Aggiornamento incrementale avanzato e dati in tempo reale con l'endpoint XMLA
I modelli semantici in una capacità Premium con l'endpoint XMLA abilitato per le operazioni di lettura/scrittura consentono distribuzioni più avanzate di aggiornamento, gestione delle partizioni e metadati solo tramite strumenti, script e supporto API. Inoltre, le operazioni di aggiornamento tramite l'endpoint XMLA non sono limitate a 48 aggiornamenti al giorno e il limite di tempo di aggiornamento pianificato non viene imposto.
Partizioni
Le partizioni di tabella del modello semantico non sono visibili e non possono essere gestite usando Power BI Desktop o il servizio Power BI. Per i modelli in un'area di lavoro assegnata a una capacità Premium, le partizioni possono essere gestite tramite l'endpoint XMLA usando strumenti come SQL Server Management Studio (SSMS), l'editor tabulare open source, con script con TMSL (Tabular Model Scripting Language) e a livello di codice con il modello a oggetti tabulare (TOM).
Quando si pubblica un modello per la prima volta nel servizio Power BI, ogni tabella nel nuovo modello ha una partizione. Per le tabelle senza criteri di aggiornamento incrementale, tale partizione contiene tutte le righe di dati per tale tabella, a meno che non siano stati applicati filtri. Per le tabelle con criteri di aggiornamento incrementale, tale partizione iniziale esiste solo perché Power BI non ha ancora applicato i criteri. La partizione iniziale in Power BI Desktop viene configurata quando si definisce il filtro di intervallo di data/ora per la tabella in base ai parametri RangeStart e RangeEnd e qualsiasi altro filtro applicato nell'editor di Power Query. Questa partizione iniziale contiene solo le righe di dati che soddisfano i criteri di filtro.
Quando si esegue la prima operazione di aggiornamento, le tabelle senza criteri di aggiornamento incrementale aggiornano tutte le righe contenute nella singola partizione predefinita della tabella. Per le tabelle con criteri di aggiornamento incrementale, le partizioni di aggiornamento e cronologia vengono create automaticamente e le righe vengono caricate in base alla data/ora per ogni riga. Se i criteri di aggiornamento incrementale includono il recupero dei dati in tempo reale, Power BI aggiunge anche una partizione DirectQuery alla tabella.
Questa prima operazione di aggiornamento può richiedere molto tempo a seconda della quantità di dati che devono essere caricati dall'origine dati. La complessità del modello può anche essere un fattore significativo perché le operazioni di aggiornamento devono eseguire più elaborazione e ricalcolo. Questa operazione può essere avviata. Per altre informazioni, vedere Impedire i timeout durante l'aggiornamento completo iniziale.
Le partizioni vengono create e denominate in base alla granularità del periodo: anni, trimestri, mesi e giorni. Le partizioni più recenti, le partizioni di aggiornamento, contengono righe nel periodo di aggiornamento specificato nei criteri. Le partizioni cronologiche contengono righe per periodo completo fino al periodo di aggiornamento. Se il tempo reale è abilitato, una partizione DirectQuery preleva tutte le modifiche apportate ai dati che si sono verificate dopo la data di fine del periodo di aggiornamento. La granularità per le partizioni di aggiornamento e cronologia dipende dai periodi di aggiornamento e cronologici (archivio) scelti durante la definizione dei criteri.
Ad esempio, se la data odierna è il 2 febbraio 2021 e la tabella FactInternetSales nell'origine dati contiene righe fino a oggi, se i criteri specificano di includere modifiche in tempo reale, aggiornare le righe nell'ultimo periodo di aggiornamento di un giorno e archiviare le righe nell'ultimo periodo cronologico di tre anni. Con la prima operazione di aggiornamento viene quindi creata una partizione DirectQuery per le modifiche in futuro, viene creata una nuova partizione di importazione per le righe di oggi, viene creata una partizione cronologica per ieri, un periodo di giorni intero, 1 febbraio 2021. Viene creata una partizione cronologica per l'intero periodo mensile precedente (gennaio 2021), viene creata una partizione cronologica per l'intero periodo dell'anno precedente (2020) e le partizioni cronologiche per i periodi interi del 2019 e del 2018 vengono create. Non vengono create partizioni intere trimestrali perché non è ancora stato completato il primo trimestre del 2021.
