Considerazioni sul mapping dei campi per i flussi di dati standard
Quando si caricano dati in tabelle di Dataverse, si esegue il mapping delle colonne della query di origine nell'esperienza di modifica del flusso di dati alle colonne della tabella Dataverse di destinazione. Oltre al mapping dei dati, esistono altre considerazioni e procedure consigliate da tenere in considerazione. In questo articolo vengono illustrate le diverse impostazioni del flusso di dati che controllano il comportamento dell'aggiornamento del flusso di dati e, di conseguenza, i dati nella tabella di destinazione.
Controllo della creazione o dell'upsert dei flussi di dati per ogni aggiornamento
Ogni volta che si aggiorna un flusso di dati, recupera i record dall'origine e li carica in Dataverse. Se si esegue il flusso di dati più di una volta, a seconda di come si configura il flusso di dati, è possibile:
- Creare nuovi record per ogni aggiornamento del flusso di dati, anche se tali record esistono già nella tabella di destinazione.
- Creare nuovi record se non esistono già nella tabella o aggiornare i record esistenti, se già presenti nella tabella. Questo comportamento è denominato upsert.
L'uso di una colonna chiave indica al flusso di dati di eseguire l'upsert dei record nella tabella di destinazione, senza selezionare una chiave indica al flusso di dati di creare nuovi record nella tabella di destinazione.
Una colonna chiave è una colonna univoca e deterministica di una riga di dati nella tabella. Ad esempio, in una tabella Orders, se l'ID ordine è una colonna chiave, non è consigliabile avere due righe con lo stesso ID ordine. Inoltre, un ID ordine, ad esempio un ordine con ID 345, deve rappresentare solo una riga nella tabella. Per scegliere la colonna chiave per la tabella in Dataverse dal flusso di dati, è necessario impostare il campo chiave nell'esperienza Tabelle mappa.
Scelta di un nome primario e di un campo chiave durante la creazione di una nuova tabella
L'immagine seguente mostra come scegliere la colonna chiave da popolare dall'origine quando si crea una nuova tabella nel flusso di dati.
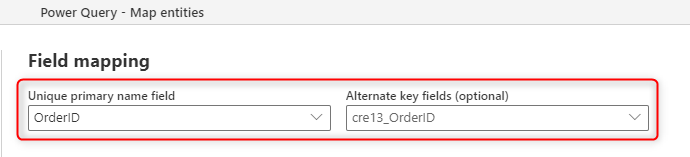
Il campo nome primario visualizzato nel mapping dei campi è relativo a un campo etichetta; questo campo non deve essere univoco. Il campo utilizzato nella tabella per controllare la duplicazione è il campo impostato nel campo Chiave alternativa.
La presenza di una chiave primaria nella tabella garantisce che, anche se sono presenti dati duplicati nel campo mappato alla chiave primaria, le voci duplicate non verranno caricate nella tabella. Questo comportamento mantiene una qualità elevata dei dati nella tabella. I dati di alta qualità sono essenziali per la creazione di soluzioni di creazione di report basate sulla tabella.
Campo nome primario
Il campo nome primario è un campo visualizzato usato in Dataverse. Questo campo viene utilizzato nelle visualizzazioni predefinite per visualizzare il contenuto della tabella in altre applicazioni. Questo campo non è il campo chiave primaria e non deve essere considerato così. Questo campo può avere valori duplicati, perché si tratta di un campo di visualizzazione. La procedura consigliata, tuttavia, consiste nell'usare un campo concatenato per eseguire il mapping al campo del nome primario, quindi il nome è completamente esplicativo.
Il campo chiave alternativo è quello usato come chiave primaria.
Scelta di un campo chiave durante il caricamento in una tabella esistente
Quando si esegue il mapping di una query del flusso di dati a una tabella Dataverse esistente, è possibile scegliere se e quale chiave deve essere usata durante il caricamento dei dati nella tabella di destinazione.
L'immagine seguente mostra come scegliere la colonna chiave da usare per l'upserting dei record in una tabella Dataverse esistente:

Impostazione della colonna ID univoco di una tabella e relativa utilizzo come campo chiave per l'upserting dei record in tabelle dataverse esistenti
Tutte le righe della tabella Microsoft Dataverse hanno identificatori univoci definiti come GUID. Questi GUID sono la chiave primaria per ogni tabella. Per impostazione predefinita, la chiave primaria di una tabella non può essere impostata dai flussi di dati e viene generata automaticamente da Dataverse quando viene creato un record. Esistono casi d'uso avanzati in cui è consigliabile sfruttare la chiave primaria di una tabella, ad esempio l'integrazione di dati con origini esterne mantenendo gli stessi valori di chiave primaria nella tabella esterna e nella tabella Dataverse.
Nota
- Questa funzionalità è disponibile solo quando si caricano dati in tabelle esistenti.
- Il campo identificatore univoco accetta solo una stringa contenente valori GUID, qualsiasi altro tipo di dati o valore causa l'esito negativo della creazione di record.
Per sfruttare i vantaggi del campo identificatore univoco di una tabella, selezionare Carica nella tabella esistente nella pagina Tabelle mappa durante la creazione di un flusso di dati. Nell'esempio illustrato nell'immagine successiva, carica i dati nella tabella CustomerTransactions e usa la colonna TransactionID dall'origine dati come identificatore univoco della tabella.
Si noti che nell'elenco a discesa Seleziona chiave è possibile selezionare l'identificatore univoco , denominato sempre "tablename + id". Poiché il nome della tabella è "CustomerTransactions", il campo identificatore univoco è denominato "CustomerTransactionId".

