Questo attributo verrà usato anche come attributo di ancoraggio.
Schema 4 (definire tipo di attributo, riferimento e direzione)
Questa pagina consente di configurare il tipo di attributo, ad esempio valore integer, binario o booleano, e la direzione per ogni attributo. Tutti gli attributi della pagina Schema 2 sono elencati con i relativi attributi multivalore.
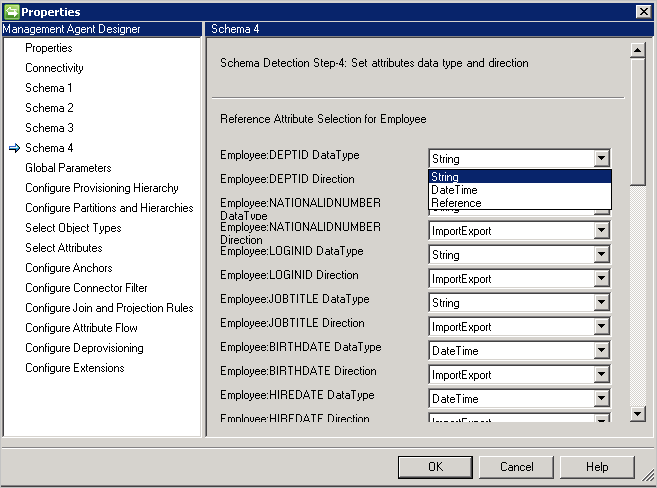
- DataType: usato per associare il tipo di attributo ai tipi noti al motore di sincronizzazione. Per impostazione predefinita, viene usato lo stesso tipo, come rilevato in SQL schema, ma DateTime e il Reference non sono facilmente rilevabili. Per questi è necessario specificare DateTime o Reference.
- Direction: è possibile impostare la direzione dell'attributo su Import, Export o ImportExport. ImportExport è il valore predefinito.
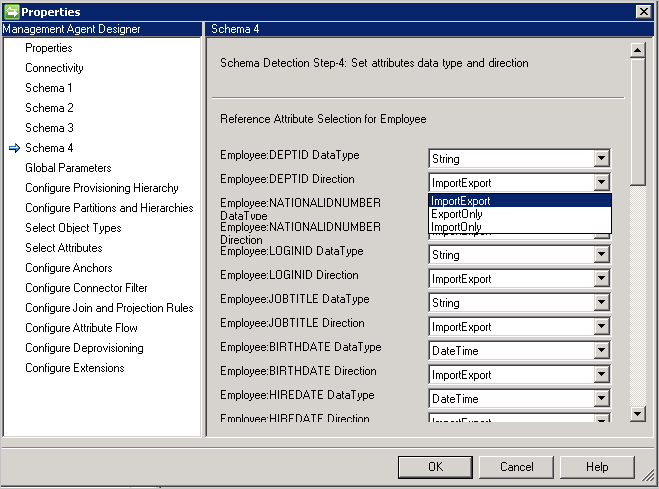
Note:
- Se un tipo di attributo non è rilevabile dal connettore, usa il tipo di dati stringa.
- Nested tables possono essere considerate tabelle di database di una colonna. Oracle archivia le righe di una tabella annidata senza un ordine particolare. Tuttavia, quando si recupera la tabella annidata in una variabile PL/SQL, alle righe vengono assegnati pedici consecutivi a partire da 1. In questo modo si avrà un accesso di tipo matrice alle singole righe.
- VARRYS non sono supportati nel connettore.
Schema 5 (definire la partizione per gli attributi di riferimento)
In questa pagina si configura, per tutti gli attributi di riferimento, a quale partizione (tipo di oggetto) fa riferimento un attributo.
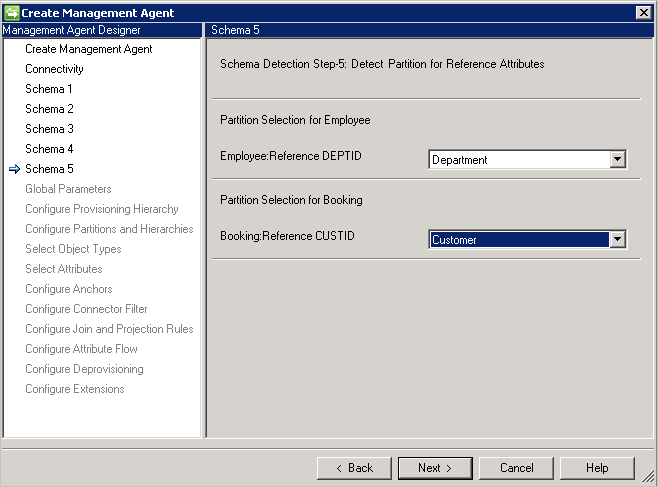
Se si usa DN is anchor(DN è Anchor) è necessario usare lo stesso tipo di oggetto da cui si fa riferimento. Non è possibile fare riferimento a un altro tipo di oggetto.