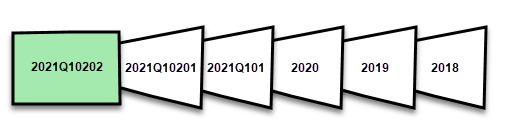
Con ogni operazione di aggiornamento, vengono aggiornate solo le partizioni del periodo di aggiornamento e il filtro data della partizione DirectQuery viene aggiornato in modo da includere solo le modifiche che si verificano dopo il periodo di aggiornamento corrente. Viene creata una nuova partizione di aggiornamento per le nuove righe con una nuova data/ora entro il periodo di aggiornamento aggiornato e le righe esistenti con data/ora già all'interno delle partizioni esistenti nel periodo di aggiornamento vengono aggiornate con gli update. Le righe con data/ora precedenti al periodo di aggiornamento non vengono più aggiornate.
Al termine dei periodi interi, le partizioni vengono unite. Ad esempio, se nel criterio viene specificato un periodo di aggiornamento di un giorno e un periodo di archivio cronologico di tre anni, il primo giorno del mese, tutte le partizioni giornaliere per il mese precedente vengono unite in una partizione mensile. Il primo giorno di un nuovo trimestre, tutte e tre le partizioni del mese precedente vengono unite in una partizione trimestrale. Il primo giorno di un nuovo anno tutte e quattro le partizioni trimestrali precedenti vengono unite in una partizione annuale.
Un modello mantiene sempre le partizioni per l'intero periodo di archiviazione cronologico e le partizioni di interi periodi fino al periodo di aggiornamento corrente. Nell'esempio vengono conservati tre anni completi di dati cronologici nelle partizioni per il 2018, 2019, 2020 e anche le partizioni per il periodo mensile 2021Q101, il periodo del giorno 2021Q10201 e la partizione del periodo di aggiornamento del giorno corrente. Poiché l'esempio conserva i dati cronologici per tre anni, la partizione 2018 viene mantenuta fino al primo aggiornamento il 1° gennaio 2022.
Con l'aggiornamento incrementale di Power BI e i dati in tempo reale, il servizio gestisce automaticamente la gestione delle partizioni in base ai criteri. Anche se il servizio può gestire automaticamente tutta la gestione delle partizioni, usando gli strumenti tramite l'endpoint XMLA, è possibile aggiornare in modo selettivo le partizioni singolarmente, in sequenza o in parallelo.
Gestione dell'aggiornamento con SQL Server Management Studio
SQL Server Management Studio (SSMS) può essere usato per visualizzare e gestire le partizioni create dall'applicazione dei criteri di aggiornamento incrementale. Usando SSMS, ad esempio, è possibile aggiornare una partizione cronologica specifica non nel periodo di aggiornamento incrementale per eseguire un aggiornamento datato senza dover aggiornare tutti i dati cronologici. SSMS può essere usato anche durante il bootstrap per caricare dati cronologici per modelli di grandi dimensioni aggiungendo/aggiornando in modo incrementale partizioni cronologiche in batch.
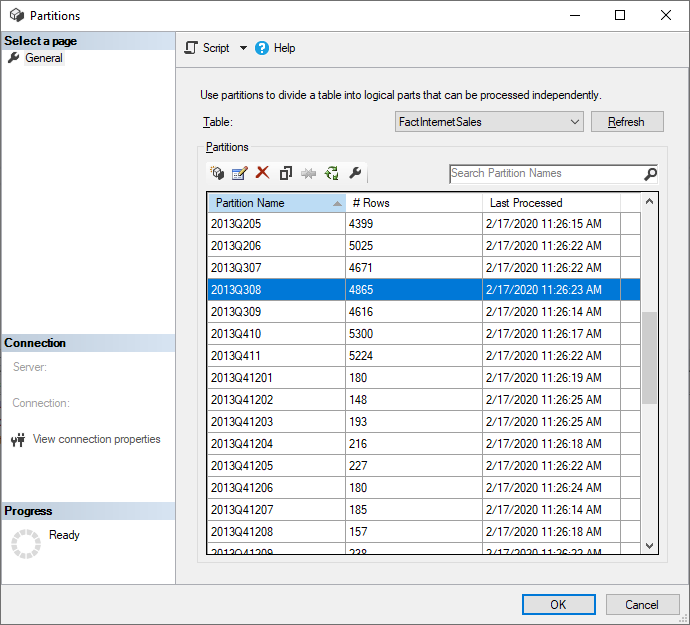
Eseguire l'override del comportamento dell'aggiornamento incrementale
Con SSMS, è anche possibile avere maggiore controllo su come richiamare gli aggiornamenti usando il linguaggio di scripting del modello tabulare e il modello a oggetti tabulari. Ad esempio, in Esplora oggetti di SSMS fare clic con il pulsante destro del mouse su una tabella e quindi scegliere l'opzione di menu Elabora tabella e quindi selezionare il pulsante Script per generare un comando di aggiornamento TMSL.
