Procedure consigliate per la creazione di un modello dimensionale tramite flussi di dati
La progettazione di un modello dimensionale è una delle attività più comuni che è possibile eseguire con un flusso di dati. Questo articolo illustra alcune delle procedure consigliate per la creazione di un modello dimensionale tramite un flusso di dati.
Flussi di dati di gestione temporanea
Uno dei punti chiave di qualsiasi sistema di integrazione dei dati consiste nel ridurre il numero di letture dal sistema operativo di origine. Nell'architettura di integrazione dei dati tradizionale questa riduzione viene eseguita creando un nuovo database denominato database di staging. Lo scopo del database di staging è caricare i dati così come sono dall'origine dati nel database di staging in base a una pianificazione regolare.
Il resto dell'integrazione dei dati userà quindi il database di staging come origine per un'ulteriore trasformazione e lo convertirà nella struttura del modello dimensionale.
È consigliabile seguire lo stesso approccio usando flussi di dati. Creare un set di flussi di dati responsabili del semplice caricamento dei dati così com'è dal sistema di origine (e solo per le tabelle necessarie). Il risultato viene quindi archiviato nella struttura di archiviazione del flusso di dati (Azure Data Lake Archiviazione o Dataverse). Questa modifica garantisce che l'operazione di lettura dal sistema di origine sia minima.
Successivamente, è possibile creare altri flussi di dati che generano i dati dai flussi di dati di staging. I vantaggi di questo approccio includono:
- Riduzione del numero di operazioni di lettura dal sistema di origine e riduzione del carico nel sistema di origine.
- Riduzione del carico nei gateway dati se viene usata un'origine dati locale.
- Avere una copia intermedia dei dati a scopo di riconciliazione, nel caso in cui i dati di sistema di origine vengano modificati.
- Rendere indipendenti dall'origine i flussi di dati della trasformazione.
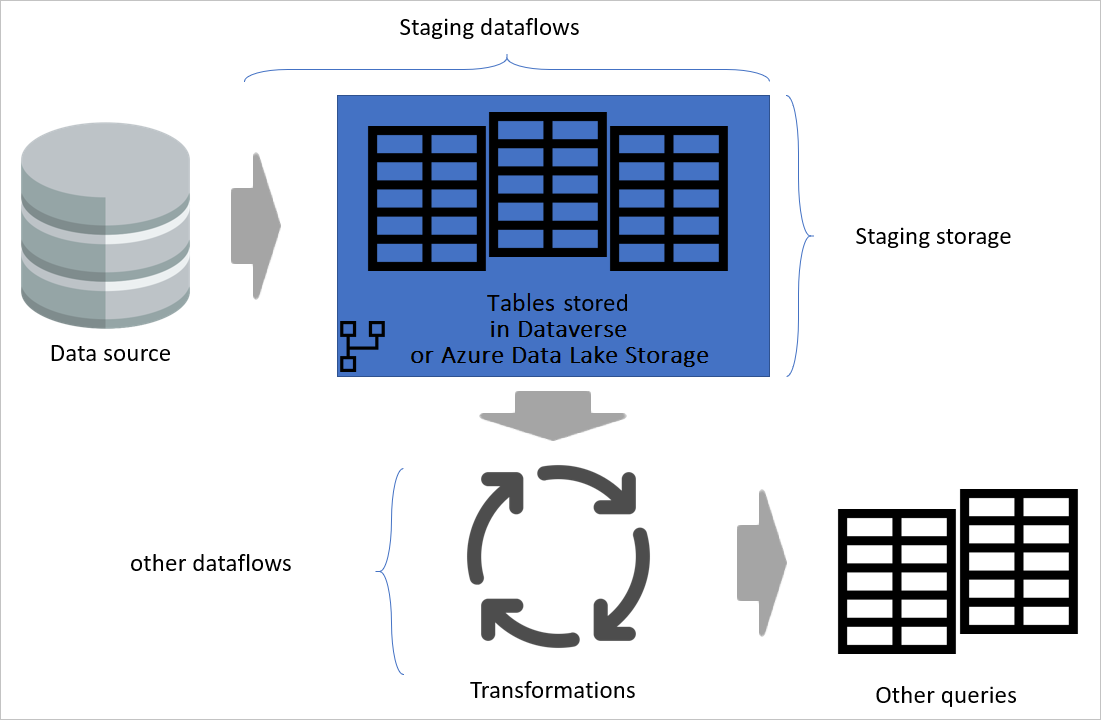
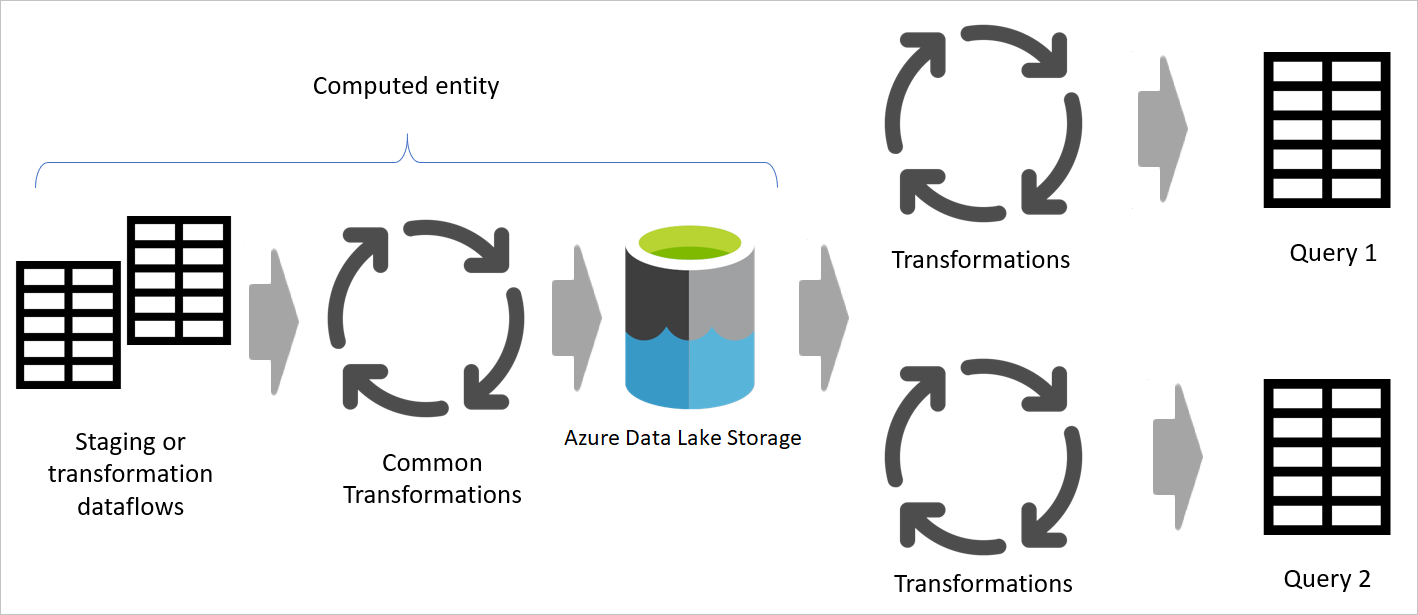
Immagine che evidenzia i flussi di dati di staging e l'archiviazione di staging e mostra i dati a cui si accede dall'origine dati tramite il flusso di dati di staging e le tabelle archiviate in Cadavers o Azure Data Lake Archiviazione. Le tabelle vengono quindi trasformate insieme ad altri flussi di dati, che vengono quindi inviati come query.