Nota
A partire dall'aggiornamento di marzo 2017 è disponibile un'opzione per "*" Quando l'opzione è selezionata, vengono importati tutti i possibili tipi di membro.
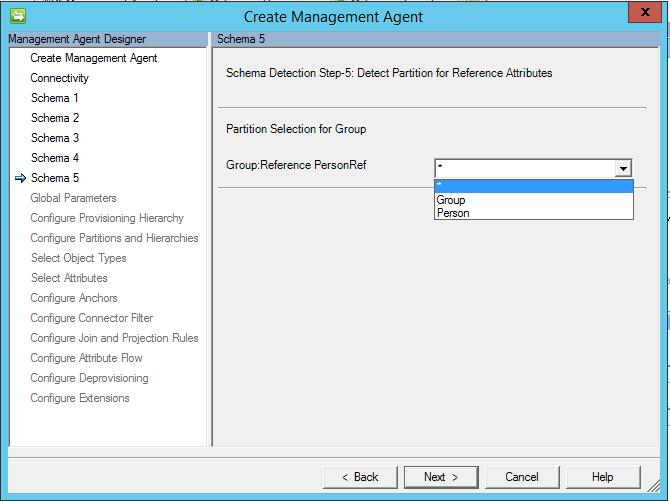
Importante
A partire da maggio 2017 l'asterisco "*", ovvero qualsiasi opzione, è stato modificato per supportare il flusso di importazione ed esportazione. Se si desidera usare questa opzione, la tabella/vista multivalore deve avere un attributo contenente il tipo di oggetto.

Se si seleziona "*", è necessario specificare anche il nome della colonna con il tipo di oggetto .
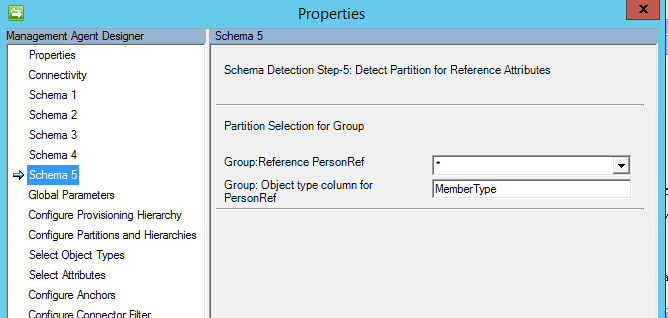
Dopo l'importazione verrà visualizzato qualcosa di simile all'immagine riportata di seguito:
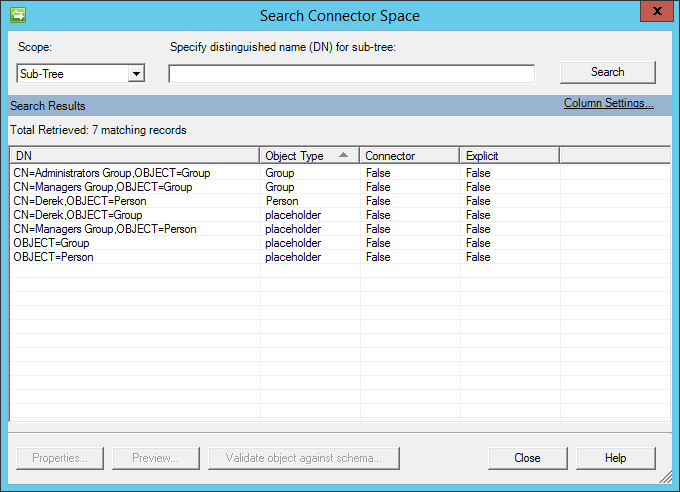
Parametri globali
La pagina Global Parameters viene usata per configurare l'importazione delta, il formato di data/ora e il metodo di password.
