Esercitazione 2: Eseguire il training di modelli di rischio di credito - Machine Learning Studio (versione classica)
SI APPLICA A:  Machine Learning Studio (versione classica)
Machine Learning Studio (versione classica)  di Azure Machine Learning
di Azure Machine Learning
Importante
Il supporto dello studio di Azure Machine Learning (versione classica) terminerà il 31 agosto 2024. È consigliabile passare ad Azure Machine Learning entro tale data.
A partire dal 1° dicembre 2021 non sarà possibile creare nuove risorse dello studio di Azure Machine Learning (versione classica). Fino al 31 agosto 2024 sarà possibile continuare a usare le risorse dello studio di Azure Machine Learning (versione classica).
- Vedere le informazioni sullo spostamento di progetti di apprendimento automatico da ML Studio (versione classica) ad Azure Machine Learning.
- Scoprire di più su Azure Machine Learning
La documentazione relativa allo studio di Machine Learning (versione classica) è in fase di ritiro e potrebbe non essere aggiornata in futuro.
In questa esercitazione si esamina il processo di sviluppo di una soluzione di analisi predittiva. Si svilupperà un modello semplice in Machine Learning Studio (versione classica). Il modello viene quindi distribuito come servizio Web di Machine Learning. Questo modello distribuito può creare previsioni usando nuovi dati. Questa esercitazione è la seconda di una serie in tre parti.
Si supponga di dover prevedere il rischio di credito di un soggetto in base alle informazioni fornite in una richiesta di credito.
La valutazione del rischio di credito è un problema complesso che verrà tuttavia semplificato con questa esercitazione. Verrà usato come esempio di come creare una soluzione di analisi predittiva usando Machine Learning Studio (versione classica). Si useranno Machine Learning Studio (versione classica) e un servizio Web di Machine Learning per questa soluzione.
In questa esercitazione in tre parti si inizia con dati sul rischio di credito disponibili pubblicamente. Verrà quindi sviluppato e sottoposto a training un modello predittivo. Il modello verrà infine distribuito come servizio Web.
Nella prima parte dell'esercitazione è stata creata un'area di lavoro di Machine Learning Studio (versione classica), sono stati caricati i dati ed è stato creato un esperimento.
In questa parte dell'esercitazione verranno eseguite queste operazioni:
- Eseguire il training di più modelli
- Classificare e valutare i modelli
Nella terza parte dell'esercitazione si distribuirà il modello come servizio Web.
Prerequisiti
Completare la prima parte dell'esercitazione.
Eseguire il training di più modelli
Uno dei vantaggi dell'uso di Machine Learning Studio (versione classica) per la creazione di modelli di Machine Learning è la possibilità di provare più di un tipo di modello alla volta in un singolo esperimento e confrontare i risultati. Questo tipo di esperimento consente di trovare la soluzione migliore per il problema che si desidera risolvere.
Nell'esperimento sviluppato in questa esercitazione verranno creati due tipi diversi di modello, quindi ne verranno confrontati i punteggi risultanti per decidere quale algoritmo usare nell'esperimento finale.
Sono disponibili diversi modelli tra cui scegliere. Per visualizzare i modelli disponibili, espandere il nodo Machine Learning nella tavolozza dei moduli, espandere Initialize Model (Inizializza modello) e quindi i nodi al suo interno. Ai fini di questo esperimento, verranno selezionati i moduli Two-Class Support Vector Machine (Macchina a vettori di supporto a due classi), o SVM, e Two-Class Boosted Decision Tree (Albero delle decisioni con boosting a due classi).
In questo esperimento verranno aggiunti il modulo Two-Class Boosted Decision Tree (Albero delle decisioni con boosting a due classi) e il modulo Two-Class Support Vector Machine (Macchina a vettori di supporto a due classi).
Albero delle decisioni incrementato a due classi
Prima di tutto verrà configurato il modello di albero delle decisioni con boosting.
Trovare il modulo Two-Class Boosted Decision Tree (Albero delle decisioni con boosting a due classi) nel pannello dei moduli e trascinarlo nel canvas.