Dopo aver selezionato, la sezione mapping colonne viene aggiornata per includere l'identificatore univoco come colonna di destinazione. È quindi possibile eseguire il mapping della colonna di origine che rappresenta l'identificatore univoco per ogni record.

Quali sono i candidati validi per il campo chiave
Il campo chiave è un valore univoco che rappresenta una riga univoca nella tabella. È importante avere questo campo perché consente di evitare la presenza di record duplicati nella tabella. Questo campo può provenire da tre origini:
Chiave primaria nel sistema di origine, ad esempio OrderID nell'esempio precedente. campo concatenato creato tramite trasformazioni di Power Query nel flusso di dati.
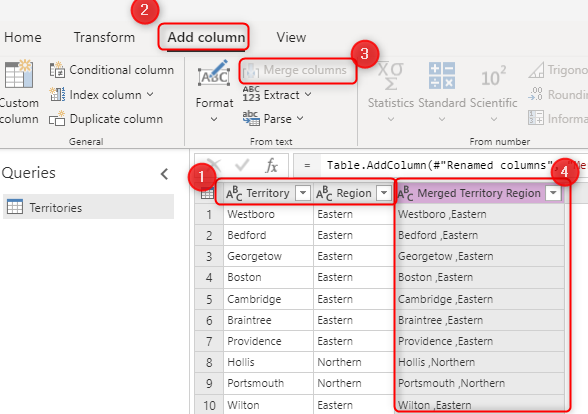
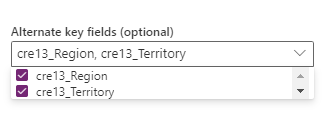
Combinazione di campi da selezionare nell'opzione Chiave alternativa. Una combinazione di campi usati come campo chiave è detta anche chiave composita.
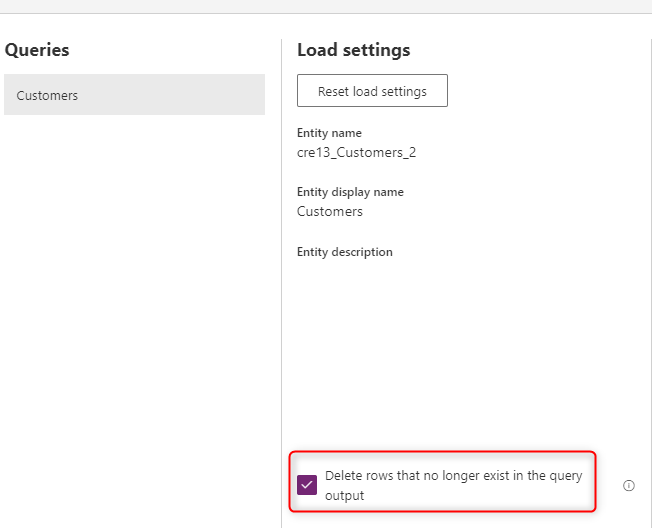
Rimuovere righe che non esistono più
Se si desidera che i dati nella tabella siano sempre sincronizzati con i dati del sistema di origine, scegliere l'opzione Elimina righe che non esistono più nell'output della query. Tuttavia, questa opzione rallenta il flusso di dati perché è necessario un confronto di righe basato sulla chiave primaria (chiave alternativa nel mapping dei campi del flusso di dati) per eseguire questa azione.
L'opzione indica che se è presente una riga di dati nella tabella che non esiste nell'output della query dell'aggiornamento del flusso di dati successivo, tale riga viene rimossa dalla tabella.
Nota
I flussi di dati V2 standard si basano sui createdon campi e modifiedon per rimuovere le righe che non esistono nell'output dei flussi di dati, dalla tabella di destinazione. Se tali colonne non esistono nella tabella di destinazione, i record non vengono eliminati.
Limitazioni note
- Il mapping ai campi di ricerca polimorfica non è attualmente supportato.
- Il mapping a un campo di ricerca a più livelli, una ricerca che punta al campo di ricerca di un'altra tabella, non è attualmente supportata.
- Il mapping ai campi Stato e Motivo stato non è attualmente supportato.
- Il mapping dei dati in testo a più righe che include caratteri di interruzione di riga non è supportato e le interruzioni di riga vengono rimosse. È invece possibile usare il tag
<br>di interruzione di riga per caricare e mantenere il testo su più righe. - Il mapping ai campi Choice configurati con l'opzione di selezione multipla abilitata è supportato solo in determinate condizioni. Il flusso di dati carica solo i dati nei campi Choice con l'opzione di selezione multipla abilitata e viene usato un elenco delimitato da virgole di valori (interi) delle etichette. Ad esempio, se le etichette sono "Choice1, Choice2, Choice3" con valori interi corrispondenti di "1, 2, 3", i valori della colonna devono essere "1,3" per selezionare la prima e l'ultima scelta.
- I flussi di dati V2 standard si basano sui
createdoncampi emodifiedonper rimuovere le righe che non esistono nell'output dei flussi di dati, dalla tabella di destinazione. Se tali colonne non esistono nella tabella di destinazione, i record non vengono eliminati. - Il mapping ai campi la cui proprietà IsValidForCreate è impostata su
falsenon è supportata, ad esempio il campo Account dell'entità Contact.