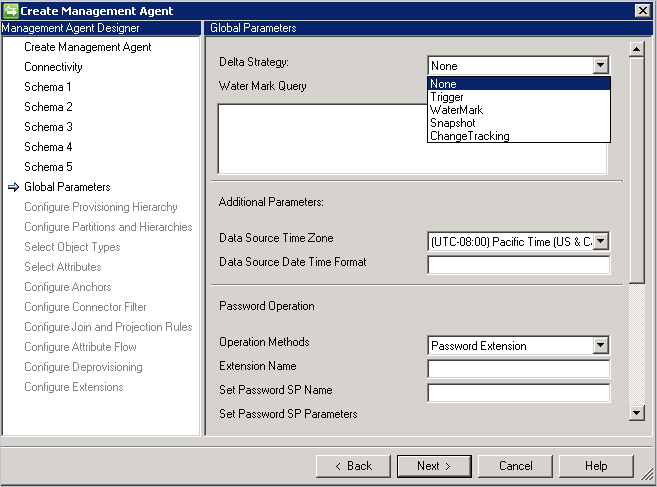
Il connettore Generic SQL supporta i seguenti metodi per l'importazione delta:
- Trigger: vedere l'articolo relativo alla generazione di visualizzazioni delta con trigger.
- Watermark(Limite): approccio generico che può essere usato con qualsiasi database. L'opzione Water Mark Query è già popolata in base al fornitore del database. In ogni tabella o visualizzazione usata deve essere presente una colonna Watermark. Questa colonna deve tenere traccia di inserimenti e aggiornamenti delle tabelle, nonché delle tabelle dipendenti (multivalore o figlio). Gli orologi tra il server di database e il servizio di sincronizzazione devono essere sincronizzati. In caso contrario, potrebbero essere omesse alcune voci nell'importazione delta.
Limitazione:- La strategia Watermark (Limite) non supporta gli oggetti eliminati.
- Snapshot(funziona solo con Microsoft SQL Server) Generating Delta Views Using Snapshots
- Change Tracking(funziona solo con Microsoft SQL Server) Informazioni sul rilevamento delle modifiche (SQL Server)
Limitazioni:- L'attributo Anchor & DN deve essere parte della chiave primaria per l'oggetto selezionato nella tabella.
- La query SQL non è supportata durante l'importazione e l'esportazione con il rilevamento delle modifiche.
Additional Parameters: specificare il fuso orario del server di database che indica dove si trova il server di database. Questo valore viene usato per supportare i diversi formati degli attributi di data e ora.
Il connettore archivia sempre data e data-ora in formato UTC. Per poter convertire correttamente la data e ora, è necessario specificare il fuso orario del server di database e il formato usato. Il formato deve essere espresso in formato .NET.
Durante l'esportazione è necessario fornire al connettore ogni attributo di data e ora in formato UTC.
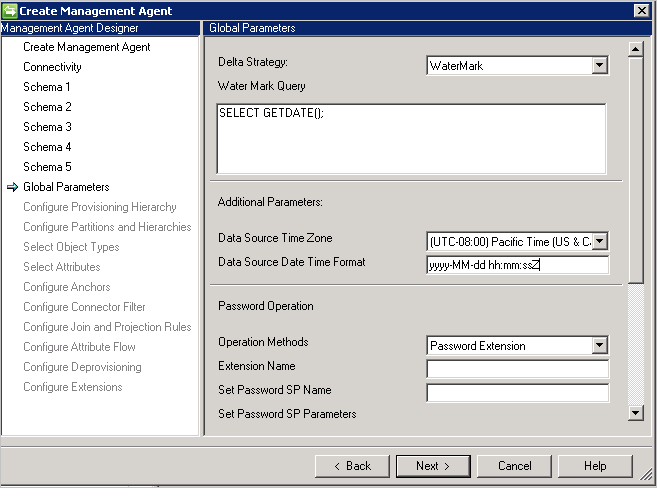
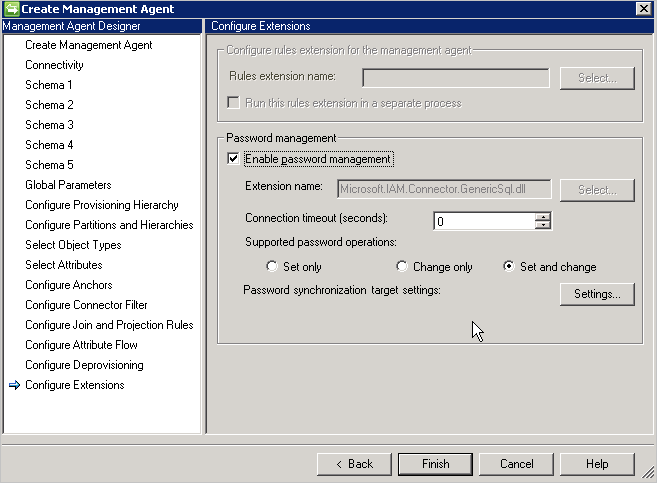
Password Configuration: il connettore fornisce funzionalità di sincronizzazione password e supporta l'impostazione e la modifica della password.