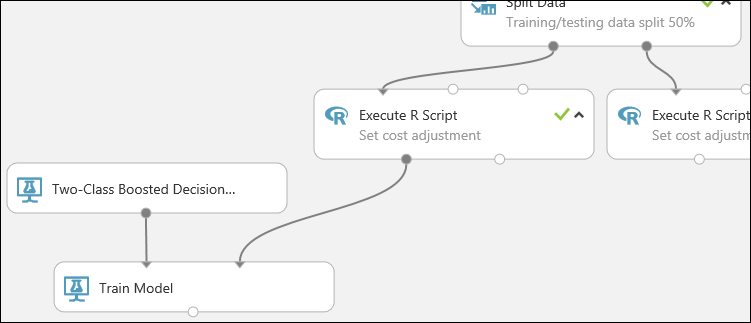
Trovare il modulo Train Model (Training modello), trascinarlo nel canvas, quindi connettere l'output del modulo Two-Class Boosted Decision Tree (Albero delle decisioni con boosting a due classi) alla porta di input sinistra del modulo Train Model (Training modello).
Il modulo Two-Class Boosted Decision Tree (Albero delle decisioni con boosting a due classi) inizializza il modello generico e Train Model (Training modello) usa i dati di training per il training del modello.
Connettere l'output sinistro del modulo Execute R Script (Esecuzione script R) sinistro alla porta di input destra del modulo Train Model (Training modello). In questa esercitazione sono stati usati i dati provenienti dal lato sinistro del modulo Split Data (Divisione dati) per il training.
Suggerimento
Due degli input e uno degli output del modulo Execute R Script (Esecuzione script R) non sono necessari per questo esperimento, pertanto potranno rimanere scollegati.
Questa parte dell'esperimento avrà ora un aspetto analogo al seguente:
A questo punto è necessario indicare al modulo Train Model (Training modello) che il modello dovrà stimare il valore del rischio di credito.
Selezionare il modulo Train Model. Nel riquadro Proprietà, fare clic su Launch column selector (Avvia selettore colonne).
Nella finestra di dialogo Select a single column (Selezionare una singola colonna), digitare "rischio di credito" nel campo di ricerca in Colonne disponibili, selezionare "Rischio di credito" di seguito e fare clic sul pulsante freccia destra (>) per spostare "Rischio di credito" su Colonne selezionate.
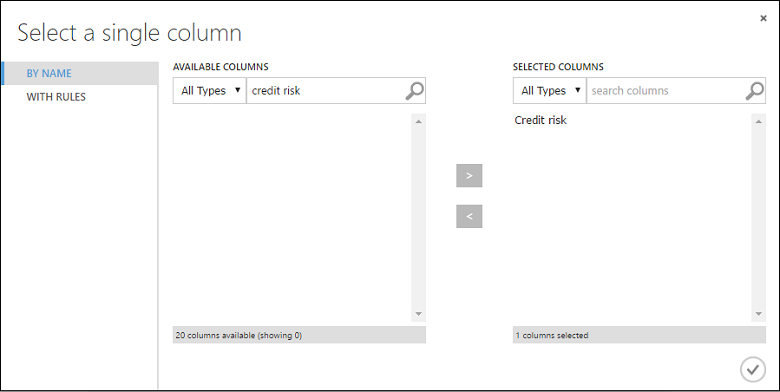
Fare clic sul segno di spunta OK.
Two-Class Support Vector Machine
Successivamente si configura il modello SVM.
Innanzitutto, una breve spiegazione di SVM. Gli alberi delle decisioni con boosting funzionano bene con qualsiasi tipo di funzionalità. Poiché tuttavia il modulo di macchina a vettori di supporto genera un classificatore lineare, il modello che genera ha l'errore di test migliore quando gli elementi numerici hanno la stessa scala. Per convertire tutte le funzioni numeriche nella stessa scala, usare una trasformazione "Tanh" con il modulo Normalize Data (Normalizza dati). In questo modo, vengono trasformati i numeri nell'intervallo [0,1]. I modulo SVM converte gli elementi stringa in elementi di categoria e quindi in elementi 0/1 binari, quindi non è necessario trasformare manualmente gli elementi stringa. Non si deve inoltre trasformare la colonna Credit Risk (colonna 21): si tratta di un valore numerico, ma è il valore per il quale il modulo deve eseguire la previsione dopo il training e non dovrà essere quindi modificato.
