Qual è la struttura di archiviazione per i flussi di dati analitici?
I flussi di dati analitici archiviano sia i dati che i metadati in Azure Data Lake Archiviazione. I flussi di dati sfruttano una struttura standard per archiviare e descrivere i dati creati nel lake, denominati cartelle Common Data Model. In questo articolo verranno fornite altre informazioni sullo standard di archiviazione usato dai flussi di dati in background.
Archiviazione necessita di una struttura per un flusso di dati analitico
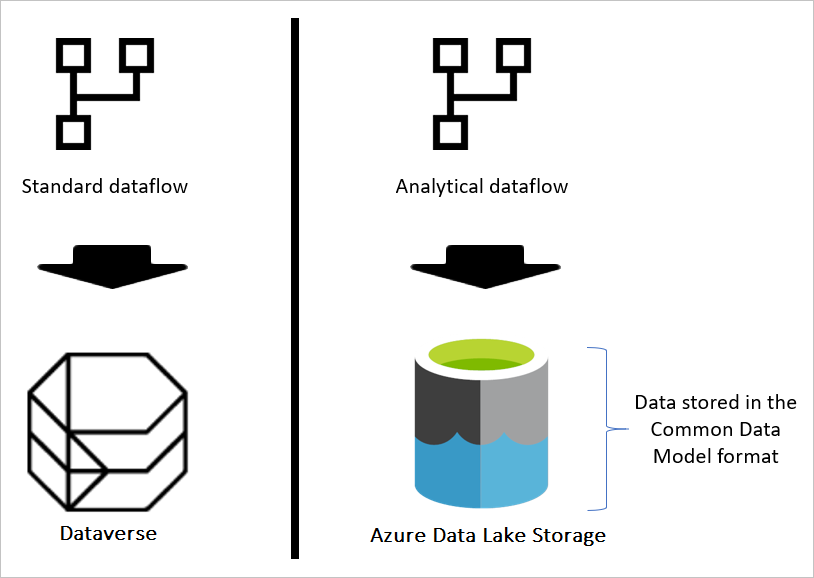
Se il flusso di dati è standard, i dati vengono archiviati in Dataverse. Dataverse è come un sistema di database; ha il concetto di tabelle, viste e così via. Dataverse è un'opzione di archiviazione dati strutturata usata dai flussi di dati standard.
Tuttavia, quando il flusso di dati è analitico, i dati vengono archiviati in Azure Data Lake Archiviazione. I dati e i metadati di un flusso di dati vengono archiviati in una cartella Common Data Model. Poiché in un account di archiviazione potrebbero essere archiviati più flussi di dati, è stata introdotta una gerarchia di cartelle e sottocartelle per organizzare i dati. A seconda del prodotto in cui è stato creato il flusso di dati, le cartelle e le sottocartelle possono rappresentare aree di lavoro (o ambienti) e quindi la cartella Common Data Model del flusso di dati. All'interno della cartella Common Data Model vengono archiviati sia lo schema che i dati delle tabelle del flusso di dati. Questa struttura segue gli standard definiti per Common Data Model.
Che cos'è la struttura di archiviazione Common Data Model?
Common Data Model è una struttura di metadati definita per garantire la conformità e la coerenza per l'uso dei dati in più piattaforme. Common Data Model non è l'archiviazione dei dati, è il modo in cui i dati vengono archiviati e definiti.
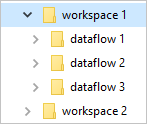
Le cartelle common Data Model definiscono come archiviare lo schema di una tabella e i relativi dati. In Azure Data Lake Archiviazione i dati sono organizzati in cartelle. Le cartelle possono rappresentare un'area di lavoro o un ambiente. In tali cartelle vengono create sottocartelle per ogni flusso di dati.
Che cos'è in una cartella del flusso di dati?
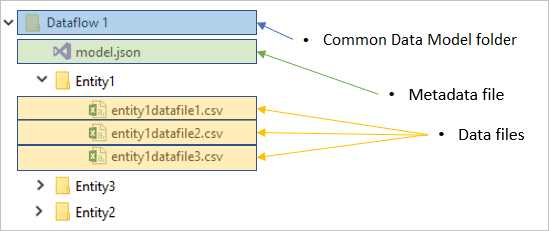
Ogni cartella del flusso di dati contiene una sottocartella per ogni tabella e un file di metadati denominato model.json.
File di metadati: model.json
Il model.json file è la definizione di metadati del flusso di dati. Si tratta di un file che contiene tutti i metadati del flusso di dati. Include un elenco di tabelle, le colonne e i relativi tipi di dati in ogni tabella, la relazione tra tabelle e così via. È possibile esportare facilmente questo file da un flusso di dati, anche se non si ha accesso alla struttura di cartelle Common Data Model.
È possibile usare questo file JSON per eseguire la migrazione (o importare) il flusso di dati in un'altra area di lavoro o ambiente.
Per informazioni esattamente sul file di metadati model.json, passare a File di metadati (model.json) per Common Data Model.
File di dati
Oltre al file di metadati, la cartella del flusso di dati include altre sottocartelle. Un flusso di dati archivia i dati per ogni tabella in una sottocartella con il nome della tabella. I dati per una tabella possono essere suddivisi in più partizioni di dati, archiviate in formato CSV.
Come visualizzare o accedere alle cartelle Common Data Model
Se si usano flussi di dati che usano l'archiviazione fornita dal prodotto in cui sono stati creati, non sarà possibile accedere direttamente a tali cartelle. In questi casi, per ottenere dati dai flussi di dati è necessario usare il connettore di flussi di dati di Microsoft Power Platform disponibile nell'esperienza Recupera dati nei prodotti servizio Power BI, Power Apps e Dynamics 35 Customer Insights o in Power BI Desktop.
Per informazioni sul funzionamento dei flussi di dati e sull'integrazione interna di Data Lake Archiviazione, passare a Flussi di dati e integrazione di Azure Data Lake (anteprima).
Se l'organizzazione ha abilitato i flussi di dati per sfruttare il proprio account Data Lake Archiviazione ed è stato selezionato come destinazione di caricamento per i flussi di dati, è comunque possibile ottenere dati dal flusso di dati usando il connettore di flussi di dati power Platform come indicato in precedenza. Ma è anche possibile accedere alla cartella Common Data Model del flusso di dati direttamente tramite il lake, anche all'esterno degli strumenti e dei servizi di Power Platform. L'accesso al lake è possibile tramite il portale di Azure, Archiviazione di Microsoft Azure Explorer o qualsiasi altro servizio o esperienza che supporti Azure Data Lake Archiviazione. Ulteriori informazioni: Connettere Azure Data Lake Storage Gen2 per l'archiviazione dei flussi di dati
Passaggi successivi
Usare Common Data Model per ottimizzare Azure Data Lake Archiviazione Gen2
Aggiungere una cartella CDM a Power BI come flusso di dati (anteprima)
Connettere Azure Data Lake Storage Gen2 per l'archiviazione dei flussi di dati
Flussi di dati e integrazione di Azure Data Lake (anteprima)
Configurare le impostazioni del flusso di dati dell'area di lavoro (anteprima)