Il connettore fornisce due metodi per supportare la sincronizzazione password:
- Stored Procedure: questo metodo richiede due stored procedure per supportare l'impostazione e la modifica della password. Digitare tutti i parametri per aggiungere e modificare l'operazione di password nei parametri Set Password SP (Configura stored procedure password) e Change Password SP (Modifica stored procedure password), rispettivamente, come illustrato nell'esempio seguente.
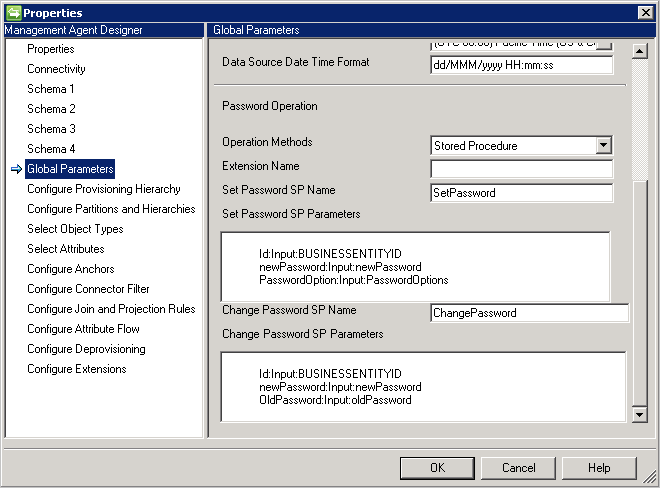
- Password Extension (Estensione password): questo metodo richiede la DLL di estensione delle password. È necessario fornire il nome della DLL di estensione che implementa l'interfaccia IMAExtensible2Password. L'assembly di estensione della password deve essere inserito nella cartella dell'estensione in modo che il connettore possa caricare la DLL in fase di esecuzione.
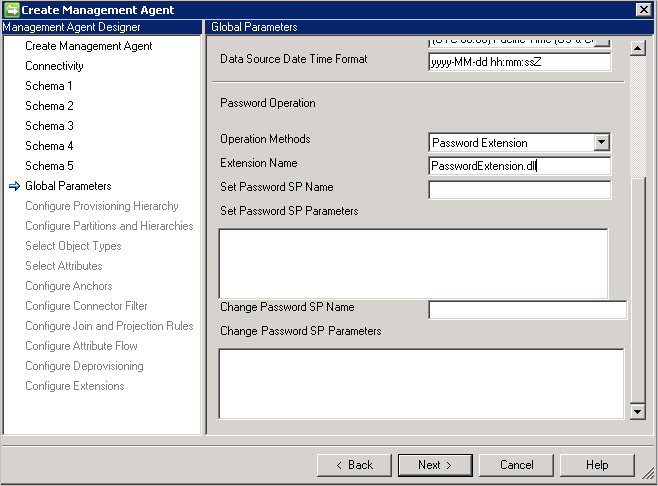
È anche necessario attivare la gestione delle password nella pagina Configure Extension .
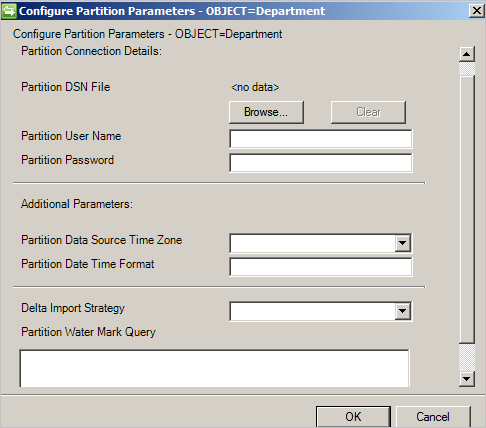
Configurare partizioni e gerarchie
Nella pagina di configurazione di partizioni e gerarchie selezionare tutti i tipi di oggetto. Ogni tipo di oggetto si trova nella propria partizione.
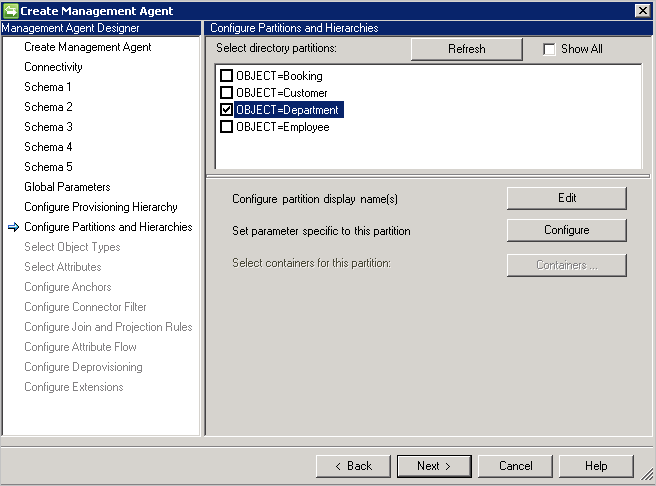
È anche possibile sostituire i valori definiti nella pagina Connectivity o Global Parameters.