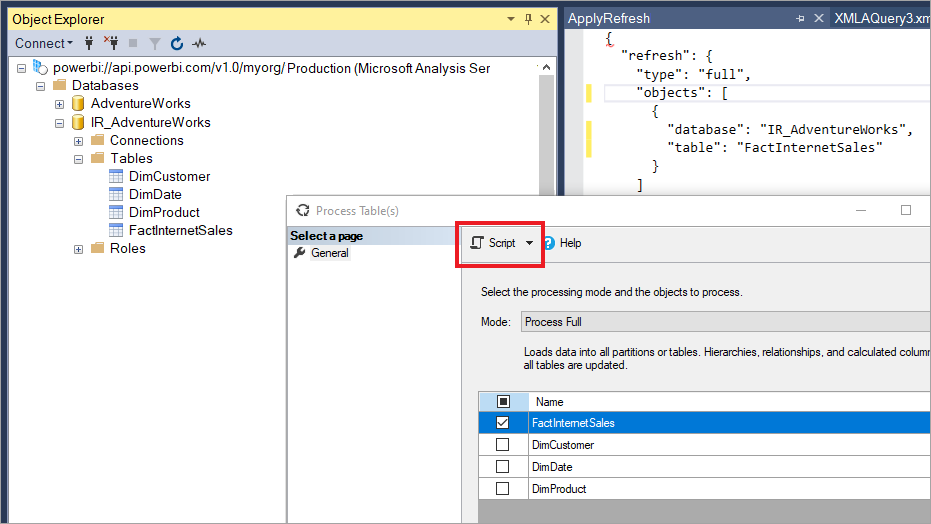
Questi parametri possono essere usati con il comando TMSL refresh per eseguire l'override del comportamento di aggiornamento incrementale predefinito:
applyRefreshPolicy. Se per una tabella è definito un criterio di aggiornamento incrementale,
applyRefreshPolicydetermina se il criterio viene applicato o meno. Se il criterio non viene applicato, un'operazione completa del processo lascia invariate le definizioni di partizione e tutte le partizioni nella tabella vengono completamente aggiornate. Il valore predefinito è true.effectiveDate. Se viene applicato un criterio di aggiornamento incrementale, è necessario conoscere la data corrente per determinare gli intervalli di finestre in sequenza per i periodi di aggiornamento incrementale e cronologici. Il parametro
effectiveDateconsente di eseguire l'override della data corrente. Questo parametro è utile per gli scenari di test, demo e aziendali in cui i dati vengono aggiornati in modo incrementale fino a una data precedente o futura (ad esempio, per i budget previsti per il futuro). Il valore predefinito è la data corrente.
{
"refresh": {
"type": "full",
"applyRefreshPolicy": true,
"effectiveDate": "12/31/2013",
"objects": [
{
"database": "IR_AdventureWorks",
"table": "FactInternetSales"
}
]
}
}
Per altre informazioni sull'override del comportamento di aggiornamento incrementale predefinito con TMSL, vedere Comando refresh.