Per configurare il modello SVM, procedere come segue:
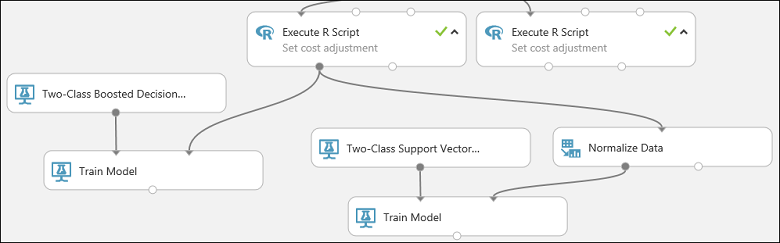
Trovare il modulo Two-Class Support Vector Machine (Macchina a vettori di supporto a due classi) nel pannello dei moduli e trascinarlo nel canvas.
Fare clic con il pulsante destro del mouse sul modulo Train Model (Training modello), scegliere Copia, quindi fare clic con il pulsante destro del mouse sul canvas e scegliere Incolla. La copia del modulo Train Model (Training modello) presenta la stessa selezione di colonne dell'originale.
Connettere l'output del modulo Two-Class Support Vector Machine (Macchina a vettori di supporto a due classi) alla porta di input sinistra del secondo modulo Train Model (Training modello).
Trovare il modulo Normalize Data (Normalizza dati) e trascinarlo nel canvas.
Connettere l'output sinistro del modulo Execute R Script (Esecuzione script R) sinistro all'input di questo modulo (si noti che la porta di output di un modulo potrebbe essere connessa a più di un modulo).
Connettere la porta di output sinistra del modulo Normalize Data (Normalizza dati) alla porta di input destra del secondo modulo Train Model (Training modello).
Questa parte dell'esperimento avrà ora un aspetto analogo al seguente:
Ora configurare il modulo Normalize Data (Normalizza dati):
Fare clic per selezionare il modulo Normalize Data (Normalizza dati). Nel riquadro Proprietà relativo al modulo di trasformazione scegliere Tanh per il parametro Transformation method (Metodo di trasformazione).
Fare clic su Launch column selector (Avvia selettore di colonna), selezionare "No columns" (Nessuna colonna) per Begin With (Inizia con), selezionare Include (Includi) nel primo elenco a discesa, selezionare column type (tipo di colonna) nel secondo elenco a discesa e infine selezionare Numeric (Numerico) nel terzo elenco a discesa. Questo specifica che verranno trasformate tutte le colonne numeriche, ma solo quelle di questo tipo.
Fare clic sul segno più (+) a destra di questa riga per creare una nuova riga di elenchi a discesa. Selezionare Escludi nel primo elenco a discesa, selezionare column names (nomi colonna) nel secondo elenco a discesa e immettere "Rischio di credito" nel campo di testo. Questa impostazione specifica che la colonna Credit Risk deve essere ignorata. Ciò è necessario perché la colonna è numerica e verrebbe quindi trasformata se non venisse esclusa.
Fare clic sul segno di spunta OK.