Configurazione ancoraggi
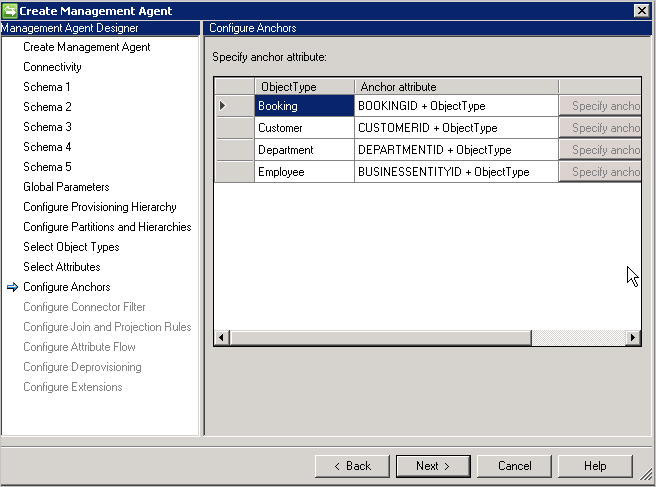
Questa pagina è di sola lettura perché l'ancoraggio è già stato definito. L'attributo di ancoraggio selezionato viene sempre aggiunto con il tipo di oggetto in modo che rimanga univoco in tutti i tipi di oggetto.
Configurare il parametro per l'esecuzione dei passaggi
Questi passaggi vengono configurati nei profili di esecuzione del connettore. Queste configurazioni eseguono l'effettiva operazione di importazione ed esportazione dei dati.
Importazione completa e delta
Il connettore Generic SQL supporta l'importazione completa e delta usando questi metodi:
- Tabella
- Vista
- Stored procedure
- Query SQL
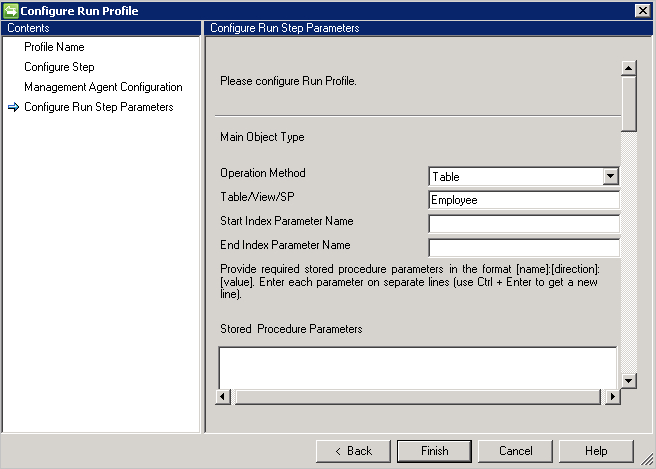
Table/View
Per importare attributi multivalore per un oggetto è necessario specificare i nomi di tabella o visualizzazione in Nome della tabella/visualizzazione multivalore e le rispettive condizioni di join in Condizione di join con la tabella padre. Se sono presenti più tabelle multivalore nell'origine dati, è possibile usare l'operatore unione per disporre di una visualizzazione singola.
Importante
L'agente di gestione SQL generico può essere usato con una sola tabella multivalore. Non inserire più nomi di tabella nel campo Nome della tabella/visualizzazione multivalore. Si tratta di una limitazione di SQL generico.
Esempio: si vuole importare l'oggetto Employee e tutti i relativi attributi multivalore. Sono presenti due tabelle denominate Employee (tabella principale) e Department (multivalore). Effettuare le operazioni seguenti:
- Digitare Employee in Table/View/SP.
- Digitare Department in Name of Multi-Valued table/views.