Flussi di dati di trasformazione
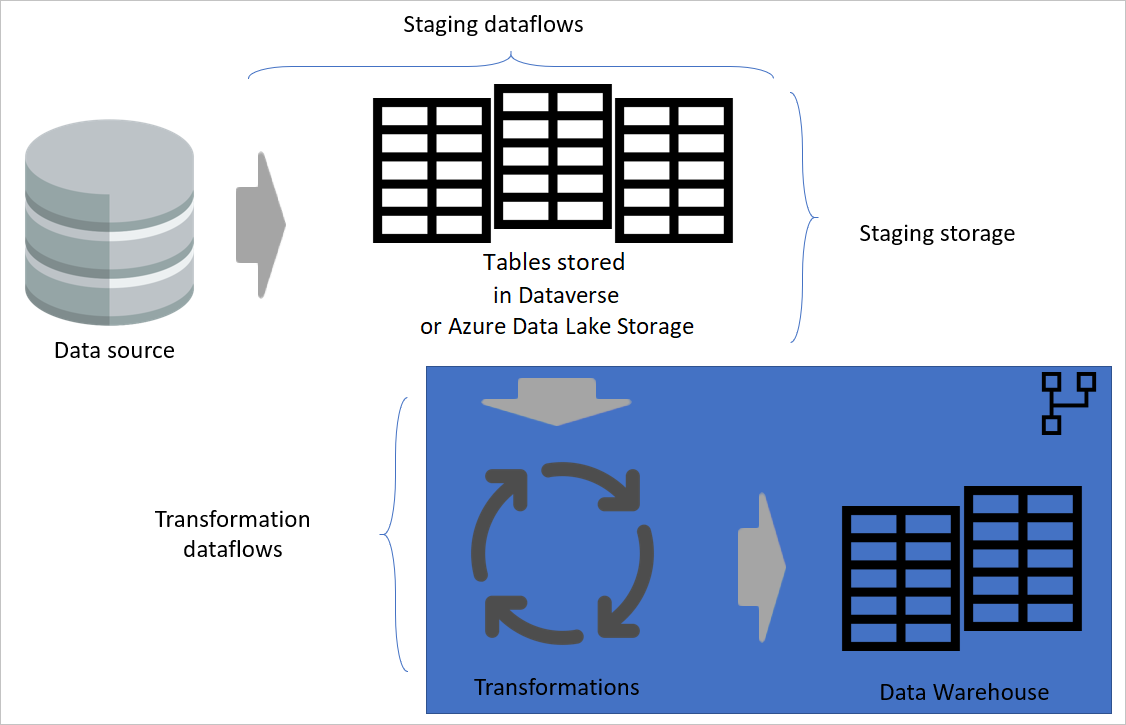
Dopo aver separato i flussi di dati della trasformazione dai flussi di dati di staging, la trasformazione sarà indipendente dall'origine. Questa separazione consente di eseguire la migrazione del sistema di origine a un nuovo sistema. In questo caso è sufficiente modificare i flussi di dati di staging. È probabile che i flussi di dati di trasformazione funzionino senza problemi perché vengono originati solo dai flussi di dati di staging.
Questa separazione aiuta anche nel caso in cui la connessione al sistema di origine sia lenta. Il flusso di dati della trasformazione non dovrà attendere molto tempo per ottenere i record provenienti da una connessione lenta dal sistema di origine. Il flusso di dati di staging ha già eseguito questa parte e i dati saranno pronti per il livello di trasformazione.
Architettura a più livelli
Un'architettura a più livelli è un'architettura in cui si eseguono azioni in livelli separati. I flussi di dati di gestione temporanea e trasformazione possono essere due livelli di un'architettura del flusso di dati a più livelli. Il tentativo di eseguire azioni nei livelli garantisce la manutenzione minima necessaria. Quando si vuole modificare qualcosa, è sufficiente modificarlo nel livello in cui si trova. Gli altri livelli dovrebbero continuare a funzionare correttamente.