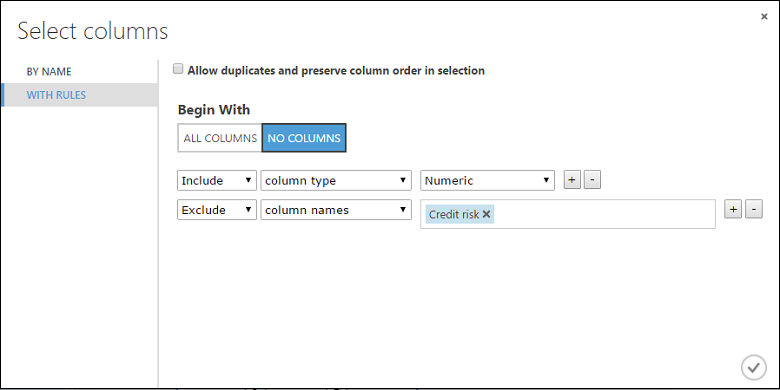
Il modulo Normalize Data (Normalizza dati) è ora impostato per eseguire una trasformazione Tanh su tutte le colonne numeriche, a eccezione della colonna del rischio di credito.
Classificare e valutare i modelli
Si useranno i dati di test che sono stati separati dal modulo Split Data (Divisione dati) per assegnare il punteggio ai moduli sottoposti a training. Sarà quindi possibile confrontare i risultati dei due modelli per stabilire quale ha generato i risultati migliori.
Aggiungere i moduli Score Model (Punteggio modello)
Trovare il modulo Score Model (Punteggio modello) e trascinarlo nel canvas.
Connettere il modulo Train Model (Training modello) connesso al modulo Two-Class Boosted Decision Tree (Albero delle decisioni con boosting a due classi) alla porta di input sinistra del modulo Score Model (Punteggio modello).
Connettere il modulo Execute R Script (Esecuzione script R) destro alla porta di input destra del modulo Score Model (Punteggio modello).
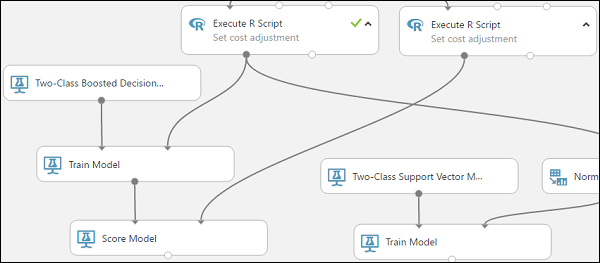
Il modulo Score Model (Punteggio modello) può ora prelevare le informazioni sul credito dai dati di test, eseguirle tramite il modello e confrontare le previsioni generate dal modello con la colonna relativa al rischio di credito dei dati di test.
Copiare e incollare il modulo Score Model (Punteggio modello) per creare una seconda copia.
Connettere l'output del modello SVM, vale a dire la porta di output del modulo Train Model (Training modello) connessa al modulo Two-Class Support Vector Machine (Macchina a vettori di supporto a due classi), alla porta di input del secondo modulo Score Model (Punteggio modello).
Per il modello SVM è necessario eseguire la stessa trasformazione sui dati di test eseguita in precedenza sui dati di training. Pertanto, copiare e incollare il modulo Normalize Data (Normalizza dati) per creare una seconda copia e connetterla al modulo Execute R Script (Esecuzione script R) destro.
Connettere l'output sinistro del secondo modulo Normalize Data (Normalizza dati) alla porta di input destra del secondo modulo Score Model (Punteggio modello).
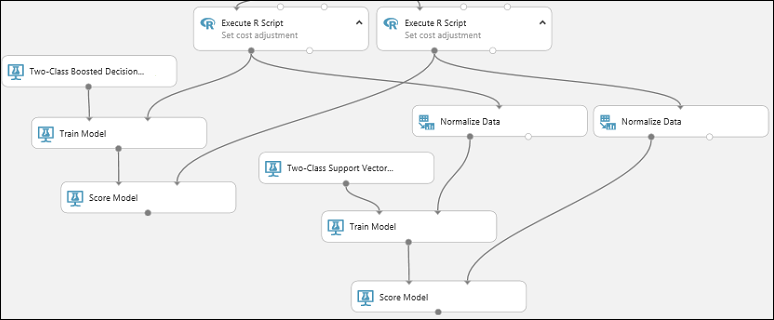
Aggiungere il modulo Evaluate Model (Modello di valutazione)
Per valutare i due risultati di punteggio e confrontarli, viene usato il modulo Evaluate Model (Valutazione modello).