- Digitare la condizione di join tra Employee e Department in Join Condition (Condizione di join), ad esempio
Employee.DEPTID=Department.DepartmentID.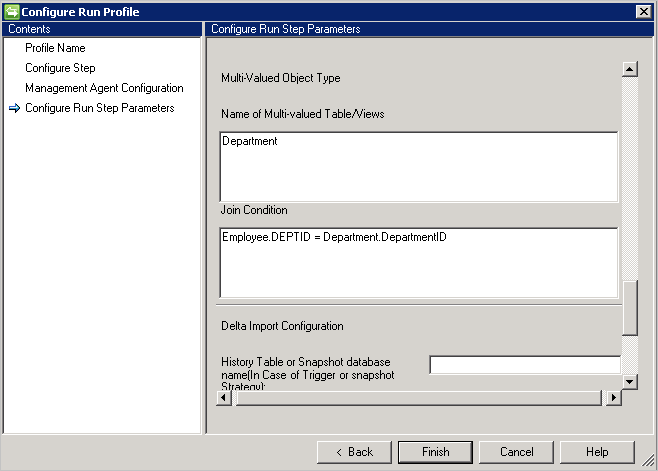
Stored procedure
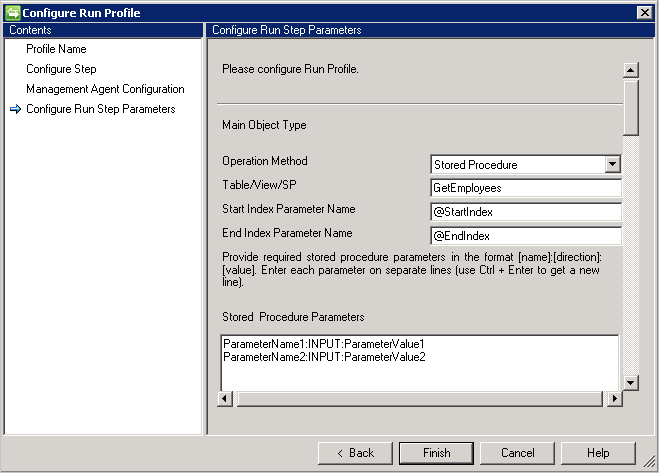
- Nel caso di una grande quantità di dati, è consigliabile implementare la paginazione con le stored procedure.
- Per consentire alla stored procedure di supportare la paginazione, è necessario fornire i valori per l'inizio e la fine dell'indice. Vedere: Paging in modo efficiente di grandi quantità di dati.
- @StartIndex e @EndIndex vengono sostituiti in fase di esecuzione con il rispettivo valore di dimensione della pagina configurato nella pagina Configure Step (Passaggio di configurazione). Ad esempio, quando il connettore recupera la prima pagina e la dimensione della pagina è impostata su 500, il valore @StartIndex sarà 1 e @EndIndex sarà 500. Questi valori vengono incrementati quando il connettore recupera le pagine successive e il valore per @StartIndex e @EndIndex viene modificato.
- Per eseguire la stored procedure con parametri, specificare i parametri nel formato
[Name]:[Direction]:[Value]. Immettere ogni parametro su una riga separata (usare CTRL+INVIO per ottenere una nuova riga). - Il connettore Generic SQL supporta anche l'operazione di importazione dai server collegati in Microsoft SQL Server. Se è necessario recuperare informazioni da una tabella in un server collegato, la tabella deve essere fornita con questo formato:
[ServerName].[Database].[Schema].[TableName] - Il connettore Generic SQL supporta solo gli oggetti che presentano una struttura simile (sia nome alias che tipo di dati) tra le informazioni sui passaggi esecuzione e il rilevamento dello schema. Se l'oggetto selezionato dallo schema e le informazioni fornite nel passaggio di esecuzione sono diverse, il connettore SQL non può supportare questo tipo di scenari.
Query SQL
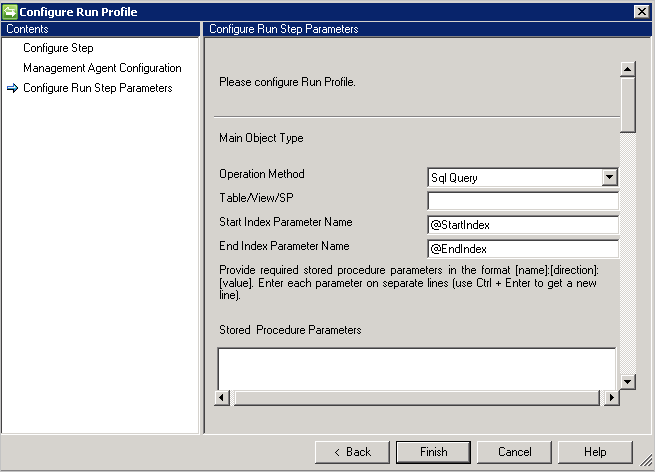
Importante
CRLF o nuovo carattere di riga funge da separatore tra più istruzioni.