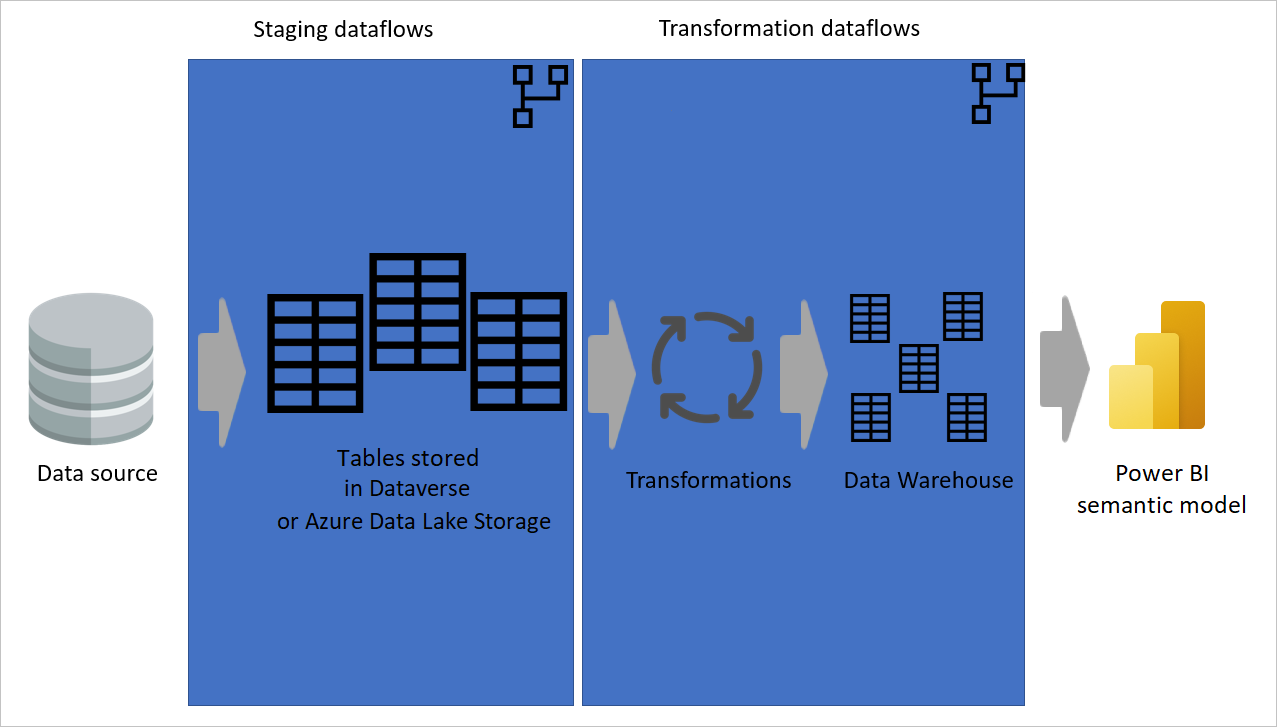
L'immagine seguente mostra un'architettura a più livelli per i flussi di dati in cui vengono quindi usate le tabelle nei modelli semantici di Power BI.
Usare una tabella calcolata il più possibile
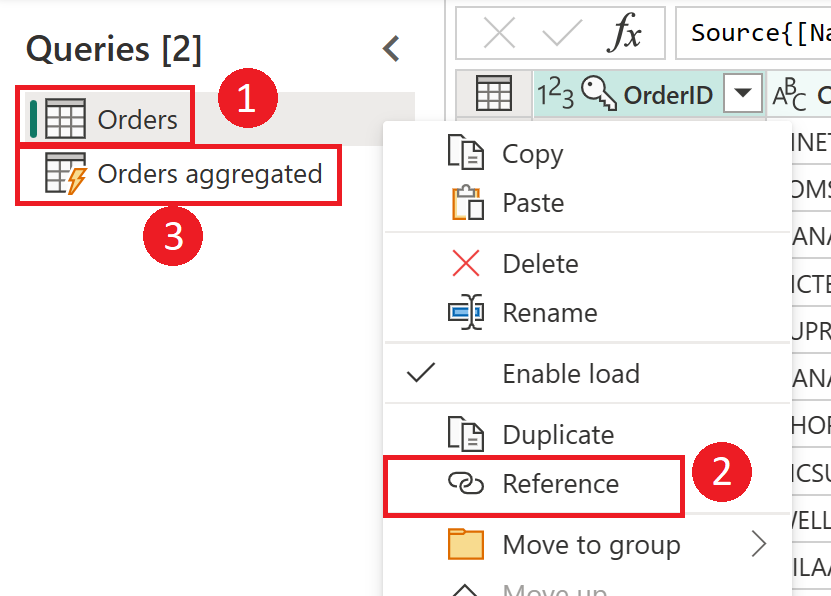
Quando si usa il risultato di un flusso di dati in un altro flusso di dati, si usa il concetto della tabella calcolata, il che significa ottenere dati da una tabella "già elaborata e archiviata". La stessa cosa può verificarsi all'interno di un flusso di dati. Quando si fa riferimento a una tabella da un'altra tabella, è possibile usare la tabella calcolata. Ciò è utile quando si dispone di un set di trasformazioni che devono essere eseguite in più tabelle, denominate trasformazioni comuni.