Trovare il modulo Evaluate Model (Valutazione modello) e trascinarlo nel canvas.
Connettere la porta di output del modulo Score Model (Punteggio modello) associata al modello di albero delle decisioni con boosting alla porta di input sinistra del modulo Evaluate Model (Valutazione modello).
Connettere l'altro modulo Score Model (Punteggio modello) alla porta di input destra.
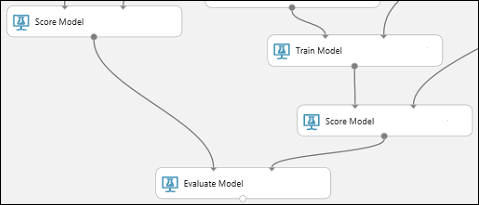
Eseguire l'esperimento e controllare i risultati
Per eseguire l'esperimento, fare clic sul pulsante RUN (ESEGUI) sotto l'area di disegno. L'operazione potrebbe richiedere alcuni minuti. Su ogni modulo verrà visualizzato un indicatore rotante per indicare che il modulo è in esecuzione, quindi apparirà un segno di spunta verde al termine dell'esecuzione. Quando tutti i moduli presentano il segno di spunta, l'esecuzione dell'esperimento sarà completa.
L'esperimento avrà ora un aspetto analogo al seguente:
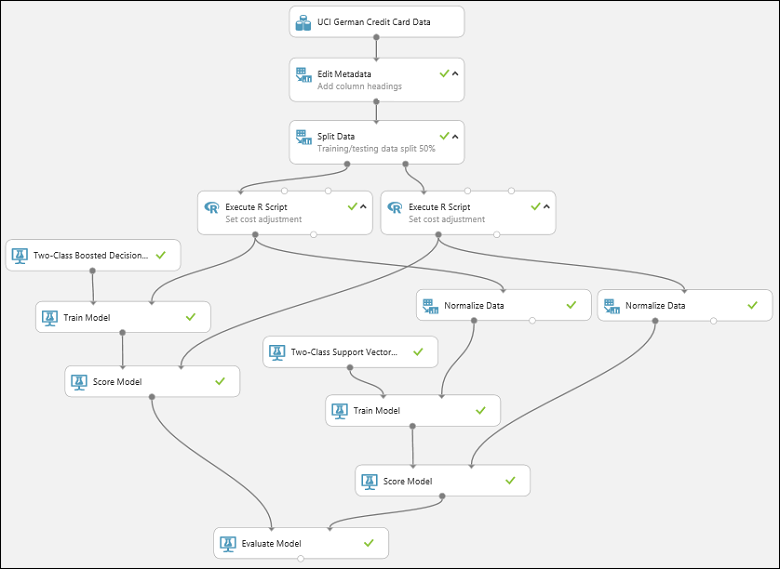
Per verificare i risultati, fare clic sulla porta di output del modulo Evaluate Model (Valutazione modello) e selezionare Visualize (Visualizza).
Il modulo Evaluate Model (Valutazione modello) produce una coppia di curve e metriche che consentono di confrontare i risultati dei due modelli classificati. È possibile visualizzare i risultati come curve ROC (Receiver Operator Characteristic), curve precisione/recupero o curve di accuratezza. Altri dati visualizzati includono una matrice di confusione, valori cumulativi per l'area nella curva (AUC) e altra metrica. È possibile modificare il valore soglia spostando il dispositivo di scorrimento a sinistra o a destra e vedere come ciò influisce sul set della metrica.
A destra del grafico fare clic su Scored dataset (Set di dati con punteggio) o Scored dataset to compare (Set di dati con punteggio da confrontare) per evidenziare la curva associata e visualizzare le metriche associate più sotto. Nella legenda per le curve, "Scored dataset" (Set di dati con punteggio) corrisponde alla porta di input sinistra del modulo Evaluate Model (Valutazione modello). In questo caso si tratta del modello di albero delle decisioni con boosting. "Scored dataset to compare" corrisponde alla porta di input destra, in questo caso il modello di macchina a vettori di supporto. Quando si fa clic su una di queste etichette, viene evidenziata la curva per il modello e viene visualizzata la metrica corrispondente, come mostrato dalla grafica seguente.