Garantire prestazioni ottimali
Con ogni operazione di aggiornamento, il servizio Power BI potrebbe inviare query di inizializzazione all'origine dati per ogni partizione di aggiornamento incrementale. È possibile migliorare le prestazioni di aggiornamento incrementale riducendo il numero di query di inizializzazione assicurando la configurazione seguente:
- La tabella per cui si configura l'aggiornamento incrementale deve ottenere dati da una singola origine dati. Se la tabella ottiene dati da più origini dati, il numero di query inviate dal servizio per ogni operazione di aggiornamento viene moltiplicato per il numero di origini dati, riducendo potenzialmente le prestazioni di aggiornamento. Verificare che la query per la tabella di aggiornamento incrementale sia per una singola origine dati.
- Per le soluzioni con aggiornamento incrementale delle partizioni di importazione e dei dati in tempo reale con Direct Query, tutte le partizioni devono eseguire query sui dati da una singola origine dati.
- Se i requisiti di sicurezza consentono, configurare l'impostazione Livello di privacy dell'origine dati su Organizzazione o Pubblico. Per impostazione predefinita, il livello di privacy è Privato, tuttavia questo livello può impedire che i dati vengano scambiati con altre origini cloud. Per impostare il livello di privacy, selezionare il menu Altre opzioni e quindi scegliere Impostazioni>Credenziali origine dati>Modifica credenziali>Livello privacy per questa origine dati. Se il livello di privacy è impostato nel modello di Power BI Desktop prima della pubblicazione nel servizio, non viene trasferito al servizio durante la pubblicazione. È comunque necessario impostarlo nelle impostazioni del modello semantico nel servizio. Per altre informazioni, vedere Livelli di privacy.
- Se si usa un gateway dati locale, assicurarsi di usare la versione 3000.77.3 o successiva.
Impedire timeout all'aggiornamento completo iniziale
Dopo la pubblicazione nel servizio Power BI, l'operazione di aggiornamento completo iniziale per il modello crea partizioni per la tabella di aggiornamento incrementale, carica ed elabora i dati cronologici per l'intero periodo definito nei criteri di aggiornamento incrementale. Per alcuni modelli che caricano ed elaborano grandi quantità di dati, la quantità di tempo impiegato dall'operazione di aggiornamento iniziale può superare il limite di tempo di aggiornamento imposto dal servizio o da un limite di tempo di query imposto dall'origine dati.
Il bootstrap dell'operazione di aggiornamento iniziale consente al servizio di creare oggetti di partizione per la tabella di aggiornamento incrementale, ma non di caricare ed elaborare i dati cronologici in una delle partizioni. SSMS viene quindi usato per elaborare in modo selettivo le partizioni. A seconda della quantità di dati da caricare per ogni partizione, è possibile elaborare ogni partizione in sequenza o in batch di piccole dimensioni per ridurre il rischio che una o più partizioni causi un timeout. I metodi seguenti funzionano per qualsiasi origine dati.
Applicare criteri di aggiornamento
Lo strumento Editor tabulare 2 open source offre un modo semplice per eseguire il bootstrap di un'operazione di aggiornamento iniziale. Dopo la pubblicazione di un modello con un criterio di aggiornamento incrementale definito da Power BI Desktop al servizio, connettersi al modello usando l'endpoint XMLA in modalità lettura/scrittura. Eseguire Applica criteri di aggiornamento nella tabella di aggiornamento incrementale. Con solo i criteri applicati, le partizioni vengono create ma non vengono caricati dati. Connettersi quindi con SSMS per aggiornare le partizioni in sequenza o in batch per caricare ed elaborare i dati. Per altre informazioni, vedere Aggiornamento incrementale nella documentazione dell'editor tabulare.