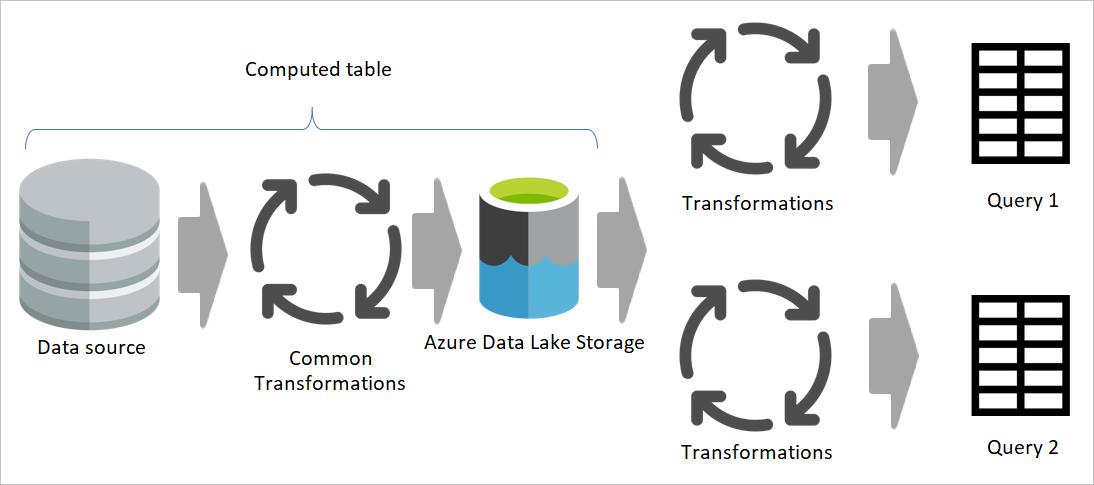
Nell'immagine precedente la tabella calcolata ottiene i dati direttamente dall'origine. Tuttavia, nell'architettura dei flussi di dati di gestione temporanea e trasformazione, è probabile che le tabelle calcolate vengano generate dai flussi di dati di staging.
Creare uno schema star
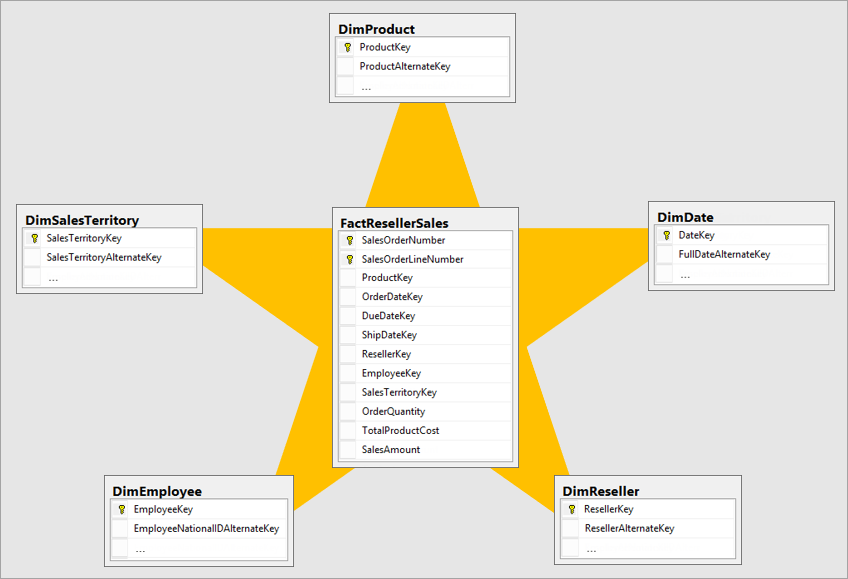
Il modello dimensionale migliore è un modello di schema star con dimensioni e tabelle dei fatti progettate in modo da ridurre al minimo la quantità di tempo per eseguire query sui dati dal modello e semplifica anche la comprensione per il visualizzatore di dati.