Query SQL di esempio con paginazione: query non corretta, non funzionerà perché viene usato il nuovo carattere di riga:
WITH A AS
(select dense_rank() over (order by BusinessEntityID)
rownumber, BusinessEntityID, DeptID, NationalIDNumber, LoginID, JobTitle, BirthDate, MaritalStatus, HireDate, ModifiedDate, Password
from Employees
) select * from A where rownumber between @StartIndex and @EndIndex
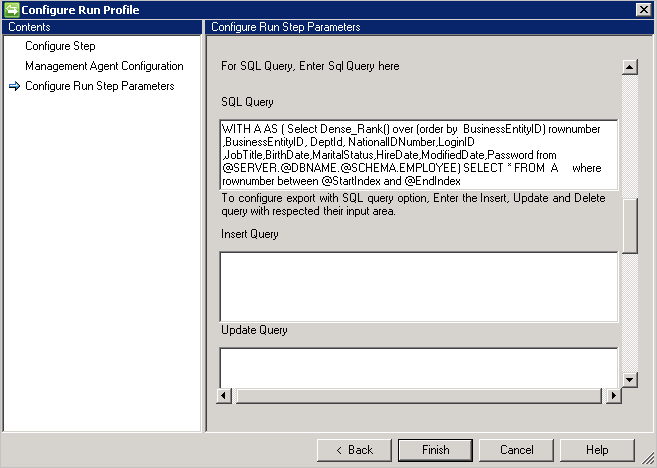
Query SQL di esempio con paginazione: query corretta:
WITH A AS (select dense_rank() over (order by BusinessEntityID) rownumber, BusinessEntityID, DeptID, NationalIDNumber, LoginID, JobTitle, BirthDate, MaritalStatus, HireDate, ModifiedDate, Password from Employees) select * from A where rownumber between @StartIndex and @EndIndex
- Le query con più set di risultati non sono supportate.
- La query SQL supporta l'impaginazione e fornisce l'indice iniziale e l'indice finale come variabile per supportare la paginazione.
Importazione delta
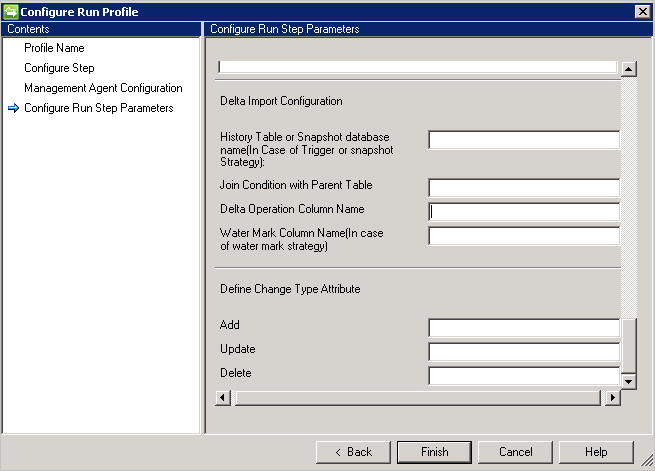
La configurazione dell'importazione differenziale richiede un numero maggiore di operazioni di configurazione rispetto all'importazione completa.
- Se si sceglie l'approccio Trigger o Snapshot per rilevare le modifiche differenziali, specificare la tabella della cronologia o il database di snapshot nella casella History Table or Snapshot database name (Nome della tabella di cronologia o del database di snapshot).
- È necessario fornire anche una condizione di join tra la tabella della cronologia o il database di snapshot, ad esempio
Employee.ID=History.EmployeeID - Per tenere traccia della transazione nella tabella padre dalla tabella della cronologia, è necessario fornire il nome della colonna che contiene le informazioni sull'operazione (aggiunta/aggiornamento/eliminazione).
- Se si sceglie Watermark (Limite) per tenere traccia delle modifiche differenziali, è necessario fornire il nome della colonna che contiene le informazioni sull'operazione in Water Mark Column Name(Nome colonna limite).
- La colonna Change Type Attribute è necessaria per il tipo di modifica. Questa colonna è associata a una modifica che si verifica nella tabella primaria o nella tabella multivalore per un tipo di modifica nella visualizzazione delta. Questa colonna può contenere il tipo di modifica Modify_Attribute per la modifica a livello di attributo o un tipo di modifica Add, Modify o Delete per un tipo di modifica a livello di oggetto. Se è diverso dal valore predefinito per l'aggiunta, la modifica o l'eliminazione, l'utente può definire i valori usando questa opzione.