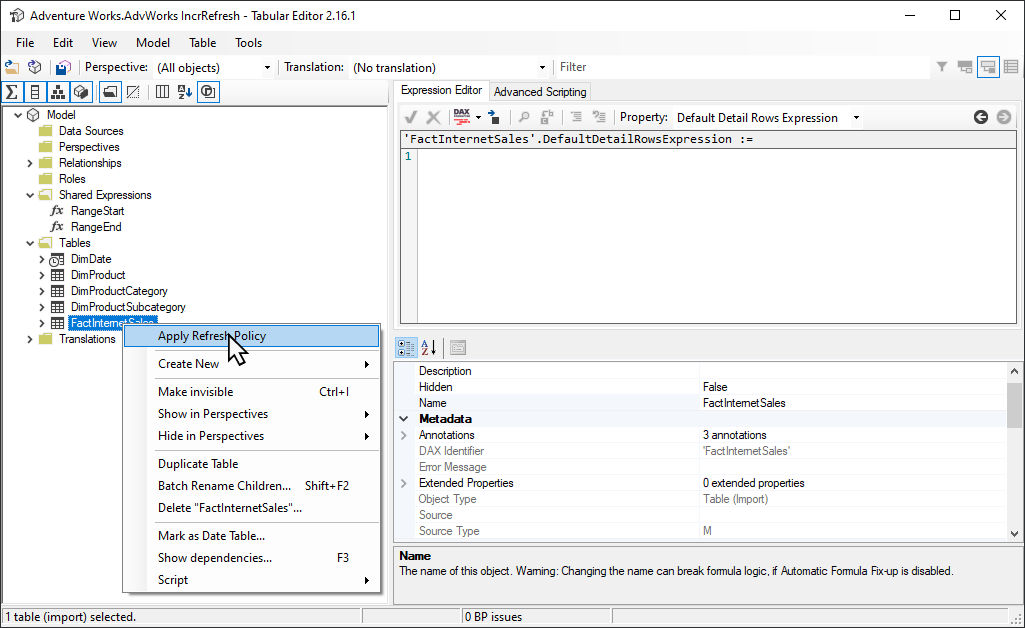
Filtro di Power Query per partizioni vuote
Prima di pubblicare il modello nel servizio, nell'editor di Power Query aggiungere un altro filtro alla colonna ProductKey che filtra qualsiasi valore diverso da 0, in modo efficace o filtrando tutti i dati dalla tabella FactInternetSales.
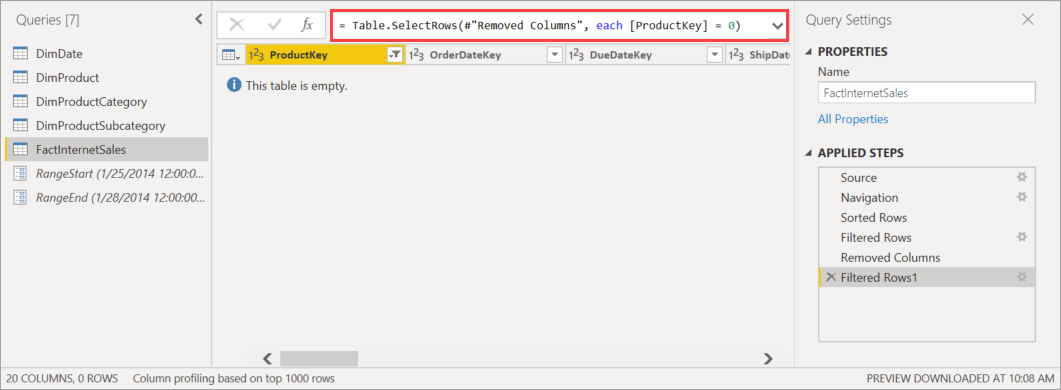
Dopo aver selezionato Chiudi e applica nell'editor di Power Query, definendo i criteri di aggiornamento incrementale e salvando il modello, il modello viene pubblicato nel servizio. Dal servizio, l'operazione di aggiornamento iniziale viene eseguita nel modello. Le partizioni per la tabella FactInternetSales vengono create in base ai criteri, ma non vengono caricati ed elaborati dati perché tutti i dati vengono filtrati.
Al termine dell'operazione di aggiornamento iniziale, nell'editor di Power Query l'altro filtro sulla colonna ProductKey viene rimosso. Dopo aver selezionato Chiudi e applica nell'editor di Power Query e aver salvato il modello, il modello non viene nuovamente pubblicato. Se il modello viene nuovamente pubblicato, sovrascrive le impostazioni dei criteri di aggiornamento incrementale e forza un aggiornamento completo sul modello quando viene eseguita un'operazione di aggiornamento successiva dal servizio. Eseguire invece una distribuzione di soli metadati usando Application Lifecycle Management (ALM) Toolkit che rimuove il filtro sulla colonna ProductKey dal modello. SSMS può quindi essere usato per elaborare in modo selettivo le partizioni. Quando tutte le partizioni sono state elaborate completamente, includendo un ricalcolo di processo in tutte le partizioni, da SSMS, le successive operazioni di aggiornamento sul modello dal servizio aggiornano solo le partizioni di aggiornamento incrementale.