Non è ideale inserire i dati nello stesso layout del sistema operativo in un sistema bi. Le tabelle di dati devono essere rimodelle. Alcune tabelle devono assumere la forma di una tabella delle dimensioni, che mantiene le informazioni descrittive. Alcune tabelle devono assumere la forma di una tabella dei fatti per mantenere i dati aggregabili. Il layout migliore per tabelle dei fatti e tabelle delle dimensioni da formare è uno schema star. Altre informazioni: Comprendere lo schema star e l'importanza di Power BI
Usare un valore di chiave univoco per le dimensioni
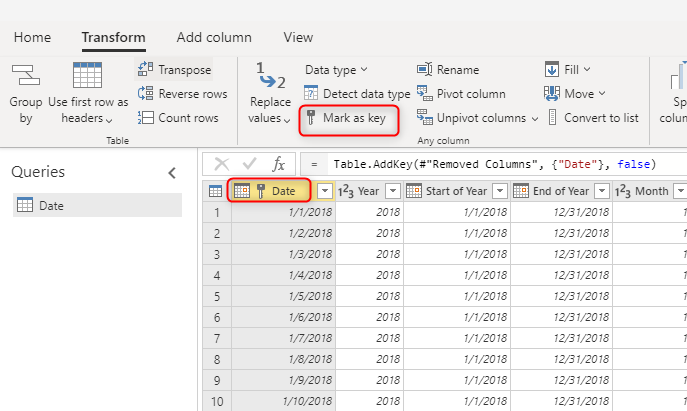
Quando si compilano tabelle delle dimensioni, assicurarsi di disporre di una chiave per ognuna di esse. Questa chiave garantisce che non vi siano relazioni molti-a-molti (o, in altre parole, "deboli") tra le dimensioni. È possibile creare la chiave applicando una trasformazione per assicurarsi che una colonna o una combinazione di colonne restituisca righe univoce nella dimensione. Tale combinazione di colonne può quindi essere contrassegnata come chiave nella tabella nel flusso di dati.
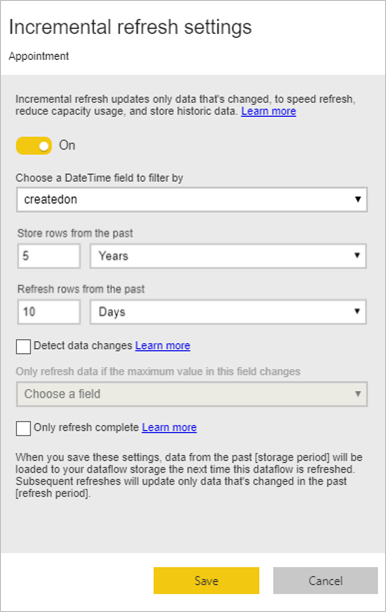
Eseguire un aggiornamento incrementale per tabelle dei fatti di grandi dimensioni
Le tabelle dei fatti sono sempre le tabelle più grandi del modello dimensionale. È consigliabile ridurre il numero di righe trasferite per queste tabelle. Se si dispone di una tabella dei fatti molto grande, assicurarsi di usare l'aggiornamento incrementale per tale tabella. È possibile eseguire un aggiornamento incrementale nel modello semantico di Power BI e anche nelle tabelle del flusso di dati.
È possibile usare l'aggiornamento incrementale per aggiornare solo parte dei dati, ovvero la parte modificata. Sono disponibili più opzioni per scegliere quale parte dei dati aggiornare e quale parte rendere persistente. Altre informazioni: Uso dell'aggiornamento incrementale con flussi di dati di Power BI
Riferimento alla creazione di dimensioni e tabelle dei fatti
Nel sistema di origine è spesso presente una tabella usata per generare tabelle dei fatti e delle dimensioni nel data warehouse. Queste tabelle sono valide per le tabelle calcolate e anche i flussi di dati intermedi. La parte comune del processo, ad esempio la pulizia dei dati e la rimozione di righe e colonne aggiuntive, possono essere eseguite una sola volta. Usando un riferimento dall'output di tali azioni, è possibile produrre le tabelle delle dimensioni e dei fatti. Questo approccio userà la tabella calcolata per le trasformazioni comuni.