Esportazione
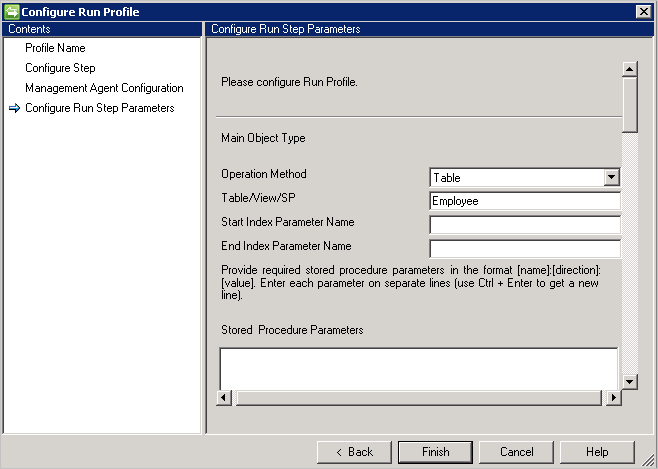
Il connettore Generic SQL supporta l'esportazione tramite quattro metodi supportati, ad esempio:
- Tabella
- Vista
- Stored procedure
- Query SQL
Table/View
(Tabella/Vista) Se si sceglie l'opzione Table/View (Tabella/Vista), il connettore genera le rispettive query per eseguire l'esportazione.
Stored procedure
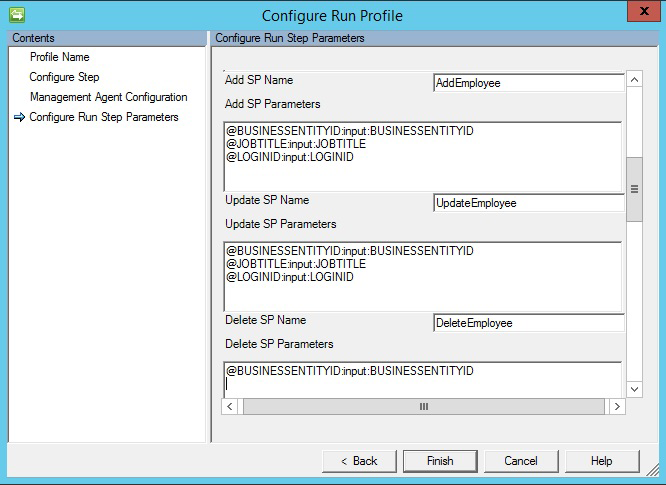
Se si sceglie l'opzione relativa alle stored procedure, l'esportazione richiede tre diverse stored procedure per eseguire le operazioni di inserimento/aggiornamento/eliminazione.
- Add SP Name(Aggiungi nome stored procedure): questa stored procedure viene eseguita se un oggetto qualsiasi perviene al connettore per l'inserimento nella rispettiva tabella.
- Update SP Name(Aggiorna nome stored procedure): questa stored procedure viene eseguita se un oggetto qualsiasi perviene al connettore per l'aggiornamento nella rispettiva tabella.
- Delete SP Name(Elimina nome stored procedure): questa stored procedure viene eseguita se un oggetto qualsiasi perviene al connettore per l'eliminazione nella rispettiva tabella.
- L'attributo selezionato nello schema viene usato come valore di parametro per la stored procedure. Ad esempio,
@EmployeeName: INPUT: EmployeeName(EmployeeName viene selezionato nello schema del connettore e il connettore sostituisce il rispettivo valore durante l'esportazione) - Per eseguire la stored procedure con parametri, specificare i parametri nel formato
[Name]:[Direction]:[Value]. Immettere ogni parametro su una riga separata (usare CTRL+INVIO per ottenere una nuova riga).
SQL query

Se si sceglie l'opzione SQL query, l'esportazione richiede tre diverse query per eseguire le operazioni di inserimento/aggiornamento/eliminazione.
- Insert Query(Inserisci query): questa query viene eseguita se un oggetto qualsiasi perviene al connettore per l'inserimento nella rispettiva tabella.
- Update Query(Aggiorna query): questa query viene eseguita se un oggetto qualsiasi perviene al connettore per l'aggiornamento nella rispettiva tabella.
- Delete Query(Elimina query): questa query viene eseguita se un oggetto qualsiasi perviene al connettore per l'eliminazione dalla rispettiva tabella.
- L'attributo selezionato nello schema viene usato come valore di parametro per la query, ad esempio
Insert into Employee (ID, Name) Values (@ID, @EmployeeName)
Importante
CRLF o nuovo carattere di riga funge da separatore tra più istruzioni.
Esempio di query SQL di aggiornamento in più passaggi: il nuovo carattere di riga viene usato per separare le istruzioni SQL:
update Employee set jobTitle=@JOBTITLE where BusinessEntityID=@BUSINESSENTITYID
insert into ChangeLog VALUES (@BUSINESSENTITYID)
Risoluzione dei problemi
- Per informazioni su come abilitare la registrazione per risolvere i problemi relativi al connettore, vedere l'articolo relativo a come abilitare la traccia ETW per i connettori.