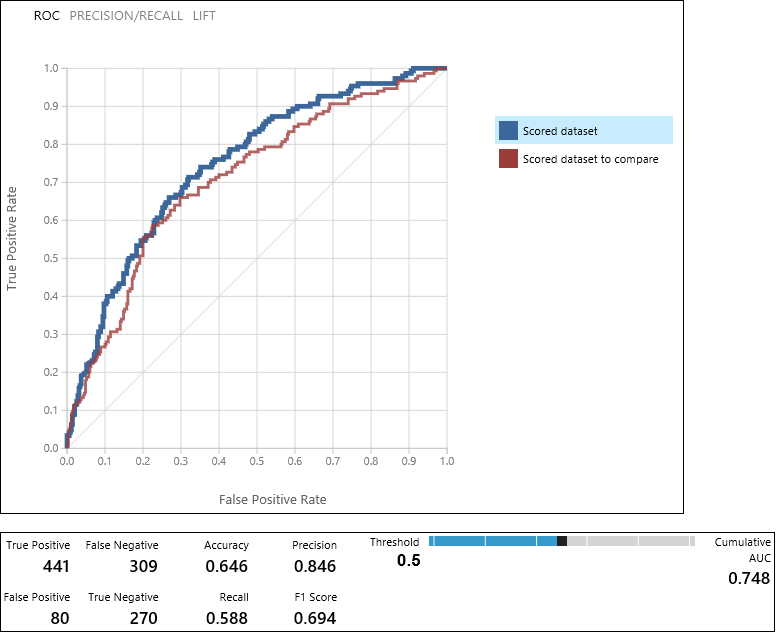
Esaminando questi valori, è possibile decidere quale sia il modello che più si avvicina ai risultati previsti. È possibile tornare indietro ed eseguire l'iterazione dell'esperimento modificando i valori di parametro dei vari modelli.
La scienza e l'arte di interpretare questi risultati e di ottimizzare le prestazioni del modello non rientrano nell'ambito di questa esercitazione. Per ulteriori informazioni, è possibile leggere gli articoli seguenti:
- Come valutare le prestazioni del modello in Machine Learning Studio (versione classica)
- Scegliere i parametri per ottimizzare gli algoritmi in Machine Learning Studio (versione classica)
- Interpretare i risultati del modello in Machine Learning Studio (versione classica)
Suggerimento
Ogni volta che si esegue l'esperimento, viene conservato un record dell'iterazione nella cronologia di esecuzione. È possibile visualizzare le iterazioni e tornare a una qualsiasi di esse facendo clic su VISUALIZZA CRONOLOGIA ESECUZIONI sotto l'area di disegno. È anche possibile fare clic su Prior Run (Esecuzione precedente) nel riquadro Properties (Proprietà) per tornare all'iterazione immediatamente precedente a quella aperta.
È possibile eseguire una copia di qualsiasi interazione dell'esperimento facendo clic su SALVA CON NOME sotto l'area di disegno. Usare le proprietà Summary (Riepilogo) e Description (Descrizione) dell'esperimento per tenere traccia dei tentativi eseguiti nelle iterazioni dell'esperimento.
Per altre informazioni, vedere Gestire le iterazioni dell'esperimento in Machine Learning Studio (versione classica).
Pulire le risorse
Se le risorse create in questo articolo non sono più necessarie, eliminarle per evitare di incorrere in eventuali addebiti. Per altre informazioni, vedere l'articolo Esportare ed eliminare i dati utente interni al prodotto.
Passaggi successivi
In questa esercitazione sono stati completati i passaggi seguenti:
- Creare un esperimento
- Eseguire il training di più modelli
- Classificare e valutare i modelli
A questo punto si è pronti per distribuire i modelli per i dati.