Suggerimento
Assicurarsi di consultare video, blog e altro ancora forniti dalla community di esperti di BI di Power BI.
Per altre informazioni sull'elaborazione di tabelle e partizioni da SSMS, vedere Elaborare database, tabelle o partizioni (Analysis Services). Per altre informazioni sull'elaborazione di modelli, tabelle e partizioni tramite TMSL, vedere Comando refresh (TMSL).
Query personalizzate per le modifiche dei dati rilevate
TMSL e TOM possono essere usati per eseguire l'override del comportamento delle modifiche ai dati rilevate. Questo metodo non solo può essere usato per evitare di rendere persistente l'ultima colonna di aggiornamento nella cache in memoria, ma può abilitare scenari in cui una tabella di configurazione o istruzioni viene preparata dai processi di estrazione, trasformazione e caricamento (ETL) per contrassegnare solo le partizioni che devono essere aggiornate. Con questo metodo è possibile creare un processo di aggiornamento incrementale più efficiente in cui vengono aggiornati solo i periodi necessari, indipendentemente dal tempo trascorso dall'aggiornamento dei dati.
pollingExpression deve essere un'espressione M leggera o un nome di un'altra query M. Deve restituire un valore scalare ed essere eseguita per ogni partizione. Se il valore restituito è diverso rispetto all'ultima esecuzione di un aggiornamento incrementale, la partizione viene contrassegnata per l'elaborazione completa.
Nell'esempio seguente vengono illustrati tutti i 120 mesi del periodo cronologico per le modifiche di cui è stato eseguito il backup. Se si specificano 120 mesi invece di 10 anni, la compressione dei dati potrebbe non essere altrettanto efficiente, ma evita di dover aggiornare un intero anno cronologico, che sarebbe più costoso quando un mese sarebbe sufficiente per una modifica retrodatata.
"refreshPolicy": {
"policyType": "basic",
"rollingWindowGranularity": "month",
"rollingWindowPeriods": 120,
"incrementalGranularity": "month",
"incrementalPeriods": 120,
"pollingExpression": "<M expression or name of custom polling query>",
"sourceExpression": [
"let ..."
]
}
Suggerimento
Assicurarsi di consultare video, blog e altro ancora forniti dalla community di esperti di BI di Power BI.
Distribuzione di soli metadati
Quando si pubblica una nuova versione di un file con estensione PBIX da Power BI Desktop in un'area di lavoro, se esiste già un modello con lo stesso nome, viene richiesto di sostituire il modello esistente.
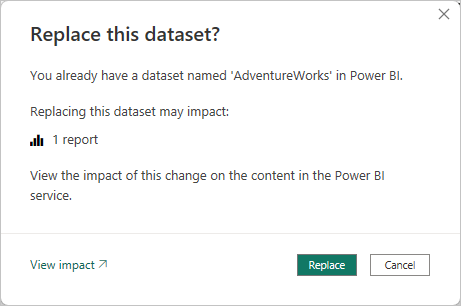
In alcuni casi, potrebbe non essere necessario sostituire il modello, in particolare con l'aggiornamento incrementale. Il modello in Power BI Desktop potrebbe essere molto più piccolo di quello nel servizio Power BI. Se il modello nel servizio Power BI ha un criterio di aggiornamento incrementale applicato, potrebbe avere diversi anni di dati cronologici che andranno persi se il modello viene sostituito. L'aggiornamento di tutti i dati cronologici può richiedere ore e causare tempo di inattività del sistema per gli utenti.
È invece preferibile eseguire solo una distribuzione dei metadati, che consente la distribuzione di nuovi oggetti senza perdere i dati cronologici. Ad esempio, se sono state aggiunte alcune misure, è possibile distribuire solo le nuove misure senza dover aggiornare i dati, risparmiando tempo.
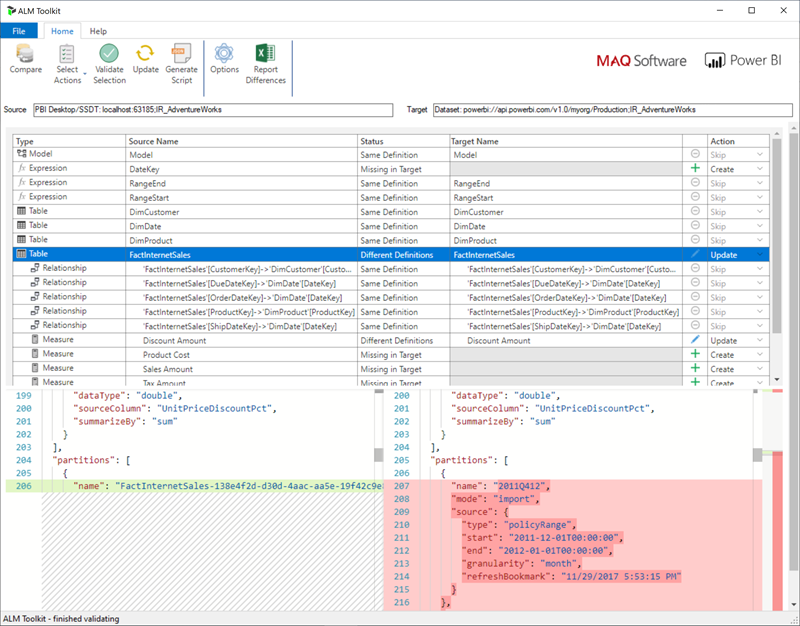
Per le aree di lavoro assegnate a una capacità Premium configurata per la lettura/scrittura dell'endpoint XMLA, gli strumenti compatibili abilitano solo la distribuzione dei metadati. Per eseguire la distribuzione dei soli metadati è ad esempio possibile usare ALM Toolkit, uno strumento di confronto di schemi per i modelli di Power BI.
Scaricare e installare la versione più recente di ALM Toolkit dal repository Git di Analysis Services. Le linee guida dettagliate sull'uso di ALM Toolkit non sono incluse nella documentazione Microsoft. I collegamenti alla documentazione di ALM Toolkit e le informazioni sul supporto sono disponibili nella barra multifunzione della Guida. Per eseguire una distribuzione solo dei metadati, eseguire un confronto e selezionare l'istanza di Power BI Desktop in esecuzione come origine e il modello esistente nel servizio Power BI come destinazione. Prendere in considerazione le differenze visualizzate e ignorare l'aggiornamento della tabella con partizioni con aggiornamento incrementale. In alternativa, nella finestra di dialogo Opzioni mantenere le partizioni per gli aggiornamenti delle tabelle. Convalidare la selezione per garantire l'integrità del modello di destinazione e quindi procedere con l'aggiornamento.
Aggiunta di criteri di aggiornamento incrementale e dati in tempo reale a livello di codice
È anche possibile usare TMSL e TOM per aggiungere un criterio di aggiornamento incrementale a un modello esistente tramite l'endpoint XMLA.
Nota
Per evitare problemi di compatibilità, assicurarsi di usare la versione più recente delle librerie client di Analysis Services. Ad esempio, per usare i criteri ibridi, la versione deve essere 19.27.1.8 o successiva.
Il processo include i passaggi seguenti:
Verificare che il modello di destinazione abbia il livello di compatibilità minimo richiesto. In SSMS fare clic con il pulsante destro del mouse su [nome modello]>Proprietà>Livello di compatibilità. Per aumentare il livello di compatibilità, usare uno script TMSL createOrReplace oppure controllare il codice di esempio TOM seguente per un esempio.
a. Import policy - 1550 b. Hybrid policy - 1565Aggiungere i parametri
RangeStarteRangeEndalle espressioni del modello. Se necessario, aggiungere anche una funzione per convertire i valori di data/ora in chiavi data.Definire un oggetto
RefreshPolicycon l'archiviazione desiderata (finestra in sequenza) e i periodi di aggiornamento incrementale, nonché un'espressione di origine che filtra la tabella di destinazione in base ai parametriRangeStarteRangeEnd. Impostare la modalità dei criteri di aggiornamento su Importa o Ibrido a seconda dei requisiti dei dati in tempo reale. L'ambiente ibrido fa sì che Power BI aggiunga una partizione DirectQuery alla tabella per recuperare le modifiche più recenti dall'origine dati che si è verificata dopo l'ora dell'ultimo aggiornamento.Aggiungere i criteri di aggiornamento alla tabella ed eseguire un aggiornamento completo in modo che Power BI partizioni la tabella in base ai requisiti.
L'esempio di codice seguente illustra come eseguire i passaggi precedenti usando TOM. Per usare questo esempio così come è, è necessario disporre di una copia per il database AdventureWorksDW e importare la tabella FactInternetSales in un modello. L'esempio di codice presuppone che i parametri RangeStart e RangeEnd e la funzione DateKey non esistano nel modello. È sufficiente importare la tabella FactInternetSales e pubblicare il modello in un'area di lavoro in Power BI Premium. Aggiornare quindi workspaceUrl in modo che l'esempio di codice possa connettersi al modello. Aggiornare qualsiasi altra riga di codice in base alle esigenze.
using System;
using TOM = Microsoft.AnalysisServices.Tabular;
namespace Hybrid_Tables
{
class Program
{
static string workspaceUrl = "<Enter your Workspace URL here>";
static string databaseName = "AdventureWorks";
static string tableName = "FactInternetSales";
static void Main(string[] args)
{
using (var server = new TOM.Server())
{
// Connect to the dataset.
server.Connect(workspaceUrl);
TOM.Database database = server.Databases.FindByName(databaseName);
if (database == null)
{
throw new ApplicationException("Database cannot be found!");
}
if(database.CompatibilityLevel < 1565)
{
database.CompatibilityLevel = 1565;
database.Update();
}
TOM.Model model = database.Model;
// Add RangeStart, RangeEnd, and DateKey function.
model.Expressions.Add(new TOM.NamedExpression {
Name = "RangeStart",
Kind = TOM.ExpressionKind.M,
Expression = "#datetime(2021, 12, 30, 0, 0, 0) meta [IsParameterQuery=true, Type=\"DateTime\", IsParameterQueryRequired=true]"
});
model.Expressions.Add(new TOM.NamedExpression
{
Name = "RangeEnd",
Kind = TOM.ExpressionKind.M,
Expression = "#datetime(2021, 12, 31, 0, 0, 0) meta [IsParameterQuery=true, Type=\"DateTime\", IsParameterQueryRequired=true]"
});
model.Expressions.Add(new TOM.NamedExpression
{
Name = "DateKey",
Kind = TOM.ExpressionKind.M,
Expression =
"let\n" +
" Source = (x as datetime) => Date.Year(x)*10000 + Date.Month(x)*100 + Date.Day(x)\n" +
"in\n" +
" Source"
});
// Apply a RefreshPolicy with Real-Time to the target table.
TOM.Table salesTable = model.Tables[tableName];
TOM.RefreshPolicy hybridPolicy = new TOM.BasicRefreshPolicy
{
Mode = TOM.RefreshPolicyMode.Hybrid,
IncrementalPeriodsOffset = -1,
RollingWindowPeriods = 1,
RollingWindowGranularity = TOM.RefreshGranularityType.Year,
IncrementalPeriods = 1,
IncrementalGranularity = TOM.RefreshGranularityType.Day,
SourceExpression =
"let\n" +
" Source = Sql.Database(\"demopm.database.windows.net\", \"AdventureWorksDW\"),\n" +
" dbo_FactInternetSales = Source{[Schema=\"dbo\",Item=\"FactInternetSales\"]}[Data],\n" +
" #\"Filtered Rows\" = Table.SelectRows(dbo_FactInternetSales, each [OrderDateKey] >= DateKey(RangeStart) and [OrderDateKey] < DateKey(RangeEnd))\n" +
"in\n" +
" #\"Filtered Rows\""
};
salesTable.RefreshPolicy = hybridPolicy;
model.RequestRefresh(TOM.RefreshType.Full);
model.SaveChanges();
}
Console.WriteLine("{0}{1}", Environment.NewLine, "Press [Enter] to exit...");
Console.ReadLine();
}
}
}